Esta página descreve como usar o painel do Query insights para detectar e analisar problemas de desempenho do Spanner.
Visão geral do Query Insights
O Query Insights ajuda a detectar e diagnosticar problemas de desempenho de consultas e
instruções DML (INSERT, UPDATE e DELETE)
para um banco de dados do Spanner. Ele auxilia o monitoramento intuitivo e fornece informações de diagnóstico que ajudam você a ir além da detecção, para identificar a causa raiz de problemas de desempenho.
O Query Insights ajuda a melhorar o desempenho das consultas do Spanner orientando você pelas seguintes etapas:
- Determine se consultas ineficientes estão causando alta utilização da CPU.
- Identificar uma consulta ou tag potencialmente problemática.
- Analise a consulta ou tag de solicitação para identificar problemas.
Os insights de consulta estão disponíveis em configurações de região única e multirregional.
Preços
Não há custo adicional para os insights de consulta.
Retenção de dados
O Query Insights retém dados por no máximo 30 dias.
Para o gráfico Uso total da CPU (por tag de solicitação ou consulta), o Spanner recupera dados das tabelas SPANNER_SYS.QUERY_STATS_TOP_*. Essas tabelas têm uma retenção máxima de 30 dias. Consulte Retenção de dados para saber mais.
Funções exigidas
Você precisa de diferentes papéis e permissões do IAM, dependendo se é um usuário do IAM ou de controle de acesso refinado.
Usuário do Identity and Access Management (IAM)
Para receber as permissões necessárias para acessar a página "Insights de consulta", peça ao administrador para conceder a você os seguintes papéis do IAM na instância:
-
Leitor do Cloud Spanner (
roles/spanner.viewer) -
Leitor de banco de dados do Cloud Spanner (
roles/spanner.databaseReader)
As seguintes permissões no papel Leitor de banco de dados do Cloud Spanner(
roles/spanner.databaseReader) são necessárias para acessar a página do Query Insights:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Usuário de controle de acesso refinado
Se você usa o controle de acesso refinado, verifique se:
- Ter a função Leitor do Cloud Spanner(
roles/spanner.viewer) - Ter privilégios de controle de acesso refinado e receber a função de sistema
spanner_sys_readerou uma das funções de membro dela. - Selecione
spanner_sys_readerou uma função de membro como sua função atual do sistema na página de visão geral do banco de dados.
Para mais informações, consulte Sobre o controle de acesso refinado e Papéis do sistema de controle de acesso refinado.
O painel do Query Insights
O painel do Query insights mostra a carga de consulta com base no banco de dados e no período selecionados. A carga de consulta é uma medida da utilização total da CPU para todas as consultas na instância no intervalo de tempo selecionado. O painel fornece uma série de filtros que ajudam você a visualizar a carga de consulta.
Para acessar o painel do Query Insights de um banco de dados, faça o seguinte:
- Selecione Query Insights no painel de navegação à esquerda. O painel Insights de consulta é aberto.
- Selecione um banco de dados na lista Bancos de dados. O painel mostra as informações de carga de consulta do banco de dados.
As áreas do painel incluem:
- Lista de bancos de dados: filtra a carga de consulta em um banco de dados específico ou em todos os bancos de dados.
- Filtro de período: filtra a carga da consulta por períodos, como horas, dias ou um período personalizado.
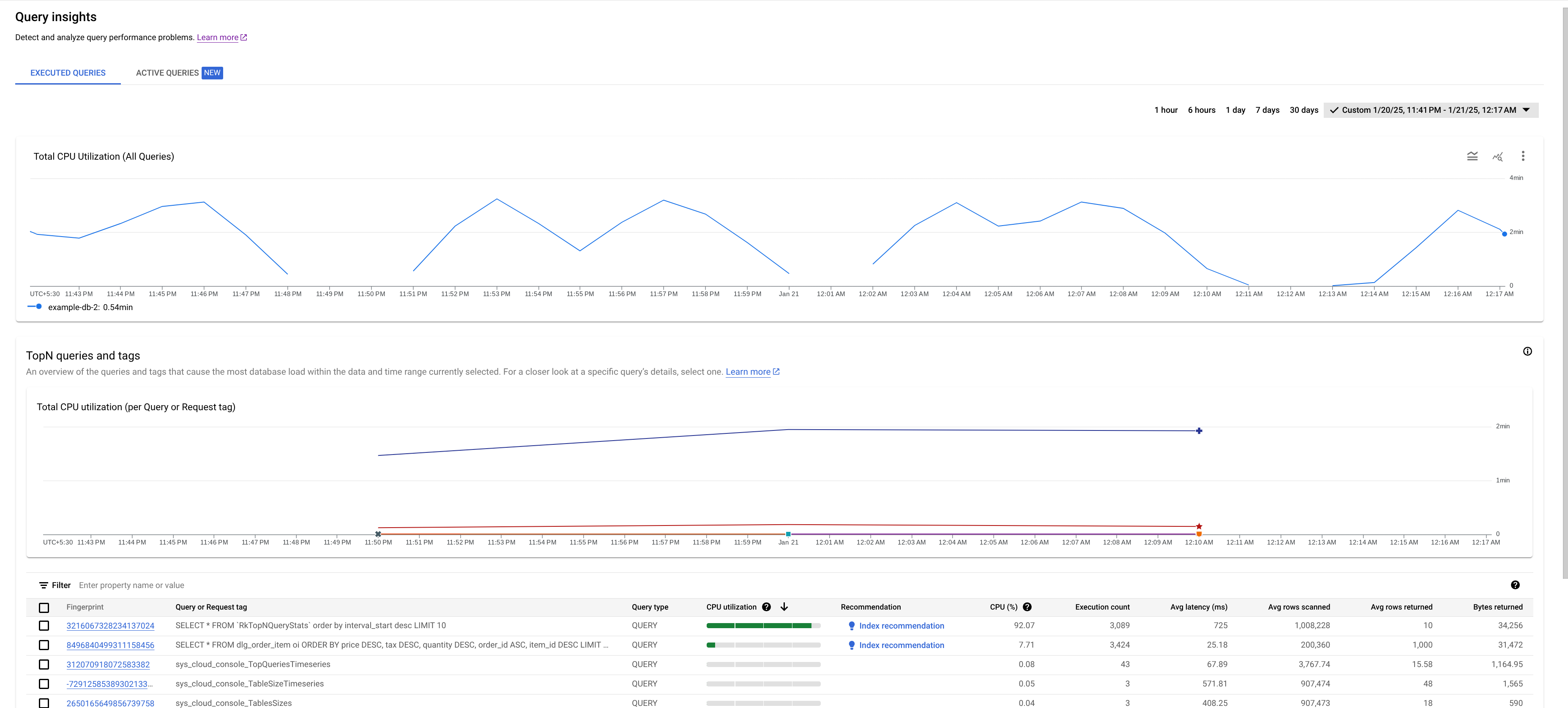
- Gráfico de uso total da CPU (todas as consultas): mostra a carga agregada de todas as consultas.
