Compreenda o desempenho
Esta página descreve o desempenho aproximado que o Bigtable pode oferecer em condições ideais, os fatores que podem afetar o desempenho e sugestões para testar e resolver problemas de desempenho do Bigtable.
Desempenho para cargas de trabalho típicas
O Bigtable oferece um desempenho altamente previsível e linearmente escalável. Quando evita as causas do desempenho mais lento descritas nesta página, cada nó do Bigtable pode fornecer a seguinte taxa de transferência aproximada, consoante o tipo de armazenamento que o cluster usa:
| Tipo de armazenamento | Leituras | Escreve | Análises | ||
|---|---|---|---|---|---|
| SSD | até 17 000 linhas por segundo | ou | até 14 000 linhas por segundo | ou | Até 220 MBps |
| HDD | até 500 linhas por segundo | ou | até 10 000 linhas por segundo | ou | Até 180 MBps |
| Armazenamento de acesso pouco frequente | até 100 linhas por segundo | ou | até 10 000 linhas por segundo | ou | Até 36 MBps |
Estas estimativas pressupõem que cada linha contém 1 KB.
Em geral, o desempenho de um cluster é proporcional à medida que adiciona nós ao cluster. Por exemplo, se criar um cluster de SSDs com 10 nós, o cluster pode suportar até 140 000 linhas por segundo para uma carga de trabalho típica só de leitura ou só de escrita.
Planeie a capacidade do Bigtable
Ao planear os clusters do Bigtable, decida se quer otimizar para latência ou débito. Por exemplo, para uma tarefa de tratamento de dados em lote, pode dar mais importância ao débito e menos à latência. Por outro lado, para um serviço online que responde a pedidos dos utilizadores, pode dar prioridade a uma latência inferior em vez de ao débito. Pode alcançar os números na secção Desempenho para cargas de trabalho típicas quando faz a otimização para débito.
Utilização da CPU
Em quase todos os casos, recomendamos que use o dimensionamento automático, que permite ao Bigtable adicionar ou remover nós com base na utilização. Para mais informações, consulte Ajuste automático de escala.
Use as seguintes diretrizes quando configurar os seus alvos de dimensionamento automático ou se escolher a atribuição manual de nós. Estas diretrizes aplicam-se independentemente do número de clusters que a sua instância tem. Para um cluster com atribuição manual de nós, tem de monitorizar a utilização da CPU do cluster com o objetivo de manter a utilização da CPU abaixo destes valores para um desempenho ideal.
| Objetivo de otimização | Utilização máxima da CPU |
|---|---|
| Débito | 90% |
| Latência | 60% |
Para mais informações sobre a monitorização, consulte o artigo Monitorização.
Utilização do armazenamento
O armazenamento é outra consideração no planeamento de capacidade. A capacidade de armazenamento de um cluster é determinada pelo tipo de armazenamento e pelo número de nós no cluster. Quando a quantidade de dados armazenados num cluster aumenta, o Bigtable otimiza o armazenamento distribuindo os dados por todos os nós no cluster.
Pode determinar a utilização de armazenamento por nó dividindo a utilização de armazenamento (bytes) do cluster pelo número de nós no cluster. Por exemplo, considere um cluster com três nós de HDD e 9 TB de dados. Cada nó armazena cerca de 3 TB, o que corresponde a 18,75% do limite de armazenamento do disco rígido por nó de 16 TB.
Quando a utilização do armazenamento aumenta, as cargas de trabalho podem sofrer um aumento na latência de processamento de consultas, mesmo que o cluster tenha nós suficientes para satisfazer as necessidades gerais de CPU. Isto deve-se ao facto de que quanto maior for o armazenamento por nó, mais trabalho em segundo plano, como a indexação, é necessário. O aumento do trabalho em segundo plano para processar mais armazenamento pode resultar numa latência mais elevada e num débito mais baixo.
