Conforme descrito em Planos de execução de consulta, o compilador SQL transforma uma instrução SQL em um plano de execução de consulta, que é usado para receber os resultados da consulta. Esta página descreve as práticas recomendadas para criar instruções SQL para ajudar o Spanner a encontrar planos de execução eficientes.
As instruções SQL de exemplo mostradas nesta página usam o seguinte esquema de amostra:
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Para ver todas as referências do SQL, consulte Sintaxe da instrução, Funções e operadores e Estrutura léxica e sintaxe.
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Para mais informações, consulte A linguagem PostgreSQL no Spanner.
Usar parâmetros de consulta
O Spanner aceita parâmetros de consulta para aumentar o desempenho e ajudar a impedir a injeção de SQL quando as consultas são criadas usando entradas do usuário. É possível usar parâmetros de consulta como substitutos de expressões arbitrárias, mas não como substitutos de identificadores, nomes de colunas, nomes de tabelas ou outras partes da consulta.
Os parâmetros podem ser exibidos em qualquer lugar onde se espera um valor literal. O mesmo nome de parâmetro pode ser usado mais de uma vez em uma única instrução SQL.
Em resumo, os parâmetros de consulta oferecem suporte à execução de consulta das seguintes maneiras:
- Planos pré-otimizados: as consultas que usam parâmetros podem ser executadas mais rapidamente em cada invocação porque a parametrização facilita o armazenamento em cache do plano de execução pelo Spanner.
- Composição de consulta simplificada: não é necessário inserir caractere de escape em valores de string ao fornecê-los em parâmetros de consulta. Os parâmetros de consulta também reduzem o risco de erros de sintaxe.
- Segurança: os parâmetros de consulta deixam as consultas mais seguras, protegendo você de vários ataques injeção de SQL. Essa proteção é especialmente importante para consultas que você constrói com base na entrada do usuário.
Entender como o Spanner executa consultas
O Spanner permite consultar bancos de dados usando instruções SQL declarativas que especificam quais dados você quer recuperar. Se você quiser entender como o Spanner obtém os resultados, examine o plano de execução da consulta. Um plano de execução de consulta mostra o custo computacional associado a cada etapa da consulta. Usando os custos, é possível depurar os problemas de desempenho da consulta e otimizá-la. Para saber mais, consulte Planos de execução de consulta.
É possível recuperar planos de execução de consulta pelo console do Google Cloud ou as bibliotecas de cliente.
Para conferir um plano de execução de consulta específico usando o console do Google Cloud , siga estas etapas:
Abra a página "Instâncias do Spanner".
Selecione os nomes da instância do Spanner e do banco de dados que você quer consultar.
Clique em Spanner Studio no painel de navegação à esquerda.
Digite a consulta no campo de texto e clique em Executar consulta.
