Com o visualizador de planos de consulta, é possível entender rapidamente a estrutura do plano de consulta escolhido pelo Spanner para avaliar uma consulta. Este guia descreve como usar um plano de consulta para entender a execução das suas consultas.
Antes de começar
Para se familiarizar com as partes da interface do usuário do console do Google Cloud mencionadas neste guia, leia o seguinte:
Executar uma consulta no console do Google Cloud
- Acesse a página Instâncias do Spanner em Google Cloud console.
-
Selecione o nome da instância que contém o banco de dados que você quer consultar.
OGoogle Cloud console mostra a página Visão geral da instância.
-
Selecione o nome do banco de dados que você quer consultar.
O console doGoogle Cloud mostra a página Visão geral do banco de dados.
-
No menu lateral, clique em Spanner Studio.
O consoleGoogle Cloud mostra a página Spanner Studio do banco de dados.
- Digite a consulta SQL no painel do editor.
-
Clique em Executar.
O Spanner executa a consulta.
- Clique na guia Explicação para ver a visualização do plano de consulta.
Um tour pelo editor de consultas
A página do Spanner Studio fornece guias de consulta que permitem digitar ou colar instruções SQL e DML, executá-las no seu banco de dados e visualizar os resultados e planos de execução de consulta. Os principais componentes da página do Spanner Studio estão numerados na captura de tela a seguir.
- A barra de guias mostra as guias de consulta que estão abertas. Para criar uma nova
guia, clique em Nova guia.
A barra de guias também fornece uma lista de Modelos de consulta que você pode usar para colar consultas que apresentam insights sobre consultas de bancos de dados, transações, leituras e muito mais, conforme descrito em Visão geral das ferramentas de introspecção
- A barra de comandos do editor oferece estas opções:
- O comando exibir executa as instruções inseridas no painel de edição produzindo resultados de consulta na guia de Resultados
planos de execução de consulta na guia de Explicação. Altere o
comportamento padrão usando a lista suspensa para produzir Somente resultados
ou Apenas explicação.
Destacar algo no editor muda o comando Exibir para Exibir selecionado, permitindo que você execute apenas o que você selecionou.
- O comando Limpar consulta exclui todo o texto no editor e limpa as subguias Resultados e Explicação.
- O comando Formatar consulta formata as instruções no editor, facilitando a leitura.
- O comando Atalhos exibe o conjunto de atalhos do teclado que você pode usar no editor.
- O link Ajuda com a consulta SQL abre uma guia do navegador para a documentação sobre a sintaxe da consulta SQL.
As consultas são validadas automaticamente sempre que são atualizadas no editor. Se as instruções forem válidas, a barra de comandos do editor exibirá uma marca de confirmação e a mensagem Valid. Se houver algum problema, ele exibirá uma mensagem de erro com detalhes.
- O comando exibir executa as instruções inseridas no painel de edição produzindo resultados de consulta na guia de Resultados
planos de execução de consulta na guia de Explicação. Altere o
comportamento padrão usando a lista suspensa para produzir Somente resultados
ou Apenas explicação.
- O editor é onde você insere as consultas SQL e DML.
Elas são codificadas por cores, e os números das linhas são adicionados automaticamente para
instruções com várias linhas.
Se você inserir mais de uma instrução no editor, será necessário usar um ponto e vírgula de encerramento após cada instrução, exceto a última.
- O painel inferior de uma guia de consulta fornece três subguias:
- A subguia Esquema mostra as tabelas no banco de dados e os esquemas delas. Use-a como uma referência rápida ao escrever instruções no editor.
- A subguia Resultados mostra os resultados quando você executa as
instruções no editor. Para consultas, ele mostra uma tabela de resultados e,
para instruções DML, como
INSERTe >UPDATE, mostra uma mensagem sobre quantas linhas foram afetadas. - A subguia Explicação mostra gráficos para os planos de consulta criados quando você executa as instruções no editor.
- As subguias Resultados e Explicação fornecem um seletor de instruções usado para escolher os resultados da instrução ou o plano de consulta que você quer. visualização.
Ver planos de consulta de amostra
- Acesse a página Instâncias do Spanner em Google Cloud console.
-
Clique no nome da instância com as consultas que você quer investigar.
OGoogle Cloud console mostra a página Visão geral da instância.
-
No menu Navegação, em "Observabilidade", clique em Query Insights.
OGoogle Cloud console mostra a página Insights de consulta da instância.
-
No menu suspenso Banco de dados, selecione o banco de dados com as consultas que você quer investigar.
O consoleGoogle Cloud mostra as informações de carga de consulta do banco de dados. A tabela "Consultas e tags TopN" mostra a lista das principais consultas e tags de solicitação classificadas por utilização da CPU.
-
Encontre a consulta com alta utilização da CPU para a qual você quer ver planos de consulta amostrados. Clique no valor FPRINT dessa consulta.
A página Detalhes da consulta mostra um gráfico Amostras de planos de consulta para sua consulta ao longo do tempo. É possível diminuir o zoom para até sete dias antes do horário atual. Observação: os planos de consulta não são compatíveis com consultas que têm partitionTokens obtidos da API PartitionQuery e consultas de DML particionada.
-
Clique em um dos pontos no gráfico para conferir um plano de consulta mais antigo e visualizar as etapas realizadas durante a execução da consulta. Você também pode clicar em qualquer operador para ver mais informações sobre ele.
