Memahami performa
Halaman ini menjelaskan perkiraan performa yang dapat disediakan Bigtable dalam kondisi optimal, faktor yang dapat memengaruhi performa, dan tips untuk menguji dan memecahkan masalah performa Bigtable.
Performa untuk beban kerja umum
Bigtable memberikan performa yang sangat dapat diprediksi dan skalabilitasnya linear. Jika Anda menghindari penyebab performa yang lebih lambat yang dijelaskan di bawah, setiap node Bigtable dapat memberikan throughput perkiraan berikut, bergantung pada jenis penyimpanan yang digunakan cluster:
| Jenis Penyimpanan | Baca | Tulis | Pemindaian | ||
|---|---|---|---|---|---|
| SSD | hingga 17.000 baris per detik | atau | hingga 14.000 baris per detik | atau | hingga 220 MB/dtk |
| HDD | hingga 500 baris per detik | atau | hingga 10.000 baris per detik | atau | hingga 180 MB/dtk |
Estimasi ini mengasumsikan bahwa setiap baris berisi data 1 KB.
Secara umum, performa cluster diskalakan secara linear saat Anda menambahkan node ke cluster. Misalnya, jika Anda membuat cluster SSD dengan 10 node, cluster tersebut dapat mendukung hingga 140.000 baris per detik untuk beban kerja hanya baca atau hanya tulis yang umum.
Merencanakan kapasitas Bigtable
Saat merencanakan cluster Bigtable, tentukan apakah Anda ingin mengoptimalkan latensi atau throughput. Misalnya, untuk tugas pemrosesan data batch, Anda mungkin lebih memperhatikan throughput dan kurang memperhatikan latensi. Sebaliknya, untuk layanan online yang melayani permintaan pengguna, Anda dapat memprioritaskan latensi yang lebih rendah daripada throughput. Anda dapat mencapai angka di bagian Performa untuk beban kerja umum saat mengoptimalkan throughput.
Pemakaian CPU
Dalam hampir semua kasus, sebaiknya gunakan penskalaan otomatis, yang memungkinkan Bigtable menambahkan atau menghapus node berdasarkan penggunaan Anda. Untuk informasi selengkapnya, lihat Penskalaan otomatis.
Gunakan panduan berikut saat mengonfigurasi target penskalaan otomatis atau jika Anda memilih alokasi node manual. Panduan ini berlaku terlepas dari jumlah cluster yang dimiliki instance Anda. Untuk cluster dengan alokasi node manual, Anda harus memantau penggunaan CPU cluster dengan tujuan menjaga penggunaan CPU di bawah nilai ini untuk performa yang optimal.
| Sasaran pengoptimalan | Pemakaian CPU maksimum |
|---|---|
| Throughput | 90% |
| Latensi | 60% |
Untuk mengetahui informasi selengkapnya tentang pemantauan, lihat Pemantauan.
Pemanfaatan penyimpanan
Pertimbangan lainnya dalam perencanaan kapasitas adalah penyimpanan. Kapasitas penyimpanan cluster ditentukan oleh jenis penyimpanan dan jumlah node dalam cluster. Saat jumlah data yang disimpan di cluster meningkat, Bigtable akan mengoptimalkan penyimpanan dengan mendistribusikan jumlah data ke semua node dalam cluster.
Anda dapat menentukan penggunaan penyimpanan per node dengan membagi penggunaan penyimpanan (byte) cluster dengan jumlah node dalam cluster. Misalnya, pertimbangkan cluster yang memiliki tiga node HDD dan data sebesar 9 TB. Setiap node menyimpan sekitar 3 TB, yang merupakan 18,75% dari batas penyimpanan HDD per node sebesar 16 TB.
Saat penggunaan penyimpanan meningkat, workload dapat mengalami peningkatan latensi pemrosesan kueri meskipun cluster memiliki cukup node untuk memenuhi kebutuhan CPU secara keseluruhan. Hal ini karena semakin tinggi penyimpanan per node, semakin banyak pekerjaan latar belakang seperti pengindeksan yang diperlukan. Peningkatan tugas latar belakang untuk menangani penyimpanan yang lebih banyak dapat menyebabkan latensi yang lebih tinggi dan throughput yang lebih rendah.
