Descrizione delle prestazioni
Questa pagina descrive le prestazioni approssimative che Bigtable può fornire in condizioni ottimali, i fattori che possono influire sulle prestazioni e i suggerimenti per testare e risolvere i problemi di prestazioni di Bigtable.
Prestazioni per carichi di lavoro tipici
Bigtable offre prestazioni altamente prevedibili e scalabili in modo lineare. Se eviti le cause di prestazioni più lente descritte di seguito, ogni nodo Bigtable può fornire il seguente throughput approssimativo, a seconda del tipo di spazio di archiviazione utilizzato dal cluster:
| Tipo di archiviazione | Letture | Scritture | Scansioni | ||
|---|---|---|---|---|---|
| SSD | fino a 17.000 righe al secondo | o | fino a 14.000 righe al secondo | o | fino a 220 MB/s |
| HDD | fino a 500 righe al secondo | o | fino a 10.000 righe al secondo | o | fino a 180 MB/s |
Queste stime presuppongono che ogni riga contenga 1 KB di dati.
In generale, le prestazioni di un cluster aumentano in modo lineare man mano che aggiungi nodi al cluster. Ad esempio, se crei un cluster SSD con 10 nodi, il cluster può supportare fino a 140.000 righe al secondo per un tipico carico di lavoro di sola lettura o di sola scrittura.
Pianificare la capacità di Bigtable
Quando pianifichi i cluster Bigtable, decidi se ottimizzare per latenza o throughput. Ad esempio, per un job di elaborazione dei dati in batch, potresti essere più interessato alla velocità effettiva e meno alla latenza. Al contrario, per un servizio online che gestisce le richieste degli utenti, potresti dare la priorità alla latenza inferiore rispetto al throughput. Puoi ottenere i numeri riportati nella sezione Rendimento per carichi di lavoro tipici quando esegui l'ottimizzazione per il throughput.
Utilizzo CPU
Nella maggior parte dei casi, ti consigliamo di utilizzare la scalabilità automatica, che consente a Bigtable di aggiungere o rimuovere nodi in base al tuo utilizzo. Per ulteriori informazioni, consulta la sezione Scalabilità automatica.
Segui le linee guida riportate di seguito quando configuri i target di scalabilità automatica o se scegli l'allocazione manuale dei nodi. Queste linee guida si applicano indipendentemente dal numero di cluster della tua istanza. Per un cluster con allocazione manuale dei nodi, devi monitorare l'utilizzo della CPU del cluster con l'obiettivo di mantenere l'utilizzo della CPU inferiore a questi valori per un rendimento ottimale.
| Obiettivo di ottimizzazione | Utilizzo massimo della CPU |
|---|---|
| Velocità effettiva | 90% |
| Latenza | 60% |
Per ulteriori informazioni sul monitoraggio, consulta Monitoraggio.
Utilizzo archiviazione
Un altro aspetto da considerare nella pianificazione della capacità è lo spazio di archiviazione. La capacità di archiviazione di un cluster è determinata dal tipo di archiviazione e dal numero di nodi nel cluster. Quando la quantità di dati archiviati in un cluster aumenta, Bigtable ottimizza lo spazio di archiviazione distribuendo la quantità di dati su tutti i nodi del cluster.
Puoi determinare l'utilizzo dello spazio di archiviazione per nodo dividendo l'utilizzo dello spazio di archiviazione (byte) del cluster per il numero di nodi del cluster. Ad esempio, prendi in considerazione un cluster con tre nodi HDD e 9 TB di dati. Ogni nodo immagazzina circa 3 TB, ovvero il 18,75% del limite di spazio di archiviazione HDD per nodo di 16 TB.
Quando l'utilizzo dello spazio di archiviazione aumenta, i workload possono registrare un aumento della latenza di elaborazione delle query anche se il cluster dispone di un numero di nodi sufficiente per soddisfare le esigenze complessive della CPU. Questo perché, maggiore è lo spazio di archiviazione per nodo, maggiore è il lavoro in background, come l'indicizzazione, richiesto. L'aumento del lavoro in background per gestire più spazio di archiviazione può comportare una latenza più elevata e una minore velocità in uscita.
