瞭解效能
本頁面說明 Bigtable 在最佳情況下可提供的約略效能、可能影響效能的因素,以及測試和排解 Bigtable 效能問題的訣竅。
一般工作負載效能
Bigtable 提供非常容易預測的效能,且可線性擴充。避免本頁所述的效能變慢原因後,視叢集使用的儲存空間類型而定,每個 Bigtable 節點都能提供下列約略輸送量:
| 儲存空間類型 | 讀取 | 寫入 | 掃描 | ||
|---|---|---|---|---|---|
| SSD | 每秒最多 17,000 列 | 或 | 每秒最多 14,000 列 | 或 | 最高 220 MBps |
| HDD | 每秒最多 500 列 | 或 | 每秒最多 10,000 個資料列 | 或 | 最高 180 MBps |
| 不常存取的儲存空間 | 每秒最多 100 個資料列 | 或 | 每秒最多 10,000 個資料列 | 或 | 最高 36 MBps |
這些預估值假設每個資料列包含 1 KB。
一般來說,叢集的效能會隨著叢集中的節點增加而線性提升。舉例來說,如果您建立的 SSD 叢集包含 10 個節點,這個叢集每秒可支援多達 140,000 個資料列執行一般唯讀或唯寫工作負載。
規劃 Bigtable 容量
規劃 Bigtable 叢集時,請決定要著重於延遲時間還是處理量。舉例來說,如果是批次資料處理工作,您可能會更重視總處理量,而非延遲時間。相較之下,如果線上服務是處理使用者要求,您可能會優先考量低延遲,而非輸送量。如果以輸送量為目標進行最佳化,即可達到「一般工作負載的效能」部分所列的數字。
CPU 使用率
在幾乎所有情況下,我們都建議您使用自動調度資源功能,讓 Bigtable 根據用量新增或移除節點。詳情請參閱「自動調度」。
設定自動調整目標時,或選擇手動節點分配時,請遵循下列指南。無論執行個體有多少叢集,都適用這些規範。如果是手動分配節點的叢集,您必須監控叢集的 CPU 使用率,目標是將 CPU 使用率維持在這些值以下,以獲得最佳效能。
| 最佳化目標 | 最高 CPU 使用率 |
|---|---|
| 處理量 | 90% |
| 延遲時間 | 60% |
如要進一步瞭解監控功能,請參閱「監控」。
儲存空間使用率
容量規劃時,儲存空間也是考量因素。叢集的儲存空間容量取決於儲存空間類型和叢集中的節點數量。當叢集儲存的資料量增加時,Bigtable 會在叢集中的所有節點分配資料,藉此最佳化儲存空間。
如要判斷每個節點的儲存空間用量,請將叢集的儲存空間用量 (位元組) 除以叢集中的節點數量。舉例來說,假設某個叢集有三個 HDD 節點和 9 TB 的資料。每個節點儲存約 3 TB,相當於每個節點 16 TB 的 HDD 儲存空間上限的 18.75%。
儲存空間使用率增加時,即使叢集有足夠的節點來滿足整體 CPU 需求,工作負載的查詢處理延遲仍可能增加。這是因為節點儲存空間越大,就越需要執行索引等背景工作。處理更多儲存空間時,背景工作量會增加,導致延遲時間變長,處理量變少。
設定自動調度資源設定時,請先從下列項目著手。如果選擇手動分配節點,請監控叢集的儲存空間用量,並新增或移除節點,以維持下列狀態。
| 最佳化目標 | 儲存空間使用率上限 |
|---|---|
| 處理量 | 70% |