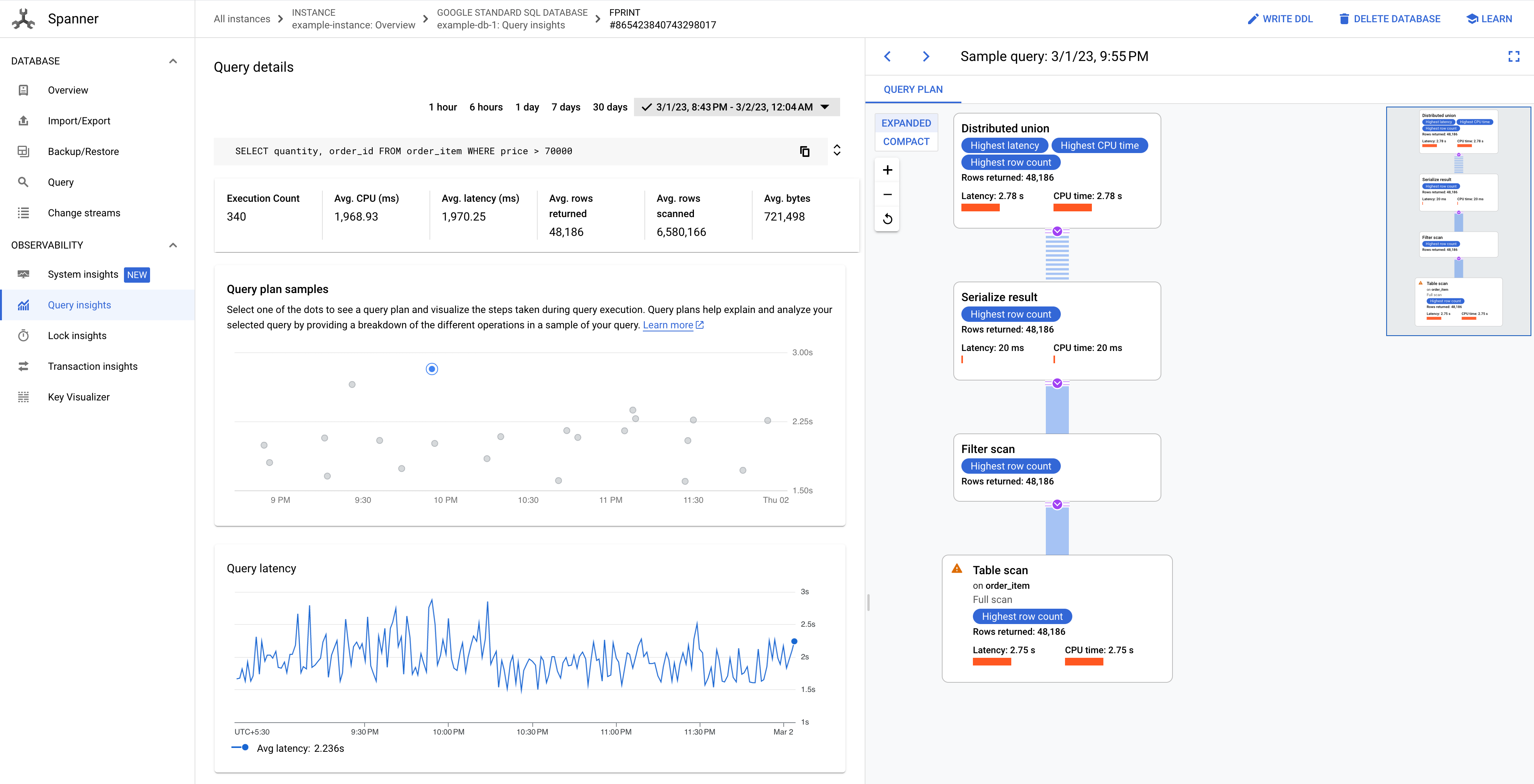
Figura 8. Gráfico de amostras de planos de consulta.
Em alguns casos, talvez seja necessário conferir planos de consulta amostrados e comparar o desempenho de uma consulta ao longo do tempo. Para consultas que consomem mais CPU, o Spanner retém planos de consulta amostrados por 30 dias na página Query Insights do console Google Cloud . Para ver planos de consulta amostrados:
Conheça o visualizador de planos de consulta
Os principais componentes do visualizador são anotados na captura de tela a seguir e descritos em mais detalhes. Depois de executar uma consulta em uma guia de consulta, selecione a guia EXPLANATION abaixo do editor de consultas para abrir o visualizador do plano de execução da consulta.
O fluxo de dados no diagrama a seguir é de baixo para cima, ou seja, todas as tabelas e índices estão na parte de baixo do diagrama e a saída final está na parte de cima.
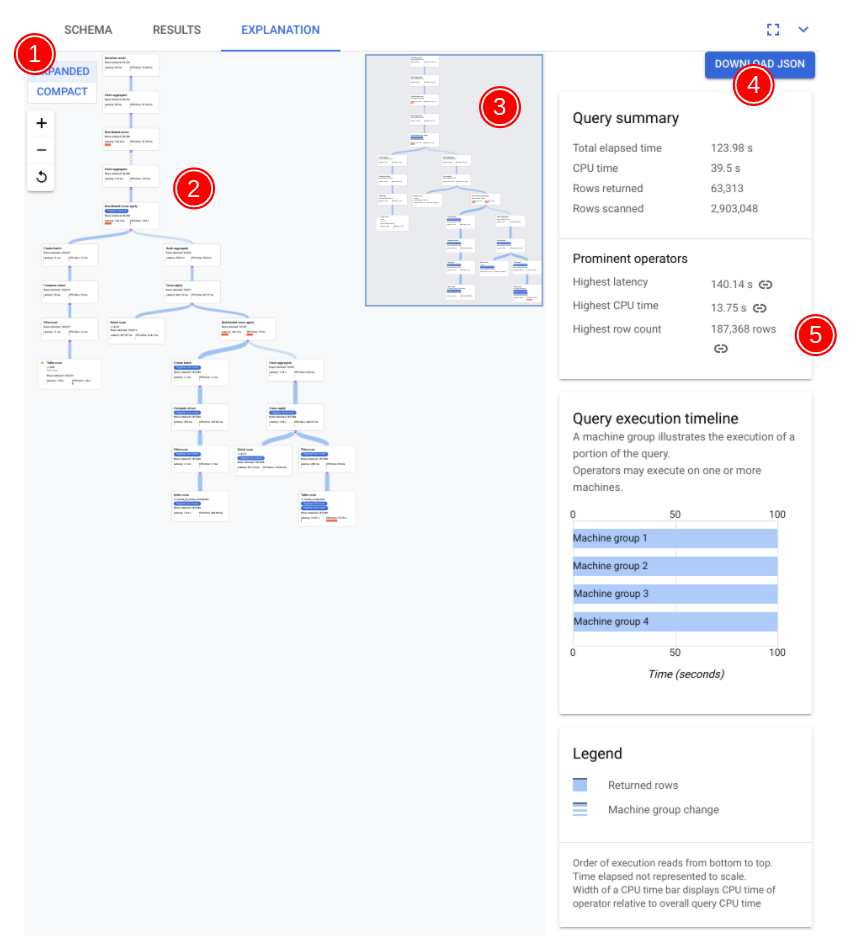
- A visualização do seu plano pode ser grande, dependendo da consulta executada. Para ocultar e mostrar detalhes, alterne o seletor de visualização EXPANDED/COMPACT. É possível personalizar a quantidade de plano exibida a qualquer momento usando o controle de zoom.
