Auf dieser Seite erfahren Sie, wie Sie einen Dataproc-Cluster erstellen, der den Spark Spanner-Connector verwendet, um Daten aus Spanner mit Apache Spark zu lesen.
Der Spanner-Connector funktioniert mit Spark, um Daten aus der Spanner-Datenbank mit der Spanner-Java-Bibliothek zu lesen. Der Spanner-Connector unterstützt das Lesen von Spanner-Tabellen und Diagrammen in Spark-DataFrames und GraphFrames.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Dataproc
- Spanner
- Cloud Storage
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweise
Bevor Sie den Spanner-Connector in dieser Anleitung verwenden, müssen Sie einen Dataproc-Cluster sowie eine Spanner-Instanz und -Datenbank einrichten.
Dataproc-Cluster einrichten
Erstellen Sie einen Dataproc-Cluster oder verwenden Sie einen vorhandenen Dataproc-Cluster mit den folgenden Einstellungen:
Berechtigungen für das VM-Dienstkonto. Dem VM-Dienstkonto des Clusters müssen die entsprechenden Spanner-Berechtigungen zugewiesen werden. Wenn Sie Data Boost verwenden (Data Boost ist im Beispielcode unter Spanner-Tabellen exportieren aktiviert), muss das VM-Dienstkonto auch die erforderlichen Data Boost-IAM-Berechtigungen haben.
Zugriffsbereich. Der Cluster muss mit dem
cloud-platform-Bereich oder dem entsprechendenspanner-Bereich erstellt werden. Der Bereichcloud-platformist standardmäßig für Cluster aktiviert, die mit Image-Version 2.1 oder höher erstellt wurden.In der folgenden Anleitung erfahren Sie, wie Sie den
cloud-platform-Bereich als Teil einer Anfrage zum Erstellen eines Clusters festlegen, die die Google Cloud Console, die gcloud CLI oder die Dataproc API verwendet. Weitere Informationen zum Erstellen von Clustern finden Sie unter Cluster erstellen.Google Cloud Console
- Öffnen Sie in der Google Cloud Console die Dataproc-Seite Cluster erstellen.
- Klicken Sie im Bereich Sicherheit verwalten im Abschnitt Projektzugriff auf „Aktiviert den Bereich ‚cloud-platform‘ für diesen Cluster“.
- Füllen Sie die anderen Felder zur Clustererstellung aus oder bestätigen Sie sie und klicken Sie dann auf Erstellen.
gcloud-CLI
Mit dem folgenden
gcloud dataproc clusters create-Befehl können Sie einen Cluster mit aktiviertemcloud-platform-Bereich erstellen.gcloud dataproc clusters create CLUSTER_NAME --scopes https://www.googleapis.com/auth/cloud-platform
API
Sie können GceClusterConfig.serviceAccountScopes im Rahmen einer clusters.create-Anfrage angeben.
"serviceAccountScopes": "https://www.googleapis.com/auth/cloud-platform"
Spanner-Instanz mit einer Datenbanktabelle „Singers“ einrichten
Spanner-Instanz erstellen mit einer Datenbank, die eine Singers-Tabelle enthält. Notieren Sie sich die Spanner-Instanz-ID und die Datenbank-ID.
Spanner-Connector mit Spark verwenden
Der Spanner-Connector ist für Spark-Versionen 3.1+ verfügbar.
Sie geben die Connector-Version als Teil der JAR-Datei des Cloud Storage-Connectors an, wenn Sie einen Job an einen Dataproc-Cluster senden.
Beispiel:gcloud CLI-Spark-Job mit dem Spanner-Connector senden.
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar \ ... [other job submission flags]
Ersetzen Sie Folgendes:
CONNECTOR_VERSION: Version des Spanner-Connectors.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub-Repository GoogleCloudDataproc/spark-spanner-connector aus.