Mulailah dengan hal berikut saat mengonfigurasi setelan penskalaan otomatis. Jika Anda memilih alokasi node manual, pantau penggunaan penyimpanan cluster dan tambahkan atau hapus node untuk mempertahankan hal berikut.
| Sasaran pengoptimalan | Pemakaian penyimpanan maksimum |
|---|---|
| Throughput | 70% |
| Latensi | 60% |
Untuk mengetahui informasi selengkapnya, lihat Penyimpanan per node.
Menjalankan workload standar Anda terhadap Bigtable
Selalu jalankan beban kerja standar Anda sendiri terhadap cluster Bigtable saat melakukan perencanaan kapasitas, sehingga Anda dapat mengetahui alokasi resource terbaik untuk aplikasi Anda.
PerfKit Benchmarker Google menggunakan YCSB untuk menjalankan benchmark layanan cloud. Anda dapat mengikuti
tutorial PerfKitBenchmarker untuk Bigtable
untuk membuat pengujian bagi beban kerja Anda sendiri. Saat melakukannya, Anda harus menyesuaikan
parameter dalam file yaml konfigurasi benchmark untuk memastikan bahwa
benchmark yang dihasilkan mencerminkan karakteristik berikut dalam produksi Anda:
- Total ukuran tabel Anda. Hal ini dapat bersifat proporsional, tetapi gunakan setidaknya 100 GB.
- Bentuk data baris (ukuran kunci baris, jumlah kolom, ukuran data baris, dll.)
- Pola akses data (distribusi kunci baris)
- Campuran operasi baca vs. tulis
Lihat Menguji performa dengan Bigtable untuk mengetahui praktik terbaik lainnya.
Penyebab performa yang lebih lambat
Ada beberapa faktor yang dapat menyebabkan Bigtable berperforma lebih lambat daripada estimasi yang ditampilkan di atas:
- Anda membaca sejumlah besar kunci baris atau rentang baris yang tidak berdekatan dalam satu permintaan baca. Bigtable memindai tabel dan membaca baris yang diminta secara berurutan. Kurangnya paralelisme ini memengaruhi latensi keseluruhan, dan setiap operasi baca yang mencapai node panas dapat meningkatkan latensi ekor. Lihat Pembacaan dan performa untuk mengetahui detailnya.
- Skema tabel Anda tidak didesain dengan benar. Untuk mendapatkan performa yang baik dari Bigtable, Anda harus mendesain skema yang memungkinkan distribusi operasi baca dan tulis secara merata di setiap tabel. Selain itu, hotspot di satu tabel dapat memengaruhi performa tabel lain dalam instance yang sama. Lihat Praktik terbaik desain skema untuk mengetahui informasi selengkapnya.
- Baris dalam tabel Bigtable Anda berisi data dalam jumlah besar. Estimasi performa yang ditampilkan di atas mengasumsikan bahwa setiap baris berisi data sebesar 1 KB. Anda dapat membaca dan menulis data dalam jumlah yang lebih besar per baris, tetapi meningkatkan jumlah data per baris juga akan mengurangi jumlah baris per detik.
- Baris dalam tabel Bigtable Anda berisi banyak sekali sel. Bigtable memerlukan waktu untuk memproses setiap sel dalam baris. Selain itu, setiap sel menambahkan beberapa overhead ke jumlah data yang disimpan dalam tabel dan dikirim melalui jaringan. Misalnya, jika Anda menyimpan data sebesar 1 KB (1.024 byte), akan jauh lebih hemat ruang jika menyimpan data tersebut dalam satu sel, daripada menyebarkan data ke 1.024 sel yang masing-masing berisi 1 byte. Jika Anda membagi data ke lebih banyak sel dari yang diperlukan, Anda mungkin tidak mendapatkan performa terbaik. Jika baris berisi banyak sel karena kolom berisi beberapa versi data dengan stempel waktu, pertimbangkan untuk hanya menyimpan nilai terbaru. Opsi lain untuk tabel yang sudah ada adalah mengirim penghapusan untuk semua versi sebelumnya dengan setiap penulisan ulang.
Cluster tidak memiliki cukup node. Node cluster menyediakan komputasi untuk cluster guna menangani pembacaan dan penulisan yang masuk, melacak penyimpanan, dan melakukan tugas pemeliharaan seperti pemadatan. Anda harus memastikan bahwa cluster memiliki node yang cukup untuk memenuhi batas yang direkomendasikan untuk komputasi dan penyimpanan. Gunakan alat pemantauan untuk memeriksa apakah cluster kelebihan beban.
