Présentation
Cette page décrit des concepts sur les plans d'exécution de requêtes et leur utilisation par Spanner afin d'exécuter des requêtes dans un environnement distribué. Pour savoir comment récupérer un plan d'exécution pour une requête donnée à l'aide de la consoleGoogle Cloud , consultez la section Comprendre comment Spanner exécute les requêtes. Vous pouvez également afficher des échantillons d'historiques de plans de requête et comparer les performances d'une requête au fil du temps pour certaines requêtes. Pour en savoir plus, consultez la section Exemples de plans de requêtes.
Pour interroger ses bases de données, Spanner utilise des instructions SQL déclaratives. Les instructions SQL définissent le résultat attendu par l'utilisateur sans spécifier comment l'obtenir. Un plan d'exécution de requêtes réunit l'ensemble des étapes permettant de définir ce "comment". Pour une instruction SQL donnée, les résultats peuvent être obtenus de plusieurs façons. L'optimiseur de requête de Spanner évalue différents plans d'exécution et choisit celui qu'il considère comme le plus efficace. Spanner extrait ensuite les résultats à l'aide du plan d'exécution.
Conceptuellement, un plan d'exécution correspond à une arborescence d'opérateurs relationnels. Chaque opérateur lit les lignes à partir de ses entrées et génère des lignes de sortie. Le résultat de l'opérateur situé à la racine de l'exécution est renvoyé en tant que résultat de la requête SQL.
À titre d'exemple, prenons la requête suivante :
SELECT s.SongName FROM Songs AS s;
Elle renvoie un plan d'exécution de requêtes pouvant être visualisé comme suit :
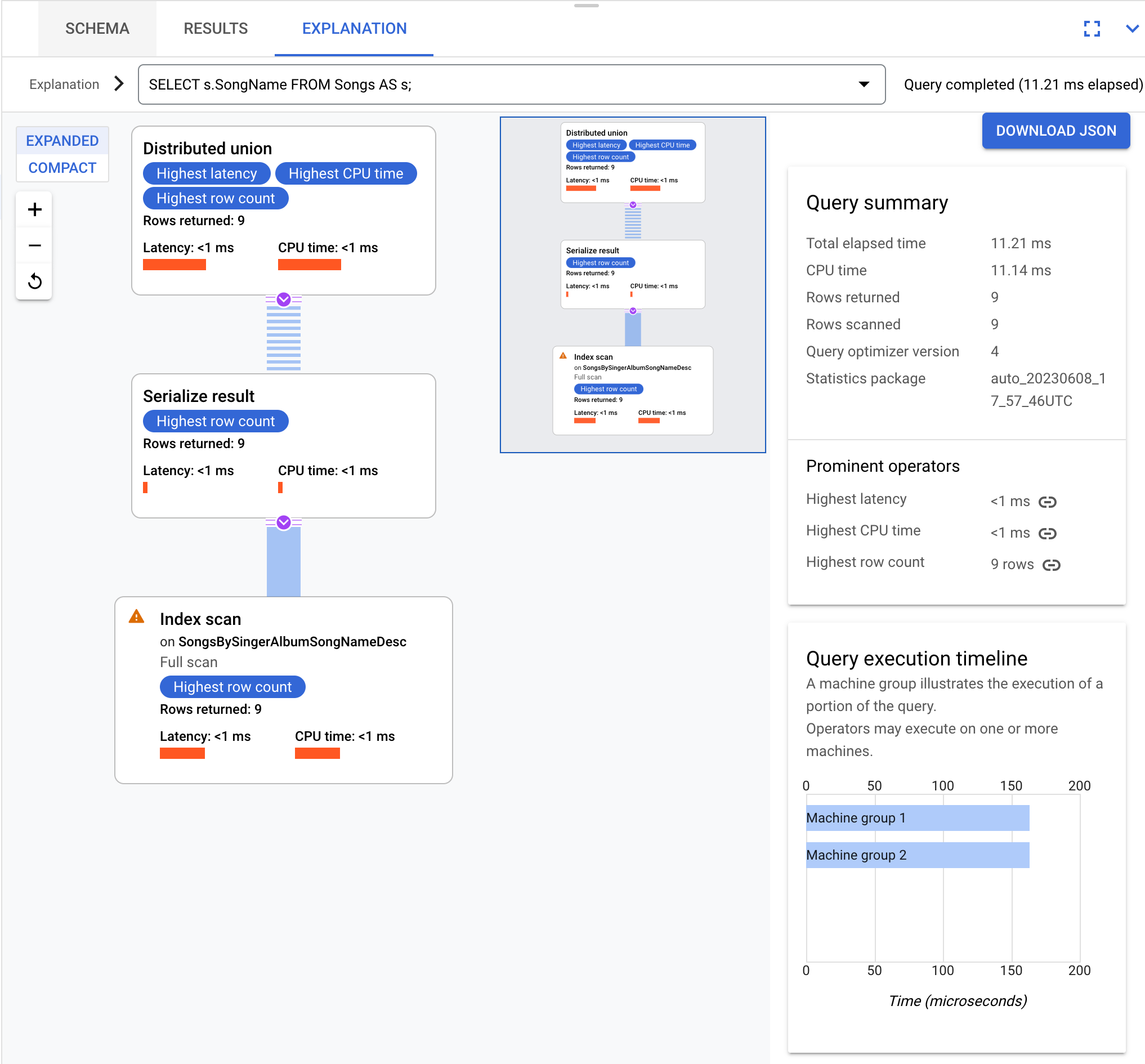
Les requêtes et les plans d'exécution de cette page sont basés sur le schéma de base de données suivant :
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
Vous pouvez utiliser les instructions LMD (langage de manipulation de données) suivantes pour ajouter des données à ces tables :
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
L'obtention de plans d'exécution efficaces représente un défi, car Spanner répartit les données en différentes partitions. Les divisions peuvent bouger indépendamment les unes des autres, et être affectées à différents serveurs, qui peuvent eux-mêmes se trouver dans des emplacements physiques variés. Pour évaluer les plans d'exécution sur les données distribuées, Spanner utilise une exécution basée sur:
- l'exécution locale des sous-plans dans les serveurs contenant les données ;
- l'orchestration et l'agrégation de multiples exécutions à distance avec élimination de distributions intensives.