| 延遲時間 | 60% |
詳情請參閱「每個節點的儲存空間」。
針對 Bigtable 執行工作負載
進行容量規劃時,請務必針對 Bigtable 集群執行工作負載,判斷應用程式的最佳資源分配方式。
Google 的 PerfKit Benchmarker 使用 YCSB 進行雲端服務基準測試。您可以按照 Bigtable 適用的 PerfKitBenchmarker 教學課程,為工作負載建立測試。這麼做時,請調整基準化設定 YAML 檔案中的參數,確保產生的基準反映下列生產特性:
- 資料表總大小 (成比例,但至少 100 GB)。
- 列資料形狀 (列鍵大小、欄數、列資料大小等)
- 資料存取模式 (資料列鍵發布)
- 讀取與寫入的混合比例
如需更多最佳做法,請參閱「使用 Bigtable 測試效能」。
效能緩慢的原因
下列因素可能會導致 Bigtable 執行速度比預估值慢:
- 您在單一讀取要求中讀取大量不連續的資料列鍵或資料列範圍。Bigtable 會掃描資料表,並依序讀取所要求的資料列。這種缺乏平行處理能力的情況會影響整體延遲時間,而讀取作業命中熱節點可能會增加尾部延遲時間。詳情請參閱「讀取次數和成效」一文。
- 資料表的結構定義設計不正確。如要讓 Bigtable 獲得良好效能,請務必設計結構定義,以便在每個資料表之間平均分配讀取與寫入作業。此外,一個資料表中的熱點可能會影響同一執行個體中其他資料表的效能。詳情請參閱「結構定義設計最佳做法」。
- Bigtable 資料表中的資料列包含大量資料。效能預估值假設每個資料列包含 1 KB 的資料。每個資料列可以讀取及寫入更大的資料量,但增加每個資料列的資料量也會降低每秒的資料列數。
- Bigtable 資料表中的資料列包含非常大量的儲存格。 Bigtable 需要時間來處理資料列中的每一個儲存格。每一個儲存格也會對資料表儲存及透過網路傳送的資料量增加一些負擔。舉例來說,如果儲存 1 KB (1,024 個位元組) 的資料,將資料儲存在單一儲存格中會比分散在 1,024 個儲存格 (每個儲存格包含 1 個位元組) 中更有效率。如果分割資料的儲存格數量超過必要數量,效能可能無法達到最佳狀態。如果資料欄包含多個帶有時間戳記的資料版本,導致資料列含有大量儲存格,請考慮只保留最新值。如果資料表已存在,您也可以在每次重寫時,傳送所有先前版本的刪除要求。
叢集的節點數量不足。叢集的節點會提供運算資源,供叢集處理傳入的讀取和寫入作業、追蹤儲存空間,以及執行壓縮等維護工作。請務必確保叢集有足夠的節點,可滿足運算和儲存空間的建議限制。使用監控工具檢查叢集是否過度負載。
- 運算 - 如果 Bigtable 叢集的 CPU 負載過重,新增更多節點可將工作負載分散到更多節點,進而提升效能。
- 儲存空間 - 如果每個節點的儲存空間用量高於建議值,請新增更多節點,以維持最佳延遲時間和輸送量,即使叢集有足夠的 CPU 來處理要求也一樣。這是因為增加每個節點的儲存空間,會增加每個節點的背景維護工作量。詳情請參閱「儲存空間用量與效能之間的取捨」。
Bigtable 叢集最近擴充或縮減。 自動調度資源功能增加叢集中的節點數量後,可能要費時 20 分鐘才能在負載下大幅提升效能。Bigtable 會根據叢集節點的負載量調整節點數量。
