Visão geral
Esta página contém conceitos sobre planos de execução de consulta e como eles são usados pelo Spanner para executar consultas em um ambiente distribuído. Para saber como extrair um plano de execução para uma consulta específica usando o consoleGoogle Cloud , consulte Noções básicas sobre como o Spanner executa consultas. Também é possível conferir amostras de planos de consulta históricos e comparar o desempenho de uma consulta ao longo do tempo para determinadas consultas. Para saber mais, consulte Planos de consulta amostrados.
O Spanner usa instruções SQL declarativas para consultar os bancos de dados. As instruções SQL definem o que o usuário quer sem especificar como conseguir os resultados. Um plano de execução de consulta é o conjunto de etapas para alcançar os resultados. Para uma determinada instrução SQL, pode haver várias maneiras de conseguir os resultados. O otimizador de consultas do Spanner avalia diferentes planos de execução e escolhe o que considera mais eficiente. O Spanner usa o plano de execução para recuperar os resultados.
Conceitualmente, um plano de execução é uma árvore de operadores relacionais. Cada operador lê as linhas de entrada e produz linhas de saída. O resultado do operador na raiz da execução é retornado como resultado da consulta SQL.
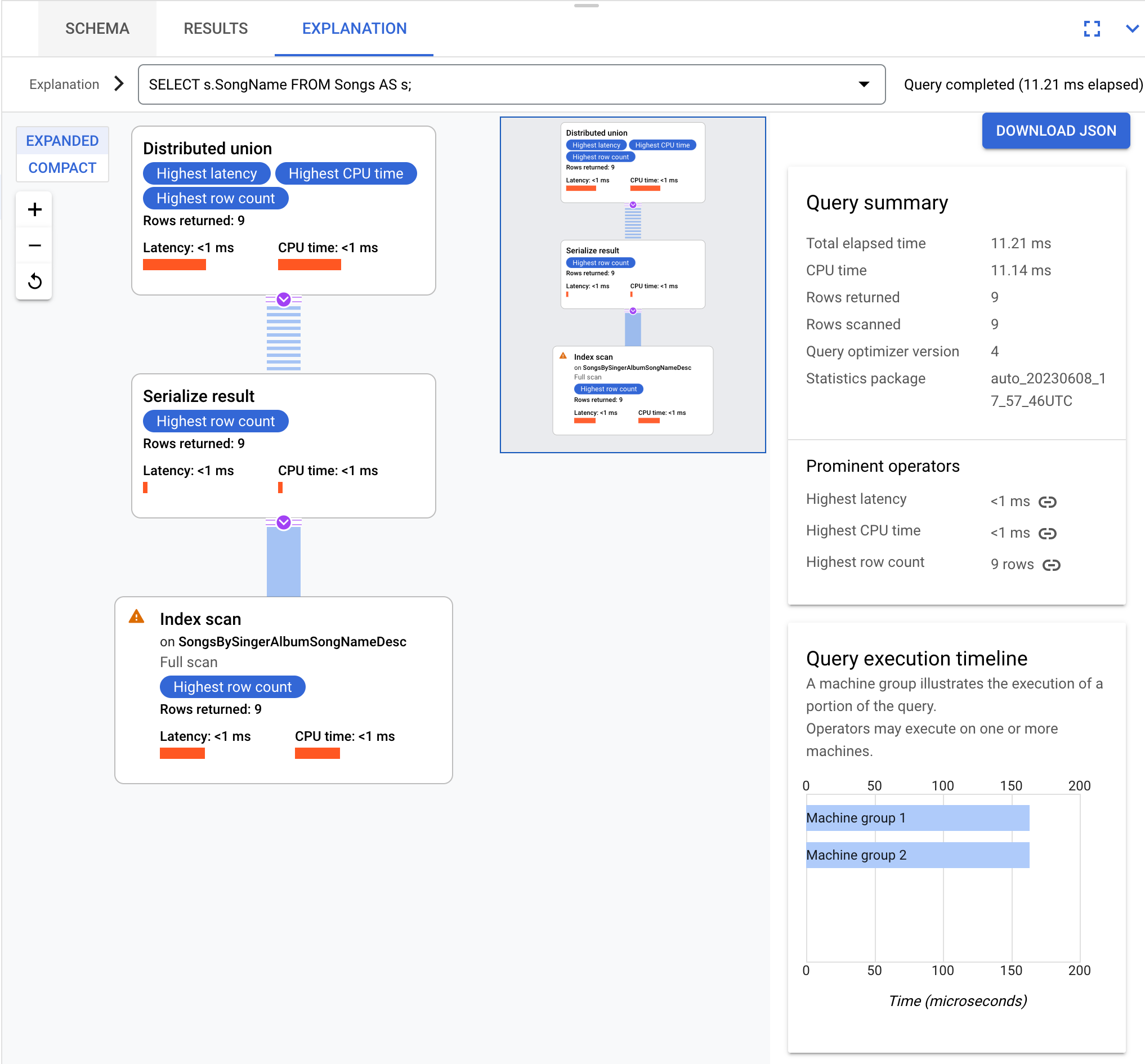
Como exemplo, esta consulta:
SELECT s.SongName FROM Songs AS s;
resulta em um plano de execução de consulta que pode ser visualizado como:
As consultas e os planos de execução dessa página se baseiam no esquema de banco de dados abaixo:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
É possível usar as seguintes instruções da linguagem de manipulação de dados (DML) para adicionar dados a estas tabelas:
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Conseguir planos de execução eficientes é um desafio porque o Spanner divide os dados em divisões. As divisões podem ser movimentadas independentemente entre si e atribuídas a servidores diferentes, que podem estar em diferentes locais físicos. Para avaliar os planos de execução sobre os dados distribuídos, o Spanner usa a execução com base em:
- execução local de subplanos em servidores que contêm os dados;
- orquestração e agregação de várias execuções remotas com poda agressiva por distribuição.
