Entender o desempenho
Esta página descreve o desempenho aproximado que o Bigtable pode oferecer em condições ideais, os fatores que podem afetar esse desempenho e dicas para testar e solucionar problemas de desempenho do Bigtable.
Desempenho em cargas de trabalho típicas
O Bigtable fornece um desempenho altamente previsível que pode ser escalonado linearmente. Ao evitar as causas de desempenho mais lento descritas abaixo, cada nó do Bigtable pode fornecer a seguinte capacidade aproximada, dependendo do tipo de armazenamento usado pelo cluster:
| Tipo de armazenamento | Leituras | Gravações | Verificações | ||
|---|---|---|---|---|---|
| SSD | até 17.000 linhas por segundo | ou | até 14.000 linhas por segundo | ou | até 220 MB/s |
| HDD | até 500 linhas por segundo | ou | até 10.000 linhas por segundo | ou | até 180 MB/s |
Essas estimativas pressupõem que tenha 1 KB de dados em cada linha.
Em geral, o desempenho de um cluster aumenta linearmente à medida que nós são adicionados ao cluster. Por exemplo, se você criar um cluster SSD com 10 nós, ele aceitará até 140.000 linhas por segundo para uma carga de trabalho típica somente leitura ou somente gravação.
Planejar a capacidade do Bigtable
Ao planejar os clusters do Bigtable, decida se você quer otimizar a latência ou a capacidade. Por exemplo, para um job de processamento de dados em lote, você pode se preocupar mais com a capacidade e menos com a latência. Por outro lado, para um serviço on-line que atende solicitações de usuários, talvez seja necessário priorizar uma latência mais baixa em vez da capacidade. Você pode alcançar os números na seção Performance para cargas de trabalho típicas ao otimizar a capacidade.
Uso da CPU
Em quase todos os casos, recomendamos o uso do escalonamento automático, que permite que o Bigtable adicione ou remova nós com base no seu uso. Para mais informações, consulte Escalonamento automático.
Siga as diretrizes a seguir ao configurar os destinos de escalonamento automático ou se você escolher a alocação manual de nós. Essas diretrizes se aplicam independentemente do número de clusters que a instância tem. Para um cluster com alocação manual de nós, é necessário monitorar a utilização da CPU do cluster com o objetivo de manter a utilização abaixo desses valores para um desempenho ideal.
| Meta de otimização | Utilização máxima da CPU |
|---|---|
| Capacidade | 90% |
| Latência | 60% |
Para mais informações sobre o monitoramento, consulte Monitoramento.
Uso do armazenamento
Outra consideração no planejamento de capacidade é o armazenamento. A capacidade de armazenamento de um cluster é determinada pelo tipo de armazenamento e pelo número de nós no cluster. Quando a quantidade de dados armazenados em um cluster aumenta, o Bigtable otimiza o armazenamento distribuindo a quantidade de dados em todos os nós do cluster.
É possível determinar o uso de armazenamento por nó dividindo a utilização de armazenamento (bytes) do cluster pelo número de nós no cluster. Por exemplo, considere um cluster que tenha três nós do HDD e 9 TB de dados. Cada nó armazena cerca de 3 TB, o que é 18,75% do armazenamento HDD por limite de 16 TB.
Quando a utilização do armazenamento aumenta, as cargas de trabalho podem apresentar um aumento na latência do processamento de consultas, mesmo que o cluster tenha nós suficientes para atender às necessidades gerais da CPU. Isso acontece porque, quanto maior o armazenamento por nó, mais trabalho em segundo plano, como indexação, é necessário. O aumento no trabalho em segundo plano para processar mais armazenamento pode resultar em maior latência e menor capacidade.
Comece com as seguintes etapas ao configurar as configurações de escalonamento automático. Se você escolher a alocação manual de nós, monitore a utilização de armazenamento do cluster e adicione ou remova nós para manter o seguinte.
| Meta de otimização | Uso máximo do armazenamento |
|---|---|
| Capacidade | 70% |
| Latência | 60% |
Para mais informações, consulte Armazenamento por nó.