- A álgebra que explica como o Spanner executa a consulta
é desenhada como um gráfico acíclico, em que cada nó corresponde a um
iterador que consome linhas das entradas e produz linhas para o
pai. Veja um plano de amostra na Figura 9. Clique no diagrama
para ver uma visualização expandida de alguns dos detalhes do plano.
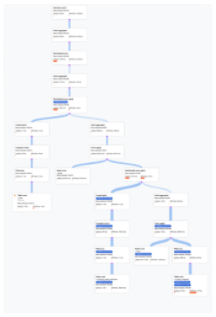
Figura 9. Exemplo de plano visual (clique para aumentar o zoom). 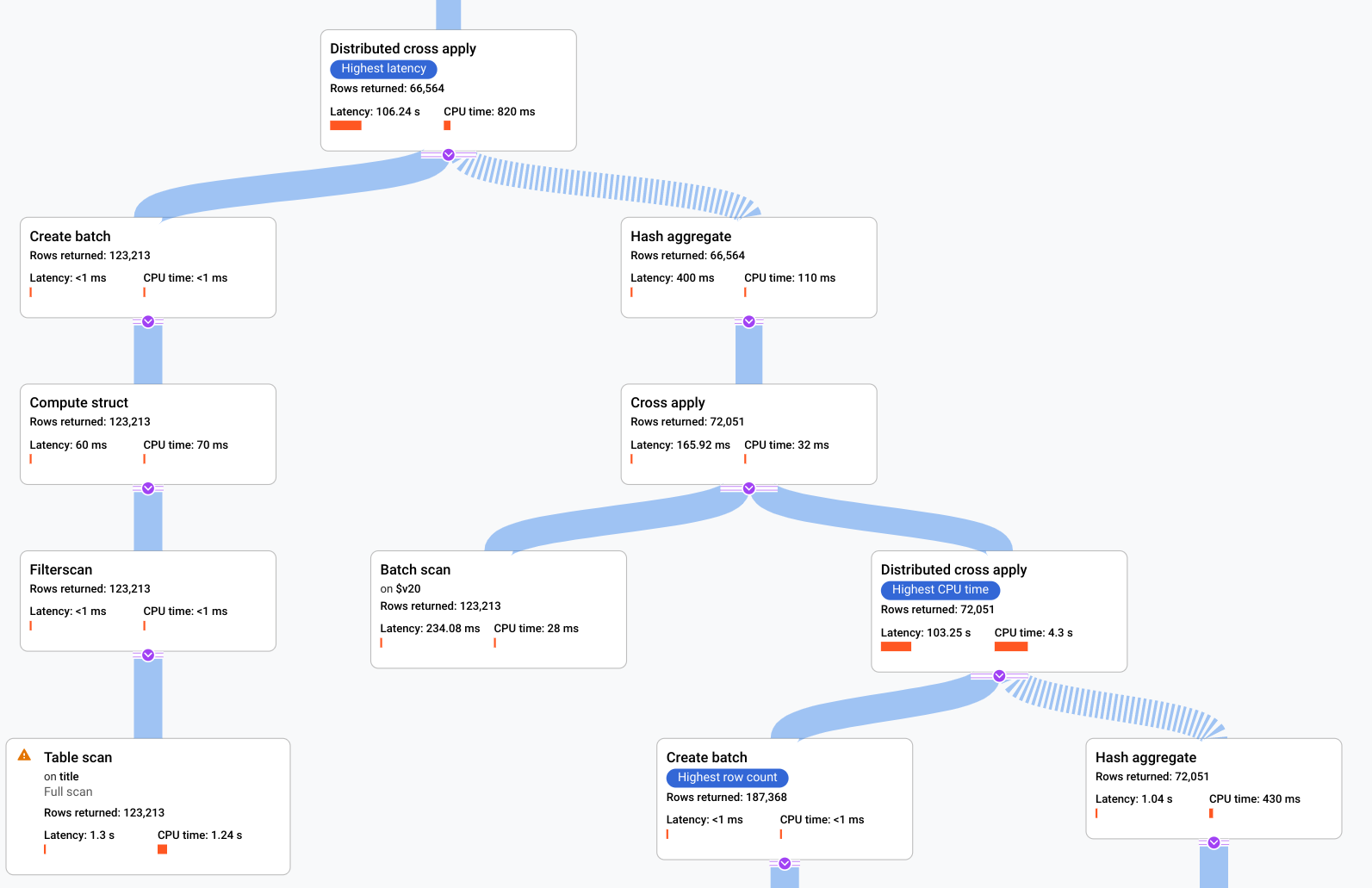
Cada nó, ou card, no gráfico representa um iterador e contém as seguintes informações:
- O nome do iterador. Um iterador consome linhas da sua entrada e produz linhas.