Spanner utilise l'opérateur primitif distributed union, ainsi que ses variantes distributed cross apply et distributed outer apply, pour activer ce modèle.
Plans de requêtes échantillonnés
Les échantillons de plans de requêtes Spanner vous permettent d'afficher des échantillons d'historiques de plans de requêtes et de comparer les performances d'une requête au fil du temps. Les plans de requêtes échantillonnés ne sont pas disponibles pour toutes les requêtes. Seules les requêtes qui consomment plus de ressources processeur peuvent être échantillonnées. La période de conservation des échantillons de plan de requête Spanner est de 30 jours. Vous trouverez des exemples de plans de requête sur la page Insights sur les requêtes de la console Google Cloud . Pour savoir comment procéder, consultez la section Afficher des plans de requête échantillonnés.
L'anatomie d'un plan de requête échantillonné est la même que celle d'un plan d'exécution de requêtes standard. Pour en savoir plus sur la compréhension des plans visuels et leur utilisation pour déboguer vos requêtes, consultez Présentation du visualiseur de plan de requête.
Cas d'utilisation courants des plans de requête échantillonnés:
Voici quelques cas d'utilisation courants des plans de requête échantillonnés:
- Observez les modifications du plan de requête en raison de modifications de schéma (par exemple, ajout ou suppression d'un indice).
- Observer les modifications apportées au plan de requête en raison d'une mise à jour de la version de l'optimiseur
- Observez les modifications du plan de requêtes en raison de nouvelles statistiques de l'optimiseur, qui sont collectées automatiquement tous les trois jours ou manuellement à l'aide de la commande
ANALYZE.
Si les performances d'une requête présentent des différences significatives au fil du temps ou si vous souhaitez les améliorer, consultez les bonnes pratiques SQL pour créer des instructions de requête optimisées qui aident Spanner à trouver des plans d'exécution efficaces.
Cycle de vie d'une requête
Une requête SQL dans Spanner est d'abord compilée dans un plan d'exécution, puis envoyée à un serveur racine initial pour exécution. Le serveur racine est choisi de manière à réduire le nombre de sauts, et ainsi à atteindre les données interrogées. Le serveur racine:
- lance l'exécution à distance des sous-plans (si nécessaire) ;
- attend les résultats des exécutions à distance ;
- gère toutes les étapes d'exécution locales restantes, telles que l'agrégation des résultats ;
- renvoie les résultats correspondant à la requête.