Clique em Explicação
. O console do Google Cloud exibe um plano de execução visual para sua consulta.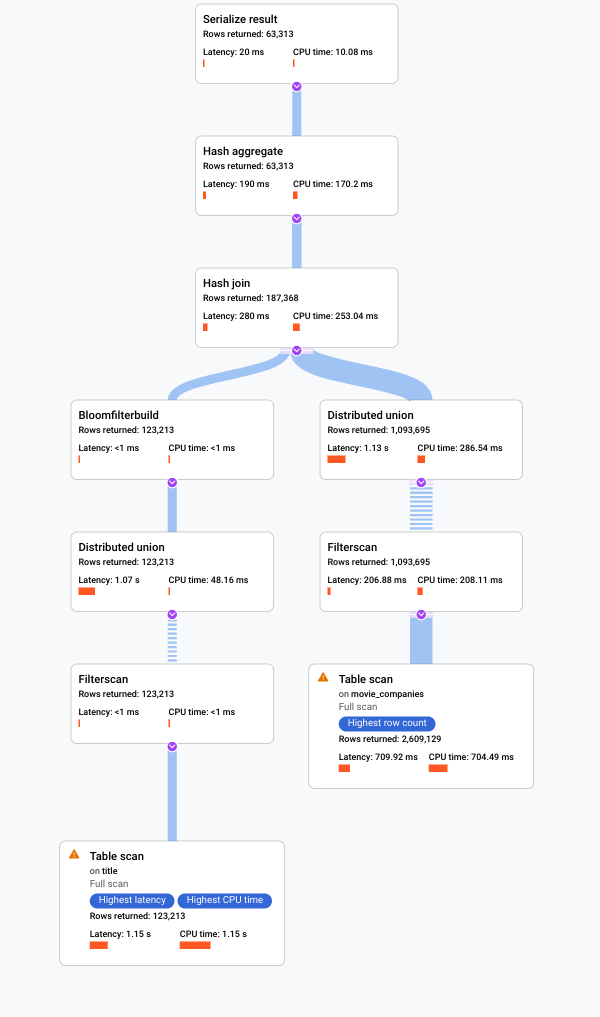
Para mais informações sobre como entender os planos visuais e usá-los para depurar suas consultas, consulte Ajustar uma consulta usando o visualizador de planos de consulta.
Também é possível conferir amostras de planos de consulta históricos e comparar a performance de uma consulta ao longo do tempo para determinadas consultas. Para saber mais, consulte Planos de consulta amostrados.
Usar índices secundários
Assim como acontece com outros bancos de dados relacionais, o Spanner oferece índices secundários, que é possível usar para recuperar dados usando uma instrução SQL ou a interface de leitura do Spanner. A maneira mais comum de buscar dados de um índice é usar o Spanner Studio. Com um índice secundário em uma consulta SQL, é possível especificar como você quer que o Spanner receba os resultados. A especificação de um índice secundário pode acelerar a execução da consulta.
Por exemplo, suponha que você queira buscar os IDs de todos os cantores com um sobrenome específico. Uma maneira de escrever uma consulta SQL é:
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
Essa consulta retornaria os resultados que você espera, mas talvez levasse muito tempo para fazer isso. O tempo dependerá do número de linhas na tabela Singers e quantas satisfazem o predicado WHERE s.LastName = 'Smith'. Se não houver um índice secundário que contenha a coluna LastName a ser lida, o plano de consulta vai ler toda a tabela Singers para encontrar linhas que correspondam ao predicado. Ler a tabela inteira é chamado de verificação completa da tabela. Uma verificação completa da tabela é uma maneira cara
de conseguir os resultados quando a tabela contém apenas uma pequena porcentagem de
Singers com esse sobrenome.
É possível melhorar o desempenho dessa consulta definindo um índice secundário na coluna de sobrenome:
CREATE INDEX SingersByLastName ON Singers (LastName);
Como o índice secundário SingersByLastName contém a coluna da tabela indexada
LastName e a coluna de chave primária SingerId, o Spanner pode
buscar todos os dados da tabela de índice muito menor em vez de verificar toda a
tabela Singers.
Nesse cenário, o Spanner usa automaticamente o índice
secundário SingersByLastName ao executar a consulta, desde que três dias tenham se passado
desde a criação do banco de dados. Consulte
Uma observação sobre novos bancos de dados. No entanto, é melhor
informar explicitamente ao Spanner para usar esse índice especificando
uma diretiva de índice na cláusula FROM:
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Agora, suponha que você também queria buscar o nome do cantor além do ID. Mesmo que a coluna FirstName não esteja contida no índice, especifique a diretiva de índice como antes:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Você ainda recebe um benefício de desempenho ao usar o índice porque o Spanner
não precisa fazer uma verificação completa da tabela ao executar o plano de consulta. Em vez disso, ele
seleciona o subconjunto de linhas que satisfazem o predicado do índice SingersByLastName
e faz uma pesquisa da tabela base Singers para buscar o primeiro
nome apenas desse subconjunto de linhas.