- Komputasi - Jika CPU cluster Bigtable Anda dibebani secara berlebihan, menambahkan lebih banyak node dapat meningkatkan performa dengan menyebarkan beban kerja ke lebih banyak node.
- Penyimpanan - Jika penggunaan penyimpanan per node menjadi lebih tinggi dari yang direkomendasikan, Anda perlu menambahkan lebih banyak node untuk mempertahankan latensi dan throughput yang optimal, meskipun cluster memiliki cukup CPU untuk memproses permintaan. Hal ini karena meningkatkan penyimpanan per node akan meningkatkan jumlah pekerjaan pemeliharaan latar belakang per node. Untuk mengetahui detailnya, lihat Kompromi antara performa dan penggunaan penyimpanan.
Cluster Bigtable baru-baru ini diskalakan atau diperkecil. Setelah jumlah node dalam cluster ditingkatkan, perlu waktu hingga 20 menit dalam pemuatan sebelum Anda melihat peningkatan performa cluster yang signifikan. Bigtable menskalakan node dalam cluster berdasarkan beban yang dialaminya.
Saat Anda mengurangi jumlah node dalam cluster untuk menskalakan ke bawah, cobalah untuk tidak mengurangi ukuran cluster lebih dari 10% dalam periode 10 menit untuk meminimalkan lonjakan latensi.
Cluster Bigtable menggunakan disk HDD. Pada umumnya, cluster Anda harus menggunakan disk SSD, yang memiliki performa yang jauh lebih baik daripada disk HDD. Lihat Memilih antara penyimpanan SSD dan HDD untuk mengetahui detailnya.
Terjadi masalah dengan koneksi jaringan. Masalah jaringan dapat mengurangi throughput dan menyebabkan operasi baca dan tulis memerlukan waktu lebih lama dari biasanya. Secara khusus, Anda mungkin melihat masalah jika klien tidak berjalan di zona yang sama dengan cluster Bigtable, atau jika klien berjalan di luar Google Cloud.
Anda menggunakan replikasi, tetapi aplikasi Anda menggunakan library klien yang sudah tidak berlaku. Jika Anda mengamati peningkatan latensi setelah mengaktifkan replikasi, pastikan library klien Cloud Bigtable yang digunakan aplikasi Anda sudah yang terbaru. Library klien versi lama mungkin tidak dioptimalkan untuk mendukung replikasi. Lihat Library klien Cloud Bigtable untuk menemukan repositori GitHub library klien Anda, tempat Anda dapat memeriksa versi dan mengupgradenya jika perlu.
Anda mengaktifkan replikasi, tetapi tidak menambahkan node lain ke cluster. Dalam instance yang menggunakan replikasi, setiap cluster harus menangani pekerjaan replikasi selain beban yang diterima dari aplikasi. Cluster yang tidak memadai dapat menyebabkan peningkatan latensi. Anda dapat memverifikasinya dengan memeriksa diagram penggunaan CPU instance di konsol Google Cloud.
Karena workload yang berbeda dapat menyebabkan performa bervariasi, Anda harus melakukan pengujian dengan workload Anda sendiri untuk mendapatkan benchmark yang paling akurat.
Cold start dan QPS rendah
Cold start dan QPS rendah dapat meningkatkan latensi. Bigtable berperforma terbaik dengan tabel besar yang sering diakses. Oleh karena itu, jika Anda mulai mengirim permintaan setelah periode tanpa penggunaan (cold start), Anda mungkin akan melihat latensi yang tinggi saat Bigtable membuat ulang koneksi. Latensi juga lebih tinggi saat QPS rendah.
Jika QPS rendah, atau jika Anda tahu bahwa terkadang Anda akan mengirim permintaan ke tabel Bigtable setelah periode tidak aktif, Anda dapat mencoba strategi berikut untuk menjaga koneksi tetap aktif dan mencegah latensi tinggi ini.
- Kirim traffic buatan dengan kecepatan rendah ke tabel setiap saat.
- Konfigurasikan kumpulan koneksi untuk memastikan QPS yang stabil membuat kumpulan tetap aktif.
Selama periode QPS rendah, jumlah error yang ditampilkan Bigtable lebih relevan daripada persentase operasi yang menampilkan error.