Comece com o seguinte quando configurar as definições de dimensionamento automático. Se escolher a atribuição manual de nós, monitorize a utilização do armazenamento do cluster e adicione ou remova nós para manter o seguinte.
| Objetivo de otimização | Utilização máxima do armazenamento |
|---|---|
| Débito | 70% |
| Latência | 60% |
Para mais informações, consulte o artigo Armazenamento por nó.
Execute as suas cargas de trabalho no Bigtable
Execute sempre as suas cargas de trabalho num cluster do Bigtable quando fizer o planeamento da capacidade para determinar a melhor atribuição de recursos para as suas aplicações.
O PerfKit Benchmarker da Google usa o YCSB para testes de referência de serviços na nuvem. Pode seguir o tutorial do PerfKitBenchmarker para o Bigtable para criar testes para as suas cargas de trabalho. Ao fazê-lo, ajuste os parâmetros nos ficheiros YAML de configuração de testes de referência para garantir que o teste de referência gerado reflete as seguintes caraterísticas de produção:
- Tamanho total da tabela (proporcional, mas, pelo menos, 100 GB).
- Formato dos dados das linhas (tamanho da chave da linha, número de colunas, tamanhos dos dados das linhas, etc.)
- Padrão de acesso aos dados (distribuição de chaves de linhas)
- Mistura de leituras e escritas
Consulte o artigo Testar o desempenho com o Bigtable para ver mais práticas recomendadas.
Causas do desempenho mais lento
Os seguintes fatores podem fazer com que o Bigtable tenha um desempenho mais lento do que o estimado:
- Lê um grande número de chaves de linhas ou intervalos de linhas não contíguos numa única solicitação de leitura. O Bigtable analisa a tabela e lê as linhas pedidas sequencialmente. Esta falta de paralelismo afeta a latência geral e as leituras que atingem um nó ativo podem aumentar a latência final. Consulte o artigo Leituras e desempenho para ver detalhes.
- O esquema da tabela não está concebido corretamente. Para conseguir um bom desempenho do Bigtable, é essencial criar um esquema que permita distribuir as leituras e as escritas de forma uniforme por cada tabela. Além disso, os pontos críticos numa tabela podem afetar o desempenho de outras tabelas na mesma instância. Consulte as práticas recomendadas de criação de esquemas para mais informações.
- As linhas na sua tabela do Bigtable contêm grandes quantidades de dados. As estimativas de desempenho pressupõem que cada linha contém 1 KB de dados. Pode ler e escrever maiores quantidades de dados por linha, mas aumentar a quantidade de dados por linha também reduz o número de linhas por segundo.
- As linhas na sua tabela do Bigtable contêm um número muito elevado de células. O Bigtable demora algum tempo a processar cada célula numa linha. Além disso, cada célula adiciona alguma sobrecarga à quantidade de dados armazenados na tabela e enviados através da rede. Por exemplo, se estiver a armazenar 1 KB (1024 bytes) de dados, é muito mais eficiente em termos de espaço armazenar esses dados numa única célula do que distribuí-los por 1024 células que contêm 1 byte cada. Se dividir os dados em mais células do que o necessário, pode não conseguir o melhor desempenho possível. Se as linhas contiverem um grande número de células porque as colunas contêm várias versões com data/hora dos dados, considere manter apenas o valor mais recente. Outra opção para uma tabela existente é enviar uma eliminação de todas as versões anteriores com cada reescrita.
O cluster não tem nós suficientes. Os nós de um cluster fornecem capacidade de computação para o cluster processar leituras e escritas recebidas, monitorizar o armazenamento e realizar tarefas de manutenção, como a compactação. Tem de garantir que o cluster tem nós suficientes para satisfazer os limites recomendados para o cálculo e o armazenamento. Use as ferramentas de monitorização para verificar se o cluster está sobrecarregado.
- Computação: se a CPU do cluster do Bigtable estiver sobrecarregada, a adição de mais nós melhora o desempenho ao distribuir a carga de trabalho por mais nós.
