AI 基礎架構
適用於每個 AI 工作負載的基礎架構,可擴充、高效能且具成本效益。
AI 加速器能滿足各種用途,無論是高效能訓練或低成本推論都沒問題
運用 Google Kubernetes Engine 或 Google Compute Engine 上的 GPU 和 TPU 加速資源調度
Vertex AI、Google Kubernetes Engine 和 Cloud HPC Toolkit 適用的可部署解決方案
部署 AI 超級電腦架構,充分發揮 AI 基礎架構的效用

優點
大規模最佳化效能和成本效益
Google Cloud 的 GPU、TPU 或 CPU 可讓您選擇各種用途,包括高效能訓練、低成本推論,以及大規模資料處理。
透過代管型基礎架構更快取得結果
利用 Vertex AI 提供的代管基礎架構,以更快、更有效率的方式擴充。快速部署機器學習環境、自動化調度管理作業、管理大型叢集,以及建構低延遲應用程式。
使用專為 AI 技術打造的軟體進行開發
運用 GKE 管理大規模工作負載,提升 AI 開發工作效率。訓練及提供基礎模型,並支援自動調度資源、工作負載自動化調度管理和自動升級功能。
主要功能與特色
主要功能與特色
易於使用、管理及擴充
以往要使用 Cloud TPU 和 Cloud GPU 自動化調度管理大規模 AI 工作負載時,必須手動處理故障、記錄、監控和其他基礎作業。Google Kubernetes Engine (GKE) 是擴充性最高的全代管 Kubernetes 服務,可以大幅簡化運作 TPU 和 GPU 所需的工作。使用 GKE 在 Cloud TPU 和 Cloud GPU 上管理大規模 AI 工作負載自動化調度管理,可以提高 AI 開發作業的工作效率。
此外,如果機構偏好透過代管服務簡化基礎架構管理作業,Vertex AI 現可支援使用 Cloud TPU 和 Cloud GPU 的各種架構和程式庫進行訓練。
急速擴充 AI 模型
我們打造的 AI 技術最佳化基礎架構可因應 Google 產品對全球規模與效能的需求。YouTube、Gmail、Google 地圖、Google Play、Android 等產品皆採用此基礎架構,為全球數十億使用者提供服務。我們的 AI 基礎架構解決方案均以 Google Cloud 的 Jupiter 資料中心網路為基礎,支援業界最佳的基礎服務向外擴充功能,以及高強度的 AI 工作負載。
非常靈活的開放式平台
幾十年來,我們一直努力推進 TensorFlow、JAX 等重要的 AI 專案,我們與其他合作夥伴共同創立 PyTorch 基金會,並於日前宣布成立新的產業聯盟:OpenXLA 專案。Google 也是 CNCF 開放原始碼的主要貢獻者,在 TFX、MLIR、OpenXLA、KubeFlow 和 Kubernetes 等 OSS 方面貢獻超過 20 年,也贊助了對數據資料學社群來說非常重要的 OSS 專案,例如 Project Jupyter 和 NumFOCverteUS。
此外,我們在 AI 基礎架構服務嵌入最熱門的 AI 架構 (例如 TensorFlow、PyTorch 和 MXNet),客戶可以繼續依習慣使用,不受到特定架構/或硬體架構的限制。

客戶
採用 Google Cloud AI 基礎架構的客戶
隨著 AI 為各產業開啟了創新的大門,各家公司選擇採用 Google Cloud 來充分運用開放且有彈性的高效能基礎架構。









