Cette page explique comment utiliser la récupération à un moment précis (PITR) pour conserver et récupérer des données dans Spanner pour les bases de données utilisant le dialecte GoogleSQL et celles utilisant le dialecte PostgreSQL.
Pour en savoir plus, consultez la section Récupération à un moment précis.
Prérequis
Ce guide utilise la base de données et le schéma définis dans le guide de démarrage rapide de Spanner. Vous pouvez suivre le guide de démarrage rapide pour créer la base de données et le schéma, ou modifier les commandes à utiliser avec votre propre base de données.
Définir la durée de conservation
Pour définir la durée de conservation de votre base de données, procédez comme suit :
Console
Accédez à la page "Instances Spanner" dans la consoleGoogle Cloud .
Cliquez sur l'instance contenant la base de données pour ouvrir la page Présentation correspondante.
Cliquez sur la base de données pour ouvrir la page Présentation correspondante.
Sélectionnez l'onglet Sauvegarder/Restaurer.
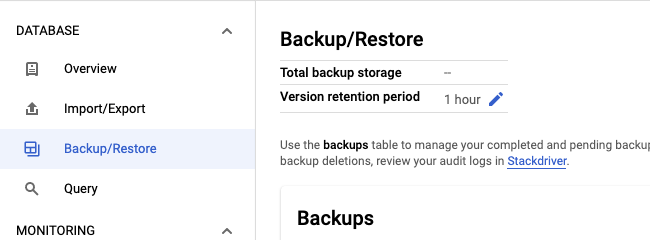
Cliquez sur l'icône en forme de crayon dans le champ Durée de conservation de la version.
Saisissez une quantité et une unité de temps pour la durée de conservation, puis cliquez sur Mettre à jour.
gcloud
Mettez à jour le schéma de la base de données avec l'instruction ALTER DATABASE. Exemple :
gcloud spanner databases ddl update example-db \
--instance=test-instance \
--ddl='ALTER DATABASE `example-db` \
SET OPTIONS (version_retention_period="7d");'Pour afficher la durée de conservation, obtenez le LDD de votre base de données :
gcloud spanner databases ddl describe example-db \
--instance=test-instanceVoici le résultat :
ALTER DATABASE example-db SET OPTIONS (
version_retention_period = '7d'
);
...
Bibliothèques clientes
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Remarques concernant l'utilisation :
- La durée de conservation doit être comprise entre 1 heure et 7 jours, et peut être spécifiée en jours, en heures, en minutes ou en secondes. Par exemple, les valeurs
1d,24h,1440met86400ssont équivalentes. - Si vous avez activé la journalisation pour l'API Spanner dans votre projet, l'événement est consigné en tant que UpdateDatabaseDdl et est visible dans l'explorateur de journaux.
- Pour rétablir la durée de conservation par défaut d'une heure, vous pouvez définir l'option de base de données
version_retention_periodsurNULLpour les bases de données GoogleSQL ou surDEFAULTpour les bases de données PostgreSQL. - Lorsque vous prolongez la durée de conservation, le système ne remplit pas les versions précédentes des données. Par exemple, si vous prolongez la durée de conservation de 1 heure à 24 heures, vous devez attendre 23 heures pour que le système accumule d'anciennes données avant de pouvoir récupérer les données des 24 heures précédentes.
Obtenir la durée de conservation et la date de la première version
La ressource Database (Base de données) comporte deux champs :
version_retention_period: période pendant laquelle Spanner conserve toutes les versions de données de la base de données.earliest_version_time: horodatage le plus ancien à partir duquel les anciennes versions des données peuvent être lues dans la base de données. Cette valeur est mise à jour en continu par Spanner et devient obsolète au moment où elle est interrogée. Si vous utilisez cette valeur pour récupérer des données, veillez à tenir compte du moment où la valeur est interrogée jusqu'au moment où vous lancez la récupération.
Console
Accédez à la page "Instances Spanner" dans la console Google Cloud .
Cliquez sur l'instance contenant la base de données pour ouvrir la page Présentation correspondante.
Cliquez sur la base de données pour ouvrir la page Présentation correspondante.