Quando configuri le impostazioni di scalabilità automatica, inizia con quanto segue. Se scelgo l'allocazione manuale dei nodi, monitora l'utilizzo dello spazio di archiviazione del cluster e aggiungi o rimuovi i nodi per mantenere quanto segue.
| Obiettivo di ottimizzazione | Utilizzo massimo dello spazio di archiviazione |
|---|---|
| Velocità effettiva | 70% |
| Latenza | 60% |
Per ulteriori informazioni, consulta Spazio di archiviazione per nodo.
Esegui i tuoi carichi di lavoro tipici su Bigtable
Esegui sempre i tuoi carichi di lavoro tipici su un cluster Bigtable quando pianifichi la capacità, in modo da poter determinare la migliore allocazione delle risorse per le tue applicazioni.
PerfKit Benchmarker di Google utilizza YCSB per eseguire il benchmark dei servizi cloud. Puoi seguire il
tutorial su PerfKitBenchmarker per Bigtable
per creare test per i tuoi carichi di lavoro. A questo scopo, devi ottimizzare i parametri nei file di configurazione del benchmarking yaml per assicurarti che il benchmark generato rifletta le seguenti caratteristiche nella produzione:
- Dimensioni totali della tabella. Può essere proporzionale, ma utilizza almeno 100 GB.
- Forma dei dati di riga (dimensioni della chiave di riga, numero di colonne, dimensioni dei dati di riga e così via)
- Pattern di accesso ai dati (distribuzione delle chiavi di riga)
- Combinazione di letture e scritture
Per ulteriori best practice, consulta Testare le prestazioni con Bigtable.
Cause di prestazioni più lente
Esistono diversi fattori che possono causare un funzionamento più lento di Bigtable rispetto alle stime riportate sopra:
- Leggi un numero elevato di chiavi di riga o intervalli di righe non contigui in una singola richiesta di lettura. Bigtable esegue la scansione della tabella e legge le righe richieste in sequenza. Questa mancanza di parallelismo influisce sulla latenza complessiva e qualsiasi lettura che colpisce un nodo hot può aumentare la latenza di coda. Per informazioni dettagliate, consulta Letture e rendimento.
- Lo schema della tabella non è progettato correttamente. Per ottenere un buon rendimento da Bigtable, è essenziale progettare uno schema che consenta di distribuire le letture e le scritture in modo uniforme in ogni tabella. Inoltre, gli hotspot in una tabella possono influire sulle prestazioni di altre tabelle nella stessa istanza. Per saperne di più, consulta le best practice per la progettazione degli schemi.
- Le righe della tabella Bigtable contengono grandi quantità di dati. Le stime sul rendimento mostrate sopra presuppongono che ogni riga contenga 1 KB di dati. Puoi leggere e scrivere quantità maggiori di dati per riga, ma l'aumento della quantità di dati per riga riduce anche il numero di righe al secondo.
- Le righe della tabella Bigtable contengono un numero molto elevato di cellule. Bigtable impiega del tempo per elaborare ogni cella di una riga. Inoltre, ogni cella aggiunge un po' di overhead alla quantità di dati memorizzati nella tabella e inviati tramite la rete. Ad esempio, se memorizzi 1 KB (1024 byte) di dati, è molto più efficiente in termini di spazio archiviarli in una singola cella anziché distribuirli su 1024 celle contenenti ciascuna 1 byte. Se dividi i dati in più celle del necessario, potresti non ottenere il rendimento migliore possibile. Se le righe contengono un numero elevato di celle perché le colonne contengono più versioni dei dati con timestamp, valuta la possibilità di mantenere solo il valore più recente. Un'altra opzione per una tabella esistente è inviare un'eliminazione per tutte le versioni precedenti con ogni riscrittura.
Il cluster non ha un numero sufficiente di nodi. I nodi di un cluster forniscono risorse di calcolo per consentire al cluster di gestire le letture e le scritture in arrivo, tenere traccia dello spazio di archiviazione ed eseguire attività di manutenzione come la compattazione. Devi assicurarti che il cluster abbia nodi sufficienti per soddisfare i limiti consigliati sia per l'elaborazione sia per lo spazio di archiviazione. Utilizza gli strumenti di monitoraggio per verificare se il cluster è sovraccarico.