Se você não quiser que o Spanner busque linhas da tabela
base, armazene uma cópia da coluna FirstName no
próprio índice:
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
Usar uma cláusula STORING (para o dialeto GoogleSQL) ou uma cláusula INCLUDE
(para o dialeto PostgreSQL) como essa custa armazenamento extra, mas oferece as seguintes vantagens:
- As consultas SQL que usam o índice e selecionam as colunas armazenadas na cláusula
STORINGouINCLUDEnão exigem uma vinculação extra à tabela base. - As chamadas de leitura que usam o índice podem ler colunas armazenadas na cláusula
STORINGouINCLUDE.
Os exemplos anteriores ilustram como índices secundários podem agilizar consultas quando as linhas escolhidas pela cláusula WHERE podem ser identificadas rapidamente usando o índice secundário.
Outro cenário em que índices secundários podem oferecer benefícios de desempenho é para determinadas consultas que retornam resultados ordenados. Por exemplo, suponha que você queira buscar todos os títulos de álbuns e as datas de lançamento deles em ordem crescente na data de lançamento e em ordem decrescente por título do álbum. Você pode escrever uma consulta SQL da seguinte maneira:
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Sem um índice secundário, esta consulta requer uma etapa de classificação potencialmente cara no plano de execução. É possível agilizar a execução da consulta definindo esse índice secundário:
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
Em seguida, reescreva a consulta para usar o índice secundário:
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Essa consulta e a definição de índice atendem aos seguintes critérios:
- Para remover a etapa de classificação, verifique se a lista de colunas na cláusula
ORDER BYé um prefixo da lista de chaves do índice. - Para evitar a junção de volta da tabela base para buscar as colunas ausentes, verifique se o índice abrange todas as colunas na tabela que a consulta usa.
Embora os índices secundários possam acelerar consultas comuns, adicionar índices secundários pode aumentar a latência das operações de confirmação, porque cada índice secundário normalmente requer o envolvimento de um nó extra em cada confirmação. Na maioria das cargas de trabalho, não há problemas em ter alguns índices secundários. No entanto, você precisa considerar se é mais importante a latência de leitura ou de gravação e quais operações são as mais críticas para a carga de trabalho. Compare sua carga de trabalho para garantir que ela esteja funcionando conforme o esperado.
Para a referência completa de índices secundários, consulte Índices secundários.
Otimizar digitalizações
Determinadas consultas do Spanner podem se beneficiar do uso de um método de processamento orientado a lotes ao verificar dados em vez do método de processamento orientado a linhas mais comum. Processar verificações em lotes é uma maneira mais eficiente de processar grandes volumes de dados de uma só vez e permite que as consultas reduzam a utilização da CPU e a latência.
A operação de verificação do Spanner sempre inicia a execução no modo orientado a linhas. Durante esse período, o Spanner coleta várias métricas de execução. Em seguida, o Spanner aplica um conjunto de heurísticas com base no resultado dessas métricas para determinar o modo de verificação ideal. Quando apropriado, o Spanner muda para um modo de processamento orientado a lotes para melhorar a capacidade e o desempenho da verificação.
Casos de uso comuns
As consultas com as seguintes características geralmente se beneficiam do uso de processamento orientado a lotes:
- Verificações grandes em dados atualizados com pouca frequência.
- Faz verificações com predicados em colunas de largura fixa.
- Verificações com contagens de busca grandes. Uma busca usa um índice para extrair registros.
Casos de uso sem ganhos de desempenho
Nem todas as consultas se beneficiam do processamento orientado a lotes. Os tipos de consulta a seguir têm melhor desempenho com o processamento de verificação orientado por linha:
- Consultas de pesquisa de ponto: consultas que buscam apenas uma linha.
- Pequenas consultas de verificação: verificações de tabela que verificam apenas algumas linhas, a menos que tenham contagens de busca grandes.