Cold start pada waktu inisialisasi klien. Jika menggunakan versi klien Cloud Bigtable untuk Java yang lebih lama dari versi 2.18.0, Anda dapat mengaktifkan pembaruan saluran. Di versi yang lebih baru, pemuatan ulang saluran diaktifkan secara default. Memuatnya ulang akan melakukan dua hal:
- Saat diinisialisasi, klien akan menyiapkan saluran sebelum mengirim permintaan pertama.
- Server memutuskan koneksi yang berumur panjang setiap jam. Pemantapan channel akan mengganti saluran yang akan berakhir masa berlakunya secara proaktif.
Namun, hal ini tidak akan membuat channel tetap aktif jika ada periode tidak aktif.
Cara Bigtable mengoptimalkan data Anda dari waktu ke waktu
Untuk menyimpan data pokok untuk setiap tabel, Bigtable membagi data menjadi beberapa tablet, yang dapat dipindahkan di antara node dalam cluster Bigtable Anda. Metode penyimpanan ini memungkinkan Bigtable menggunakan dua strategi berbeda untuk mengoptimalkan data Anda dari waktu ke waktu:
- Bigtable mencoba menyimpan jumlah data yang kira-kira sama di setiap node Bigtable.
- Bigtable mencoba mendistribusikan operasi baca dan tulis secara merata di seluruh semua node Bigtable.
Terkadang strategi ini saling bertentangan. Misalnya, jika satu baris tablet dibaca sangat sering, Bigtable mungkin menyimpan tablet tersebut di node-nya sendiri, meskipun hal ini menyebabkan beberapa node menyimpan lebih banyak data daripada yang lain.
Sebagai bagian dari proses ini, Bigtable juga dapat membagi tablet menjadi dua tablet yang lebih kecil atau lebih, baik untuk mengurangi ukuran tablet maupun untuk mengisolasi baris yang sering digunakan dalam tablet yang ada.
Bagian berikut menjelaskan setiap strategi ini secara lebih mendetail.
Mendistribusikan jumlah data di seluruh node
Saat Anda menulis data ke tabel Bigtable, Bigtable akan mengelompokkan data tabel ke dalam tablet. Setiap tablet berisi rentang baris yang berdekatan dalam tabel.
Jika Anda telah menulis data kurang dari beberapa GB ke tabel, Bigtable akan menyimpan semua tablet di satu node dalam cluster Anda:
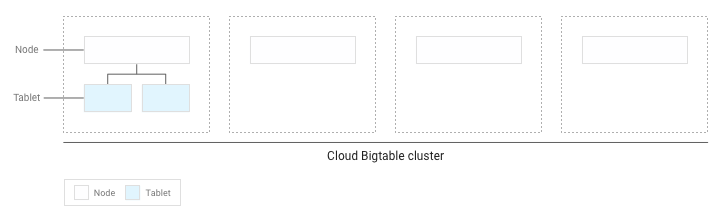
Seiring bertambahnya tablet, Bigtable akan memindahkan beberapa tablet ke node lain dalam cluster sehingga jumlah data seimbang secara lebih merata di seluruh cluster:
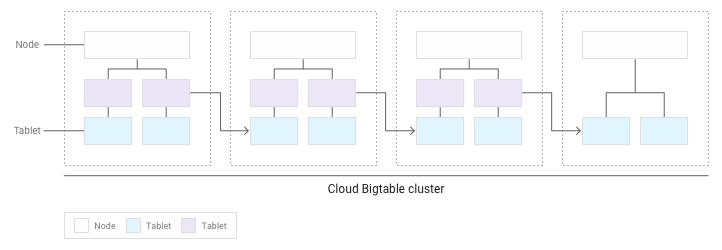
Mendistribusikan operasi baca dan tulis secara merata di seluruh node
Jika Anda telah mendesain skema dengan benar, operasi baca dan tulis harus didistribusikan secara merata di seluruh tabel. Namun, ada beberapa kasus saat Anda tidak dapat menghindari akses ke baris tertentu lebih sering daripada baris lainnya. Bigtable membantu Anda menangani kasus ini dengan mempertimbangkan pembacaan dan penulisan saat menyeimbangkan tablet di seluruh node.