Spanner-Tabellen lesen
Sie können mit Python oder Scala Spanner-Tabellendaten in einen Spark-DataFrame einlesen. Verwenden Sie dazu die Spark-Datenquellen-API.
PySpark
Sie können den Beispiel-PySpark-Code in diesem Abschnitt in Ihrem Cluster ausführen, indem Sie den Job an den Dataproc-Dienst senden oder den Job über die spark-submit-REPL auf dem Masterknoten des Clusters ausführen.
Dataproc-Job
- Erstellen Sie eine
singers.py-Datei mit einem lokalen Texteditor oder in Cloud Shell mit dem vorinstallierten Texteditorvi,vimodernano. - Nachdem Sie die Platzhaltervariablen eingefügt haben, fügen Sie den folgenden Code in die Datei
singers.pyein. Das Spanner-Feature Data Boost ist aktiviert. Es hat praktisch keine Auswirkungen auf die Haupt-Spanner-Instanz.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Google Cloud -Projekt-ID Projekt-IDs werden im Bereich Projektinformationen im Dashboard der Google Cloud Console aufgeführt.
- INSTANCE_ID, DATABASE_ID und TABLE_NAME : Weitere Informationen finden Sie unter Spanner-Instanz mit der Datenbanktabelle
Singerseinrichten.
- Speichern Sie die Datei
singers.py. - Job an den Dataproc-Dienst senden
mit der Google Cloud -Konsole, der gcloud CLI oder der Dataproc API.
Beispiel:Job mit dem Spanner-Connector über die gcloud CLI einreichen.
gcloud dataproc jobs submit pyspark singers.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jarErsetzen Sie Folgendes:
- CLUSTER_NAME: Der Name des neuen Clusters.
- REGION: Eine verfügbare Compute Engine-Region zum Ausführen der Arbeitslast.
- CONNECTOR_VERSION: Version des Spanner-Connectors.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub-Repository
GoogleCloudDataproc/spark-spanner-connectoraus.
spark-submit-Job
- Stellen Sie eine SSH-Verbindung zum Masterknoten des Dataproc-Clusters her.
- Rufen Sie in der Google Cloud Console die Dataproc-Seite Cluster auf und klicken Sie auf den Namen des Clusters.
