Lorsque vous utilisez des requêtes SQL pour rechercher des données, Spanner utilise automatiquement tous les index secondaires qui sont susceptibles de récupérer les données plus efficacement. Cependant, dans certains cas, Spanner peut choisir un index qui ralentit les requêtes. Par conséquent, vous remarquerez peut-être que certaines requêtes s'exécutent plus lentement que par le passé.
Cette page explique comment détecter les changements de vitesse d'exécution des requêtes, inspecter le plan d'exécution de requête pour ces requêtes, et spécifier un autre index pour les requêtes futures, si nécessaire.
Détecter les changements de vitesse d'exécution des requêtes
Vous pouvez constater une modification de la vitesse d'exécution des requêtes après avoir apporté l'une des modifications suivantes :
- Modification importante d'une grande quantité de données existantes associées à un index secondaire
- Ajout, modification ou suppression d'un index secondaire
Vous pouvez utiliser plusieurs outils pour identifier une requête spécifique que Spanner exécute plus lentement que d'habitude:
- Insights sur les requêtes et Statistiques sur les requêtes
Statistiques spécifiques à une application capturées et analysées avec Cloud Monitoring Par exemple, vous pouvez surveiller la métrique Nombre de requêtes pour déterminer le nombre de requêtes d'une instance au fil du temps et déterminer la version de l'optimiseur de requêtes utilisée pour l'exécution d'une requête.
Outils de surveillance côté client mesurant les performances de votre application
Remarque concernant les nouvelles bases de données
Lorsque vous interrogez des bases de données nouvellement créées avec des données fraîchement insérées ou importées, il est possible que Spanner ne sélectionne pas les index les plus appropriés, car l'optimiseur de requêtes met jusqu'à trois jours à collecter automatiquement les statistiques de l'optimiseur. Pour optimiser l'utilisation des index d'une nouvelle base de données Spanner plus tôt, vous pouvez créer manuellement un nouveau package de statistiques.
Examiner le schéma
Une fois que vous avez trouvé la requête à l'origine du ralentissement, examinez l'instruction SQL de la requête et identifiez les tables utilisées par l'instruction ainsi que les colonnes récupérées dans ces tables.
Ensuite, recherchez les index secondaires qui existent pour ces tables. Déterminez si l'un des index inclut les colonnes sur lesquelles vous exécutez la requête. Si c'est le cas, Spanner peut utiliser l'un des index pour traiter la requête.
- S'il existe des index applicables, l'étape suivante consiste à trouver l'index utilisé par Spanner pour la requête.
En l'absence d'index applicables, utilisez la commande
gcloud spanner operations listpour vérifier si vous avez récemment supprimé un index applicable :gcloud spanner operations list \ --instance=INSTANCE \ --database=DATABASE \ --filter="@TYPE:UpdateDatabaseDdlMetadata"Si vous avez supprimé un index applicable, cette modification peut avoir affecté les performances des requêtes. Rétablissez l'index secondaire dans la table. Une fois que Spanner a ajouté l'index, réexécutez la requête et examinez ses performances. Si les performances ne s'améliorent pas, l'étape suivante consiste à trouver l'index utilisé par Spanner pour la requête.
Si vous n'avez pas supprimé d'index applicable, cela signifie que la sélection d'index n'est pas à l'origine de la régression des performances de la requête. Recherchez d'autres modifications de vos données ou de vos modèles d'utilisation susceptibles d'avoir affecté les performances.
Rechercher l'index utilisé pour une requête
Pour savoir quel index Spanner utilise pour traiter une requête, consultez le plan d'exécution de requête dans la console Google Cloud :
Accédez à la page Instances de Spanner dans la console Google Cloud .
Cliquez sur le nom de l'instance que vous souhaitez interroger.
Dans le volet de gauche, cliquez sur la base de données à interroger, puis sur Spanner Studio.
Saisissez la requête à tester.
Dans la liste déroulante Exécuter la requête, sélectionnez Explication uniquement. Spanner affiche le plan de requête.
Recherchez au moins un des opérateurs suivants dans le plan de requête :
- table scan
- index scan
- cross apply ou distributed cross apply
Les sections suivantes présentent chaque opérateur.
Opérateur table scan
L'opérateur table scan indique que Spanner n'a pas utilisé d'index secondaire:
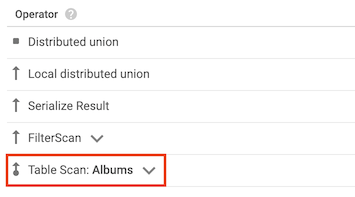
Par exemple, supposons que la table Albums ne comporte aucun index secondaire et que vous exécutez la requête suivante :
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
Étant donné qu'il n'existe aucun index à utiliser, le plan de requête inclut un opérateur table scan.
Opérateur index scan
L'opérateur index scan indique que Spanner a utilisé un index secondaire lors du traitement de la requête:
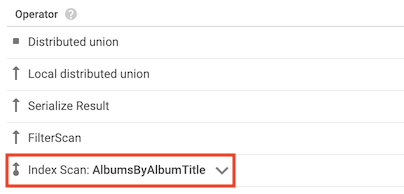
Par exemple, supposons que vous ajoutiez un index à la table Albums :
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Vous exécutez ensuite la requête suivante :
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
L'index AlbumsByAlbumTitle contient AlbumTitle, qui est la seule colonne sélectionnée par la requête. Par conséquent, le plan de requête inclut un opérateur index scan.
Opérateur cross apply
Dans certains cas, Spanner utilise un index qui ne contient que certaines des colonnes sélectionnées par la requête. Par conséquent, Spanner doit joindre l'index à la table de base.
