Esta página descreve como usar o painel de controlo Estatísticas de consultas para detetar e analisar problemas de desempenho do Spanner.
Vista geral das estatísticas de consultas
As estatísticas de consultas ajudam a detetar e diagnosticar problemas de desempenho de consultas e
declarações DML (INSERT, UPDATE e DELETE)
para uma base de dados do Spanner. Suporta a monitorização intuitiva e fornece informações de diagnóstico que ajudam a ir além da deteção para identificar a causa essencial dos problemas de desempenho.
As estatísticas de consultas ajudam a melhorar o desempenho das consultas do Spanner, orientando-o através dos seguintes passos:
- Determine se as consultas ineficientes estão a causar uma elevada utilização da CPU.
- Identifique uma consulta ou uma etiqueta potencialmente problemática.
- Analisar a etiqueta de consulta ou pedido para identificar problemas.
As estatísticas de consultas estão disponíveis em configurações de região única e várias regiões.
Preços
Não existem custos adicionais para as estatísticas de consultas.
Retenção de dados
As estatísticas de consultas retêm dados durante um máximo de 30 dias.
Para o gráfico Utilização total da CPU (por etiqueta de consulta ou de pedido), o Spanner obtém dados das tabelas SPANNER_SYS.QUERY_STATS_TOP_*. Estas tabelas têm um período de retenção máximo de 30 dias. Consulte o artigo Retenção de dados
para saber mais.
Funções necessárias
Precisa de diferentes funções e autorizações do IAM, consoante seja um utilizador do IAM ou um utilizador do controlo de acesso detalhado.
Utilizador da gestão de identidade e de acesso (IAM)
Para receber as autorizações de que precisa para ver a página Estatísticas de consultas, peça ao seu administrador que lhe conceda as seguintes funções de IAM na instância:
-
Visitante do Cloud Spanner (
roles/spanner.viewer) -
Leitor da base de dados do Cloud Spanner (
roles/spanner.databaseReader)
São necessárias as seguintes autorizações na função Leitor da base de dados do Cloud Spanner(
roles/spanner.databaseReader)
para ver a página Estatísticas de consultas:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Utilizador com controlo de acesso detalhado
Se for um utilizador do controlo de acesso detalhado, verifique se:
- Ter o papel Cloud Spanner Viewer(
roles/spanner.viewer) - Têm privilégios de controlo de acesso detalhados e é-lhes concedida a
spanner_sys_readerfunção do sistema ou uma das respetivas funções de membro. - Selecione
spanner_sys_readerou uma função de membro como a função atual do sistema na página de vista geral da base de dados.
Para mais informações, consulte os artigos Acerca do controlo de acesso detalhado e Funções do sistema de controlo de acesso detalhado.
O painel de controlo Estatísticas de consultas
O painel de controlo Estatísticas de consultas mostra a carga de consultas com base na base de dados e no intervalo de tempo que selecionar. A carga de consultas é uma medição da utilização total da CPU para todas as consultas na instância no intervalo de tempo selecionado. O painel de controlo oferece uma série de filtros que ajudam a ver a carga de consultas.
Para ver o painel de controlo Estatísticas de consultas de uma base de dados, faça o seguinte:
- Selecione Estatísticas de consultas no painel de navegação do lado esquerdo. É aberto o painel de controlo de estatísticas de consultas.
- Selecione uma base de dados na lista Bases de dados. O painel de controlo mostra as informações de carga de consultas da base de dados.
As áreas do painel de controlo incluem:
- Lista de bases de dados: filtra a carga de consultas numa base de dados específica ou em todas as bases de dados.
- Filtro de intervalo de tempo: filtra o carregamento da consulta por intervalos de tempo, como horas, dias ou um intervalo personalizado.
- Gráfico de utilização total da CPU (todas as consultas): apresenta a carga agregada de todas as consultas.
- Gráfico de utilização total da CPU (por etiqueta de consulta ou de pedido): apresenta a utilização da CPU por cada etiqueta de consulta ou de pedido.
- Tabela de consultas e etiquetas TopN: apresenta a lista das principais consultas e etiquetas de pedidos ordenadas por utilização da CPU. Consulte o artigo Identifique uma consulta ou uma etiqueta potencialmente problemática.