- Wählen Sie auf der Seite Clusterdetails den Tab „VM-Instanzen“ aus. Klicken Sie dann rechts neben dem Namen des Cluster-Masterknotens auf
SSH.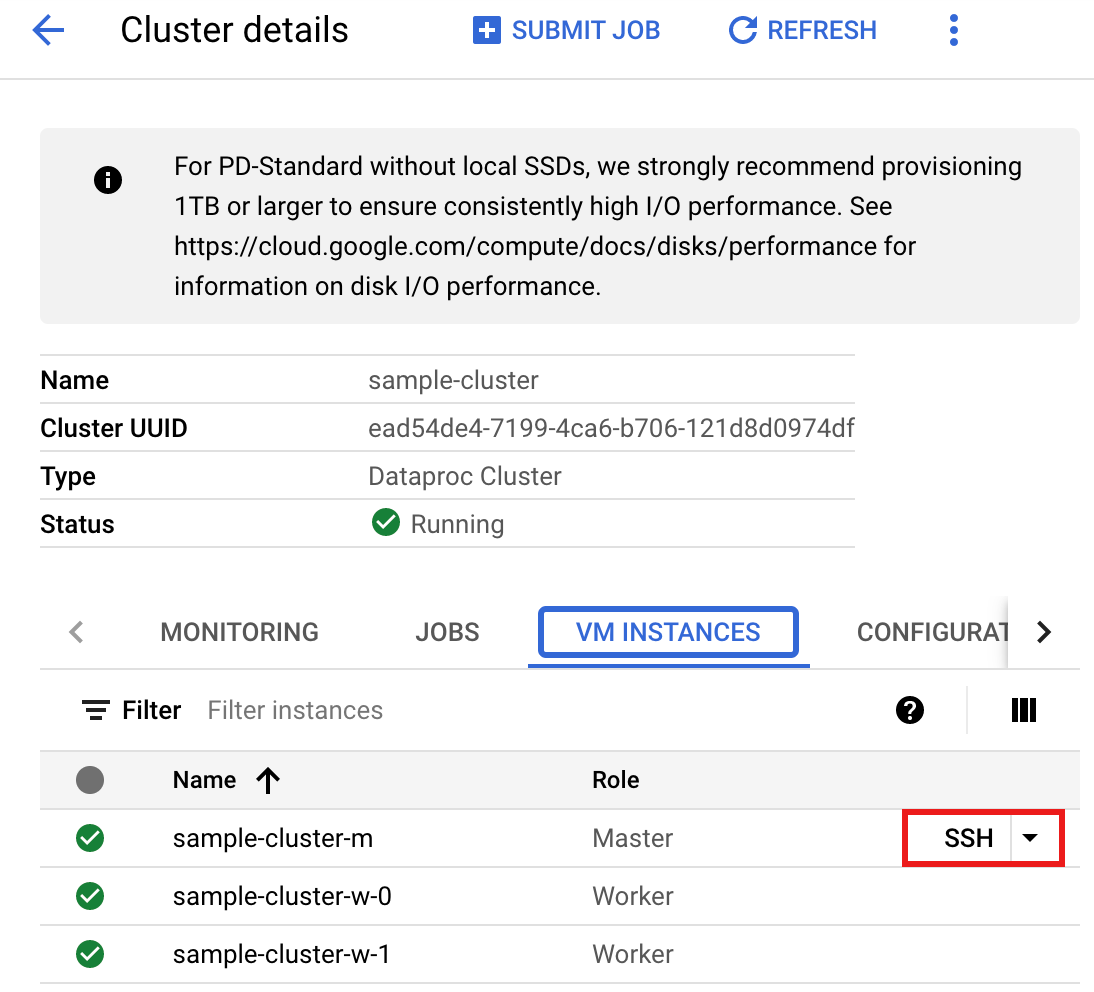
Im Stammverzeichnis des Masterknotens wird ein Browserfenster geöffnet.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Erstellen Sie auf dem Masterknoten eine
singers.py-Datei mit dem vorinstallierten Texteditorvi,vimodernano.- Fügen Sie den folgenden Code in die Datei
singers.pyein. Das Spanner-Feature Data Boost ist aktiviert. Es hat praktisch keine Auswirkungen auf die Haupt-Spanner-Instanz.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Google Cloud -Projekt-ID Projekt-IDs werden im Bereich Projektinformationen im Dashboard der Google Cloud Console aufgeführt.
- INSTANCE_ID, DATABASE_ID und TABLE_NAME : Weitere Informationen finden Sie unter Spanner-Instanz mit der Datenbanktabelle
Singerseinrichten.
- Speichern Sie die Datei
singers.py.
- Fügen Sie den folgenden Code in die Datei
- Führen Sie
singers.pymitspark-submitaus, um die Spanner-TabelleSingerszu erstellen.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
Ersetzen Sie Folgendes:
- CONNECTOR_VERSION: Version des Spanner-Connectors.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub-Repository
GoogleCloudDataproc/spark-spanner-connectoraus.
Die Ausgabe sieht so aus:
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- CONNECTOR_VERSION: Version des Spanner-Connectors.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub-Repository
Scala
Führen Sie die folgenden Schritte aus, um den Beispiel-Scala-Code in Ihrem Cluster auszuführen:
- Stellen Sie eine SSH-Verbindung zum Masterknoten des Dataproc-Clusters her.
- Rufen Sie in der Google Cloud Console die Dataproc-Seite Cluster auf und klicken Sie auf den Namen des Clusters.
- Wählen Sie auf der Seite Clusterdetails den Tab „VM-Instanzen“ aus. Klicken Sie dann rechts neben dem Namen des Cluster-Masterknotens auf
SSH.