- Consultas que usam
LIMIT. - Consultas que leem dados de alta rotatividade: consultas em que mais de 10% dos dados lidos são atualizados com frequência.
- Consultas com linhas que contêm valores grandes: linhas de valores grandes são aquelas que contêm valores maiores que 32.000 bytes (antes da compactação) em uma única coluna.
Como verificar o método de verificação usado por uma consulta
Para verificar se a consulta usa processamento orientado a lotes, processamento orientado a linhas ou alterna automaticamente entre os dois métodos de leitura:
Acesse a página Instâncias do Spanner no console do Google Cloud .
Clique no nome da instância com a consulta que você quer investigar.
Na tabela "Bancos de dados", clique no banco de dados com a consulta que você quer investigar.
No menu de navegação, clique em Spanner Studio.
Abra uma nova guia clicando em New SQL editor tab ou New tab.
Quando o editor de consultas aparecer, crie sua consulta.
Clique em Executar.
O Spanner executa a consulta e mostra os resultados.
Clique na guia Explicação abaixo do editor de consultas.
O Spanner mostra um visualizador do plano de execução de consulta. Cada card no gráfico representa um iterador.
Clique no card do iterador Verificação de tabela para abrir um painel de informações.
O painel de informações mostra informações contextuais sobre a verificação selecionada. O método de leitura é mostrado neste card. Automático indica que o Spanner determina o método de digitalização. Outros valores possíveis incluem Vectorized para processamento orientado a lote e Scalar para processamento orientado a linha.
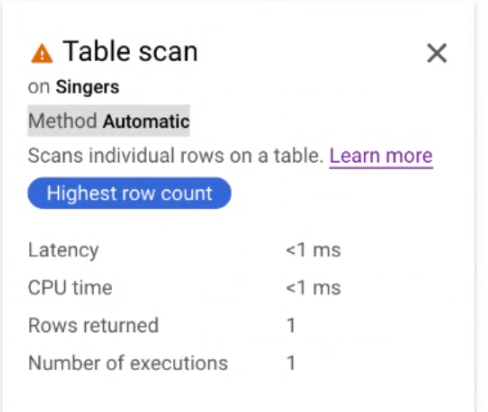
Como aplicar o método de verificação usado por uma consulta
Para otimizar o desempenho da consulta, o Spanner escolhe o método de verificação ideal para a consulta. Recomendamos que você use esse método de verificação padrão. No entanto, pode haver cenários em que você queira aplicar um tipo específico de método de verificação.
Como aplicar a verificação orientada a lotes
É possível aplicar a verificação orientada a lotes no nível da tabela e da instrução.
Para aplicar o método de verificação orientada a lotes no nível da tabela, use uma dica de tabela na consulta:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
Para aplicar o método de verificação orientada a lotes no nível da instrução, use uma dica de instrução na consulta:
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
Como desativar a leitura automática e aplicar a leitura orientada por linha
Embora não recomendemos desativar o método de verificação automática definido pelo Spanner, você pode decidir desativá-lo e usar o método de verificação orientado a linha para fins de solução de problemas, como diagnosticar latência.
Para desativar o método de verificação automática e aplicar o processamento de linhas no nível da tabela, use uma dica de tabela na consulta:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
Para desativar o método de verificação automática e aplicar o processamento de linhas no nível da instrução, use uma dica de instrução na consulta:
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
Otimizar pesquisas de chaves de intervalo
Um uso comum de uma consulta SQL é ler várias linhas do Spanner com base em uma lista de chaves conhecidas.
As práticas recomendadas a seguir ajudam a escrever consultas eficientes durante a busca de dados por um intervalo de chaves:
Se a lista de chaves for esparsa e não adjacente, use parâmetros de consulta e
UNNESTpara construir a consulta.Por exemplo, se a lista de chaves for
{1, 5, 1000}, escreva a consulta assim:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
Observações:
O operador UNNEST da matriz nivela uma matriz de entrada em linhas de elementos.