Execute suas cargas de trabalho típicas no Bigtable
Sempre execute suas próprias cargas de trabalho típicas em um cluster do Bigtable ao planejar a capacidade. Assim, você descobrirá a melhor alocação de recursos para seus aplicativos.
O PerfKit Benchmarker do Google usa o YCSB para comparar serviços de nuvem. Siga o
tutorial do PerfKitBenchmarker para o Bigtable
e crie testes para suas próprias cargas de trabalho. Ao fazer isso, ajuste os
parâmetros nos arquivos de configuração de comparativo de mercado yaml para garantir que o
comparativo de mercado gerado reflita as seguintes características na sua produção:
- Tamanho total da tabela. Pode ser proporcional, mas use pelo menos 100 GB.
- Formato de dados de linha (tamanho da chave de linha, número de colunas, tamanhos de dados da linha etc.)
- Padrão de acesso de dados (distribuição de chaves de linha)
- Combinação entre leituras e gravações
Consulte Como testar o desempenho com o Bigtable para conhecer mais práticas recomendadas.
Causas para um desempenho mais lento
Existem vários fatores que podem fazer com que o Cloud Bigtable apresente um desempenho mais lento do que o estimado acima:
- Você lê um grande número de intervalos ou chaves de linha não contíguos em uma única solicitação de leitura. O Bigtable verifica a tabela e lê as linhas solicitadas sequencialmente. Essa falta de paralelismo afeta a latência geral, e qualquer leitura que atinja um nó quente pode aumentar a latência de cauda. Consulte Leituras e desempenho para mais detalhes.
- O esquema da tabela não foi criado corretamente. Para conseguir um bom desempenho do Bigtable, é essencial projetar um esquema que possibilite distribuir leituras e gravações igualmente entre todas as tabelas. Além disso, os pontos de acesso em uma tabela podem afetar o desempenho de outras tabelas na mesma instância. Consulte Práticas recomendadas de design do esquema para mais informações.
- As linhas na tabela do Bigtable contêm grande quantidade de dados. As estimativas de desempenho mostradas acima pressupõem que tenha 1 KB de dados em cada linha. É possível ler e gravar grandes quantidades de dados por linha, mas aumentar essa quantidade também reduzirá o número de linhas por segundo.
- As linhas na tabela do Bigtable contêm um grande número de células. Leva tempo para que o Bigtable processe cada célula de uma linha. Além disso, cada célula adiciona uma sobrecarga à quantidade de dados armazenados em sua tabela e enviados pela rede. Por exemplo, se você estiver armazenando 1 KB (1.024 bytes) de dados, será muito mais eficiente armazenar esses dados em uma única célula em vez de distribuí-los por 1.024 células, cada uma contendo 1 byte. Se você utilizar mais células que o necessário para armazenar seus dados, talvez não consiga atingir o melhor desempenho possível. Se as linhas tiverem um grande número de células por existirem várias versões de dados com carimbo de data/hora nas colunas, pense em manter apenas o valor mais recente. Outra opção para uma tabela que já existe é enviar uma exclusão de todas as versões anteriores a cada regravação.
O cluster não tem nenhum nó. Os nós de um cluster fornecem computação para que o cluster processe leituras e gravações de entrada, acompanhe o armazenamento e realize tarefas de manutenção, como compactação. É necessário garantir que o cluster tenha nós suficientes para atender aos limites recomendados de computação e armazenamento. Use as ferramentas de monitoramento para verificar se o cluster está sobrecarregado.
- Computação: se a CPU do cluster do Bigtable estiver sobrecarregada, adicione mais nós para melhorar o desempenho ao distribuir a carga de trabalho por mais nós.