Les serveurs distants qui reçoivent un sous-plan agissent comme serveur "racine" de ce sous-plan, suivant ainsi le même modèle que le serveur racine en tête de liste. Le résultat correspond à une arborescence d'exécutions à distance. Sur le plan conceptuel, l'exécution de requêtes s'effectue de haut en bas et les résultats de la requête sont renvoyés de bas en haut. Le schéma suivant illustre ce modèle :

Les exemples ci-dessous illustrent ce modèle plus en détail.
Requêtes d'agrégation
Une requête d'agrégation met en œuvre les requêtes GROUP BY.
Par exemple, si vous utilisez cette requête :
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
Vous obtenez les résultats suivants :
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
Sur le plan conceptuel, voici le plan d'exécution :
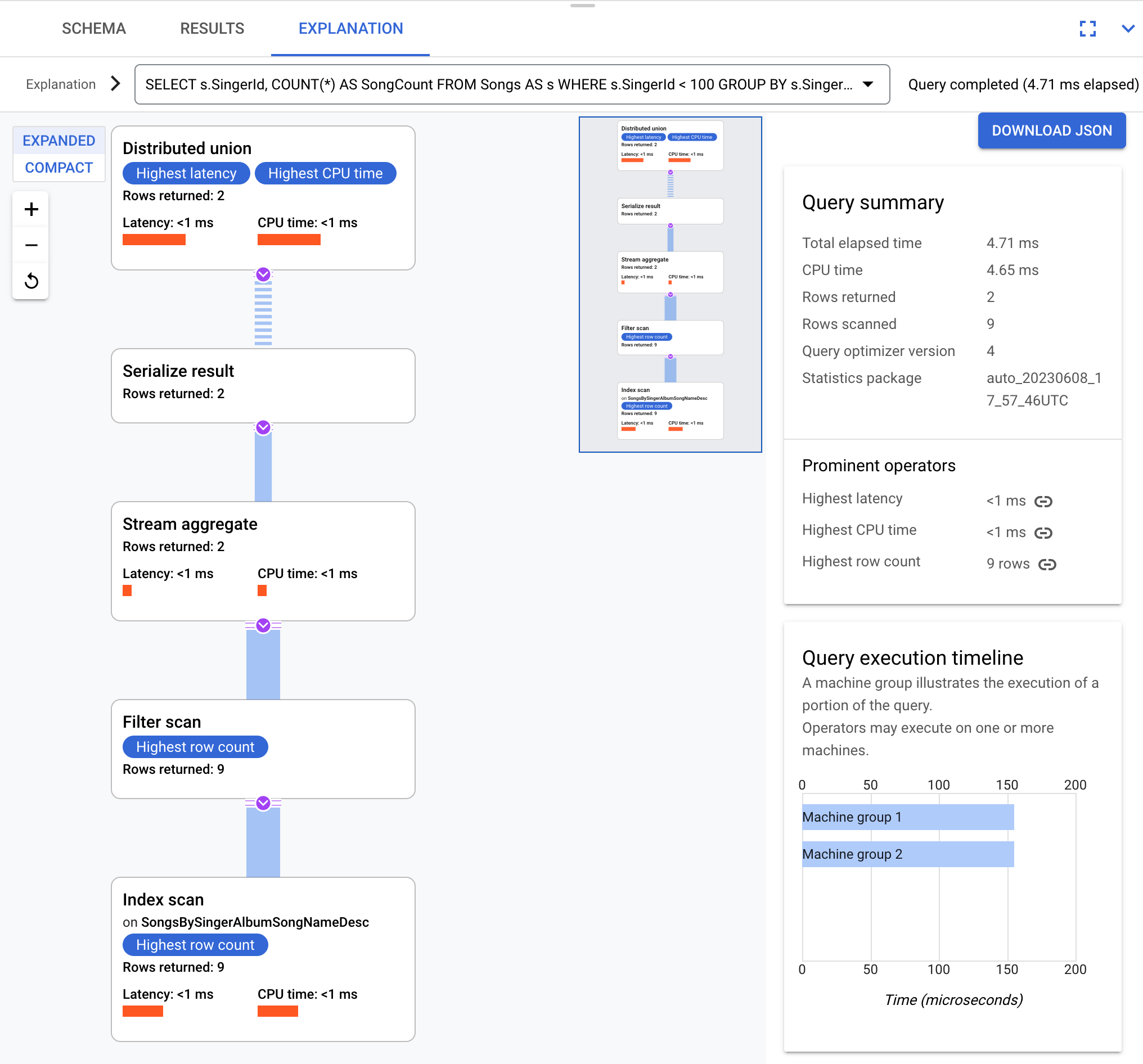
Spanner envoie le plan d'exécution à un serveur racine qui coordonne l'exécution de la requête et effectue la distribution à distance des sous-plans.