O parâmetro de consulta, que é
@KeyListpara o GoogleSQL e$1para o PostgreSQL, pode acelerar a consulta, conforme discutido na prática recomendada anterior.
Se a lista de chaves for adjacente e estiver dentro de um intervalo, especifique os limites mínimo e máximo do intervalo de chaves na cláusula
WHERE.Por exemplo, se a lista de chaves for
{1,2,3,4,5}, construa a consulta assim:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
Essa consulta só será mais eficiente se as chaves no intervalo forem adjacentes. Em outras palavras, se a lista de chaves for
{1, 5, 1000}, não especifique os limites mínimo e máximo, como na consulta anterior, porque a consulta resultante verificaria todos os valores entre 1 e 1.000.
Otimizar agrupamentos
As operações de mesclagem podem ser caras porque podem aumentar significativamente o número de linhas que a consulta precisa verificar, o que resulta em consultas mais lentas. Além das técnicas que você está acostumado a usar em outros bancos de dados relacionais para otimizar consultas de vinculação, aqui estão algumas práticas recomendadas para um JOIN mais eficiente ao usar o Spanner SQL:
Se possível, vincule dados em tabelas intercaladas por chave principal. Exemplo:
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
As linhas na tabela intercalada
Albumstêm a garantia de estar fisicamente armazenadas nas mesmas divisões que a linha pai emSingers, conforme discutido no Esquema e Modelo de Dados. Por isso, as mesclagens podem ser concluídas localmente sem enviar muitos dados pela rede.Use a diretiva de vinculação se você quiser forçar a ordem da vinculação. Exemplo:
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
A diretiva de junção
FORCE_JOIN_ORDERdiz ao Spanner para usar a ordem de junção especificada na consulta (isto é,Singers JOIN Albums, nãoAlbums JOIN Singers). Os resultados retornados são os mesmos, independentemente da ordem escolhida pelo Spanner. No entanto, convém usar essa diretiva de vinculação se você notar no plano de consulta que o Spanner mudou a ordem de vinculação e causou consequências indesejáveis, como resultados intermediários maiores, ou perdeu oportunidades de procurar linhas.Use uma diretiva de vinculação para escolher uma implementação de junção. Quando você usa o SQL para consultar várias tabelas, o Spanner usa automaticamente um método de junção que provavelmente tornará a consulta mais eficiente. No entanto, o Google aconselha realizar testes com diferentes algoritmos de mesclagem. Escolher o algoritmo de mesclagem certo para a consulta pode melhorar a latência, o consumo de memória ou ambos. Esta consulta demonstra a sintaxe para usar uma diretiva JOIN com a dica
JOIN_METHODpara escolher umHASH JOIN:GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
Se você estiver usando um
HASH JOINouAPPLY JOINe tiver uma cláusulaWHEREaltamente seletiva em um lado doJOIN, coloque a tabela que produz o menor número de linhas como a primeira tabela na cláusulaFROMda mesclagem. Essa estrutura ajuda porque, atualmente, emHASH JOIN, o Spanner sempre escolhe a tabela do lado esquerdo como build e a tabela do lado direito como sondagem. Da mesma forma, paraAPPLY JOIN, o Spanner escolhe a tabela do lado esquerdo como externa e a tabela do lado direito como interna. Saiba mais sobre esses tipos de mesclagem: Hash e Apply.Para consultas essenciais à sua carga de trabalho, especifique o método de junção com o melhor desempenho e a ordem de junção nas instruções SQL para um desempenho mais consistente.
Evitar grandes leituras em transações de leitura e gravação
Transações de leitura/gravação permitem uma sequência de zero ou mais leituras ou consultas SQL e podem incluir um conjunto de mutações, antes de uma chamada para confirmação. Para manter a consistência dos dados, o Spanner adquire bloqueios ao ler e gravar linhas nas tabelas e nos índices. Para mais informações sobre o bloqueio, consulte Vida útil das leituras e gravações.