- Armazenamento: se a utilização do armazenamento por nó for superior à recomendada, adicione mais nós para manter a latência e a taxa de transferência ideais, mesmo que o cluster tenha CPU suficiente para processar pedidos. Isto deve-se ao facto de que o aumento da quantidade de armazenamento por nó aumenta a quantidade de trabalho de manutenção em segundo plano por nó. Para mais informações, consulte o artigo Compromissos entre a utilização do armazenamento e o desempenho.
O cluster do Bigtable foi aumentado ou reduzido recentemente. Depois de o dimensionamento automático aumentar o número de nós num cluster, podem demorar até 20 minutos sob carga antes de o desempenho melhorar significativamente. O Bigtable dimensiona os nós do cluster com base na carga que experimentam.
Quando diminui o número de nós num cluster para reduzir a escala, tente não reduzir o tamanho do cluster em mais de 10% num período de 10 minutos para minimizar os picos de latência.
O cluster do Bigtable usa discos HDD. Na maioria dos casos, o cluster deve usar discos SSD, que têm um desempenho significativamente melhor do que os discos HDD. Consulte o artigo Escolher entre o armazenamento SSD e HDD para ver detalhes.
Existem problemas com a ligação de rede. Os problemas de rede podem reduzir a taxa de transferência e fazer com que as leituras e as escritas demorem mais do que o habitual. Em particular, pode ter problemas se os seus clientes não estiverem a ser executados na mesma zona que o cluster do Bigtable ou se os seus clientes forem executados Google Cloudfora Google Clouddo Google Cloud.
Está a usar a replicação, mas a sua aplicação está a usar uma biblioteca de cliente desatualizada. Se observar um aumento da latência após ativar a replicação, certifique-se de que a biblioteca de cliente do Cloud Bigtable que a sua aplicação está a usar está atualizada. As versões anteriores das bibliotecas de cliente podem não estar otimizadas para suportar a replicação. Consulte as bibliotecas cliente do Cloud Bigtable para encontrar o repositório do GitHub da sua biblioteca cliente, onde pode verificar a versão e fazer a atualização, se necessário.
Ativou a replicação, mas não adicionou mais nós aos seus clusters. Numa instância que usa a replicação, cada cluster tem de processar o trabalho de replicação, além da carga que recebe das aplicações. Os clusters com aprovisionamento insuficiente podem causar um aumento da latência. Pode verificar isto consultando os gráficos de utilização da CPU da instância na Google Cloud consola.
Uma vez que diferentes cargas de trabalho podem fazer com que o desempenho varie, faça testes com as suas cargas de trabalho para obter as referências mais precisas.
Inícios a frio e CPS baixa
Os inícios a frio e o baixo QPS podem aumentar a latência. O Bigtable tem o melhor desempenho com tabelas grandes que são acedidas com frequência. Por este motivo, se começar a enviar pedidos após um período sem utilização (um início a frio), pode observar uma latência elevada enquanto o Bigtable restabelece as ligações. A latência também é mais elevada quando o QPS é baixo.
Se o seu QPS for baixo ou se souber que, por vezes, envia pedidos para uma tabela do Bigtable após um período de inatividade, experimente as seguintes estratégias para manter a ligação ativa e evitar uma latência elevada.
- Enviar sempre uma taxa baixa de tráfego artificial para a tabela.
- Configure o conjunto de ligações para ajudar a garantir que o QPS constante mantém o conjunto ativo.
Durante períodos de QPS baixo, o número de erros que o Bigtable devolve é mais relevante do que a percentagem de operações que devolvem um erro.
Início a frio no momento da inicialização do cliente. Se estiver a usar uma versão do cliente do Cloud Bigtable para Java anterior à versão 2.18.0, pode ativar a atualização do canal. Nas versões posteriores, a atualização de canais está ativada por predefinição. A atualização do canal faz duas coisas:
- Quando o cliente é inicializado, prepara o canal antes de enviar os primeiros pedidos.
- O servidor desliga as ligações de longa duração a cada hora. A preparação dos canais substitui preventivamente os canais com prazo de validade.
No entanto, isto não mantém o canal ativo quando existem períodos de inatividade.
