Halaman ini menjelaskan cara kerja Cloud TPU dengan Google Kubernetes Engine (GKE), termasuk terminologi, manfaat Unit Pemrosesan Tensor (TPU), dan pertimbangan penjadwalan workload. TPU adalah sirkuit terintegrasi khusus aplikasi (ASIC) yang dikembangkan khusus oleh Google untuk mempercepat beban kerja ML yang menggunakan framework seperti TensorFlow, PyTorch, dan JAX.
Halaman ini ditujukan bagi admin dan operator Platform serta spesialis Data dan AI yang menjalankan model machine learning (ML) yang memiliki karakteristik seperti berskala besar, berjalan lama, atau didominasi oleh komputasi matriks. Untuk mempelajari lebih lanjut peran umum dan contoh tugas yang kami referensikan dalam konten Google Cloud, lihat Peran dan tugas pengguna GKE umum.
Sebelum membaca halaman ini, pastikan Anda memahami cara kerja akselerator ML. Untuk mengetahui detailnya, lihat Pengantar Cloud TPU.
Manfaat menggunakan TPU di GKE
GKE memberikan dukungan penuh untuk pengelolaan siklus proses node dan node pool TPU, termasuk membuat, mengonfigurasi, dan menghapus VM TPU. GKE juga mendukung Spot VM dan penggunaan Cloud TPU yang dicadangkan. Untuk mengetahui informasi selengkapnya, lihat Opsi pemakaian Cloud TPU.
Manfaat menggunakan TPU di GKE meliputi:
- Lingkungan operasional yang konsisten: Anda dapat menggunakan satu platform untuk semua machine learning dan workload lainnya.
- Upgrade otomatis: GKE mengotomatiskan update versi, yang mengurangi overhead operasional.
- Load balancing: GKE mendistribusikan beban, sehingga mengurangi latensi dan meningkatkan keandalan.
- Penskalaan responsif: GKE secara otomatis menskalakan resource TPU untuk memenuhi kebutuhan workload Anda.
- Pengelolaan resource: Dengan Kueue, sistem antrean pekerjaan berbasis Kubernetes, Anda dapat mengelola resource di beberapa tenant dalam organisasi Anda menggunakan antrean, preemption, prioritas, dan pembagian yang adil.
- Opsi sandbox: GKE Sandbox membantu melindungi workload Anda dengan gVisor. Untuk mengetahui informasi selengkapnya, lihat GKE Sandbox.
Manfaat menggunakan TPU Trillium
Trillium adalah TPU generasi keenam Google. Trillium memiliki manfaat berikut:
- Trillium meningkatkan performa komputasi per chip dibandingkan dengan TPU v5e.
- Trillium meningkatkan kapasitas dan bandwidth Memori Bandwidth Tinggi (HBM), serta meningkatkan bandwidth Interchip Interconnect (ICI) dibandingkan TPU v5e.
- Trillium dilengkapi dengan SparseCore generasi ketiga, akselerator khusus untuk memproses embedding yang sangat besar yang umum dalam beban kerja rekomendasi dan peringkat lanjutan.
- Trillium 67% lebih hemat energi daripada TPU v5e.
- Trillium dapat menskalakan hingga 256 TPU dalam satu slice TPU berbandwidth tinggi dan latensi rendah.
- Trillium mendukung penjadwalan pengumpulan. Penjadwalan pengumpulan memungkinkan Anda mendeklarasikan grup TPU (node pool slice TPU host tunggal dan multi-host) untuk memastikan ketersediaan tinggi bagi permintaan workload inferensi Anda.
Di semua platform teknis seperti API dan log, serta di bagian tertentu dokumentasi GKE, kami menggunakan v6e atau TPU Trillium (v6e) untuk merujuk ke TPU Trillium. Untuk mempelajari manfaat Trillium lebih lanjut, baca
postingan blog pengumuman Trillium. Untuk
memulai penyiapan TPU, lihat Merencanakan TPU di GKE.
Terminologi yang terkait dengan TPU di GKE
Halaman ini menggunakan terminologi berikut yang terkait dengan TPU:
- Jenis TPU: jenis Cloud TPU, seperti v5e.
- Node slice TPU: node Kubernetes yang diwakili oleh satu VM yang memiliki satu atau beberapa chip TPU yang saling terhubung.