- Armazenamento: se o uso do armazenamento por nó tiver sido maior que o recomendado, adicione mais nós para manter a latência e a capacidade ideais, mesmo que o armazenamento cluster tenha CPU suficiente para processar solicitações. Isso ocorre porque o aumento do armazenamento por nó aumenta a quantidade de trabalhos de manutenção em segundo plano por nó. Para mais detalhes, consulte Vantagens e desvantagens entre o uso do armazenamento e o desempenho.
O cluster do Bigtable foi ampliado ou reduzido recentemente. Depois que o número de nós em um cluster é aumentado, pode levar até 20 minutos sob carga para que você note uma melhoria significativa no desempenho do cluster. O Bigtable escalona os nodes em um cluster com base na carga que ele vivencia.
Ao diminuir o número de nós de um cluster para reduzir o escalonamento, tente não diminuir o tamanho do cluster em mais de 10% em um período de 10 minutos para minimizar os picos de latência.
O cluster do Bigtable usa discos HDD. Na maioria dos casos, o cluster precisa usar discos SSD, porque eles apresentam um desempenho significativamente melhor do que os discos HDD. Para saber mais, consulte Como escolher entre armazenamento SSD e HDD.
A conexão com a rede apresenta problemas. Problemas na rede podem reduzir a capacidade e fazer com que as leituras e gravações demorem mais que o normal. Em particular, podem surgir problemas se os clientes não estiverem sendo executados na mesma zona do cluster do Bigtable ou se estiverem sendo executados fora do Google Cloud.
Você está usando a replicação, mas o aplicativo está usando uma biblioteca de cliente desatualizada. Se você observar uma latência maior depois de ativar a replicação, verifique se a biblioteca de cliente do Cloud Bigtable que o aplicativo está usando está atualizada. As versões mais antigas das bibliotecas de cliente podem não ser otimizadas para oferecer suporte à replicação. Consulte Bibliotecas de cliente do Cloud Bigtable para encontrar o repositório do GitHub da biblioteca de clientes, em que é possível verificar a versão e fazer upgrade se necessário.
Você ativou a replicação, mas não adicionou nós aos clusters. Em uma instância que usa replicação, cada cluster precisa processar o trabalho de replicação, além da carga recebida dos aplicativos. Clusters subprovisionados podem causar maior latência. Para verificar isso, confira os gráficos de uso da CPU da instância no console do Google Cloud .
Como cargas de trabalho diferentes podem provocar variações no desempenho, faça alguns testes com as próprias cargas de trabalho para conseguir parâmetros de comparação mais precisos.
Inicializações a frio e QPS baixo
As inicializações a frio e o QPS baixo podem aumentar a latência. O Bigtable tem um desempenho melhor com tabelas grandes que são acessadas com frequência. Por esse motivo, se você começar a enviar solicitações após um período sem uso (uma inicialização a frio), poderá observar alta latência enquanto o Bigtable restabelece as conexões. A latência também é maior quando o QPS é baixo.
Se a QPS for baixa ou se você souber que às vezes vai enviar solicitações para uma tabela do Bigtable após um período de inatividade, tente as estratégias a seguir para manter a conexão ativa e evitar essa alta latência.
- Sempre envie uma baixa taxa de tráfego artificial para a tabela.
- Configurar o pool de conexões para garantir que o QPS constante mantenha o pool ativo.
Durante períodos de QPS baixo, o número de erros retornados pelo Bigtable é mais relevante do que a porcentagem de operações que retornam erros.
Inicialização a frio no momento da inicialização do cliente. Se você estiver usando uma versão do cliente do Cloud Bigtable para Java anterior à 2.18.0, ative a atualização do canal. Nas versões mais recentes, a atualização do canal é ativada por padrão. A atualização do canal faz duas coisas:
- Quando o cliente é inicializado, ele prepara o canal antes de enviar as primeiras solicitações.
- O servidor desconecta as conexões de longa duração a cada hora. A preparação do canal troca de forma preventiva os canais que estão prestes a expirar.
No entanto, isso não mantém o canal ativo quando há períodos de inatividade.