Ce plan d'exécution commence par une union distribuée, qui distribue des sous-plans aux serveurs distants avec des partitions conformes à SingerId < 100. Une fois l'analyse des divisions individuelles terminée, l'opérateur agrégation de flux agrège les lignes pour obtenir les totaux de chaque SingerId. L'opérateur serialize result sérialise ensuite le résultat. Enfin, l'union distribuée combine tous les résultats et renvoie les résultats de la requête.
Vous pouvez en apprendre davantage sur les agrégats dans la section sur l'opérateur aggregate.
Requêtes de jointure colocalisée
Les tables entrelacées sont stockées physiquement, leurs lignes issues des tables associées étant colocalisées. Les jointures colocalisées permettent de joindre des tables entrelacées. Elles peuvent offrir de meilleures performances que les jointures nécessitant des index ou des jointures ultérieures.
Par exemple, si vous utilisez cette requête :
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(Cette requête suppose que l'objet Songs soit entrelacé dans Albums).
Vous obtenez les résultats suivants :
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
Voici le plan d'exécution :
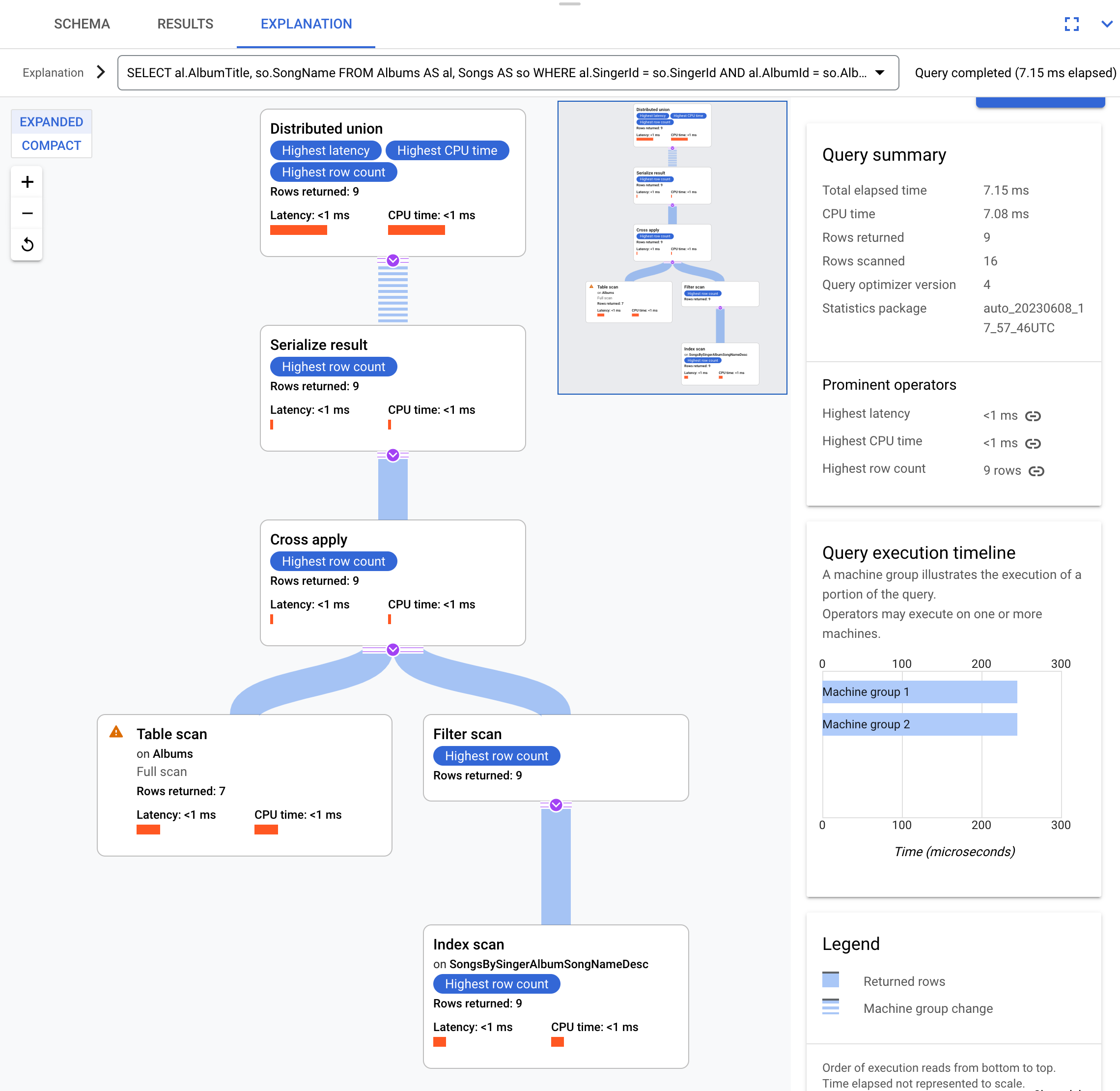
Ce plan d'exécution commence par une union distribuée, qui distribue des sous-plans aux serveurs distants contenant des partitions de la table Albums.
Comme Songs est une table entrelacée de Albums, chaque serveur distant peut exécuter l'intégralité du sous-plan sur chaque serveur distant sans avoir à ajouter une jointure à un autre serveur.