Desempenho do painel de controlo
Use parâmetros de consulta ou etiquete as suas consultas para otimizar o desempenho das Estatísticas de consultas. Se não parametrizar nem etiquetar as consultas, podem ser devolvidos demasiados resultados, o que pode fazer com que a tabela de consultas e etiquetas TopN não seja carregada corretamente.
Confirme se as consultas ineficientes são responsáveis pela elevada utilização da CPU
A utilização total da CPU é uma medida do trabalho (em segundos de CPU) que as consultas executadas na base de dados selecionada realizam ao longo do tempo.

Reveja o gráfico para explorar estas perguntas:
Que base de dados está a sofrer a carga? Selecione bases de dados diferentes na lista Bases de dados para encontrar as bases de dados com os carregamentos mais elevados. Para saber que base de dados tem a carga mais elevada, também pode rever o gráfico Utilização da CPU – total para bases de dados na Google Cloud consola.
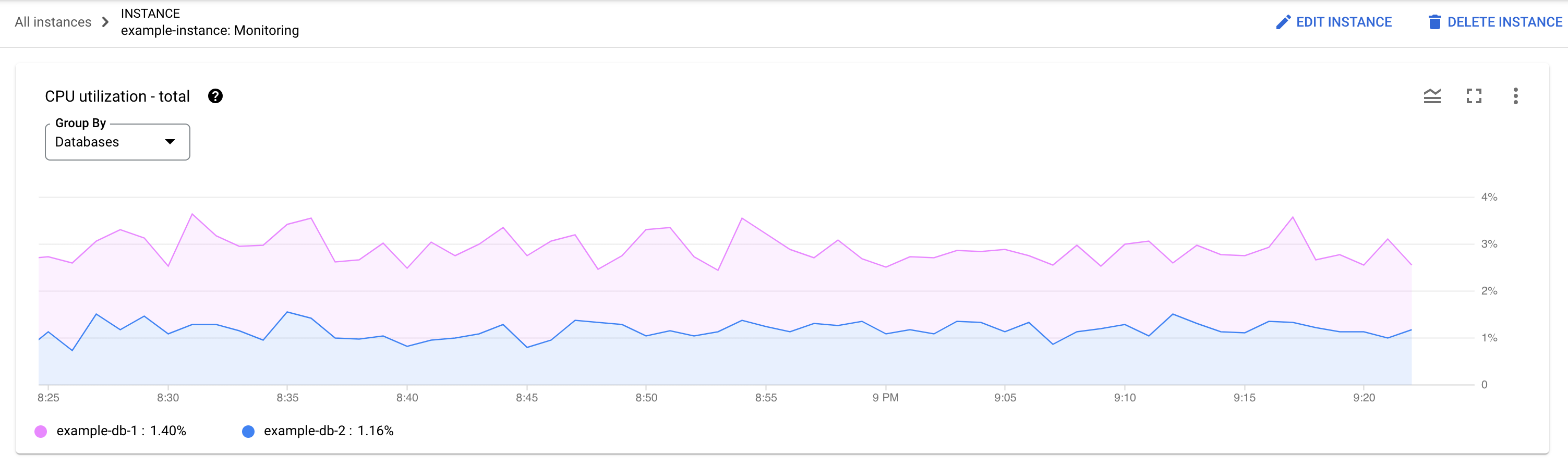
A utilização da CPU é elevada? O gráfico está a ter picos ou está elevado ao longo do tempo? Se não vir uma utilização elevada da CPU, o problema não está nas suas consultas.
Há quanto tempo é elevada a utilização da CPU? Aumentou recentemente ou tem sido consistentemente elevado durante algum tempo? Use o seletor de intervalo para selecionar vários períodos para saber quanto tempo o problema durou. Aumente o zoom para ver um período em que se observam picos de carga de consultas. Diminua o zoom para ver até uma semana da cronologia.
Se vir um pico ou uma elevação no gráfico correspondente à utilização geral da CPU da instância, é muito provável que se deva a uma ou mais consultas dispendiosas. Em seguida, pode analisar mais detalhadamente o processo de depuração identificando uma etiqueta de consulta ou de pedido potencialmente problemática.