Como o Bigtable otimiza os dados ao longo do tempo
Para armazenar os dados subjacentes de cada tabela, o Bigtable fragmenta os dados em vários blocos, que podem ser movidos entre os nós do cluster do Bigtable. Com esse método de armazenamento, o Bigtable pode usar duas estratégias diferentes para otimizar os dados ao longo do tempo:
- O Bigtable tenta armazenar aproximadamente a mesma quantidade de dados em cada nó do Bigtable.
- O Bigtable tenta distribuir igualmente as leituras e gravações em todos os nós do Bigtable.
Às vezes, essas estratégias entram em conflito. Por exemplo, se as linhas de um bloco são lidas com uma frequência muito grande, talvez o Bigtable armazene esse bloco em um nó próprio, mesmo que alguns nós armazenem mais dados do que outros.
Como parte desse processo, também há a possibilidade de o Bigtable dividir um bloco em dois ou mais nós menores, seja para reduzir o tamanho do bloco, seja para isolar as linhas com muito acesso dentro de um bloco existente.
As seções a seguir explicam cada uma das estratégias com mais detalhes.
Distribuição da quantidade de dados pelos nós
Ao gravar dados em uma tabela do Bigtable, o Bigtable fragmenta os dados da tabela em tablets. Cada bloco contém um intervalo contíguo de filas na tabela.
Se você tiver gravado menos de vários GB de dados na tabela, o Bigtable armazenará todos os blocos em um único nó dentro do cluster:
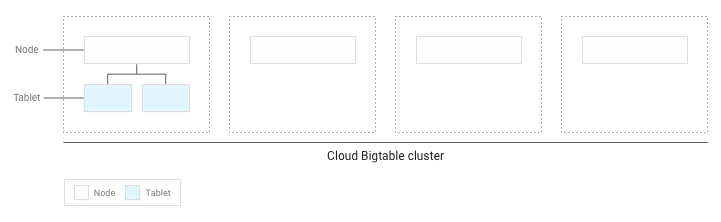
À medida que os blocos vão se acumulando, o Bigtable move alguns para outros nós no cluster. Assim, a quantidade de dados é balanceada de forma uniforme no cluster:
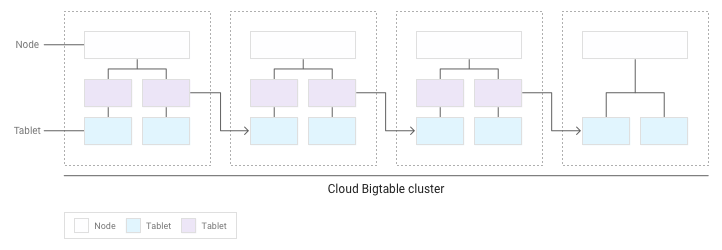
Distribuição uniforme de leituras e gravações nos nós
Se você criou o esquema corretamente, as leituras e gravações serão distribuídas de forma uniforme por toda a tabela. No entanto, em alguns casos, não é possível evitar que algumas filas sejam acessadas com mais frequência que outras. O Bigtable ajuda você a lidar com esses casos ao considerar as leituras e gravações quando faz o balanceamento dos blocos pelos nós.