Im Stammverzeichnis des Masterknotens wird ein Browserfenster geöffnet.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Erstellen Sie auf dem Masterknoten eine
singers.scala-Datei mit dem vorinstallierten Texteditorvi,vimodernano.- Fügen Sie den folgenden Code in die Datei
singers.scalaein. Das Spanner-Feature Data Boost ist aktiviert. Es hat praktisch keine Auswirkungen auf die Haupt-Spanner-Instanz.object singers { def main(): Unit = { /* * Uncomment (use the following code) if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .option("enableDataBoost", true) .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Google Cloud -Projekt-ID Projekt-IDs werden im Bereich Projektinformationen im Dashboard der Google Cloud Console aufgeführt.
- INSTANCE_ID, DATABASE_ID und TABLE_NAME : Weitere Informationen finden Sie unter Spanner-Instanz mit der Datenbanktabelle
Singerseinrichten.
- Speichern Sie die Datei
singers.scala.
- Fügen Sie den folgenden Code in die Datei
- Starten Sie die
spark-shell-REPL.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
Ersetzen Sie Folgendes:
CONNECTOR_VERSION: Version des Spanner-Connectors. Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub-Repository
GoogleCloudDataproc/spark-spanner-connectoraus. - Führen Sie
singers.scalamit dem Befehl:load singers.scalaaus, um die Spanner-TabelleSingerszu erstellen. Die Ausgabeliste enthält Beispiele aus der Ausgabe von Singers.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
Spanner-Diagramme lesen
Der Spanner-Connector unterstützt den Export des Diagramms in separate Knoten- und Kanten-DataFrames sowie den direkten Export in GraphFrames.
Im folgenden Beispiel wird eine Spanner-Instanz in eine GraphFrame exportiert.
Dazu wird die Python-Klasse SpannerGraphConnector verwendet, die in der JAR-Datei des Spanner-Connectors enthalten ist, um den Spanner-Graphen zu lesen.
from pyspark.sql import SparkSession connector_jar = "gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar" spark = (SparkSession.builder.appName("spanner-graphframe-graphx-example") .config("spark.jars.packages", "graphframes:graphframes:0.8.4-spark3.5-s_2.12") .config("spark.jars", connector_jar) .getOrCreate()) spark.sparkContext.addPyFile(connector_jar) from spannergraph import SpannerGraphConnector connector = (SpannerGraphConnector() .spark(spark) .project("PROJECT_ID") .instance("INSTANCE_ID") .database("DATABASE_ID") .graph("GRAPH_ID")) g = connector.load_graph() g.vertices.show() g.edges.show()
Ersetzen Sie Folgendes:
- CONNECTOR_VERSION: Version des Spanner-Connectors.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub-Repository
GoogleCloudDataproc/spark-spanner-connectoraus. - PROJECT_ID: Ihre Google Cloud -Projekt-ID Projekt-IDs werden im Abschnitt Projektinformationen im Dashboard der Google Cloud Console aufgeführt.
- INSTANCE_ID, DATABASE_ID und TABLE_NAME: Fügen Sie die Instanz-, Datenbank- und Diagramm-IDs ein.
Wenn Sie Knoten und Kanten DataFrames anstelle von GraphFrames exportieren möchten, verwenden Sie stattdessen load_dfs:
df_vertices, df_edges, df_id_map = connector.load_dfs()
Bereinigen
Um laufende Gebühren für Ihr Google Cloud -Konto zu vermeiden, können Sie Ihren Dataproc-Cluster beenden oder löschen und Ihre Spanner-Instanz löschen.
Nächste Schritte
pyspark.sql.DataFrame-Beispiele- Informationen zur Sprachunterstützung für Spark-DataFrames finden Sie unter den folgenden Links:
- Weitere Informationen finden Sie im Spark Spanner Connector-Repository auf GitHub.
- Tipps zur Feinabstimmung von Spark-Jobs