Misalnya, 25% operasi baca ditujukan ke sejumlah kecil tablet dalam cluster, dan operasi baca tersebar secara merata di semua tablet lainnya:
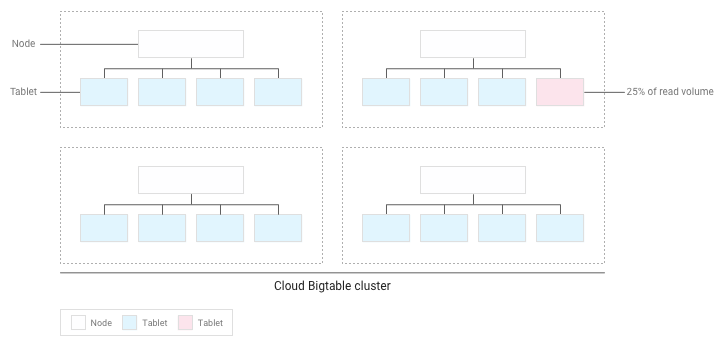
Bigtable akan mendistribusikan ulang tablet yang ada sehingga operasi baca tersebar sesecara merata di seluruh cluster:
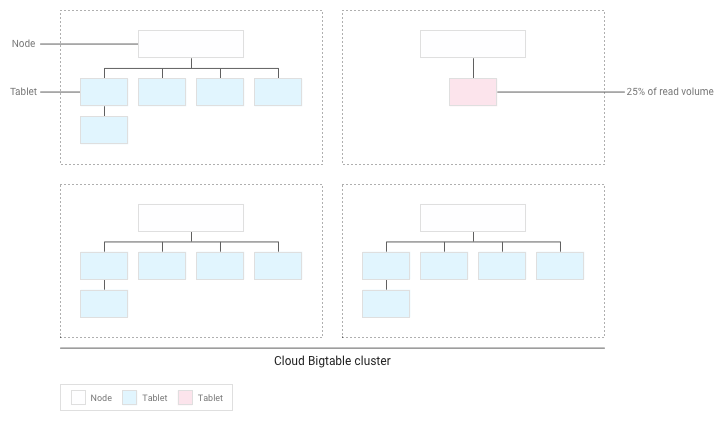
Menguji performa dengan Bigtable
Jika Anda menjalankan pengujian performa untuk aplikasi yang bergantung pada Bigtable, ikuti panduan ini saat Anda merencanakan dan menjalankan pengujian:
- Uji dengan data yang memadai.
- Jika tabel di instance produksi Anda berisi total 100 GB data atau kurang per node, lakukan pengujian dengan tabel yang memiliki jumlah data yang sama.
- Jika tabel berisi lebih dari 100 GB data per node, uji dengan tabel yang berisi minimal 100 GB data per node. Misalnya, jika instance produksi Anda memiliki satu cluster empat node, dan tabel dalam instance tersebut berisi total 1 TB data, jalankan pengujian menggunakan tabel minimal 400 GB.
- Uji dengan satu tabel.
- Tetap di bawah penggunaan penyimpanan yang direkomendasikan per node. Untuk mengetahui detailnya, lihat Penggunaan penyimpanan per node.
- Sebelum melakukan pengujian, jalankan pra-pengujian berat selama beberapa menit. Langkah ini memberi Bigtable kesempatan untuk menyeimbangkan data di seluruh node Anda berdasarkan pola akses yang diamatinya.
- Jalankan pengujian selama minimal 10 menit. Langkah ini memungkinkan Bigtable mengoptimalkan data Anda lebih lanjut, dan membantu memastikan bahwa Anda akan menguji pembacaan dari disk serta pembacaan yang di-cache dari memori.
Memecahkan masalah performa
Jika Anda merasa Bigtable mungkin menyebabkan bottleneck performa di aplikasi, pastikan untuk memeriksa semua hal berikut:
- Lihat pemindaian Key Visualizer untuk tabel Anda. Alat Key Visualizer untuk Bigtable menghasilkan data pemindaian baru setiap 15 menit yang menunjukkan pola penggunaan untuk setiap tabel dalam cluster. Key Visualizer memungkinkan Anda memeriksa apakah pola penggunaan Anda menyebabkan hasil yang tidak diinginkan, seperti hotspot pada baris tertentu atau penggunaan CPU yang berlebihan. Pelajari cara memulai Key Visualizer.
- Coba komentari kode yang melakukan operasi baca dan tulis Bigtable. Jika masalah performa hilang, Anda mungkin menggunakan Bigtable dengan cara yang menghasilkan performa yang kurang optimal. Jika masalah performa berlanjut, masalah tersebut mungkin tidak terkait dengan Bigtable.