Por exemplo, vamos supor que 25% das leituras têm como destino um número pequeno de blocos dentro de um cluster e o restante está espalhado de forma uniforme nos outros blocos:
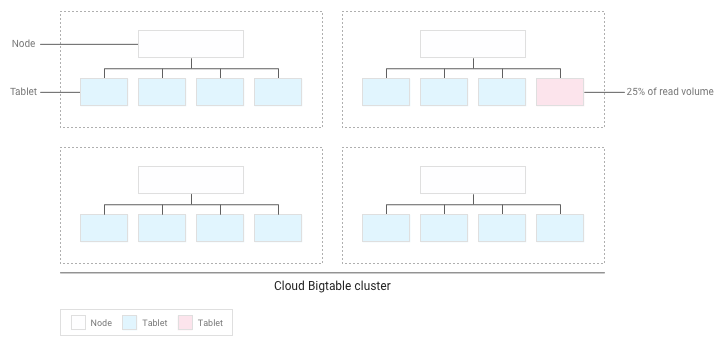
O Bigtable redistribuirá os blocos existentes para que as leituras sejam espalhadas da maneira mais uniforme possível por todo o cluster:
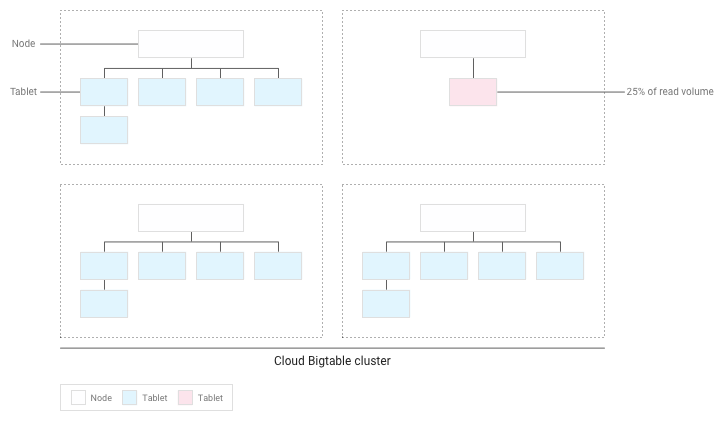
Testar o desempenho com o Bigtable
Se você estiver executando um teste de desempenho para um aplicativo que depende do Bigtable, siga estas diretrizes ao planejar e executar o teste:
- Teste com dados suficientes.
- Se as tabelas na instância de produção contiverem um total de 100 GB de dados ou menos por nó, teste com uma tabela da mesma quantidade de dados.
- Se as tabelas contiverem mais de 100 GB de dados por nó, teste com uma tabela que contenha pelo menos 100 GB de dados por nó. Por exemplo, se a instância de produção tiver um cluster de quatro nós e as tabelas contiverem um total de 1 TB de dados, execute o teste usando uma tabela de pelo menos 400 GB.
- Teste com uma única tabela.
- Permaneça abaixo da utilização de armazenamento recomendada por nó. Veja mais detalhes em Uso do armazenamento por nó.
- Antes de iniciar o teste, execute um teste preliminar intenso por vários minutos. Essa etapa dá ao Bigtable uma oportunidade de balancear os dados por todos os nós, com base nos padrões de acesso observados.
- Execute o teste por pelo menos 10 minutos. Essa etapa permite que o Bigtable otimize ainda mais os dados e ajuda a garantir que serão testadas tanto as leituras do disco quanto as leituras contidas em caches da memória.
Resolver problemas de desempenho
Se você achar que o Bigtable pode criar um afunilamento de desempenho no aplicativo, realize estas verificações:
- Observe os verificações do Key Visualizer para sua tabela. A ferramenta Key Visualizer para Bigtable gera novos dados de verificação a cada 15 minutos que mostram os padrões de uso de cada tabela em um cluster. Com o Key Visualizer é possível verificar se os padrões de uso estão causando resultados indesejáveis, como pontos de acesso em linhas específicas ou uso excessivo da CPU. Veja como começar a usar o Key Visualizer.
- Converta em comentário o código que realiza as leituras e gravações no Bigtable. Se o problema de desempenho desaparecer, isso significa que a forma como você usa o Bigtable resulta em um desempenho abaixo do ideal. Se o problema de desempenho persistir, é porque o problema provavelmente não tem relação com o Bigtable.
Verifique se você está criando o menor número de clientes possível. Criar um cliente para o Bigtable é uma operação relativamente cara. Portanto, crie o menor número possível de clientes:
- Se você usa replicação ou perfis de aplicativo para identificar diferentes tipos de tráfego para sua instância, crie um cliente por perfil de app e compartilhe os clientes em todo o aplicativo.