Devido à forma como o bloqueio funciona no Spanner, executar uma consulta de leitura ou SQL
que leia um grande número de linhas (por exemplo, SELECT * FROM Singers)
significa que nenhuma outra transação pode gravar nas linhas lidas até que
sua transação seja confirmada ou cancelada.
Além disso, como sua transação está processando um grande número de linhas, é provável que demore mais do que uma transação que lê um intervalo muito menor de linhas (por exemplo, SELECT LastName FROM Singers WHERE SingerId = 7), o que agrava ainda mais o problema e reduz a capacidade do sistema.
Portanto, tente evitar leituras grandes (por exemplo, verificações de tabela completas ou operações de vinculação em massa) nas suas transações, a menos que esteja disposto a aceitar uma capacidade de gravação menor.
Em alguns casos, o seguinte padrão pode render resultados melhores:
- Realize as leituras grandes em uma transação somente leitura. As transações somente leitura permitem uma capacidade agregada maior porque não usam bloqueios.
- Opcional: faça qualquer processamento necessário nos dados que você acabou de ler.
- Inicie uma transação de leitura/gravação.
- Verifique se as linhas críticas não mudaram os valores desde que você executou
a transação somente leitura na etapa 1.
- Se houve mudança, reverta sua transação e comece novamente na etapa 1.
- Se tudo estiver certo, confirme as mutações.
Uma maneira de garantir que você evite leituras grandes em transações de leitura/gravação é examinar os planos de execução gerados pelas consultas.
Usar ORDER BY para garantir a ordem dos resultados SQL
Se você espera uma certa ordem para os resultados de uma consulta SELECT,
inclua explicitamente a cláusula ORDER BY. Por exemplo, se você quiser listar todos os cantores na ordem de chave primária, use esta consulta:
SELECT * FROM Singers
ORDER BY SingerId;
O Spanner garante a ordenação de resultados apenas se a cláusula ORDER BY
estiver presente na consulta. Em outras palavras, considere esta consulta sem o ORDER
BY:
SELECT * FROM Singers;
O Spanner não garante que os resultados dessa consulta estejam em ordem de chave primária. Além disso, a ordem dos resultados pode mudar a qualquer momento
e não há garantia de consistência de invocação para invocação. Se uma consulta
tiver uma cláusula ORDER BY e o Spanner usar um índice que fornece a
ordem necessária, ele não vai classificar os dados explicitamente. Portanto,
não se preocupe com o impacto no desempenho da inclusão dessa cláusula. É possível verificar
se uma operação de classificação explícita está incluída na execução analisando
o plano de consulta.
Use STARTS_WITH em vez de LIKE
Como o Spanner não avalia padrões LIKE parametrizados até o momento da execução, ele precisa ler todas as linhas e avaliá-las na expressão LIKE para filtrar aquelas que não correspondem.
Quando um padrão LIKE tem o formato foo% (por exemplo, começa com uma string fixa e termina com um único caractere curinga percentual) e a coluna é indexada, use STARTS_WITH em vez de LIKE. Essa
opção permite que o Spanner otimize de maneira mais eficaz o plano de execução
de consultas.
Não recomendado:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
Recomendado:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
Usar carimbos de data/hora de confirmação
Se o aplicativo precisar consultar dados gravados após um determinado horário,
adicione colunas de carimbo de data/hora de confirmação às tabelas relevantes. As marcações de tempo de confirmação
ativam uma otimização do Spanner que pode reduzir a E/S de
consultas em que as cláusulas WHERE restringem os resultados a linhas gravadas mais recentemente
do que em um horário específico.
Saiba mais sobre essa otimização com bancos de dados do GoogleSQL ou com bancos de dados do PostgreSQL.