Les sous-plans contiennent une application croisée. Chaque application croisée effectue une analyse de la table Albums pour récupérer SingerId, AlbumId et AlbumTitle. L'application croisée mappe ensuite les résultats de l'analyse de la table avec ceux d'une analyse d'index sur l'index SongsBySingerAlbumSongNameDesc, les résultats étant soumis à un filtre de l'objet SingerId dans l'index, qui correspond à l'objet SingerId du résultat de l'analyse de la table. Chaque application croisée envoie ses résultats à un opérateur serialize result qui sérialise les données AlbumTitle et SongName, et renvoie les résultats aux unions distribuées locales. L'union distribuée agrège les résultats provenant des unions distribuées locales, puis les renvoie en tant que résultats de la requête.
Index et requêtes de jointure ultérieure
L'exemple ci-dessus utilisait une jointure sur deux tables, entrelacées l'une dans l'autre. Les plans d'exécution sont plus complexes et moins efficaces lorsque deux tables (ou une table et un index) ne sont pas entrelacés.
Prenons l'exemple d'un index créé avec la commande suivante :
CREATE INDEX SongsBySongName ON Songs(SongName)
Utilisez cet index dans la requête suivante :
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Vous obtenez les résultats suivants :
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
Voici le plan d'exécution :
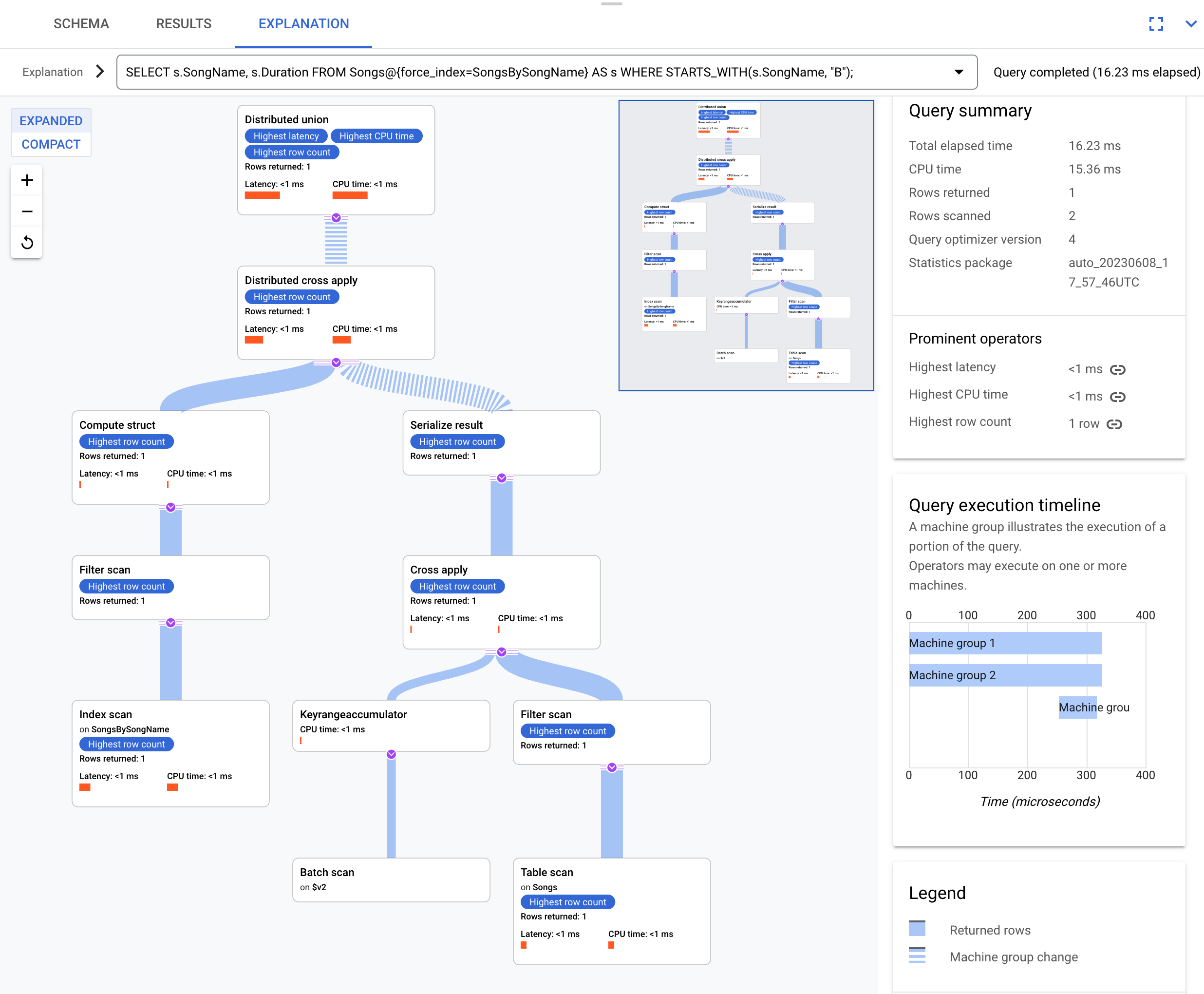