- Caso você não use replicação ou perfis de aplicativo, crie um único cliente e compartilhe-o em todo o aplicativo.
Se estiver usando o cliente HBase para Java, crie um objeto
Connectionem vez de um cliente, dessa forma, você criará o menor número de conexões possível.Verifique se as leituras e gravações são realizadas em várias linhas diferentes da tabela. O Bigtable tem um desempenho melhor quando as leituras e gravações são distribuídas de forma uniforme por toda a tabela. Isso ajuda o Bigtable a distribuir a carga de trabalho por todos os nós do cluster. Se não for possível espalhar as leituras e gravações por todos os nós do Bigtable, o desempenho será prejudicado.
Caso perceba estar lendo e gravando um número pequeno de linhas, você precisa reprojetar o esquema. Dessa maneira, as leituras e as gravações são distribuídas mais igualmente.
Verifique se as leituras e gravações têm aproximadamente o mesmo desempenho. Caso perceba que as leituras são mais rápidas que as gravações, é possível que você esteja tentando ler chaves de linha inexistentes ou um grande intervalo de chaves de linha que contêm apenas um pequeno número de linhas.
Para fazer uma comparação válida entre leituras e gravações, é necessário que pelo menos 90% das leituras retornem resultados válidos. Além disso, se você estiver realizando a leitura de um intervalo grande de chaves de linha, meça o desempenho com base no número real de linhas no intervalo, em vez de usar o número máximo de linhas que podem existir.
Use o tipo certo de solicitação de gravação para seus dados. A escolha da melhor forma de gravar seus dados ajuda a manter um alto desempenho.
Verifique a latência de uma única linha. Se você observar uma latência inesperada ao enviar solicitações
ReadRows, poderá verificar a latência da primeira linha da solicitação para restringir a causa. Por padrão, a latência geral de uma solicitaçãoReadRowsinclui a latência de cada linha nela, bem como o tempo de processamento entre as linhas. Se a latência geral for alta, mas a primeira latência de linha for baixa, pode significar que a latência é causada pelo número de solicitações ou pelo tempo de processamento, não por um problema com o Bigtable.Se você estiver usando a biblioteca de cliente do Bigtable para Java, será possível visualizar a métrica
read_rows_first_row_latencyno Google Cloud Explorador de métricas do console após a ativação de métricas do lado do cliente.Use um perfil de app separado para cada carga de trabalho. Se você tiver problemas de desempenho após adicionar uma nova carga de trabalho, crie um novo perfil de aplicativo para ela. Em seguida, é possível monitorar as métricas dos perfis de app separadamente para solucionar problemas. Consulte Como os perfis de app funcionam para conferir detalhes sobre por que é uma prática recomendada usar vários perfis.
Ative as métricas do lado do cliente. É possível configurar métricas do lado do cliente para ajudar a otimizar e resolver problemas de desempenho. Por exemplo, como o Bigtable funciona melhor com QPS distribuído e alto, o aumento da latência P100 (máxima) para uma pequena porcentagem de solicitações não indica necessariamente um maior problema de desempenho com o Bigtable. As métricas do lado do cliente podem fornecer insights sobre qual parte do ciclo de vida da solicitação pode estar causando latência.
O aplicativo precisa consumir as solicitações de leitura antes do tempo limite. Se o aplicativo processar dados durante um fluxo de leitura, você corre o risco de o tempo de solicitação expirar antes de receber todas as respostas da chamada. Isso resulta em uma mensagem
ABORTED. Se esse erro aparecer, reduza a quantidade de processamento durante o fluxo de leitura.
A seguir
- Saiba como projetar um esquema do Bigtable.
- Aprenda a monitorar o desempenho do Bigtable.
- Saiba como solucionar problemas com o Key Visualizer.
- Visualize o código da amostra para adicionar nós de maneira programática a um cluster do Bigtable.