縮減叢集中的節點數量時,請盡量不要在 10 分鐘內將叢集大小縮減超過 10%,以免延遲時間大幅增加。
Bigtable 叢集使用 HDD 磁碟。在大部分的情況下,叢集應使用 SSD 磁碟,這類磁碟的效能明顯優於 HDD 磁碟。詳情請參閱「選擇 SSD 或 HDD 儲存空間」。
網路連線有問題。網路問題會造成總處理量降低,讀取和寫入作業的時間會比平常更久。具體來說,如果用戶端與 Bigtable 叢集不在同一個區域,或是用戶端在 Google Cloud以外的環境中執行,就可能會發生問題。
您正在使用複寫功能,但應用程式使用的用戶端程式庫版本過舊。如果在啟用複寫功能後發現延遲時間變長,請確認應用程式使用的 Cloud Bigtable 用戶端程式庫是最新版本。舊版用戶端程式庫可能未經過最佳化,無法支援複製作業。請參閱 Cloud Bigtable 用戶端程式庫,找出用戶端程式庫的 GitHub 存放區,並視需要檢查版本及升級。
您已啟用複製功能,但未在叢集中新增節點。在採用複寫功能的執行個體中,每個叢集除了要處理來自應用程式的負載,還必須處理複寫作業。如果叢集資源不足,可能會導致延遲時間增加。如要確認這一點,請在 Google Cloud 控制台中查看執行個體的 CPU 使用率圖表。
由於效能會因工作負載不同而異,請測試自己的工作負載,以取得最準確的基準。
冷啟動和低 QPS
冷啟動和低 QPS 可能會增加延遲時間。Bigtable 最適合用於經常存取的大型資料表。因此,如果您在一段時間未使用後開始傳送要求 (冷啟動),Bigtable 重新建立連線時可能會出現高延遲。QPS 偏低時,延遲時間也會較長。
如果 QPS 偏低,或您知道自己有時會在一段時間沒有活動後,將要求傳送至 Bigtable 資料表,請嘗試下列策略,讓連線保持運作狀態,避免發生高延遲。
- 隨時以低速率將人為流量傳送至資料表。
- 設定連線集區,確保穩定的 QPS 可讓集區保持運作。
在 QPS 偏低的期間,Bigtable 傳回的錯誤數量比傳回錯誤的作業百分比更具參考價值。
在用戶端初始化時冷啟動。 如果您使用的 Cloud Bigtable Java 用戶端版本低於 2.18.0 版,可以啟用通道重新整理。在後續版本中,頻道重新整理功能預設為啟用。頻道重新整理會執行以下兩項作業:
- 用戶端初始化時,會先準備好管道,再傳送第一個要求。
- 伺服器每小時會中斷長期連線。頻道預先準備功能會預先更換即將到期的頻道。
不過,如果頻道有一段時間沒有活動,這項功能就無法維持頻道熱度。
Bigtable 如何長期最佳化您的資料
為儲存每個資料表的基礎資料,Bigtable 會將資料分片為多個平板電腦,這些平板電腦可在 Bigtable 叢集的節點之間移動。這種儲存方法可讓 Bigtable 隨著時間推移,使用兩種策略來最佳化資料:
- Bigtable 會在每個 Bigtable 節點上儲存大致相同的資料量。
- Bigtable 會在所有 Bigtable 節點之間平均分配讀取和寫入作業。
有時這些策略會互相衝突。舉例來說,如果某個子表的資料列讀取頻率極高,Bigtable 可能會將該子表儲存在自己的節點上,即使這會導致某些節點儲存的資料量多於其他節點。