- Node pool slice TPU: sekelompok node Kubernetes dalam cluster yang semuanya memiliki konfigurasi TPU yang sama.
- Topologi TPU: jumlah dan pengaturan fisik TPU chip dalam slice TPU.
- Atomik: GKE memperlakukan semua node yang saling terhubung sebagai satu unit. Selama operasi penskalaan, GKE menskalakan seluruh set node menjadi 0 dan membuat node baru. Jika mesin dalam grup gagal atau berhenti, GKE akan membuat ulang seluruh set node sebagai unit baru.
- Tidak dapat diubah: Anda tidak dapat menambahkan node baru secara manual ke set node yang saling terhubung. Namun, Anda dapat membuat node pool baru yang memiliki topologi TPU yang Anda inginkan dan menjadwalkan workload di node pool baru.
Jenis node pool slice TPU
GKE mendukung dua jenis TPU node pool:
Jenis dan topologi TPU menentukan apakah node slice TPU Anda dapat berupa multi-host atau host tunggal. Sebaiknya:
- Untuk model berskala besar, gunakan node slice TPU multi-host.
- Untuk model berskala kecil, gunakan node slice TPU host tunggal.
- Untuk pelatihan atau inferensi berskala besar, gunakan Pathways. Pathways menyederhanakan komputasi machine learning berskala besar dengan memungkinkan satu klien JAX mengatur workload di beberapa slice TPU besar. Untuk mengetahui informasi selengkapnya, lihat Pathways.
Node pool slice TPU multi-host
Node pool slice TPU multi-host adalah node pool yang berisi dua atau beberapa VM TPU yang saling terhubung. Setiap VM memiliki perangkat TPU yang terhubung dengannya. TPU dalam slice TPU multi-host terhubung melalui interkoneksi berkecepatan tinggi (ICI). Setelah
node pool slice TPU multi-host dibuat, Anda tidak dapat menambahkan node ke node pool tersebut. Misalnya, Anda tidak dapat membuat node pool v4-32, lalu menambahkan node Kubernetes (TPU VM) ke node pool tersebut. Untuk menambahkan slice TPU ke cluster GKE, Anda harus membuat node pool baru.
VM dalam node pool slice TPU multi-host diperlakukan sebagai satu unit atomik. Jika GKE tidak dapat men-deploy satu node dalam slice, tidak ada node dalam node slice TPU yang di-deploy.