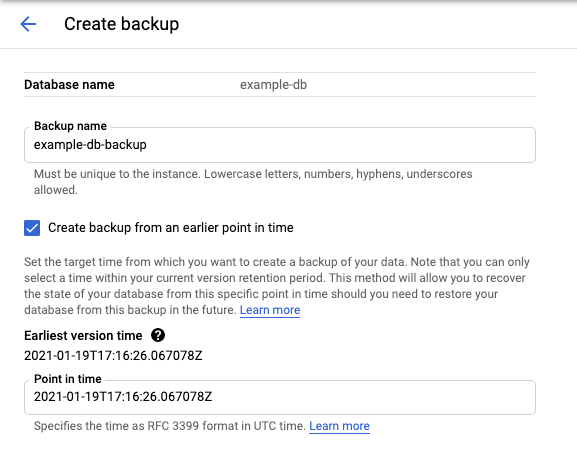
Sélectionnez l'onglet Sauvegarder/Restaurer pour ouvrir la page Sauvegarder/Restaurer et afficher la durée de conservation.
Cliquez sur Créer pour ouvrir la page Créer une sauvegarde et afficher l'heure de la version la plus ancienne.
gcloud
Vous pouvez obtenir ces champs en appelant describe databases ou list databases. Exemple :
gcloud spanner databases describe example-db \
--instance=test-instanceVoici le résultat :
createTime: '2020-09-07T16:56:08.285140Z'
earliestVersionTime: '2020-10-07T16:56:08.285140Z'
name: projects/my-project/instances/test-instance/databases/example-db
state: READY
versionRetentionPeriod: 3d
Récupérer une partie de votre base de données
Effectuez une lecture non actualisée et spécifiez l'horodatage de récupération nécessaire. Assurez-vous que le code temporel que vous spécifiez est plus récent que celui de la base de données (
earliest_version_time.).gcloud
Utilisez execute-sql. Par exemple :
gcloud spanner databases execute-sql example-db \ --instance=test-instance --read-timestamp=2020-09-11T10:19:36.010459-07:00\ --sql='SELECT * FROM SINGERS'Bibliothèques clientes
Stockez les résultats de la requête. Cette opération est nécessaire, car vous ne pouvez pas réécrire les résultats de la requête dans la base de données de la même transaction. Pour de petites quantités de données, vous pouvez imprimer sur la console ou stocker en mémoire. Pour des données plus importantes, vous devrez peut-être écrire dans un fichier local.
Réécrivez les données récupérées dans la table à récupérer. Exemple :
gcloud
gcloud spanner rows update --instance=test-instance --database=example-db --table=Singers \ --data=SingerId=1,FirstName='Marc'Pour en savoir plus, consultez la section Mettre à jour des données à l'aide de gcloud.
Bibliothèques clientes
Pour en savoir plus, consultez Mettre à jour des données à l'aide du langage LMD ou Mettre à jour des données à l'aide de mutations.
Si vous souhaitez analyser les données récupérées avant de les réécrire, vous pouvez créer manuellement une table temporaire dans la même base de données, y écrire les données récupérées, effectuer l'analyse, puis lire les données que vous souhaitez récupérer à partir de cette table temporaire et les écrire dans la table à récupérer.
Récupérer une base de données entière
Vous pouvez récupérer l'intégralité de la base de données à l'aide de la fonctionnalité Sauvegarder et restaurer ou Importer et exporter, et en spécifiant un horodatage de récupération.
Sauvegarde et restauration
Créez une sauvegarde et définissez
version_timesur l'horodatage de récupération nécessaire.Console
Accédez à la page Détails de la base de données dans la console Cloud.
Dans l'onglet Sauvegarder/Restaurer, cliquez sur Créer.
Cochez la case Créer une sauvegarde à un moment antérieur.
gcloud
gcloud spanner backups create example-db-backup-1 \ --instance=test-instance \ --database=example-db \ --retention-period=1y \ --version-time=2021-01-22T01:10:35Z --asyncPour en savoir plus, consultez la section Créer une sauvegarde à l'aide de gcloud.
Bibliothèques clientes
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Restaurer à partir de la sauvegarde dans une nouvelle base de données. Notez que Spanner conserve le paramètre de durée de conservation de la sauvegarde dans la base de données restaurée.
Console
Accédez à la page Détails de l'instance dans la console Cloud.
Dans l'onglet Sauvegarder/Restaurer, sélectionnez une sauvegarde, puis cliquez sur Restaurer.
gcloud
gcloud spanner databases restore --async \ --destination-instance=destination-instance --destination-database=example-db-restored \ --source-instance=test-instance --source-backup=example-db-backup-1Pour en savoir plus, consultez la section Restaurer une base de données à partir d'une sauvegarde.
Bibliothèques clientes
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Importation et exportation
- Exportez la base de données en spécifiant le paramètre
snapshotTimevers l'horodatage de récupération nécessaire.Console
Accédez à la page Détails de l'instance dans la console Cloud.