在此程序中,Bigtable 可能會將子表分割為兩個或多個較小的子表,以縮減大小,或隔離現有子表中的熱門資料列。
下列各節進一步詳述各個策略。
將資料量分散在節點中
將資料寫入 Bigtable 資料表時,Bigtable 會將資料表資料分片為平板電腦。每一個子表都包含資料表內連續範圍的資料列。
如果寫入資料表中的資料量不到幾 GB,Bigtable 會將所有子表儲存在叢集內的單一節點上:
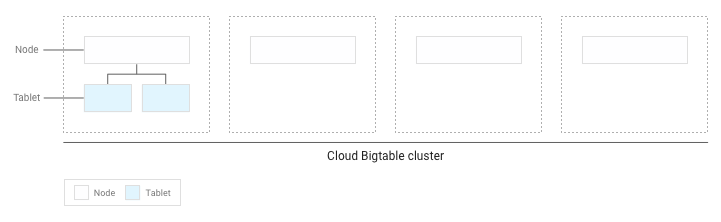
隨著子表累積,Bigtable 會將部分子表移至叢集中的其他節點,以便更平均地分配叢集中的資料量:
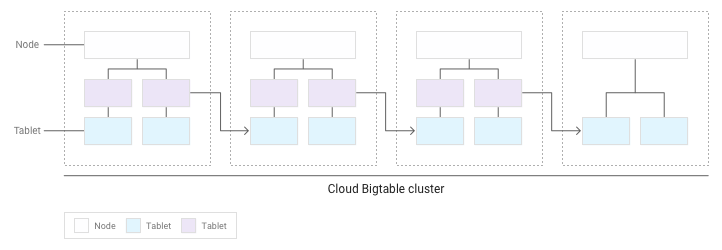
將讀取和寫入作業均勻分散在節點中
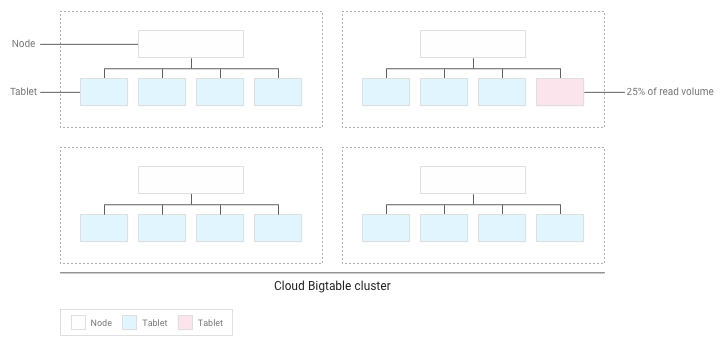
如果您已正確設計結構定義,那麼讀取和寫入作業應該會非常均勻分散在整個資料表中。然而,某些情況下,總是免不了會頻繁地存取某些特定資料列。Bigtable 會在節點間平衡子表時,將讀取和寫入作業納入考量,協助您處理這些情況。
舉例來說,假設叢集內有少數幾個平板電腦的讀取作業占了 25%,而其他平板電腦的讀取作業則平均分配:
Bigtable 會重新分配現有平板電腦,盡可能在整個叢集中平均分配讀取作業:
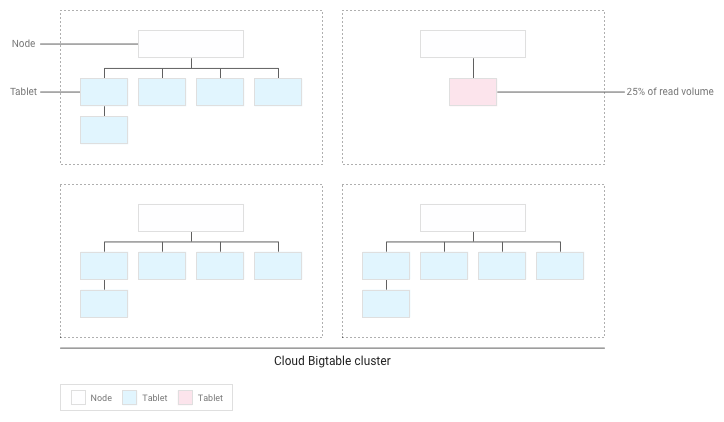
使用 Bigtable 測試效能
如果您要對依附於 Bigtable 的應用程式執行效能測試,請在規劃及執行測試時遵循下列準則:
- 使用足夠的資料進行測試。
- 如果生產環境例項中的資料表每節點總共包含 100 GB 的資料或更少,請使用相同資料量的資料表進行測試。
- 如果資料表每個節點的資料量超過 100 GB,請使用每個節點至少有 100 GB 資料的資料表進行測試。舉例來說,如果您的正式版執行個體有一個四節點叢集,且執行個體中的資料表總共包含 1 TB 的資料,請使用至少 400 GB 的資料表執行測試。
- 使用單一資料表進行測試。
- 每個節點的儲存空間使用率應維持低於建議值。詳情請參閱「每個節點的儲存空間使用率」。
- 測試前,請先執行幾分鐘的密集前測。Bigtable 會根據觀察到的存取模式,在節點間平衡資料。
- 測試時間至少要 10 分鐘。這個步驟可讓 Bigtable 進一步將資料最佳化,並有助於您確實測試磁碟讀取和記憶體快取讀取。
排解效能問題
如果您認為 Bigtable 可能會在應用程式中造成效能瓶頸,請務必檢查下列所有項目:
- 檢查資料表的 Key Visualizer 掃描結果。Bigtable 的 Key Visualizer 工具每 15 分鐘會產生新的掃描資料,顯示叢集中每個資料表的用量模式。您可以透過 Key Visualizer 檢查使用模式是否導致不良結果,例如特定資料列上的熱點或 CPU 使用率過高。詳情請參閱「使用 Key Visualizer」。
- 註解掉執行 Bigtable 讀取和寫入作業的程式碼。如果效能問題消失,表示您可能以導致效能不佳的方式使用 Bigtable。如果效能問題仍未解決,可能與 Bigtable 無關。