Pastikan Anda membuat klien sesedikit mungkin. Membuat klien untuk Bigtable adalah operasi yang relatif mahal. Oleh karena itu, Anda harus membuat jumlah klien sekecil mungkin:
- Jika Anda menggunakan replikasi, atau jika Anda menggunakan profil aplikasi untuk mengidentifikasi berbagai jenis traffic ke instance, buat satu klien per profil aplikasi dan bagikan klien di seluruh aplikasi Anda.
- Jika Anda tidak menggunakan profil aplikasi atau replikasi, buat satu klien dan bagikan di seluruh aplikasi Anda.
Jika menggunakan klien HBase untuk Java, Anda membuat objek
Connection, bukan klien, sehingga Anda harus membuat koneksi sesedikit mungkin.Pastikan Anda membaca dan menulis banyak baris yang berbeda dalam tabel. Bigtable berperforma terbaik jika operasi baca dan tulis didistribusikan secara merata di seluruh tabel, yang membantu Bigtable mendistribusikan beban kerja di semua node dalam cluster Anda. Jika operasi baca dan tulis tidak dapat tersebar di semua node Bigtable, performa akan menurun.
Jika Anda mendapati bahwa Anda hanya membaca dan menulis sejumlah kecil baris, Anda mungkin perlu mendesain ulang skema agar operasi baca dan tulis didistribusikan secara lebih merata.
Pastikan Anda melihat performa yang kira-kira sama untuk operasi baca dan menulis. Jika Anda mendapati bahwa operasi baca jauh lebih cepat daripada operasi tulis, Anda mungkin mencoba membaca kunci baris yang tidak ada, atau rentang kunci baris yang besar yang hanya berisi sejumlah kecil baris.
Untuk membuat perbandingan yang valid antara operasi baca dan tulis, Anda harus menargetkan setidaknya 90% operasi baca untuk menampilkan hasil yang valid. Selain itu, jika Anda membaca rentang kunci baris yang besar, ukur performa berdasarkan jumlah baris yang sebenarnya dalam rentang tersebut, bukan jumlah maksimum baris yang dapat ada.
Gunakan jenis permintaan tulis yang tepat untuk data Anda. Memilih cara optimal untuk menulis data membantu mempertahankan performa yang tinggi.
Periksa latensi untuk satu baris. Jika Anda mengamati latensi yang tidak terduga saat mengirim permintaan
ReadRows, Anda dapat memeriksa latensi baris pertama permintaan untuk mempersempit penyebabnya. Secara default, latensi keseluruhan untuk permintaanReadRowsmencakup latensi untuk setiap baris dalam permintaan serta waktu pemrosesan di antara baris. Jika latensi secara keseluruhan tinggi, tetapi latensi baris pertama rendah, hal ini menunjukkan bahwa latensi disebabkan oleh jumlah permintaan atau waktu pemrosesan, bukan oleh masalah pada Bigtable.Jika menggunakan library klien Bigtable untuk Java, Anda dapat melihat metrik
read_rows_first_row_latencydi Metrics Explorer konsol Google Cloud setelah mengaktifkan metrik sisi klien.Gunakan profil aplikasi terpisah untuk setiap beban kerja. Jika Anda mengalami masalah performa setelah menambahkan workload baru, buat profil aplikasi baru untuk workload baru. Kemudian, Anda dapat memantau metrik untuk profil aplikasi secara terpisah untuk memecahkan masalah lebih lanjut. Lihat Cara kerja profil aplikasi untuk mengetahui detail tentang alasan praktik terbaik adalah menggunakan beberapa profil aplikasi.
Aktifkan metrik sisi klien. Anda dapat menyiapkan metrik sisi klien untuk membantu mengoptimalkan dan memecahkan masalah performa. Misalnya, karena Bigtable berfungsi paling baik dengan QPS tinggi yang didistribusikan secara merata, peningkatan latensi P100 (maks) untuk sebagian kecil permintaan tidak selalu menunjukkan masalah performa yang lebih besar dengan Bigtable. Metrik sisi klien dapat memberi Anda insight tentang bagian siklus proses permintaan yang mungkin menyebabkan latensi.
Langkah selanjutnya
- Pelajari cara mendesain skema Bigtable.
- Cari tahu cara memantau performa Bigtable.
- Pelajari cara memecahkan masalah Visualisator Kunci.
- Lihat kode contoh untuk menambahkan node secara terprogram ke cluster Bigtable.