Le plan d'exécution résultant est compliqué, car l'index SongsBySongName ne contient pas de colonne Duration. Pour obtenir la valeur Duration, Spanner doit effectuer une jointure ultérieure des résultats indexés sur la table Songs. Il s'agit d'une jointure qui n'est pas colocalisée, car la table Songs et l'index global SongsBySongName ne sont pas entrelacés. Le plan d'exécution résultant est plus complexe que l'exemple de jointure colocalisée, car Spanner effectue des optimisations permettant d'accélérer l'exécution si les données ne sont pas colocalisées.
L'opérateur principal est un opérateur distributed cross apply. Le côté entrée de cet opérateur est constitué de lots de lignes depuis l'index SongsBySongName, conformes au prédicat STARTS_WITH(s.SongName, "B"). L'application croisée distribuée mappe ensuite ces lots avec des serveurs distants, dont les divisions contiennent les données de Duration. Les serveurs distants utilisent une analyse de table pour récupérer la colonne Duration.
L'analyse de table utilise le filtre Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId), qui effectue la jointure entre l'objet TrackId de la table Songs et l'objet TrackId des lignes regroupées depuis l'index SongsBySongName.
Les résultats sont agrégés dans la réponse à la requête finale. À son tour, le côté entrée de l'application croisée distribuée contient une paire union distribuée/union distribuée locale pour évaluer les lignes d'index conformes au prédicat STARTS_WITH.