- As estatísticas do ambiente de execução informam quantas linhas foram retornadas, qual foi a latência e a quantidade de CPU foi consumida.
- Fornecemos as seguintes dicas visuais para ajudar você a identificar possíveis problemas no plano de execução da consulta.
- As barras vermelhas em um nó são indicadores visuais da porcentagem de latência ou tempo de CPU para este iterador em comparação com o total da consulta.
- A espessura das linhas que conectam cada nó representa a contagem de linhas. Quanto mais grossa a linha, maior o número de linhas transmitidas para o próximo nó. O número real de linhas é exibido em cada card e quando você passa o cursor sobre um conector.
- Um triângulo de alerta é exibido em um nó onde uma verificação completa da tabela foi realizada. Mais detalhes no painel de informações incluem recomendações, como adição de índice ou revisão da consulta ou esquema de outras maneiras, se possível, para evitar uma verificação completa.
- Selecione um cartão no plano para ver mais detalhes no painel de informações à direita (5).
- O minimapa do plano de execução mostra uma visualização ampliada do plano completo e é útil para determinar o formato geral do plano de execução e para navegar para diferentes partes do plano rapidamente. Arraste diretamente no minimapa ou clique no local em que você quer focar para acessar outra parte do plano visual.
Selecione FAZER O DOWNLOAD DO JSON para baixar uma versão JSON do plano de execução, o que é útil para a solução de problemas. Você também pode compartilhar esse ID ao entrar em contato com a equipe do Spanner para receber suporte. Salvar o JSON não salva o resultado da consulta.
Para fazer o download e salvar uma versão JSON do plano de execução para visualizar mais tarde:
- No Spanner Studio, execute uma consulta.
- Selecione a guia Explicação.
- Clique em FAZER O DOWNLOAD DO JSON para baixar a versão JSON do plano de execução.
- Salve e copie o conteúdo do arquivo JSON.
- Abra uma nova guia do editor de consultas.
- Na guia do editor, insira:
PROTO: CONTENT_OF_JSON
- Clique em Executar.
- Selecione a guia Explicação abaixo do editor de consultas para ver uma representação visual do plano de execução baixado.
- O painel de informações mostra informações contextuais detalhadas sobre
o nó selecionado no diagrama do plano de consulta. As informações são
organizadas nas seguintes categorias.
- Informações do iterador fornecem detalhes, bem como estatísticas de tempo de execução, para o cartão do iterador selecionado no gráfico.
- O Resumo da consulta fornece detalhes sobre o número de linhas retornadas e o tempo necessário para executar a consulta. Operadores de destaque são aqueles que exibem latência significativa, consomem CPU significativa em relação a outros operadores e retornam um número significativo de linhas de dados.
- O cronograma de execução de consulta é um gráfico baseado em tempo que mostra por quanto tempo cada grupo de máquinas estava executando sua parte da consulta. Um grupo de máquinas pode não estar necessariamente em execução durante toda a duração do tempo de execução da consulta. Também é possível que um grupo de máquinas tenha sido executado várias vezes durante a execução da consulta, mas a linha do tempo aqui representa apenas o início da primeira execução e o fim da última vez. foi executado.
Ajustar uma consulta que mostra desempenho insatisfatório
Imagine que sua empresa administra um banco de dados de filmes on-line que contém informações sobre filmes, como elenco, empresas de produção, detalhes de filmes e muito mais. O serviço é executado no Spanner, mas tem tido alguns problemas de desempenho recentemente.
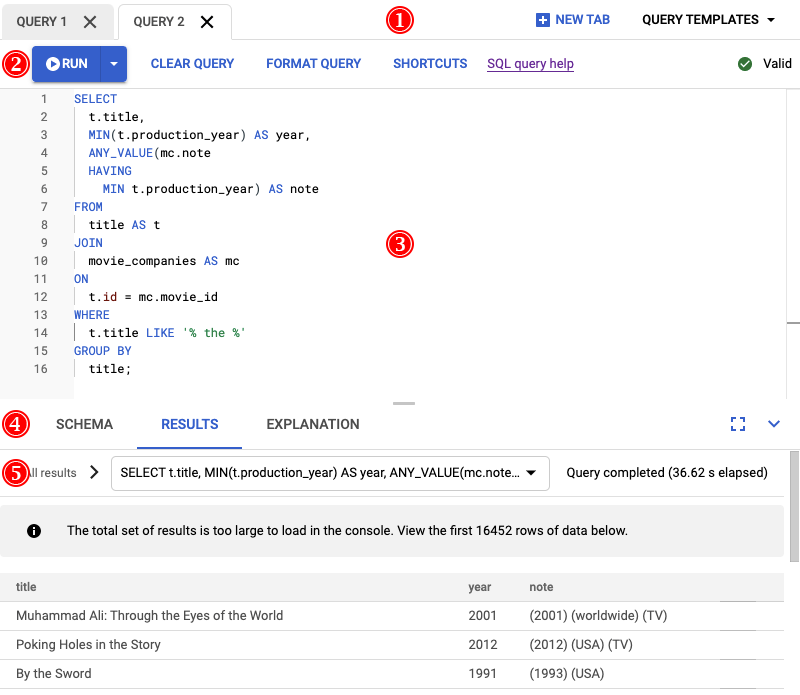
Como desenvolvedor líder do serviço, é necessário investigar esses problemas de desempenho, porque eles estão causando notas ruins para o serviço. Abra o console do Google Cloud , acesse a instância do banco de dados e abra o editor de consultas. Você insere a consulta a seguir no editor e a executa.