O Spanner usa o operador primitivo distributed union,
com as variantes distributed cross apply e
distributed outer apply, para ativar esse modelo.
Planos de consulta amostrados
Os planos de consulta de amostra do Spanner permitem que você confira amostras de planos de consulta históricos e compare o desempenho de uma consulta ao longo do tempo. Nem todas as consultas têm planos de consulta de amostra disponíveis. Apenas consultas que consomem mais CPU podem ser usadas para amostragem. A retenção de dados para amostras de plano de consulta do Spanner é de 30 dias. Você pode encontrar exemplos de plano de consulta na página Insights de consulta do console Google Cloud . Para instruções, consulte Conferir planos de consulta de amostra.
A anatomia de um plano de consulta amostrado é igual a um plano de execução de consulta normal. Para mais informações sobre como entender os planos visuais e usá-los para depurar suas consultas, consulte Um tour pelo visualizador de planos de consulta.
Casos de uso comuns para planos de consulta com amostragem:
Alguns casos de uso comuns para planos de consulta de amostra incluem:
- Observe as mudanças no plano de consulta devido a mudanças no esquema, como adição ou remoção de um índice.
- Observe as mudanças no plano de consulta devido a uma atualização da versão do otimizador.
- Observe as mudanças no plano de consulta devido às novas estatísticas do otimizador,
que são coletadas automaticamente a cada três dias ou realizadas manualmente usando
o comando
ANALYZE.
Se a performance de uma consulta mostrar uma diferença significativa ao longo do tempo ou se você quer melhorar a performance de uma consulta, consulte as práticas recomendadas de SQL para criar instruções de consulta otimizadas que ajudam o Spanner a encontrar planos de execução eficientes.
Vida útil de uma consulta
Uma consulta SQL no Spanner primeiro é compilada em um plano de execução, depois é enviada a um servidor raiz inicial para execução. O servidor raiz é escolhido para minimizar o número de saltos para alcançar os dados que estão sendo consultados. O servidor raiz então:
- inicia a execução remota de subplanos (se necessário);
- aguarda os resultados das execuções remotas;
- processas as etapas de execução local restantes, como a agregação de resultados;
- retorna os resultados da consulta.