- Computing: se la CPU del cluster Bigtable è sovraccaricata, l'aggiunta di altri nodi può migliorare le prestazioni suddividendo il workload su più nodi.
- Spazio di archiviazione: se l'utilizzo dello spazio di archiviazione per nodo è diventato superiore a quanto consigliato, devi aggiungere altri nodi per mantenere ottimali la latenza e il throughput, anche se il cluster dispone di CPU sufficienti per elaborare le richieste. Questo perché l'aumento dello spazio di archiviazione per nodo aumenta la quantità di lavoro di manutenzione in background per nodo. Per maggiori dettagli, vedi Compromisi tra utilizzo dello spazio di archiviazione e prestazioni.
Di recente è stato eseguito lo scale up o lo scale down del cluster Bigtable. Dopo aver aumentato il numero di nodi in un cluster, possono essere necessari fino a 20 minuti sotto carico prima di notare un miglioramento significativo delle prestazioni del cluster. Bigtable scala i nodi di un cluster in base al carico.
Quando riduci il numero di nodi in un cluster per eseguire lo scale down, cerca di non ridurre la dimensione del cluster di più del 10% in un periodo di 10 minuti per ridurre al minimo i picchi di latenza.
Il cluster Bigtable utilizza dischi HDD. Nella maggior parte dei casi, il cluster deve utilizzare dischi SSD, che hanno prestazioni notevolmente migliori rispetto ai dischi HDD. Per maggiori dettagli, consulta Scegliere tra archiviazione SSD e HDD.
Esistono problemi di connessione di rete. I problemi di rete possono ridurre la velocità effettiva e far sì che le letture e le scritture impieghino più tempo del solito. In particolare, potresti riscontrare problemi se i client non sono in esecuzione nella stessa zona del cluster Bigtable o se vengono eseguiti al di fuori di Google Cloud.
Utilizzi la replica, ma la tua applicazione utilizza una libreria client obsoleta. Se noti un aumento della latenza dopo aver attivato la replica, assicurati che la libreria client Cloud Bigtable utilizzata dalla tua applicazione sia aggiornata. Le versioni precedenti delle librerie client potrebbero non essere ottimizzate per supportare la replica. Consulta la pagina Librerie client di Cloud Bigtable per trovare il repository GitHub della tua libreria client, dove puoi controllare la versione ed eseguire l'upgrade, se necessario.
Hai attivato la replica, ma non hai aggiunto altri nodi ai tuoi cluster. In un'istanza che utilizza la replica, ogni cluster deve gestire il lavoro di replica oltre al carico ricevuto dalle applicazioni. I cluster sottodimensionati possono causare un aumento della latenza. Puoi verificarlo controllando i grafici dell'utilizzo della CPU dell'istanza nella Google Cloud console.
Poiché carichi di lavoro diversi possono far variare le prestazioni, è necessario eseguire test con i propri carichi di lavoro per ottenere benchmark più accurati.
Avvii a freddo e QPS ridotti
Gli avvii a freddo e un QPS basso possono aumentare la latenza. Bigtable offre il suo rendimento migliore con tabelle di grandi dimensioni a cui si accede di frequente. Per questo motivo, se inizi a inviare richieste dopo un periodo di inattività (avvio a freddo), potresti osservare una latenza elevata mentre Bigtable ristabilisce le connessioni. La latenza è più elevata anche quando il QPS è basso.
Se il QPS è basso o se sai che a volte invierai richieste a una tabella Bigtable dopo un periodo di inattività, puoi provare le seguenti strategie per mantenere attiva la connessione ed evitare questa latenza elevata.
- Invia sempre una bassa percentuale di traffico artificiale alla tabella.
- Configura il pool di connessione per assicurarti che un QPS costante mantenga il pool attivo.
Durante i periodi di QPS ridotto, il numero di errori restituiti da Bigtable è più pertinente della percentuale di operazioni che restituiscono un errore.
Avvio a freddo al momento dell'inizializzazione del client. Se utilizzi una versione del client Cloud Bigtable per Java precedente alla versione 2.18.0, puoi abilitare l'aggiornamento dei canali. Nelle versioni successive, l'aggiornamento del canale è attivo per impostazione predefinita. L'aggiornamento del canale consente di:
- Quando viene inizializzato, il client prepara il canale prima di inviare le prime richieste.