Lorsque ce type de jointure se produit, le plan de requête inclut un opérateur cross apply ou distributed cross apply qui contient les entrées suivantes :
- Un opérateur index scan pour l'index d'une table
- Un opérateur table scan pour la table propriétaire de l'index
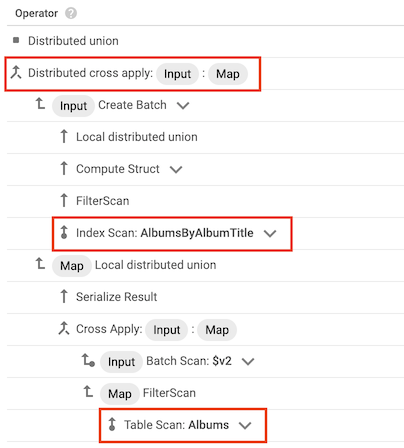
Par exemple, supposons que vous ajoutiez un index à la table Albums :
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Vous exécutez ensuite la requête suivante :
SELECT * FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
L'index AlbumsByAlbumTitle contient AlbumTitle, mais la requête sélectionne toutes les colonnes de la table, et pas seulement AlbumTitle. Par conséquent, le plan de requête inclut un opérateur distributed cross apply, avec des opérateurs index scan AlbumsByAlbumTitle et table scan Albums comme entrées.
Choisir un autre indice
Une fois que vous avez trouvé l'index utilisé par Spanner pour votre requête, essayez d'exécuter votre requête avec un autre index ou en analysant la table de base au lieu d'utiliser un index. Pour spécifier l'index, ajoutez une directive FORCE_INDEX à la requête.
Si vous trouvez une version plus rapide de la requête, mettez à jour votre application pour l'utiliser.
Consignes pour le choix d'un index
Suivez ces consignes pour déterminer l'index à tester pour la requête :
Si votre requête répond à l'un de ces critères, essayez d'utiliser la table de base au lieu d'un index secondaire :
- La requête recherche l'égalité avec un préfixe de la clé primaire de la table de base (par exemple,
SELECT * FROM Albums WHERE SingerId = 1). - De nombreuses lignes respectent les prédicats de requête (par exemple,
SELECT * FROM Albums WHERE AlbumTitle != "There Is No Album With This Title"). - La requête utilise une table de base qui ne contient que quelques centaines de lignes.
- La requête recherche l'égalité avec un préfixe de la clé primaire de la table de base (par exemple,
Si la requête contient un prédicat très sélectif (par exemple,
REGEXP_CONTAINS,STARTS_WITH,<,<=,>,>=ou!=), essayez d'utiliser un index qui inclut les mêmes colonnes que celles utilisées dans le prédicat.
Tester la requête mise à jour
Utilisez la console Google Cloud pour tester la requête mise à jour et déterminer le temps de traitement de la requête.
Si votre requête inclut des paramètres de requête et si l'un d'entre eux est associé à certaines valeurs beaucoup plus souvent que d'autres, associez le paramètre de requête à l'une de ces valeurs dans vos tests. Par exemple, si la requête inclut un prédicat tel que WHERE country = @countryId, et si presque toutes vos requêtes associent @countryId à la valeur US, associez @countryId à US pour vos tests de performances. Cette approche vous permet d'optimiser les requêtes que vous exécutez le plus fréquemment.
Pour tester la requête mise à jour dans la console Google Cloud , procédez comme suit:
Accédez à la page Instances de Spanner dans la console Google Cloud .
Cliquez sur le nom de l'instance que vous souhaitez interroger.
Dans le volet de gauche, cliquez sur la base de données à interroger, puis sur Spanner Studio.
Saisissez la requête à tester, y compris la directive
FORCE_INDEX, puis cliquez sur Exécuter la requête.La console Google Cloud ouvre l'onglet Tableau des résultats, puis affiche les résultats de la requête, y compris le temps nécessaire au service Spanner pour traiter la requête.
Cette métrique n'inclut pas les autres sources de latence, telles que le temps nécessaire à la console pour interpréter et afficher les résultats de la requête. Google Cloud
Obtenir le profil détaillé d'une requête au format JSON à l'aide de l'API REST
Par défaut, seuls les résultats des instructions sont renvoyés lorsque vous exécutez une requête.
En effet, QueryMode est défini sur NORMAL.
Pour inclure des statistiques d'exécution détaillées avec les résultats de la requête, définissez QueryMode sur PROFILE.
Créer une session
Avant de mettre à jour votre mode de requête, créez une session, qui représente un canal de communication avec le service de base de données Spanner.
- Cliquez sur
projects.instances.databases.sessions.create. Indiquez les identifiants du projet, de l'instance et de la base de données comme suit :
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]Cliquez sur Exécuter. La réponse indique la session que vous venez de créer comme suit :
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]/sessions/[\SESSION\]Vous l'utiliserez pour exécuter le profil de requête à l'étape suivante. La session créée reste active pendant une heure au maximum entre deux utilisations consécutives avant d'être supprimée par la base de données.
Profil de la requête
Activez le mode PROFILE pour la requête.
- Cliquez sur
projects.instances.databases.sessions.executeSql. Pour session, saisissez l'identifiant de session que vous avez créée lors de l'étape précédente :
projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]/sessions/[SESSION]Pour le champ Request body (Corps de la requête), utilisez les lignes suivantes :
{ "sql": "[YOUR_SQL_QUERY]", "queryMode": "PROFILE" }Cliquez sur Exécuter. La réponse renvoyée inclut les résultats de la requête, le plan de requête et les statistiques d'exécution de la requête.