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
O resultado da execução dessa consulta é mostrado na captura de tela a seguir. Formatamos a consulta no editor selecionando FORMAT QUERY. Há também uma observação no canto superior direito da tela informando que a consulta é válida.
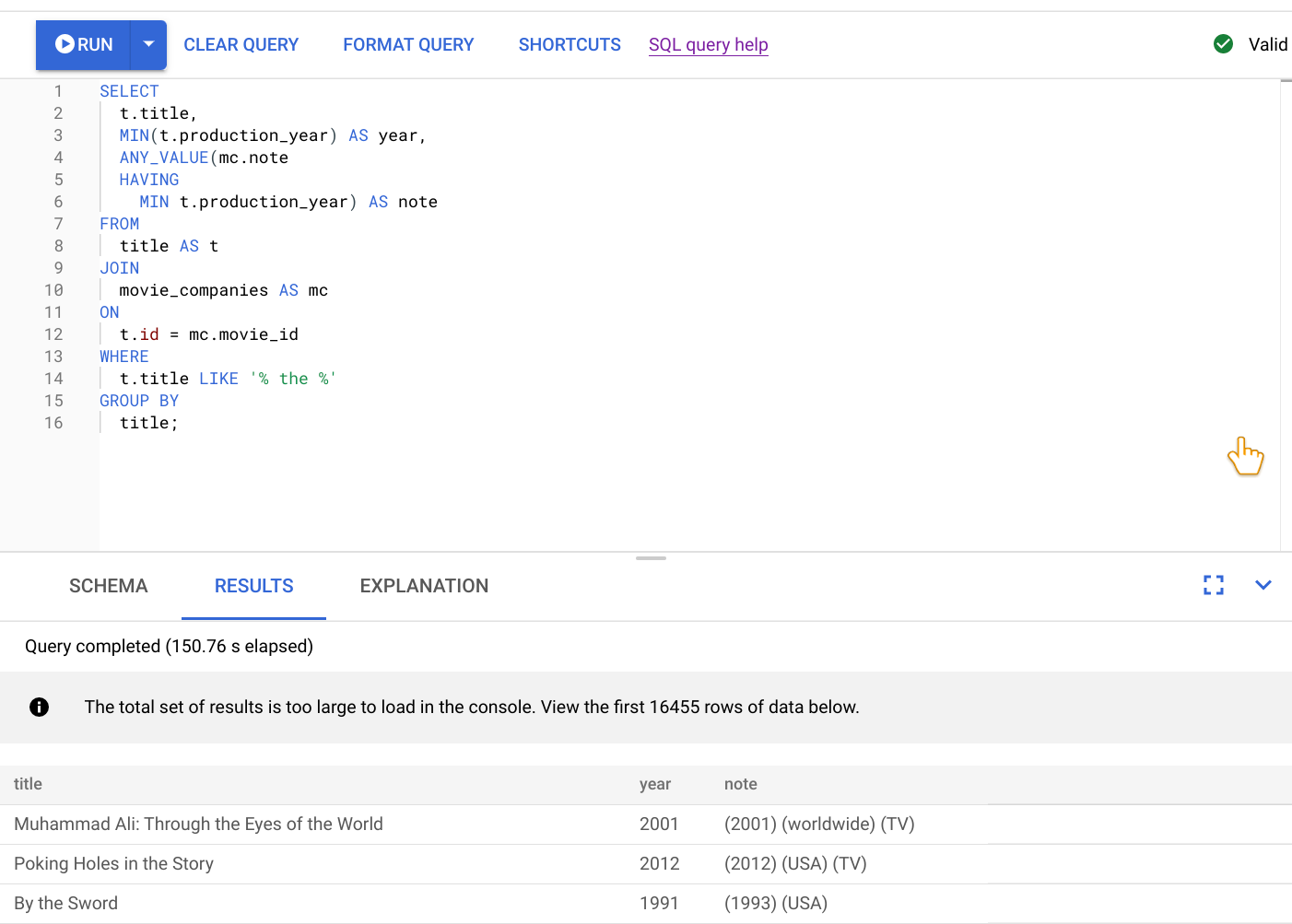
A guia RESULTADOS abaixo do editor de consultas mostra que a consulta foi concluída em pouco mais de dois minutos. Você decide olhar mais de perto para ver se a consulta é eficiente.
Analisar consultas lentas com o visualizador de planos de consulta
Neste ponto, sabemos que a consulta na etapa anterior leva dois minutos, mas não sabemos se ela é tão eficiente quanto possível e, portanto, se essa duração é esperada.
Selecione a guia EXPLANATION logo abaixo do editor de consultas para ver uma representação visual do plano de execução que o Spanner criou para executar a consulta e retornar resultados.
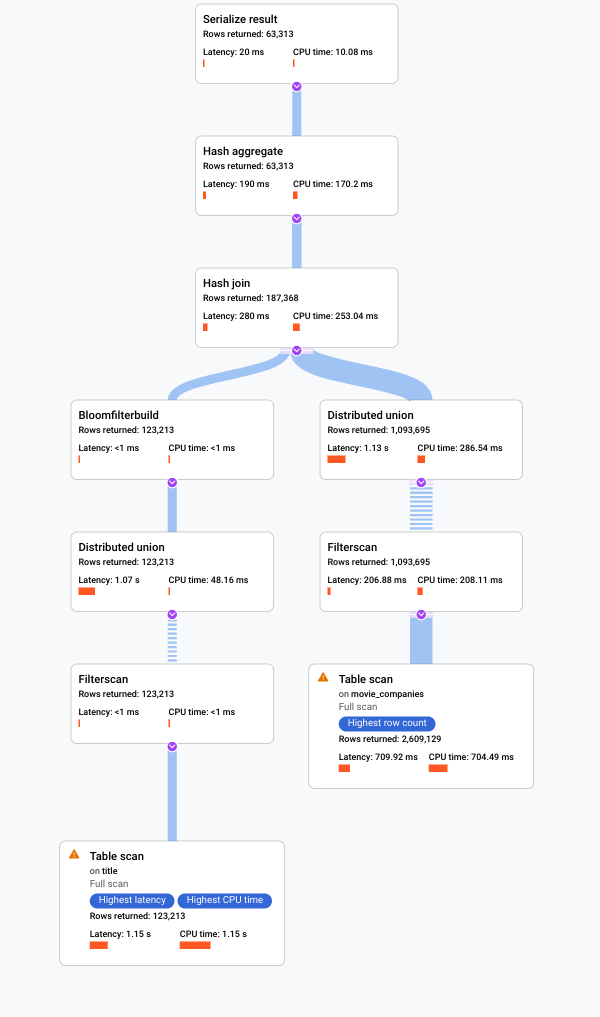
O plano mostrado na captura de tela a seguir é relativamente grande, mas, mesmo nesse nível de zoom, é possível fazer as seguintes observações.