Os servidores remotos que recebem um subplano atuam como servidor "raiz" para o subplano, seguindo o mesmo modelo que o servidor raiz superior. O resultado é uma árvore de execuções remotas. Conceitualmente, a execução da consulta flui de cima para baixo e os resultados da consulta são retornados de baixo para cima. O diagrama a seguir mostra esse padrão:

Os exemplos a seguir ilustram esse padrão com mais detalhes.
Consultas agregadas
Uma consulta agregada implementa consultas GROUP BY.
Por exemplo, para esta consulta:
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
Estes são os resultados:
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
Conceitualmente, o plano de execução é o seguinte:
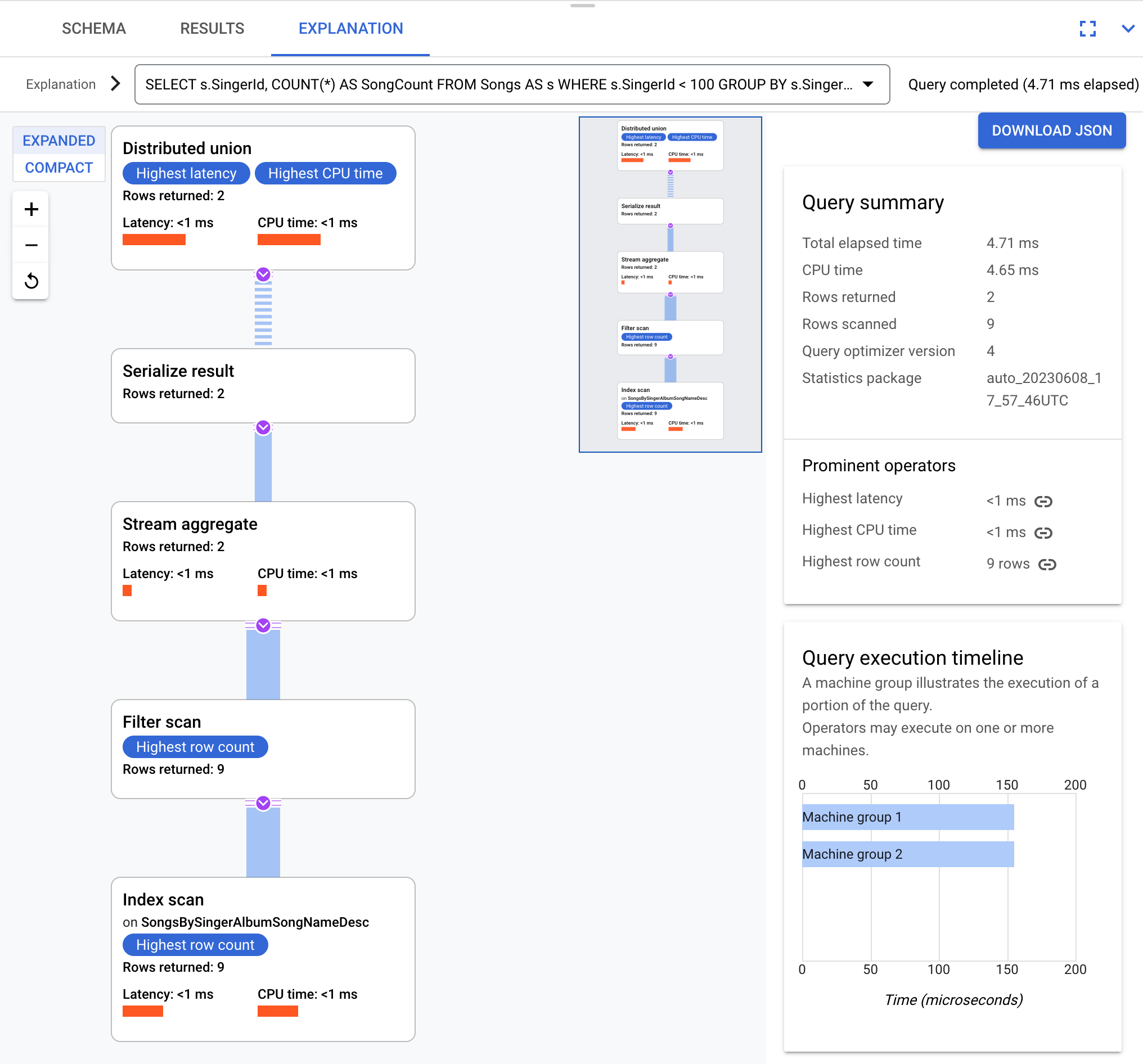
O Spanner envia o plano de execução a um servidor raiz que coordena a execução da consulta e realiza a distribuição remota dos subplanos.