- Il server disconnette le connessioni a lungo termine ogni ora. La funzionalità di priming dei canali sostituisce in via preventiva i canali in scadenza.
Tuttavia, questo non mantiene attivo il canale durante i periodi di inattività.
In che modo Bigtable ottimizza i dati nel tempo
Per archiviare i dati sottostanti di ciascuna tabella, Bigtable suddivide i dati in più tablet, che possono essere spostati tra i nodi del cluster Bigtable. Questo metodo di archiviazione consente a Bigtable di utilizzare due diverse strategie per ottimizzare i dati nel tempo:
- Bigtable tenta di archiviare all'incirca la stessa quantità di dati su ogni nodo Bigtable.
- Bigtable cerca di distribuire equamente le letture e le scritture su tutti i nodi Bigtable.
A volte queste strategie sono in conflitto tra loro. Ad esempio, se le righe di un table vengono lette molto di frequente, Bigtable potrebbe memorizzare quello stesso table sul proprio nodo, anche se questo fa sì che alcuni nodi memorizzino più dati di altri.
Nell'ambito di questo processo, Bigtable potrebbe anche suddividere un tablet in due o più tablet più piccoli, per ridurre le dimensioni di un tablet o per isolare le righe più richieste all'interno di un tablet esistente.
Le sezioni seguenti spiegano ciascuna di queste strategie in modo più dettagliato.
Distribuzione della quantità di dati tra i nodi
Quando scrivi dati in una tabella Bigtable, Bigtable li suddivide in tablet. Ogni tablet contiene un intervallo contiguo di riga all'interno della tabella.
Se hai scritto meno di diversi GB di dati nella tabella, Bigtable archivia tutti i tablet su un singolo nodo all'interno del tuo cluster:
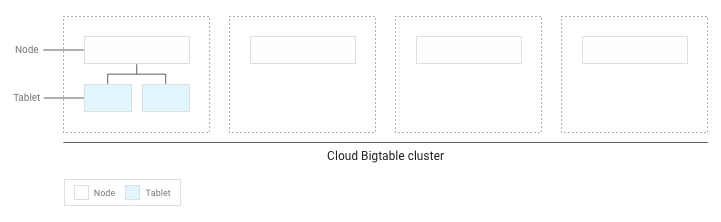
Man mano che si accumulano più tablet, Bigtable ne sposta alcuni in altri nodi del cluster in modo che la quantità di dati sia distribuita in modo più uniforme nel cluster:
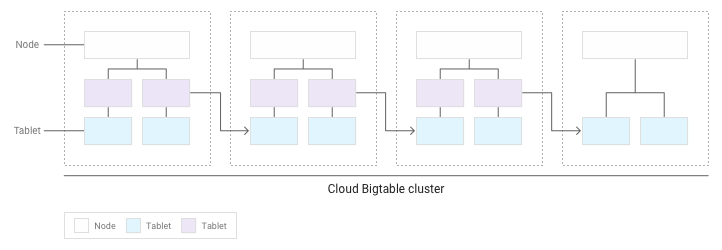
Distribuzione uniforme delle letture e delle scritture tra i nodi
Se hai progettato lo schema correttamente, le letture e le scritture dovrebbero essere distribuite in modo abbastanza uniforme in tutta la tabella. Tuttavia, in alcuni casi non puoi evitare di accedere ad alcune righe più frequentemente di altre. Bigtable ti aiuta a gestire questi casi tenendo conto delle letture e delle scritture quando bilancia i tablet tra i nodi.