請盡量減少建立的用戶端數量。建立 Bigtable 用戶端是相對昂貴的作業。因此,您建立的用戶端應該越少越好:
- 如果您使用複製功能,或是使用應用程式設定檔來辨識進入執行個體的不同流量類型,請為每個應用程式設定檔建立一個用戶端,並在整個應用程式中共用那些用戶端。
- 如果沒有使用複製功能或應用程式設定檔,請建立單一用戶端,並在整個應用程式中共用這個用戶端。
如果您使用 Java 適用的 HBase 用戶端,請建立
Connection物件,而非用戶端,因此請盡量減少連線。請務必讀取及寫入資料表中的許多不同資料列。 如果讀取和寫入作業平均分散在整個資料表中,Bigtable 的效能最佳,這有助於 Bigtable 將工作負載分配到叢集中的所有節點。如果讀取和寫入作業無法分散到所有 Bigtable 節點,效能就會受到影響。
如果您發現讀取和寫入只集中在少數的資料列時,可能需要重新設計您的結構定義,讓讀取和寫入作業可以更均勻地分佈。
確認讀取和寫入作業的效能大致相同。如果發現讀取速度遠快於寫入速度,可能是因為您嘗試讀取不存在的資料列索引鍵,或是範圍廣大的資料列索引鍵,但其中只有少數資料列。
如要有效比較讀取和寫入作業,請確保至少 90% 的讀取作業會傳回有效結果。此外,如果讀取大範圍的資料列索引鍵,請根據這個範圍內的實際資料列數測量效能,而不是根據「可能」存在的最大資料列數。
為您的資料使用正確的寫入要求類型。 選擇最佳的資料寫入方式有助於維持高效能。
檢查單一資料列的延遲時間。如果在傳送
ReadRows要求時發生非預期的延遲,您可以檢查要求第一列的延遲,縮小原因範圍。根據預設,ReadRows要求的整體延遲時間包括要求中每列的延遲時間,以及列之間的處理時間。如果整體延遲時間很長,但第一列延遲時間很短,表示延遲時間是由要求數量或處理時間所致,而非 Bigtable 問題。如果您使用 [Bigtable Java 用戶端程式庫][java-client],可以啟用用戶端指標,然後在Google Cloud 控制台的 Metrics Explorer 中查看
read_rows_first_row_latency指標。為每個工作負載使用不同的應用程式設定檔。如果新增工作負載後發生效能問題,請為新的工作負載建立新的應用程式設定檔。接著,您可以分別監控應用程式設定檔的指標,進一步排解問題。如要瞭解為什麼建議使用多個應用程式設定檔,請參閱「應用程式設定檔的運作方式」。
啟用用戶端指標。您可以設定用戶端指標,協助改善及排解效能問題。舉例來說,由於 Bigtable 最適合平均分配的高 QPS,因此一小部分要求的 P100 (最大) 延遲時間增加,不一定表示 Bigtable 有較大的效能問題。用戶端指標可協助您深入瞭解請求生命週期中,哪個部分可能導致延遲。
請確保應用程式會在讀取要求逾時前使用這些要求。如果應用程式在讀取串流期間處理資料,要求可能會在您收到所有呼叫回應前逾時。這會導致
ABORTED訊息。如果看到這項錯誤,請減少讀取串流期間的處理量。
後續步驟
- 瞭解如何設計 Bigtable 結構定義。
- 瞭解如何監控 Bigtable 效能。
- 瞭解如何排解 Key Visualizer 問題。
- 瞭解如何排解延遲問題。
- 查看透過程式將節點新增到 Bigtable 叢集的程式碼範例。