Esse plano de execução começa com uma união distribuída, que distribui
subplanos para servidores remotos com divisões que atendem a SingerId < 100. Depois que a verificação
em divisões individuais for concluída, o operador stream aggregate vai agregar linhas
para receber as contagens de cada SingerId. O operador serialize result serializa o resultado. Por fim, a união distribuída combina todos os resultados
e retorna os resultados da consulta.
Saiba mais sobre agregados em operador agregado.
Consultas de junções colocalizadas
As tabelas intercaladas são armazenadas fisicamente com as respectivas linhas de tabelas relacionadas no mesmo lugar. Uma junção colocalizada é uma junção entre tabelas intercaladas. As junções colocalizadas podem oferecer melhores benefícios de desempenho do que as junções que exigem índices ou junções de volta.
Por exemplo, para esta consulta:
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(Essa consulta pressupõe que Songs está intercalado em Albums.)
Estes são os resultados:
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
Este é o plano de execução:
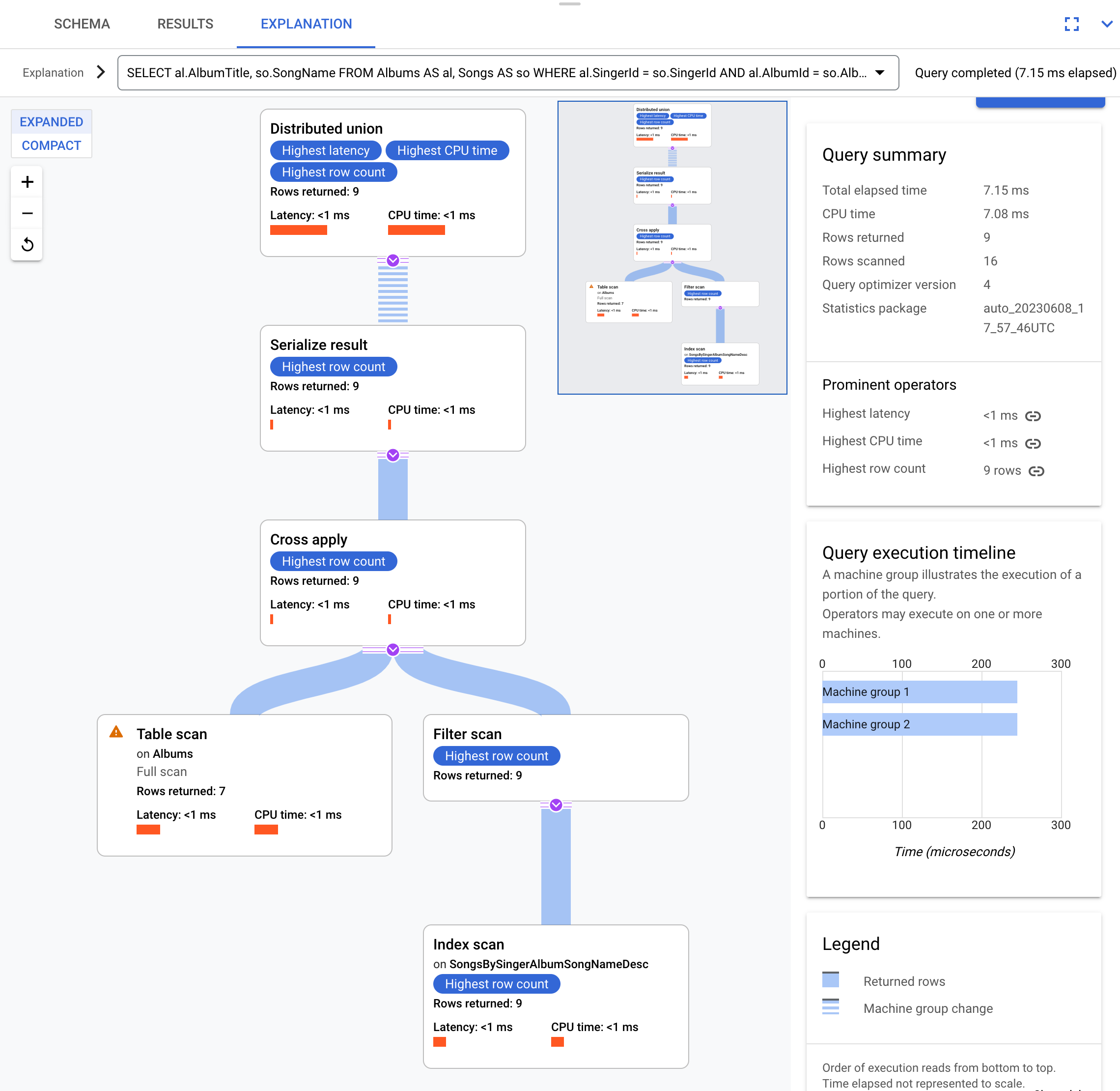
Esse plano de execução começa com uma união distribuída, que
distribui subplanos para servidores remotos que têm divisões da tabela Albums.
Como Songs é uma tabela intercalada de Albums, cada servidor remoto consegue executar todo o subplano em cada servidor remoto sem exigir uma junção com um servidor diferente.