Identifique uma consulta ou uma etiqueta de pedido potencialmente problemática
Para identificar uma consulta ou uma etiqueta de pedido potencialmente problemática, observe a secção TopN queries:
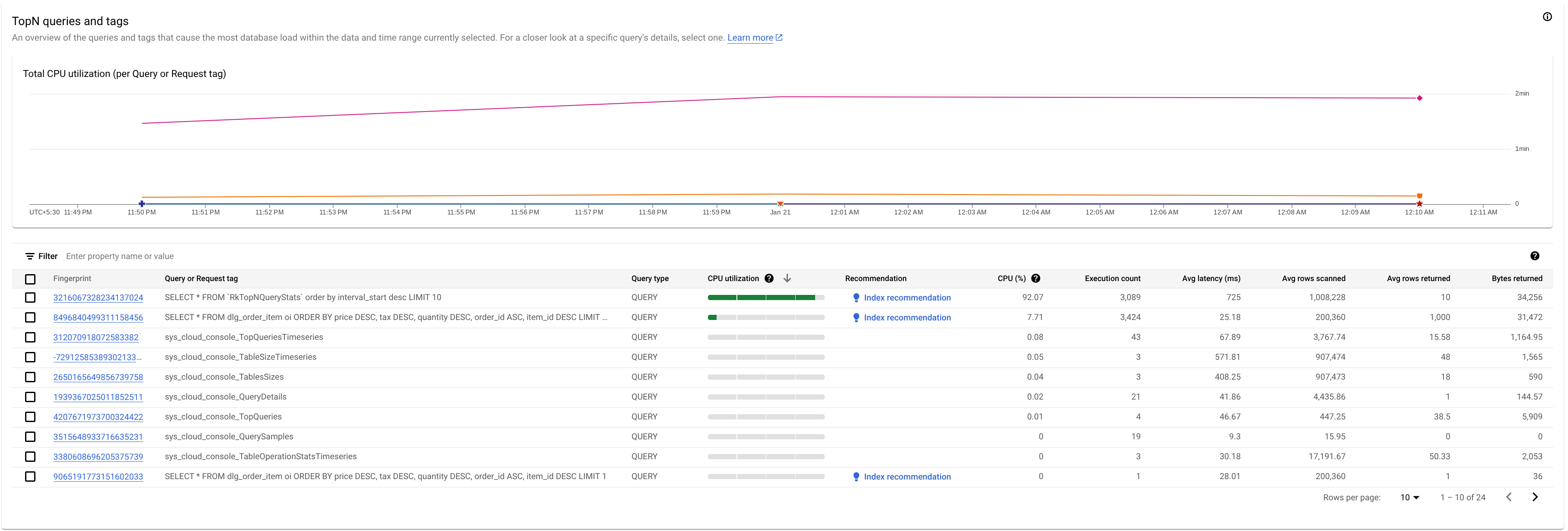
Aqui, vemos que a consulta com a impressão digital 3216067328234137024 tem uma utilização elevada da CPU e pode ser problemática.
A tabela Principais N consultas oferece uma vista geral das consultas que usam a maior quantidade de CPU durante o período escolhido, ordenadas da mais alta para a mais baixa. O número de consultas TopN está limitado a 100.
Para os gráficos, obtemos os dados da tabela de estatísticas de consultas TopN, que tem três granularidades diferentes: 1 minuto, 10 minutos e 1 hora. O valor de cada ponto de dados nos gráficos representa o valor médio durante um intervalo de um minuto.
Recomendamos que adicione etiquetas às suas consultas SQL. A etiquetagem de consultas ajuda a encontrar problemas em construções de nível superior, como a lógica empresarial ou um microsserviço.

A tabela mostra as seguintes propriedades:
- Impressão digital: hash da etiqueta de pedido ou, se a etiqueta não estiver presente, um hash do texto da consulta.
Etiqueta de consulta ou de pedido: se a consulta tiver uma etiqueta associada, é apresentada a etiqueta de pedido. As estatísticas de várias consultas que têm a mesma string de etiqueta são agrupadas numa única linha com o valor
REQUEST_TAGa corresponder à string de etiqueta. Para saber mais sobre a utilização de etiquetas de pedidos, consulte o artigo Resolução de problemas com etiquetas de pedidos e etiquetas de transações.Se a consulta não tiver uma etiqueta associada, é apresentada a consulta SQL, truncada para aproximadamente 64 KB. Para DML em lote, as declarações SQL são reduzidas a uma única linha e concatenadas, usando um delimitador de ponto e vírgula. Os textos SQL idênticos consecutivos são desduplicados antes de serem truncados.