Como o Bigtable otimiza os seus dados ao longo do tempo
Para armazenar os dados subjacentes de cada uma das suas tabelas, o Bigtable fragmenta os dados em vários tablets, que podem ser movidos entre nós no seu cluster do Bigtable. Este método de armazenamento permite que o Bigtable use duas estratégias para otimizar os dados ao longo do tempo:
- O Bigtable armazena aproximadamente a mesma quantidade de dados em cada nó do Bigtable.
- O Bigtable distribui as leituras e as escritas de forma igual por todos os nós do Bigtable.
Por vezes, estas estratégias entram em conflito. Por exemplo, se as linhas de um tablet forem lidas com muita frequência, o Bigtable pode armazenar esse tablet no respetivo nó, mesmo que isso faça com que alguns nós armazenem mais dados do que outros.
Como parte deste processo, o Bigtable pode dividir um tablet em dois ou mais tablets mais pequenos para reduzir o respetivo tamanho ou isolar linhas ativas num tablet existente.
As secções seguintes explicam cada uma destas estratégias mais detalhadamente.
Distribuir a quantidade de dados entre nós
À medida que escreve dados numa tabela do Bigtable, o Bigtable fragmenta os dados da tabela em tablets. Cada tablet contém um intervalo contíguo de linhas na tabela.
Se tiver escrito menos de vários GB de dados na tabela, o Bigtable armazena todas as tablets num único nó no cluster:
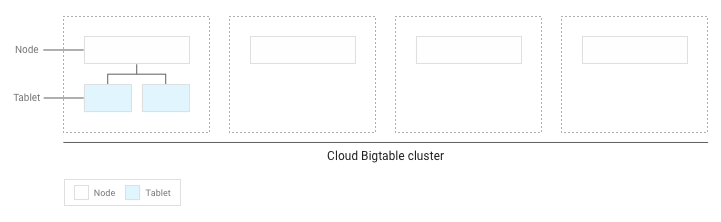
À medida que se acumulam mais tablets, o Bigtable move alguns para outros nós no cluster para equilibrar a quantidade de dados de forma mais uniforme no cluster:
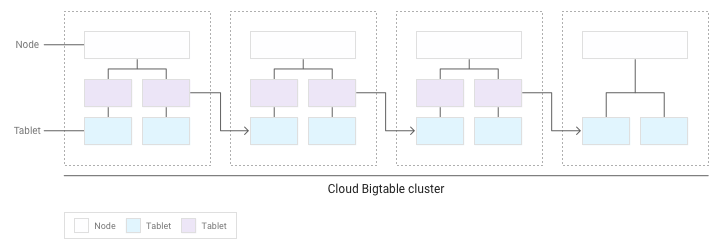
Distribuir leituras e escritas uniformemente entre nós
Se concebeu o seu esquema corretamente, as leituras e as escritas devem ser distribuídas de forma relativamente uniforme por toda a tabela. No entanto, existem alguns casos em que não pode evitar aceder a determinadas linhas com mais frequência do que outras. O Bigtable ajuda a lidar com estes casos tendo em conta as leituras e as escritas quando equilibra as tabelas em vários nós.