Os subplanos contêm um cross apply. Cada aplicação cruzada realiza uma verificação
de tabela na tabela Albums para recuperar SingerId, AlbumId e
AlbumTitle. Em seguida, o cross apply mapeia a saída da verificação da tabela para a saída
de uma verificação de índice no índice SongsBySingerAlbumSongNameDesc, sujeito a um
filtro do SingerId no índice que corresponde ao SingerId da
saída da verificação de tabela. Cada aplicação cruzada envia os resultados a um operador serialize result,
que serializa os dados de AlbumTitle e SongName e retorna
os resultados para as uniões distribuídas locais. A união distribuída agrega
os resultados das uniões distribuídas locais e os retorna como o resultado da consulta.
Consultas de índice e junção de volta
O exemplo acima usou uma junção em duas tabelas, uma intercalada à outra. Os planos de execução são mais complexos e menos eficientes quando duas tabelas, ou uma tabela e um índice, não são intercalados.
Considere um índice criado com o seguinte comando:
CREATE INDEX SongsBySongName ON Songs(SongName)
Use este índice nesta consulta:
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Estes são os resultados:
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
Este é o plano de execução:
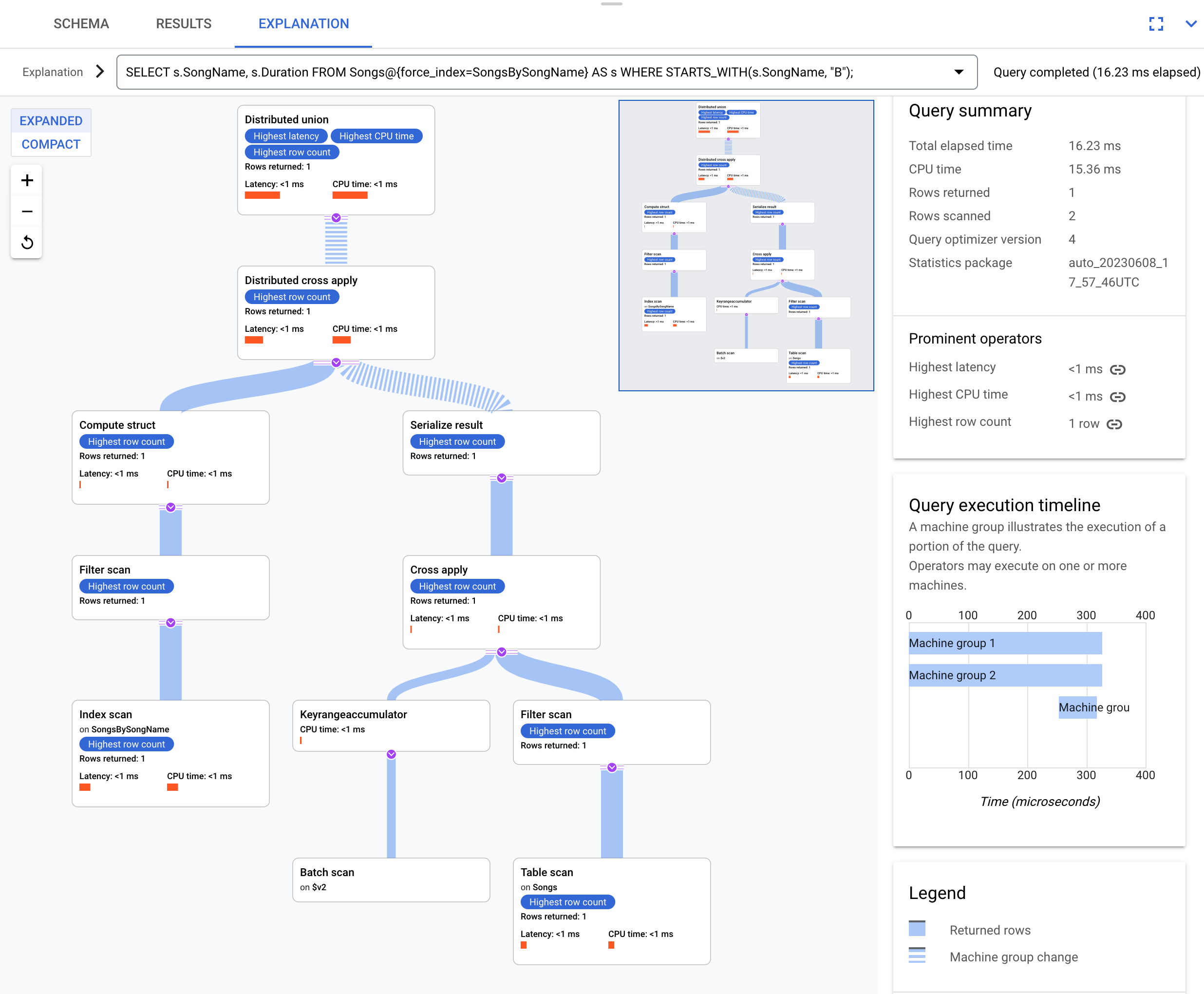