說明文件
說明文件
GKE 中的 AI 基礎架構工具
找不到所需資訊嗎?
使用案例
AI 超級電腦架構
加速進行大規模 AI 訓練
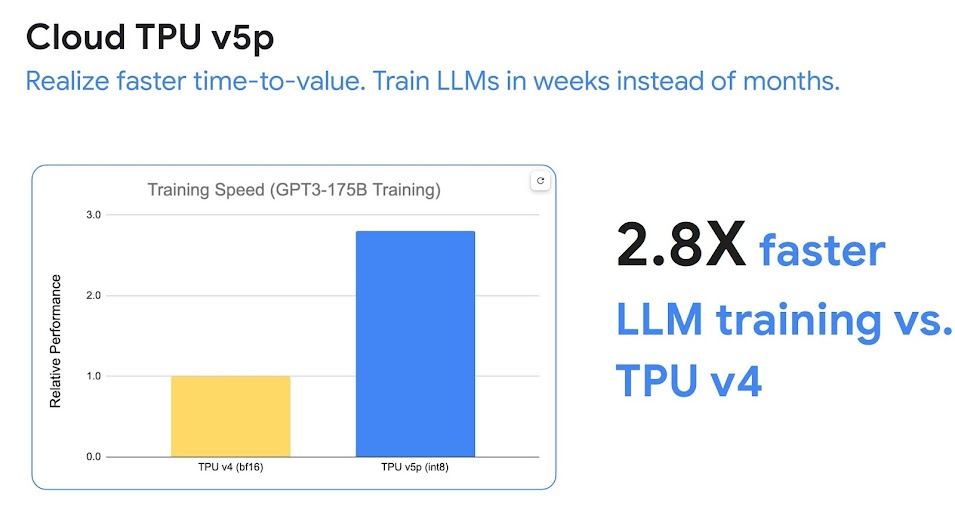
Cloud TPU Multislice Training 是一項完整堆疊技術,可讓數萬個 TPU 晶片執行快速、簡單且可靠的大規模 AI 模型訓練。
提供 AI 技術輔助應用程式
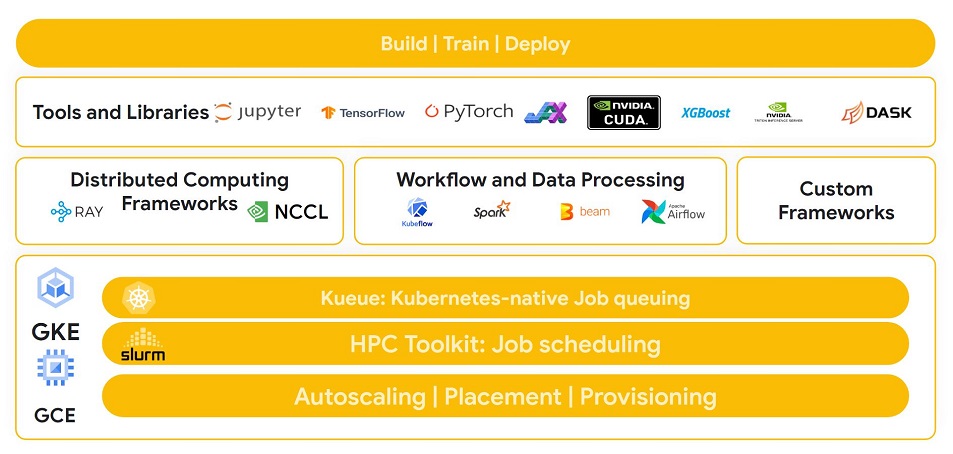
藉助 Google Cloud 的開放式軟體生態系統,您可以透過最慣用的架構和工具建構應用程式,同時享有 AI 超級電腦架構的成本效益優勢。
以更具成本效益的方式大規模提供 AI
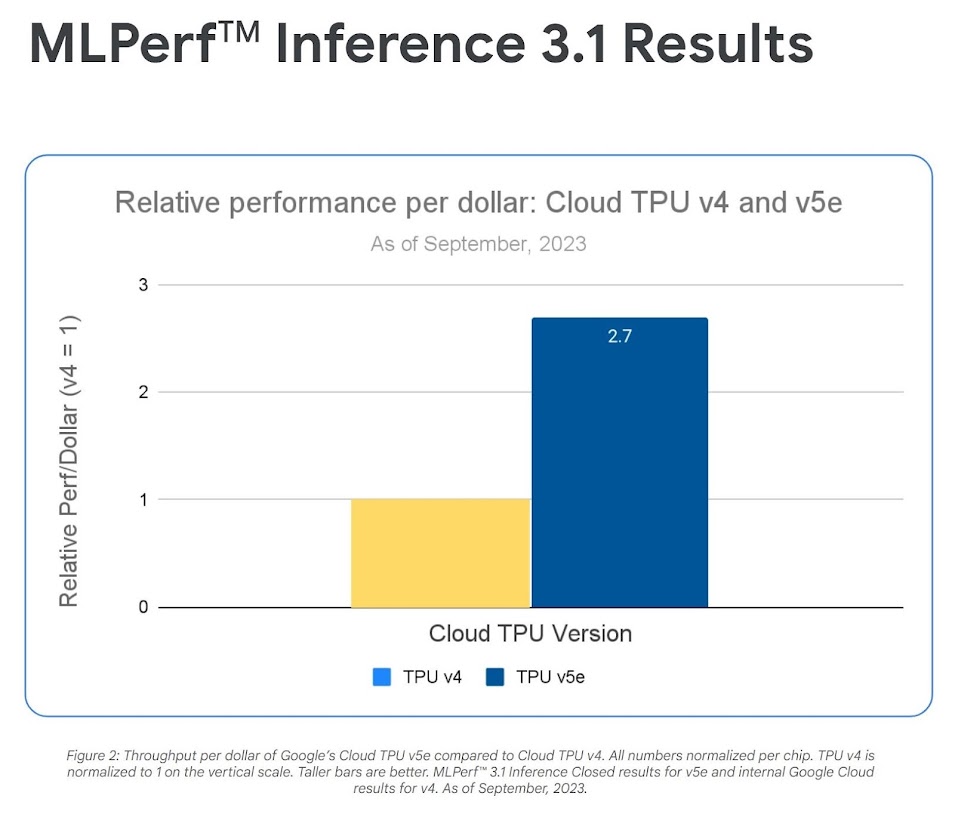
Cloud TPU v5e 和 NVIDIA L4 GPU 能讓各種 AI 工作負載 (包括最新的 LLM 和生成式 AI 模型) 進行高效能、具成本效益的推論作業。這兩項產品能大幅提高成本效益,成果遠勝於先前的模型。再加上 Google Cloud 的 AI 超級電腦架構,客戶得以擴大部署規模,成為業界領先的佼佼者。
Cloud AI 產品符合我們的服務水準協議政策。這些產品的延遲時間或可用性保證可能與其他 Google Cloud 服務不同。