Por exemplo, suponhamos que 25% das leituras são direcionadas para um pequeno número de tablets num cluster e que as leituras são distribuídas uniformemente por todos os outros tablets:
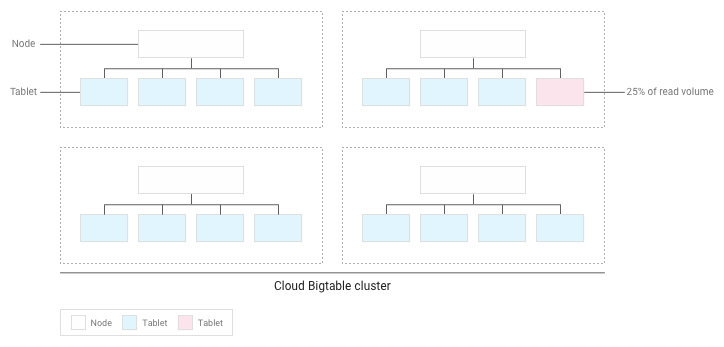
O Bigtable redistribui as tabelas existentes para que as leituras sejam distribuídas o mais uniformemente possível por todo o cluster:
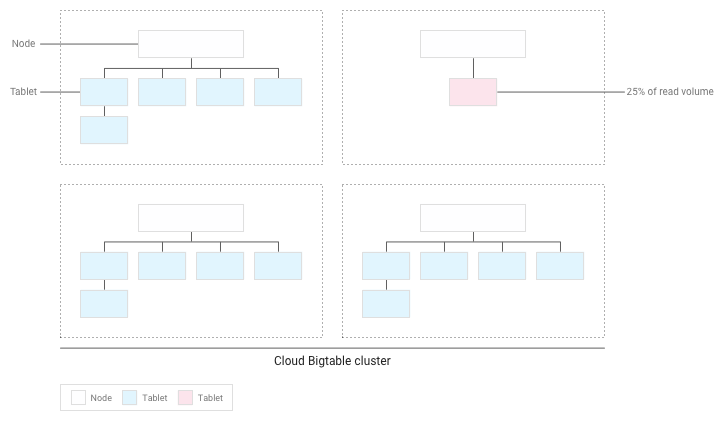
Teste o desempenho com o Bigtable
Se estiver a executar um teste de desempenho para uma aplicação que dependa do Bigtable, siga estas diretrizes ao planear e executar o teste:
- Faça testes com dados suficientes.
- Se as tabelas na sua instância de produção contiverem um total de 100 GB de dados ou menos por nó, teste com uma tabela com a mesma quantidade de dados.
- Se as tabelas contiverem mais de 100 GB de dados por nó, teste com uma tabela que contenha, pelo menos, 100 GB de dados por nó. Por exemplo, se a sua instância de produção tiver um cluster de quatro nós e as tabelas na instância contiverem um total de 1 TB de dados, execute o teste com uma tabela de, pelo menos, 400 GB.
- Teste com uma única tabela.
- Mantenha-se abaixo da utilização de armazenamento recomendada por nó. Para ver detalhes, consulte o artigo Utilização do armazenamento por nó.
- Antes de testar, execute um pré-teste intenso durante vários minutos. Este passo permite que o Bigtable equilibre os dados nos seus nós com base nos padrões de acesso que observa.
- Execute o teste durante, pelo menos, 10 minutos. Este passo permite que o Bigtable otimize ainda mais os seus dados e ajuda a garantir que testa as leituras do disco, bem como as leituras em cache da memória.
Resolva problemas de desempenho
Se considerar que o Bigtable pode estar a criar um gargalo de desempenho na sua aplicação, certifique-se de que verifica todos os seguintes aspetos:
- Examine as análises do Key Visualizer para a sua tabela. A ferramenta Key Visualizer para o Bigtable gera novos dados de análise a cada 15 minutos, mostrando os padrões de utilização de cada tabela num cluster. O Key Visualizer permite-lhe verificar se os seus padrões de utilização estão a causar resultados indesejáveis, como pontos críticos em linhas específicas ou utilização excessiva da CPU. Para mais informações, consulte o artigo Use o Key Visualizer.
- Comente o código que executa leituras e escritas do Bigtable. Se o problema de desempenho desaparecer, é provável que esteja a usar o Bigtable de uma forma que resulta num desempenho inferior ao ideal. Se o problema de desempenho persistir, é provável que não esteja relacionado com o Bigtable.
Certifique-se de que cria o menor número possível de clientes. Criar um cliente para o Bigtable é uma operação relativamente dispendiosa. Por isso, deve criar o menor número possível de clientes:
- Se usar a replicação ou se usar perfis da app para identificar diferentes tipos de tráfego para a sua instância, crie um cliente por perfil da app e partilhe os clientes em toda a sua aplicação.