O plano de execução resultante é complicado porque o índice SongsBySongName não contém a coluna Duration. Para conseguir o valor Duration,
o Spanner precisa fazer a junção de volta dos resultados indexados na tabela
Songs. Esta é uma junção, mas ela não está colocalizada porque a tabela Songs e
o índice global SongsBySongName não são intercalados. O plano de execução resultante é mais complexo do que o exemplo de junção colocalizada porque o Spanner executa otimizações para acelerar a execução quando os dados não estão colocalizados.
O operador superior é um distributed cross apply. O lado de entrada do operador é formado por lotes de linhas do índice SongsBySongName que satisfazem o predicado STARTS_WITH(s.SongName, "B"). Em seguida, a aplicação cruzada distribuída mapeia esses lotes para servidores remotos, cujas divisões contêm os dados Duration. Os servidores remotos usam uma verificação de tabela para recuperar a coluna Duration.
A verificação da tabela usa o filtro Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId), que une TrackId da tabela Songs a
TrackId das linhas que foram agrupadas do índice SongsBySongName.
Os resultados são agregados na resposta final da consulta. Por sua vez, o lado input da aplicação cruzada distribuída contém um par de união distribuída/união distribuída local para avaliar as linhas do índice que satisfazem o predicado STARTS_WITH.