Jika node dalam slice TPU multi-host memerlukan perbaikan, GKE akan mematikan semua VM dalam slice TPU, sehingga memaksa penghapusan semua Pod Kubernetes dalam workload. Setelah semua VM dalam slice TPU aktif dan berjalan, Pod Kubernetes dapat dijadwalkan di VM dalam slice TPU baru.
Diagram berikut menunjukkan slice TPU multi-host v5litepod-16 (v5e). Slice TPU ini memiliki empat VM. Setiap VM dalam slice TPU memiliki empat chip TPU v5e yang terhubung dengan interkoneksi berkecepatan tinggi (ICI), dan setiap chip TPU v5e memiliki satu TensorCore:
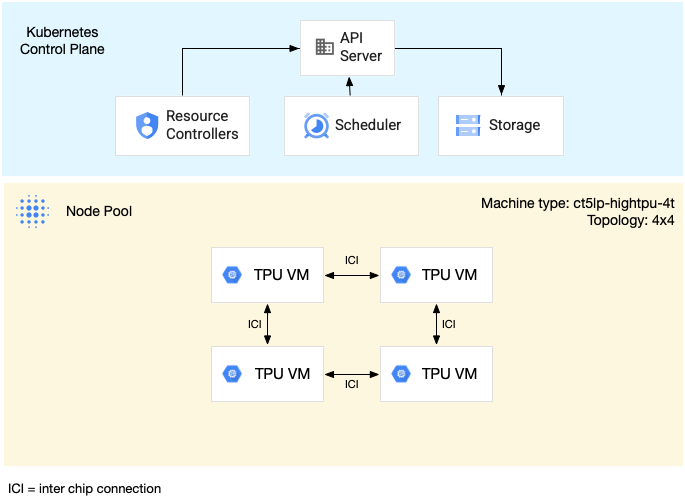
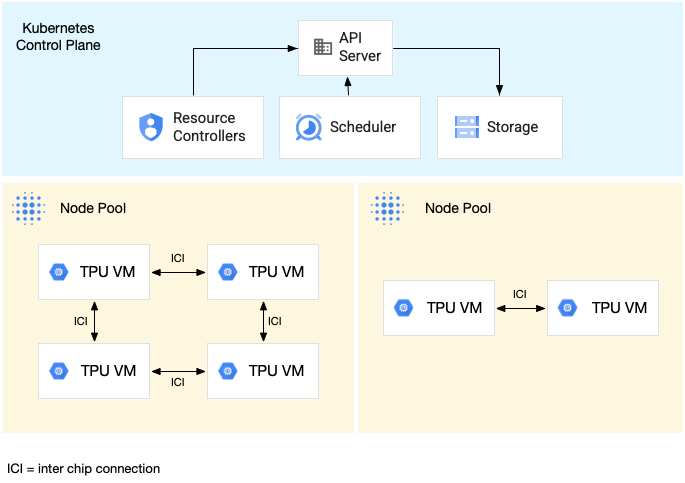
Diagram berikut menunjukkan cluster GKE yang berisi satu slice TPU
v5litepod-16 (v5e) (topologi: 4x4) dan satu slice TPU v5litepod-8 (v5e)
(topologi: 2x4):
Node pool slice TPU host tunggal
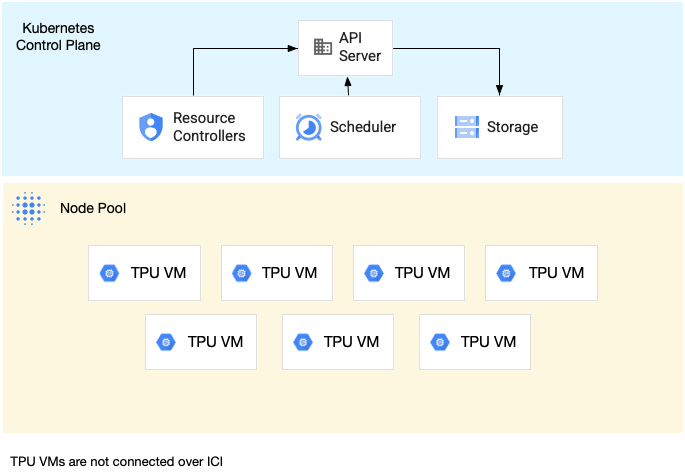
Node pool slice host tunggal adalah node pool yang berisi satu atau beberapa VM TPU independen. Setiap VM memiliki perangkat TPU yang terhubung dengannya. Meskipun VM dalam node pool slice host tunggal dapat berkomunikasi melalui Jaringan Pusat Data (DCN), TPU yang terpasang ke VM tidak saling terhubung.
Diagram berikut menunjukkan contoh slice TPU host tunggal yang berisi
tujuh mesin v4-8:
Karakteristik TPU di GKE
TPU memiliki karakteristik unik yang memerlukan perencanaan dan konfigurasi khusus.
Penggunaan TPU
Untuk mengoptimalkan pemanfaatan resource dan biaya sekaligus menyeimbangkan performa workload, GKE mendukung opsi penggunaan TPU berikut:
- Mulai fleksibel: untuk menyediakan VM Mulai fleksibel hingga tujuh hari, dengan GKE secara otomatis mengalokasikan hardware berdasarkan upaya terbaik berdasarkan ketersediaan. Untuk mengetahui informasi selengkapnya, lihat Tentang penyediaan GPU dan TPU dengan mode penyediaan mulai fleksibel.
- Spot VM: untuk menyediakan Spot VM, Anda bisa mendapatkan diskon yang signifikan, tetapi Spot VM dapat di-preempt kapan saja, dengan peringatan 30 detik. Untuk mengetahui informasi selengkapnya, lihat Spot VM.
- Pemesanan untuk masa mendatang hingga 90 hari (dalam mode kalender): untuk menyediakan resource TPU hingga 90 hari, untuk jangka waktu tertentu. Untuk mengetahui informasi selengkapnya, lihat Meminta TPU dengan pemesanan untuk masa mendatang dalam mode kalender.