Tipo de consulta: indica se uma consulta é
PARTITIONED_QUERYouQUERY. UmPARTITIONED_QUERYé uma consulta com umpartitionTokenobtido a partir da API PartitionQuery. Todas as outras consultas e declarações DML são indicadas pelo tipo de consultaQUERY.Utilização da CPU: consumo de recursos da CPU por uma consulta, como percentagem dos recursos totais da CPU usados por todas as consultas em execução nas bases de dados nesse intervalo de tempo, apresentado numa barra horizontal com um intervalo de 0 a 100.
Recomendação: o Spanner analisa as suas consultas para determinar se podem beneficiar de índices melhorados. Se for o caso, recomenda índices novos ou alterados que podem melhorar o desempenho das consultas. Para mais informações, consulte o artigo Use o consultor de índices do Spanner.
CPU (%): consumo de recursos da CPU por uma consulta, como uma percentagem dos recursos totais da CPU usados por todas as consultas em execução nas bases de dados nesse intervalo de tempo.
Contagem de execuções: número de vezes que o Spanner viu a consulta durante o intervalo.
Latência média (ms): duração média, em microsegundos, da execução de cada consulta na base de dados. Esta média exclui o tempo de codificação e transmissão do conjunto de resultados, bem como as despesas gerais.
Linhas analisadas médias: número médio de linhas que a consulta analisou, excluindo os valores eliminados.
Linhas devolvidas médias: número médio de linhas que a consulta devolveu.
Bytes devolvidos: número de bytes de dados que a consulta devolveu, excluindo a sobrecarga de codificação de transmissão.
Possível variação entre os gráficos
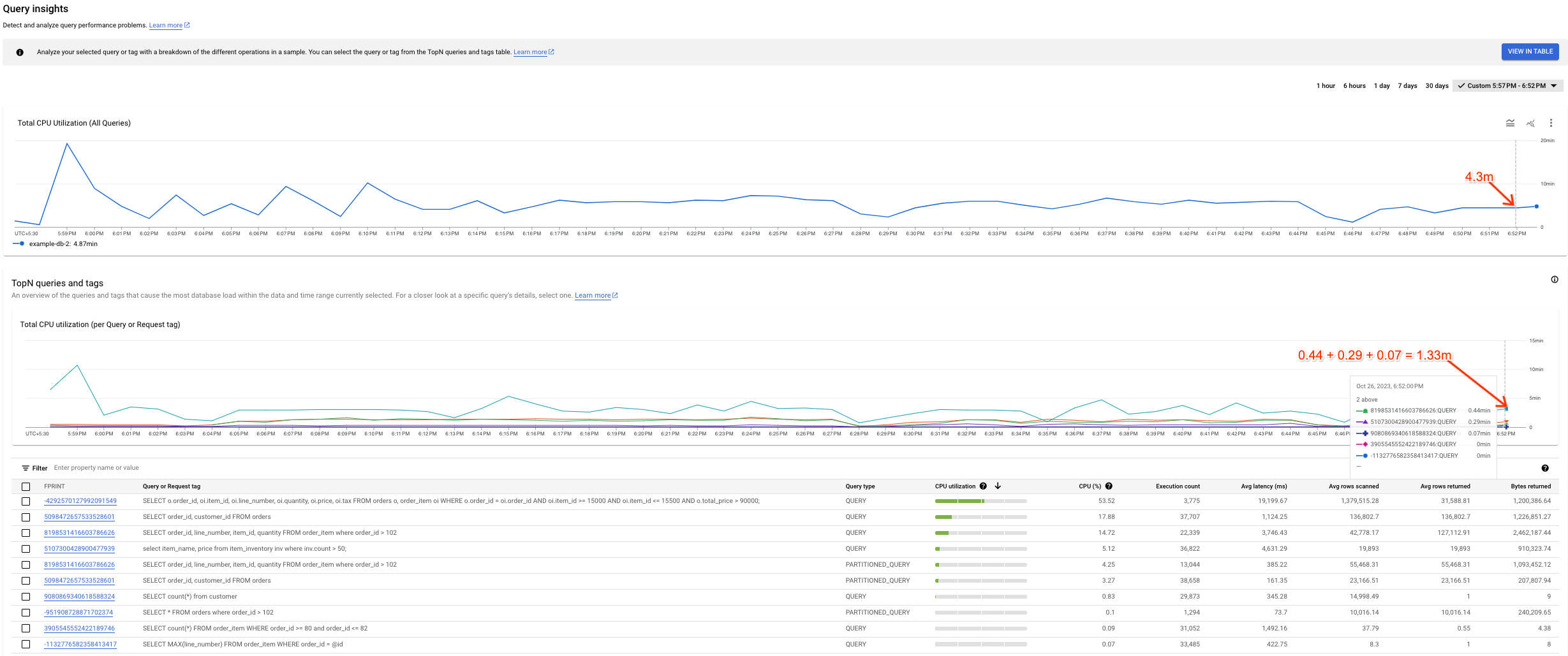
Pode notar alguma variação entre o gráfico Utilização total da CPU (todas as consultas) e o gráfico Utilização total da CPU (por etiqueta de consulta ou de pedido). Existem duas situações que podem levar a este cenário:
Diferentes origens de dados: os dados do Cloud Monitoring, que alimentam o gráfico Total CPU Utilization (all queries), são normalmente mais precisos porque são enviados a cada minuto e têm um período de retenção de 45 dias. Por outro lado, os dados da tabela do sistema, que alimentam o gráfico de utilização total da CPU (por consulta ou etiqueta de pedido), podem ser calculados em média durante 10 minutos (ou 1 hora). Neste caso, podemos perder dados de elevada granularidade que vemos no gráfico de utilização total da CPU (todas as consultas).