Com base no resumo da consulta no painel de informações à direita, descobrimos que quase 3 milhões de linhas foram verificadas e, no máximo, 64 mil foram retornados.
Também podemos ver no painel Cronograma de execução da consulta que quatro grupos de máquinas estavam envolvidos na consulta. Um grupo de máquinas é responsável pela execução de uma parte da consulta. Os operadores podem ser executados em uma ou mais máquinas. A seleção de um grupo de máquinas na linha do tempo destaca no plano visual qual parte da consulta foi executada nesse grupo.
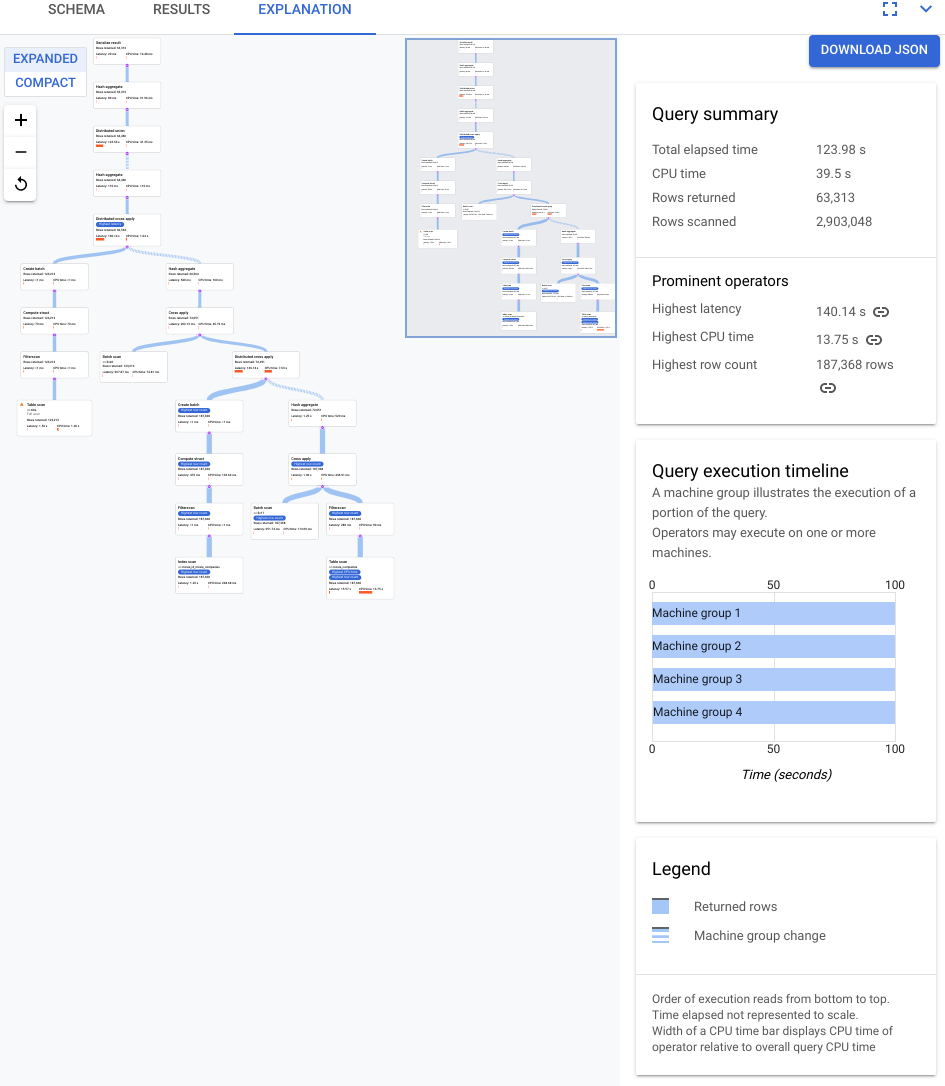
Por causa desses fatores, você decide que uma melhoria no desempenho pode ser possível alterando a junção de uma junção de aplicação, que o Spanner escolheu por padrão para uma união de hash.
Melhorar a consulta
Para melhorar o desempenho da consulta, use uma dica de junção para mudar o método de junção para uma junção de hash. Essa implementação de junção executa processamento baseado em conjunto.
Esta é a consulta atualizada:
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
A captura de tela a seguir ilustra a consulta atualizada. Conforme mostrado na captura de tela, a consulta foi concluída em menos de cinco segundos, uma melhoria significativa em tempo de execução de 120 segundos antes dessa alteração.