Ad esempio, supponiamo che il 25% delle letture venga indirizzato a un numero ridotto di tablet all'interno di un cluster e che le letture siano distribuite uniformemente su tutti gli altri tablet:
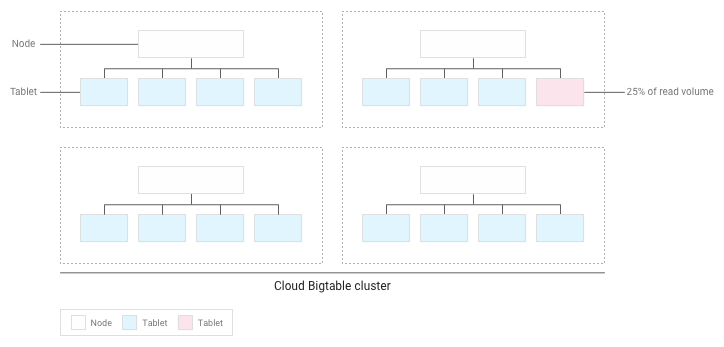
Bigtable ridistribuirà i tablet esistenti in modo che le letture siano distribuite il più uniformemente possibile nell'intero cluster:
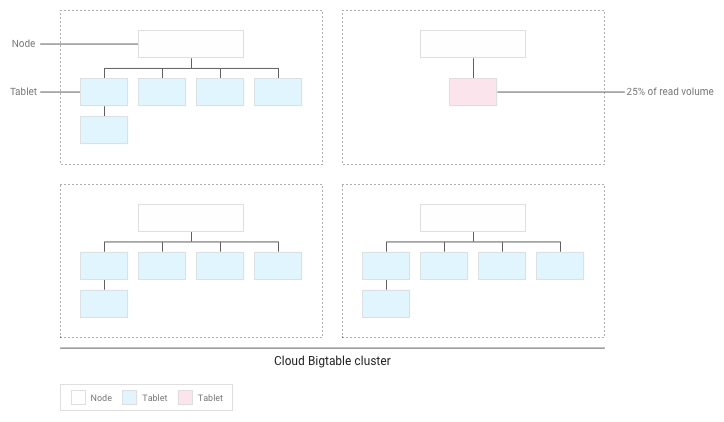
Testare le prestazioni con Bigtable
Se stai eseguendo un test di prestazioni per un'applicazione che dipende da Bigtable, segui queste linee guida durante la pianificazione ed esecuzione del test:
- Esegui il test con dati sufficienti.
- Se le tabelle dell'istanza di produzione contengono un totale di massimo 100 GB di dati per nodo, esegui il test con una tabella contenente la stessa quantità di dati.
- Se le tabelle contengono più di 100 GB di dati per nodo, esegui il test con una tabella che contenga almeno 100 GB di dati per nodo. Ad esempio, se la tua istanza di produzione ha un cluster di quattro nodi e le tabelle dell'istanza contengono un totale di 1 TB di dati, esegui il test utilizzando una tabella di almeno 400 GB.
- Esegui il test con una singola tabella.
- Rimani al di sotto dell'utilizzo dello spazio di archiviazione consigliato per nodo. Per maggiori dettagli, consulta Utilizzo dello spazio di archiviazione per nodo.
- Prima del test, esegui un pre-test impegnativo per diversi minuti. Questo passaggio consente a Bigtable di bilanciare i dati tra i nodi in base ai pattern di accesso osservati.
- Esegui il test per almeno 10 minuti. Questo passaggio consente a Bigtable di ottimizzare ulteriormente i dati e ti aiuta a verificare le letture dal disco e le letture memorizzate nella cache dalla memoria.
Risolvere i problemi di prestazioni
Se ritieni che Bigtable possa creare un collo di bottiglia nelle prestazioni della tua applicazione, assicurati di controllare quanto segue:
- Esamina le scansioni di Key Visualizer per la tua tabella. Lo strumento di visualizzazione delle chiavi per Bigtable genera nuovi dati di scansione ogni 15 minuti che mostrano i pattern di utilizzo per ogni tabella di un cluster. KeyVisualizer consente di verificare se i tuoi pattern di utilizzo stanno causando risultati indesiderati, ad esempio hot spot in righe specifiche o utilizzo eccessivo della CPU. Scopri come iniziare a utilizzare Key Visualizer.
- Prova a commentare il codice che esegue letture e scritture Bigtable. Se il problema di prestazioni scompare, probabilmente stai utilizzando Bigtable in un modo che comporta prestazioni non ottimali. Se il problema di prestazioni persiste, probabilmente non è correlato a Bigtable.