Intervalos de agregação diferentes: ambos os gráficos têm intervalos de agregação diferentes. Por exemplo, quando inspecionamos um evento com mais de 6 horas, consultamos a tabela
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE. Neste caso, um evento que ocorra às 10:01 é agregado durante 10 minutos e está presente na tabela do sistema correspondente à data/hora de 10:10.
A captura de ecrã seguinte mostra um exemplo dessa variação.
Analise uma consulta ou uma etiqueta de pedido específica
Para determinar se uma consulta ou uma etiqueta de pedido é a causa principal do problema, clique na consulta ou na etiqueta de pedido que pareça ter o carregamento mais elevado ou que esteja a demorar mais tempo do que as outras. Pode selecionar várias consultas e pedir etiquetas em simultâneo.
Pode manter o ponteiro do rato no gráfico para ver as consultas ao longo da cronologia e saber a respetiva utilização da CPU (em segundos).
Tente restringir o problema analisando o seguinte:
- Há quanto tempo é que a carga está elevada? Só está alto agora? Ou está elevado há muito tempo? Altere os intervalos de tempo para encontrar a data e a hora em que a consulta começou a ter um desempenho fraco.
- Houve picos na utilização da CPU? Pode alterar o período para analisar a utilização do CPU do histórico da consulta.
- Qual é o consumo de recursos? Como se relaciona com outras consultas? Analise a tabela e compare os dados de outras consultas com a selecionada. Existe uma diferença significativa?
Para confirmar que a consulta selecionada está a contribuir para a elevada utilização da CPU, pode ver detalhes da forma de consulta específica (ou etiqueta de pedido) e analisá-la mais detalhadamente na página Detalhes da consulta.
Veja a página de detalhes da consulta
Para ver os detalhes de uma forma de consulta ou uma etiqueta de pedido específica num formato gráfico, clique na impressão digital associada à consulta ou à etiqueta de pedido. É apresentada a página Detalhes da consulta.