Dans l'onglet Importer/Exporter, cliquez sur Exporter.
Cochez la case Exporter la base de données à un moment antérieur.
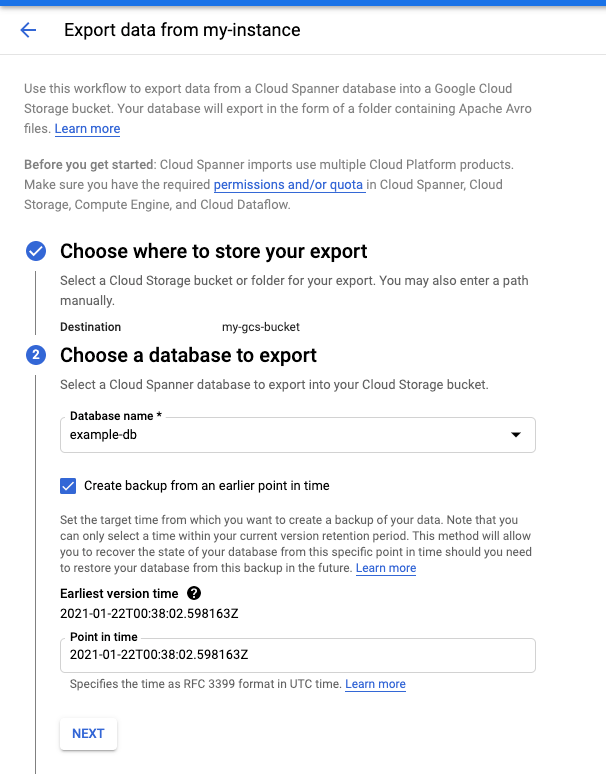
Pour obtenir des instructions détaillées, consultez la section Exporter une base de données.
gcloud
Exportez la base de données à l'aide du modèle Dataflow Spanner vers Avro.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/export/templates/Cloud_Spanner_to_GCS_Avro' --region=DATAFLOW_REGION \ --parameters='instanceId=test-instance,databaseId=example-db,outputDir=YOUR_GCS_DIRECTORY,snapshotTime=2020-09-01T23:59:40.125245Z'Remarques concernant l'utilisation :
- Vous pouvez suivre la progression de vos tâches d'importation et d'exportation dans la console Dataflow.
- Spanner garantit que les données exportées sont cohérentes en externe et en transaction à l'horodatage spécifié.
- Spécifiez l'horodatage au format RFC 3339. Par exemple 2020-09-01T23:59:30.234233Z.
- Assurez-vous que le code temporel que vous spécifiez est plus récent que celui de la base de données (
earliest_version_time). Si les données n'existent plus à l'horodatage spécifié, vous obtenez une erreur.
Importez dans une nouvelle base de données.
Console
Accédez à la page Détails de l'instance dans la console Cloud.
Dans l'onglet Importer/Exporter, cliquez sur Importer.
Pour obtenir des instructions détaillées, consultez Importer des fichiers Avro Spanner.
gcloud
Utilisez le modèle Dataflow Cloud Storage Avro vers Spanner pour importer les fichiers Avro.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/import/templates/GCS_Avro_to_Cloud_Spanner' \ --region=DATAFLOW_REGION \ --staging-location=YOUR_GCS_STAGING_LOCATION \ --parameters='instanceId=test-instance,databaseId=example-db,inputDir=YOUR_GCS_DIRECTORY'
Estimer l'augmentation de l'espace de stockage
Avant d'augmenter la durée de conservation de la version d'une base de données, vous pouvez estimer l'augmentation prévue de l'utilisation du stockage en totalisant les octets de transaction pour la période souhaitée. Par exemple, la requête suivante calcule le nombre de Gio écrits au cours des 7 derniers jours (168 h) en lisant les tables de statistiques de transactions.
GoogleSQL
SELECT
SUM(bytes_per_hour) / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168);
PostgreSQL
SELECT
bph / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
SUM(bytes_per_hour) as bph
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168)
sub1) sub2;
Notez que la requête fournit une estimation approximative et peut être inexacte pour plusieurs raisons :
- La requête ne tient pas compte de l'horodatage qui doit être stocké pour chaque version des anciennes données. Si votre base de données est composée de nombreux petits types de données, la requête peut sous-estimer l'augmentation de l'espace de stockage.
- La requête inclut toutes les opérations d'écriture, mais seules les opérations de mise à jour créent d'anciennes versions de données. Si votre charge de travail comprend de nombreuses opérations d'insertion, la requête peut surestimer l'augmentation de l'espace de stockage.