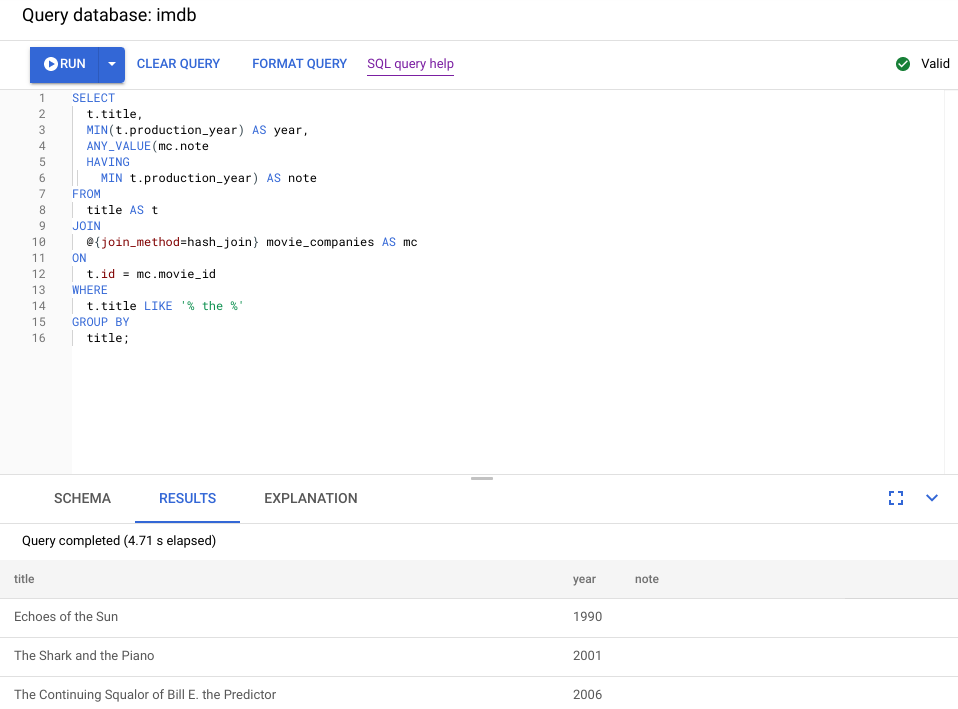
Examine o novo plano visual, mostrado no diagrama a seguir, para ver o que ele diz sobre essa melhoria.
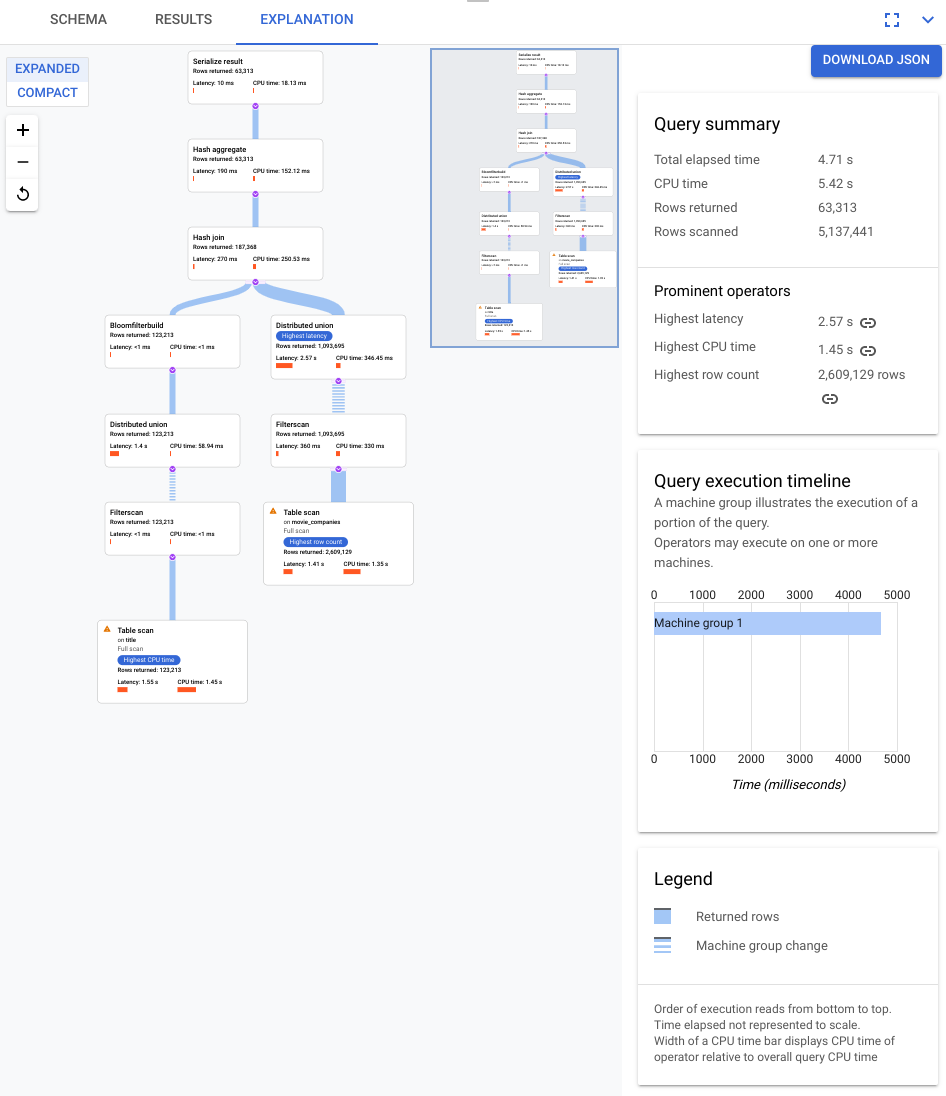
Imediatamente, você verá algumas diferenças:
Somente um grupo de máquinas foi envolvido nessa execução de consulta.
O número de agregações foi reduzido drasticamente.