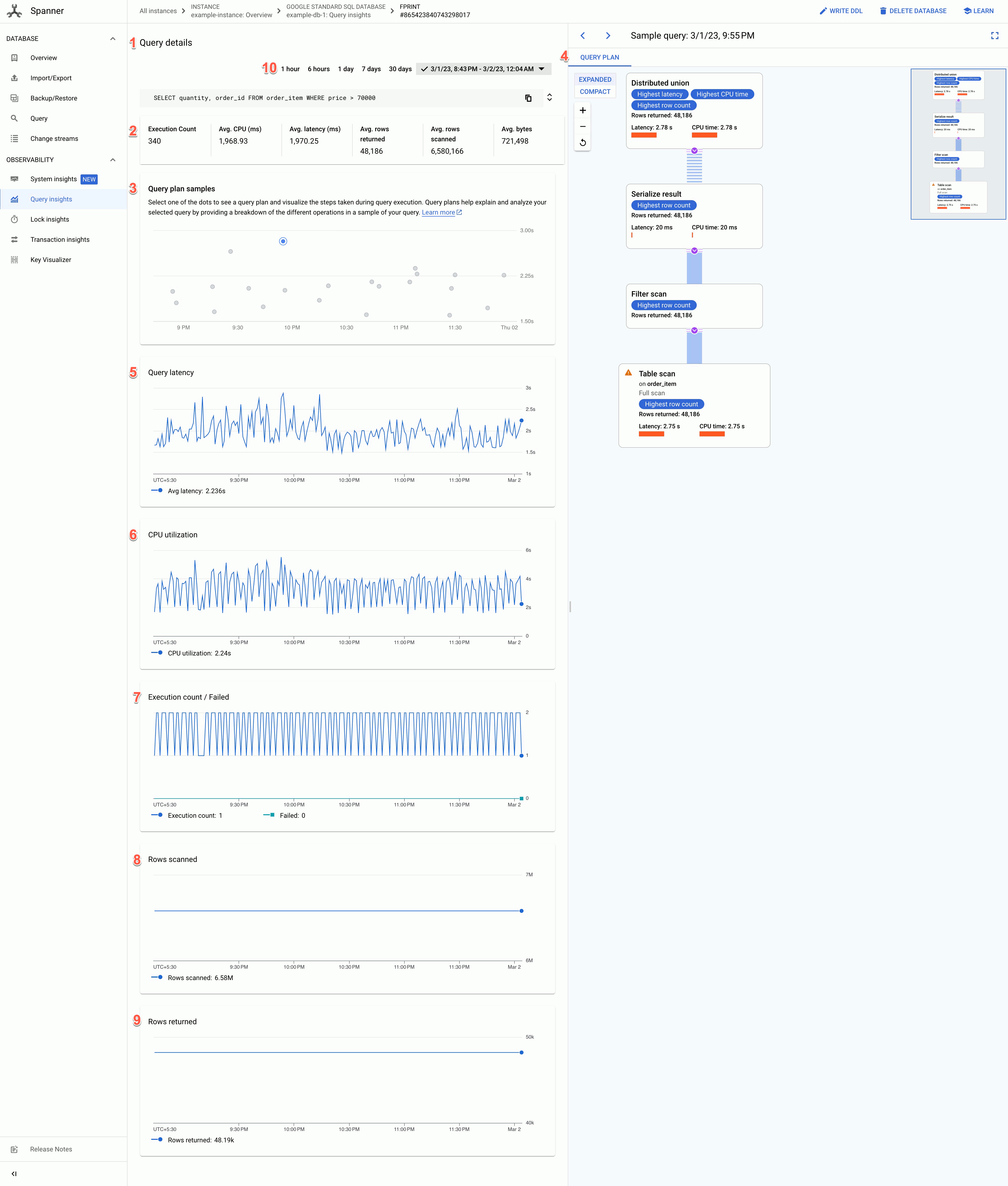
A página Detalhes da consulta mostra as seguintes informações:
- Texto dos detalhes da consulta: texto da consulta SQL, truncado para aproximadamente 64 KB. As estatísticas de várias consultas que têm a mesma string de etiqueta são agrupadas numa única linha com a REQUEST_TAG correspondente a essa string de etiqueta. Apenas o texto de uma dessas consultas é apresentado neste campo. Para DML em lote, o conjunto de declarações SQL é reduzido a uma única linha, concatenada com um delimitador de ponto e vírgula. Os textos SQL idênticos consecutivos são desduplicados antes de serem truncados.
- Os valores dos seguintes campos:
- Contagem de execuções: número de vezes que o Spanner viu a consulta durante o intervalo.