Prenons l'exemple d'une requête légèrement différente ne sélectionnant pas la colonne s.Duration :
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Cette requête peut exploiter pleinement l'index, comme indiqué dans le plan d'exécution suivant :
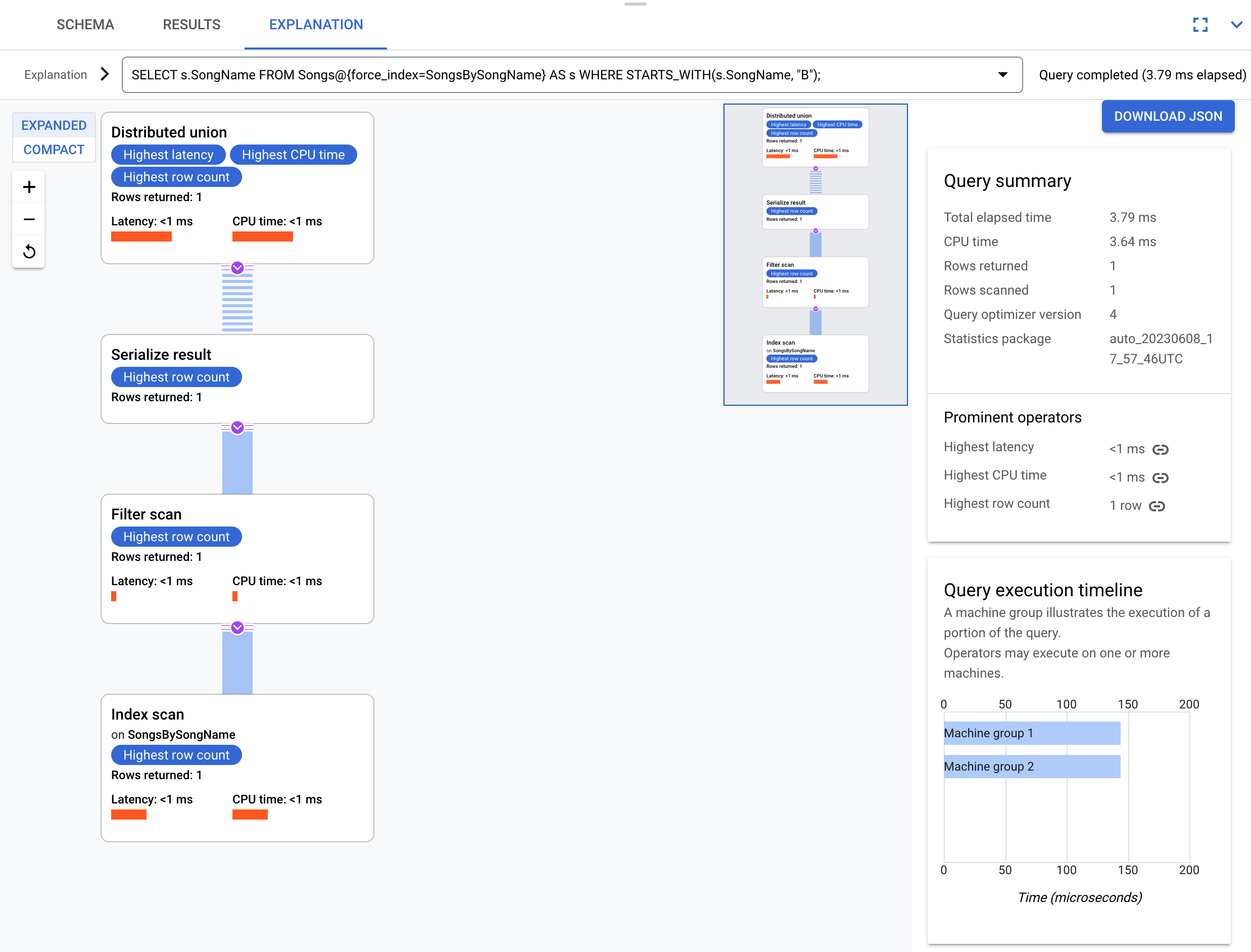
Le plan d'exécution ne nécessite pas de jointure ultérieure, car toutes les colonnes demandées par la requête sont présentes dans l'index.
Étape suivante
Découvrez plus d'informations sur les opérateurs d'exécution de requêtes.
En savoir plus sur l'optimiseur de requêtes de Spanner
Découvrez comment gérer l'optimiseur de requête.