- Pemesanan TPU: untuk meminta pemesanan untuk masa mendatang selama satu tahun atau lebih.
Untuk memilih opsi penggunaan yang memenuhi persyaratan workload Anda, lihat Tentang opsi penggunaan akselerator untuk workload AI/ML di GKE.
Sebelum menggunakan TPU di GKE, pilih opsi penggunaan yang paling sesuai dengan persyaratan beban kerja Anda.
Topologi
Topologi menentukan susunan fisik TPU dalam slice TPU. GKE menyediakan slice TPU dalam topologi dua atau tiga dimensi, bergantung pada versi TPU. Anda menentukan topologi sebagai jumlah chip TPU dalam setiap dimensi sebagai berikut:
Untuk TPU v4 dan v5p yang dijadwalkan di node pool slice TPU multi-host, Anda akan menentukan
topologi dalam 3 tuple ({A}x{B}x{C}), misalnya 4x4x4. Produk
{A}x{B}x{C} menentukan jumlah chip TPU dalam node pool. Misalnya, Anda
dapat menentukan topologi kecil yang memiliki kurang dari 64 chip TPU dengan bentuk
topologi seperti 2x2x2, 2x2x4, atau 2x4x4. Jika Anda menggunakan topologi yang lebih besar yang memiliki lebih dari 64 chip TPU, nilai yang Anda tetapkan ke {A}, {B}, dan {C} harus memenuhi kondisi berikut:
- {A}, {B}, dan {C} harus kelipatan empat.
- Topologi terbesar yang didukung untuk v4 adalah
12x16x16dan v5p adalah16x16x24. - Nilai yang ditetapkan harus mempertahankan pola A ≤ B ≤ C. Misalnya
4x4x8atau8x8x8.
Jenis mesin
Jenis mesin yang mendukung resource TPU mengikuti konvensi penamaan yang
mencakup versi TPU dan jumlah chip TPU per slice node, seperti
ct<version>-hightpu-<node-chip-count>t. Misalnya, jenis mesin
ct5lp-hightpu-1t mendukung TPU v5e dan hanya berisi satu chip TPU.
Mode istimewa
Jika Anda menggunakan GKE versi sebelum 1.28, Anda harus mengonfigurasi
container dengan kemampuan khusus untuk mengakses TPU. Di cluster mode Standard, Anda dapat menggunakan mode istimewa untuk memberikan akses ini. Mode istimewa
menggantikan banyak setelan keamanan lainnya di securityContext. Untuk
mengetahui detailnya, lihat Menjalankan container tanpa mode hak istimewa.
Versi 1.28 dan yang lebih baru tidak memerlukan mode hak istimewa atau kemampuan khusus.
Cara kerja TPU di GKE
Pengelolaan dan prioritas resource Kubernetes memperlakukan VM di TPU sama seperti jenis VM lainnya. Untuk meminta chip TPU, gunakan nama resource google.com/tpu:
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Saat menggunakan TPU di GKE, pertimbangkan karakteristik TPU berikut:
- VM dapat mengakses hingga 8 chip TPU.
- Slice TPU berisi sejumlah chip TPU tetap, dengan jumlah yang bergantung pada jenis mesin TPU yang Anda pilih.
- Jumlah
google.com/tpuyang diminta harus sama dengan jumlah total chip TPU yang tersedia di node slice TPU. Container apa pun di Pod GKE yang meminta TPU harus menggunakan semua TPU chip dalam node. Jika tidak, Deployment akan gagal karena GKE tidak dapat memakai sebagian resource TPU. Pertimbangkan skenario berikut:- Jenis mesin
ct5lp-hightpu-4tdengan topologi2x4berisi dua node slice TPU dengan masing-masing empat chip TPU, sehingga totalnya delapan chip TPU. Dengan jenis mesin ini, Anda dapat: - Tidak dapat men-deploy Pod GKE yang memerlukan delapan chip TPU di node dalam node pool ini.
- Dapat men-deploy dua Pod yang masing-masing memerlukan empat chip TPU, dengan setiap Pod berada di salah satu dari dua node di node pool ini.
- TPU v5e dengan topologi 4x4 memiliki 16 chip TPU dalam empat node. Workload Autopilot GKE yang memilih konfigurasi ini harus meminta empat chip TPU di setiap replika, untuk satu hingga empat replika.