Considere uma consulta um pouco diferente que não selecione a coluna s.Duration:
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
Essa consulta é capaz de aproveitar totalmente o índice, conforme mostrado neste plano de execução:
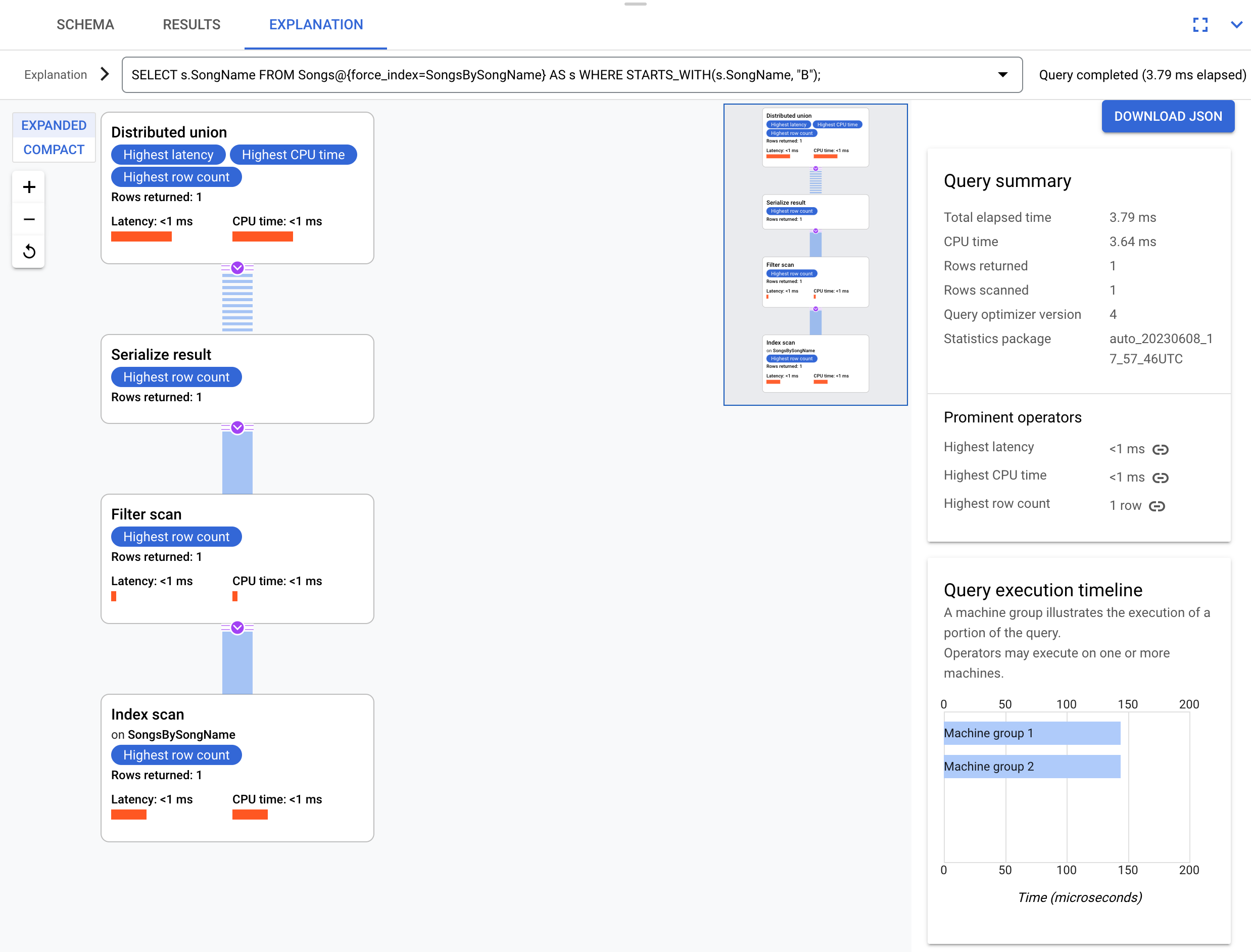
O plano de execução não requer uma junção de volta porque todas as colunas solicitadas pela consulta estão presentes no índice.
Próximas etapas
Saiba mais sobre operadores de execução de consulta.
Saiba mais sobre o otimizador de consultas do Spanner
Saiba como gerenciar o otimizador de consultas