Assicurati di creare il minor numero possibile di client. La creazione di un client per Bigtable è un'operazione relativamente costosa. Pertanto, dovresti creare il minor numero possibile di client:
- Se utilizzi la replica o i profili di app per identificare diversi tipi di traffico verso la tua istanza, crea un client per profilo di app e condividilo nell'intera applicazione.
- Se non utilizzi la replica o i profili delle app, crea un singolo cliente e condividilo nell'intera applicazione.
Se utilizzi il client HBase per Java, crei un oggetto
Connectionanziché un client, quindi devi creare il minor numero possibile di connessioni.Assicurati di leggere e scrivere molte righe diverse nella tabella. Bigtable offre il massimo rendimento quando le letture e le scritture sono distribuite uniformemente nella tabella, il che consente a Bigtable di distribuire il carico di lavoro su tutti i nodi del cluster. Se le letture e le scritture non possono essere distribuite su tutti i nodi Bigtable, il rendimento ne risentirà.
Se noti che stai leggendo e scrivendo solo un numero limitato di righe, potrebbe essere necessario ridisegnare lo schema in modo che le letture e le scritture siano distribuite in modo più uniforme.
Verifica di ottenere lo stesso rendimento approssimativo per letture e scritti. Se noti che le letture sono molto più veloci delle scritture, potresti essere in procinto di leggere chiavi di riga che non esistono o un ampio intervallo di chiavi di riga che contiene solo un numero limitato di righe.
Per fare un confronto valido tra letture e scritture, dovresti cercare di ottenere risultati validi almeno per il 90% delle letture. Inoltre, se stai leggendo un ampio intervallo di chiavi di riga, misura il rendimento in base al numero effettivo di righe nell'intervallo anziché al numero massimo di righe che potrebbero esistere.
Utilizza il tipo corretto di richieste di scrittura per i tuoi dati. Scegliere il modo ottimale per scrivere i dati contribuisce a mantenere elevate le prestazioni.
Controlla la latenza di una singola riga. Se noti una latenza imprevista quando invii richieste
ReadRows, puoi controllare la latenza della prima riga della richiesta per restringere la causa. Per impostazione predefinita, la latenza complessiva di una richiestaReadRowsinclude la latenza di ogni riga della richiesta, nonché il tempo di elaborazione tra le righe. Se la latenza complessiva è elevata, ma la latenza della prima riga è bassa, ciò suggerisce che la latenza è causata dal numero di richieste o dal tempo di elaborazione, anziché da un problema con Bigtable.Se utilizzi la libreria client Bigtable per Java, puoi visualizzare la metrica
read_rows_first_row_latencyin Google Cloud Esplora metriche della console dopo aver abilitato le metriche lato client.Utilizza un profilo app separato per ogni carico di lavoro. Se riscontri problemi di prestazioni dopo aver aggiunto un nuovo carico di lavoro, crea un nuovo profilo dell'app per il nuovo carico di lavoro. In seguito, puoi monitorare le metriche per i profili delle app separatamente per risolvere ulteriormente i problemi. Consulta Come funzionano i profili delle app per scoprire perché è una best practice utilizzare più profili delle app.
Attiva le metriche lato client. Puoi configurare le metriche lato client per contribuire a ottimizzare e risolvere i problemi di prestazioni. Ad esempio, poiché Bigtable funziona al meglio con un QPS elevato e distribuito in modo uniforme, un aumento della latenza P100 (max) per una piccola percentuale di richieste non indica necessariamente un problema di prestazioni più ampio con Bigtable. Le metriche lato client possono indicarti quale parte del ciclo di vita della richiesta potrebbe causare la latenza.
Assicurati che l'applicazione consumi le richieste di lettura prima che scada il tempo di attesa. Se la tua applicazione elabora i dati durante uno stream di lettura, rischi che la richiesta scada prima che tu abbia ricevuto tutte le risposte dalla chiamata. Il risultato è un messaggio
ABORTED. Se visualizzi questo errore, riduci la quantità di elaborazione durante lo stream di lettura.
Passaggi successivi
- Scopri come progettare uno schema Bigtable.
- Scopri come monitorare il rendimento di Bigtable.
- Scopri come risolvere i problemi relativi a KeyVisualizer.
- Visualizza il codice di esempio per l'aggiunta di nodi a un cluster Bigtable tramite programmazione.