Conclusão
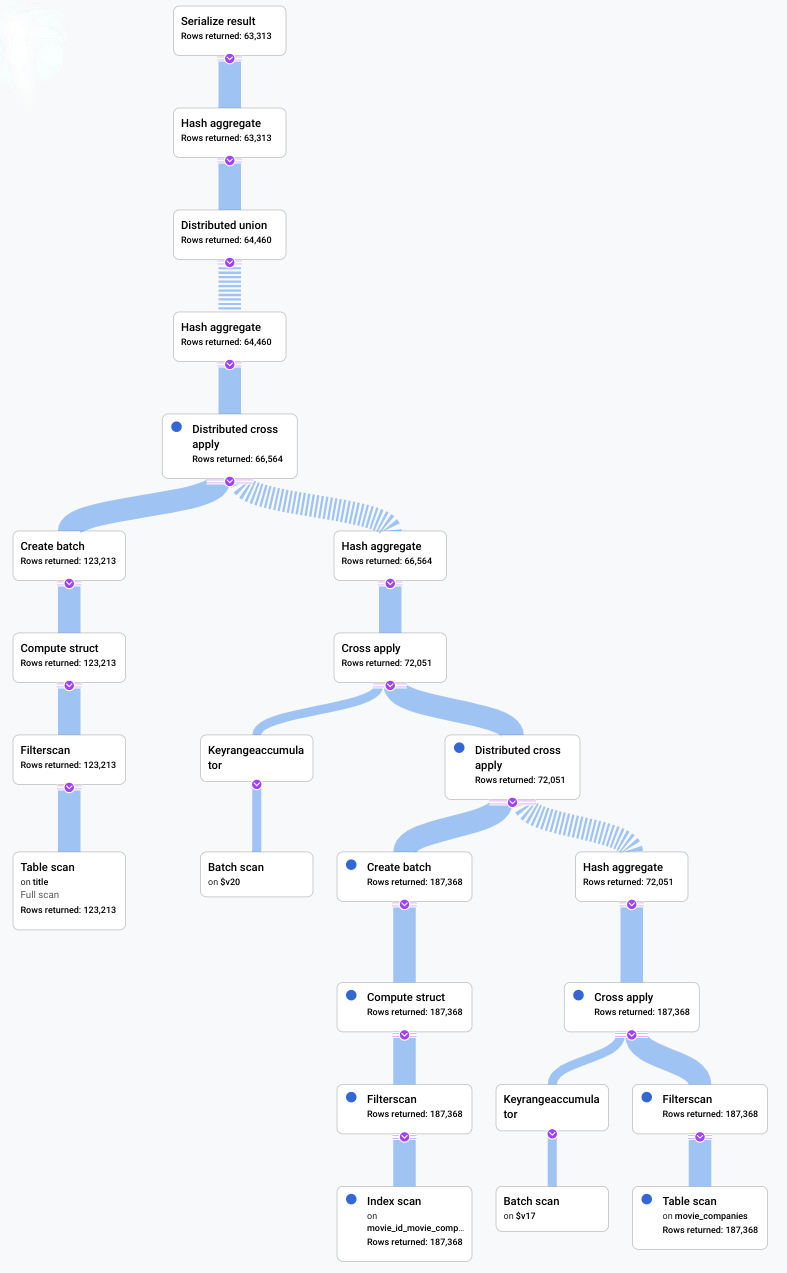
Nesse cenário, realizamos uma consulta lenta e analisamos seu plano visual para procurar ineficiências. Veja a seguir um resumo das consultas e dos planos antes e depois das alterações. Cada guia mostra a consulta que foi executada e uma visualização compacta da visualização completa do plano de execução.
Antes
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
Depois
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
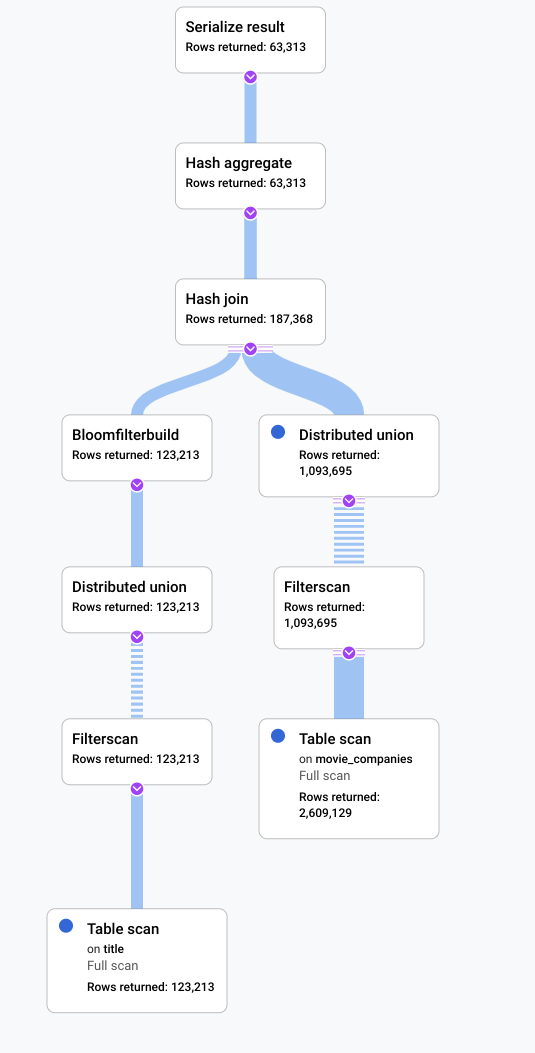
Um indicador de que algo poderia ser melhorado nesse cenário foi que uma grande proporção das linhas da tabela title qualificou o filtro LIKE
'% the %'. Ir para outra tabela com tantas linhas provavelmente será caro. Mudar nossa implementação de junção para uma junção de hash melhorou significativamente o desempenho.
A seguir
Para ver a referência completa do plano de consulta, consulte Planos de execução da consulta.
Para a referência completa do operador, consulte Operadores de execução de consulta.