- Média da CPU (ms): consumo médio de recursos da CPU, em milissegundos, por uma consulta dos recursos da CPU da instância num intervalo de tempo.
- Latência média (ms): duração média, em milissegundos, de cada execução de consulta na base de dados. Esta média exclui o tempo de codificação e transmissão do conjunto de resultados e da sobrecarga.
- Média de linhas devolvidas: número médio de linhas que a consulta devolveu.
- Média de linhas analisadas: número médio de linhas que a consulta analisou, excluindo os valores eliminados.
- Média de bytes: número de bytes de dados devolvidos pela consulta, excluindo a sobrecarga de codificação de transmissão.
- Gráfico de exemplos de planos de consultas: cada ponto no gráfico representa um plano de consultas com amostras num momento específico e a respetiva latência de consulta específica. Clique num dos pontos no gráfico para ver o plano de consulta e visualizar os passos realizados durante a execução da consulta. Nota: os planos de consulta não são suportados para consultas com partitionTokens obtidos a partir da API PartitionQuery e consultas DML particionadas.
Visualizador do plano de consulta: mostra o plano de consulta com amostragem selecionado. O Spanner oferece as seguintes opções de esquema:
- Vista de árvore: a vista de árvore visualiza o plano de consulta como um gráfico em que cada nó ou cartão representa um iterador que consome linhas das respetivas entradas e produz linhas para o respetivo elemento principal. Pode clicar em cada iterador para ver informações expandidas.
Vista sequencial: a vista sequencial visualiza o plano de consulta numa tabela hierárquica em que cada linha representa um operador. Pode clicar em cada linha para ver informações expandidas.

A tabela apresenta as seguintes colunas:
- Nome: o nome do operador.
- Grupo de máquinas: o grupo de máquinas onde este operador foi executado.
- Latência: o tempo decorrido durante a execução da operação atual. Isto pode ser superior ao tempo da CPU (por exemplo, se o operador aguardou chamadas remotas ou um atraso do sistema de ficheiros).
- Latência cumulativa: a quantidade de tempo decorrido durante a execução de toda a subárvore com raiz neste operador. Isto não inclui o tempo de criação do plano nem outros custos gerais. Por isso, a latência cumulativa pode ser inferior à duração total da consulta.
- Tempo de CPU: o tempo total de CPU gasto na execução da consulta. Exclui a latência de rede. Algumas partes da execução de consultas podem decorrer em paralelo, pelo que é possível que o tempo de CPU seja superior ao tempo decorrido total. Por exemplo, se uma consulta executar dez operações paralelas em 1 milissegundo (ms), o tempo decorrido é de 1 ms, mas o tempo de CPU é de 10 ms.
- Linhas devolvidas: o número de linhas devolvidas pelo operador.
Gráfico de latência de consultas: mostra o valor da latência de consultas para uma consulta selecionada durante um período. Também mostra a latência média.
Gráfico de utilização da CPU: mostra a utilização da CPU por uma consulta, em percentagem, durante um período. Também mostra a utilização média da CPU.
Gráfico de contagem de execuções/falhas: mostra a contagem de execuções de uma consulta durante um período e o número de vezes que a execução da consulta falhou.
Gráfico de linhas analisadas: mostra o número de linhas que a consulta analisou durante um período.
Gráfico de linhas devolvidas: mostra o número de linhas que a consulta devolveu durante um período.
Filtro de intervalo de tempo: filtra os detalhes da consulta por intervalos de tempo, como hora, dia ou um intervalo personalizado.
Para os gráficos, obtemos os dados da tabela de estatísticas de consultas TopN, que tem três granularidades diferentes: 1 minuto, 10 minutos e 1 hora. O valor de cada ponto de dados nos gráficos representa o valor médio durante um intervalo de um minuto.
Pesquise todas as execuções de uma consulta no registo de auditoria
Para pesquisar todas as execuções de uma determinada impressão digital de consulta nos
registos de auditoria do Google Cloud,
consulte o registo de auditoria e pesquise qualquer
query_fingerprint que corresponda ao campo Fingerprint na tabela de estatísticas de consultas TopN. Para mais informações, consulte o artigo Vista geral das consultas e visualização de registos. Use este método para identificar o utilizador que iniciou a consulta.