- Jenis mesin
- Di cluster Standard, beberapa Pod Kubernetes dapat dijadwalkan di VM, tetapi hanya satu container di setiap Pod yang dapat mengakses chip TPU.
- Untuk membuat Pod kube-system, seperti kube-dns, setiap cluster Standard harus memiliki setidaknya satu node pool slice non-TPU.
- Secara default, node slice TPU memiliki
google.com/tputaint yang mencegah workload non-TPU dijadwalkan di node slice TPU. Workload yang tidak menggunakan TPU dijalankan di node non-TPU, sehingga membebaskan komputasi di node slice TPU untuk kode yang menggunakan TPU. Perhatikan bahwa taint tidak menjamin bahwa resource TPU digunakan sepenuhnya. - GKE mengumpulkan log yang dikeluarkan oleh container yang berjalan di node slice TPU. Untuk mempelajari lebih lanjut, lihat Logging.
- Metrik penggunaan TPU, seperti performa runtime, tersedia di Cloud Monitoring. Untuk mempelajari lebih lanjut, lihat Kemampuan observasi dan metrik.
- Anda dapat melakukan sandbox pada workload TPU dengan GKE Sandbox. GKE Sandbox kompatibel dengan model TPU v4 dan yang lebih baru. Untuk mempelajari lebih lanjut, lihat GKE Sandbox.
Cara kerja penjadwalan pengumpulan
Di TPU Trillium, Anda dapat menggunakan penjadwalan pengumpulan untuk mengelompokkan node slice TPU. Mengelompokkan node slice TPU ini akan mempermudah penyesuaian jumlah replika untuk memenuhi permintaan workload. Google Cloud mengontrol update software untuk memastikan bahwa slice yang cukup dalam koleksi selalu tersedia untuk melayani traffic.
TPU Trillium mendukung penjadwalan pengumpulan untuk node pool host tunggal dan multi-host yang menjalankan workload inferensi. Berikut ini menjelaskan cara kerja penjadwalan pengumpulan yang bergantung pada jenis slice TPU yang Anda gunakan:
- Slice TPU multi-host: GKE mengelompokkan slice TPU multi-host untuk membentuk koleksi. Setiap node pool GKE adalah replika dalam koleksi ini. Untuk menentukan koleksi, buat slice TPU multi-host dan tetapkan nama unik ke koleksi. Untuk menambahkan lebih banyak slice TPU ke koleksi, buat node pool slice TPU multi-host lain dengan nama koleksi dan jenis workload yang sama.
- Slice TPU host tunggal: GKE menganggap seluruh node pool slice TPU host tunggal sebagai kumpulan. Untuk menambahkan lebih banyak slice TPU ke koleksi, Anda dapat mengubah ukuran node pool slice TPU host tunggal.
Penjadwalan pengumpulan memiliki batasan berikut:
- Anda hanya dapat menjadwalkan pengumpulan data untuk TPU Trillium.
- Anda hanya dapat menentukan koleksi selama pembuatan node pool.
- Spot VM tidak didukung.
- Kumpulan yang berisi node pool slice TPU multi-host harus menggunakan jenis mesin, topologi, dan versi yang sama untuk semua node pool dalam kumpulan.
Anda dapat mengonfigurasi penjadwalan pengumpulan dalam skenario berikut:
- Saat membuat node pool slice TPU di GKE Standard
- Saat men-deploy workload di GKE Autopilot
- Saat membuat cluster yang mengaktifkan penyediaan otomatis node
Langkah berikutnya
Untuk mempelajari cara menyiapkan Cloud TPU di GKE, lihat halaman berikut:
- Merencanakan TPU di GKE untuk memulai penyiapan TPU
- Men-deploy workload TPU di GKE Autopilot
- Men-deploy workload TPU di GKE Standard
- Pelajari praktik terbaik untuk menggunakan Cloud TPU untuk tugas ML Anda
- Video: Membangun machine learning berskala besar di Cloud TPU dengan GKE
- Menayangkan Model Bahasa Besar dengan KubeRay di TPU
- Pelajari cara Melakukan sandboxing pada workload GPU dengan GKE Sandbox