- Se não usar a replicação nem os perfis de apps, crie um único cliente e partilhe-o em toda a sua aplicação.
Se estiver a usar o cliente HBase para Java, cria um objeto
Connectionem vez de um cliente, pelo que deve criar o menor número possível de ligações.Certifique-se de que está a ler e escrever muitas linhas diferentes na sua tabela. O Bigtable tem o melhor desempenho quando as leituras e as escritas são distribuídas uniformemente por toda a tabela, o que ajuda o Bigtable a distribuir a carga de trabalho por todos os nós no cluster. Se as leituras e as escritas não puderem ser distribuídas por todos os nós do Bigtable, o desempenho será afetado.
Se verificar que está a ler e escrever apenas um pequeno número de linhas, pode ter de reestruturar o seu esquema para que as leituras e as escritas sejam distribuídas de forma mais uniforme.
Verifique se vê aproximadamente o mesmo desempenho para leituras e gravações. Se verificar que as leituras são muito mais rápidas do que as escritas, pode estar a tentar ler chaves de linhas que não existem ou um grande intervalo de chaves de linhas que contém apenas um pequeno número de linhas.
Para fazer uma comparação válida entre leituras e escritas, procure que, pelo menos, 90% das suas leituras devolvam resultados válidos. Além disso, se estiver a ler um grande intervalo de chaves de linhas, meça o desempenho com base no número real de linhas nesse intervalo, em vez do número máximo de linhas que poderiam existir.
Use o tipo certo de pedidos de gravação para os seus dados. Escolher a forma ideal de escrever os seus dados ajuda a manter um elevado desempenho.
Verifique a latência de uma única linha. Se observar uma latência inesperada ao enviar pedidos
ReadRows, pode verificar a latência da primeira linha do pedido para restringir a causa. Por predefinição, a latência geral de um pedidoReadRowsinclui a latência de cada linha no pedido, bem como o tempo de processamento entre linhas. Se a latência geral for elevada, mas a latência da primeira linha for baixa, isto sugere que a latência é causada pelo número de pedidos ou pelo tempo de processamento, em vez de um problema com o Bigtable.Se estiver a usar a [biblioteca cliente do Bigtable para Java] [java-client], pode ver a métrica
read_rows_first_row_latencyno Google Cloud Explorador de métricas da consola depois de ativar as métricas do lado do cliente.Use um perfil de app separado para cada carga de trabalho. Se tiver problemas de desempenho após adicionar uma nova carga de trabalho, crie um novo perfil da app para a nova carga de trabalho. Em seguida, pode monitorizar as métricas dos perfis das suas apps separadamente para resolver problemas adicionais. Consulte o artigo Como funcionam os perfis de apps para ver detalhes sobre o motivo pelo qual é uma prática recomendada usar vários perfis de apps.
Ative as métricas do lado do cliente. Pode configurar métricas do lado do cliente para ajudar a otimizar e resolver problemas de desempenho. Por exemplo, uma vez que o Bigtable funciona melhor com uma distribuição uniforme, um elevado número de consultas por segundo e um aumento da latência P100 (máxima) para uma pequena percentagem de pedidos não indicam necessariamente um problema de desempenho maior com o Bigtable. As métricas do lado do cliente podem dar-lhe estatísticas sobre que parte do ciclo de vida do pedido pode estar a causar latência.
Certifique-se de que a sua aplicação consome pedidos de leitura antes de expirarem. Se a sua aplicação processar dados durante um fluxo de leitura, corre o risco de o pedido expirar antes de ter recebido todas as respostas da chamada. Isto resulta numa mensagem
ABORTED. Se vir este erro, reduza a quantidade de processamento durante a stream de leitura.
O que se segue?
- Saiba como conceber um esquema do Bigtable.
- Saiba como monitorizar o desempenho do Bigtable.
- Saiba como resolver problemas com o Key Visualizer.
- Saiba como resolver problemas de latência.
- Veja um exemplo de código para adicionar nós programaticamente a um cluster do Bigtable.