- Gráfico de uso total da CPU (por tag de solicitação ou consulta): mostra o uso da CPU por cada consulta ou tag de solicitação.
- Tabela de consultas e tags TopN: mostra a lista das principais consultas e tags de solicitação classificadas por uso da CPU. Consulte Identificar uma consulta ou tag potencialmente problemática.
Performance do painel
Use parâmetros de consulta ou marque suas consultas para otimizar a performance dos insights de consulta. Se você não parametrizar ou incluir tags nas consultas, muitos resultados poderão ser retornados, o que pode fazer com que a tabela de consultas e tags TopN não seja carregada corretamente.
Confirmar se consultas ineficientes são responsáveis pela alta utilização da CPU
O uso total da CPU é uma medida do trabalho (em segundos de CPU) que as queries executadas no banco de dados selecionado realizam ao longo do tempo.

Analise o gráfico para responder a estas perguntas:
Qual banco de dados está passando pela carga? Selecione diferentes bancos de dados na lista para encontrar aqueles com as cargas mais altas. Para descobrir qual banco de dados tem a maior carga, consulte o gráfico Uso total da CPU para bancos de dados no consoleGoogle Cloud .
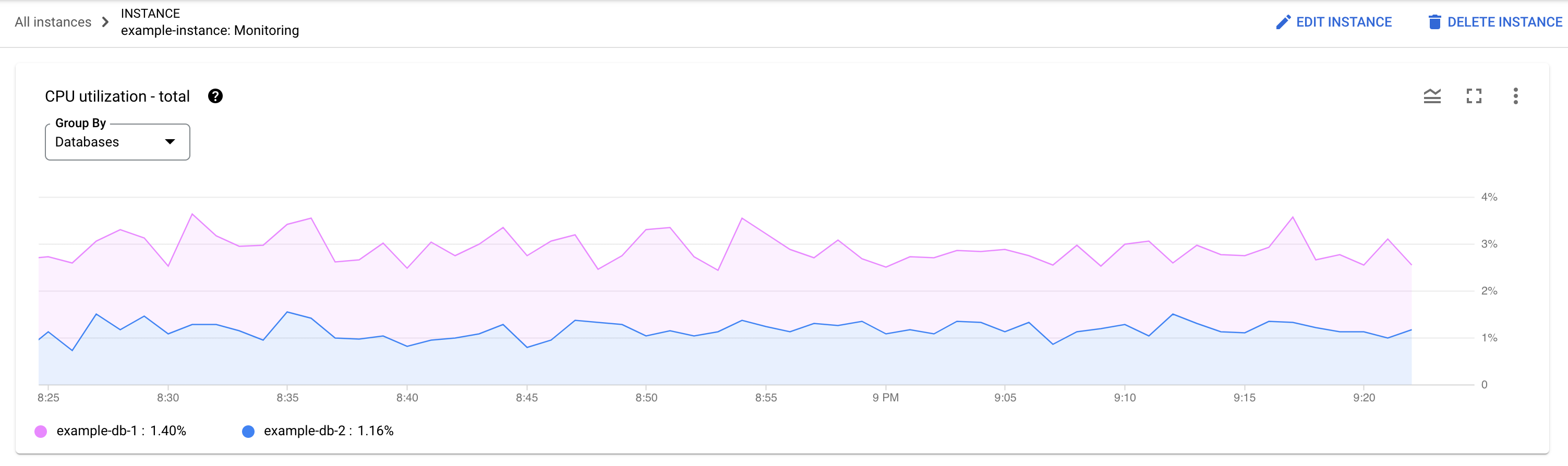
O uso da CPU está alto? O gráfico está piscando ou aumentando ao longo do tempo? Se você não perceber uma utilização alta da CPU, o problema não está nas consultas.
Quanto tempo o uso da CPU tem sido alto? Ele aumentou recentemente ou está alto há algum tempo? Use o seletor de intervalo para selecionar vários períodos e descobrir quanto tempo durou o problema. Aumente o zoom para ver uma janela de tempo em que os picos de carga de consulta são observados. Diminua o zoom para ver até uma semana na linha do tempo.
Se você notar um pico ou um aumento no gráfico correspondente ao uso geral da CPU da instância, provavelmente isso é devido a uma ou mais consultas caras. Em seguida, você pode se aprofundar na jornada de depuração identificando uma consulta ou tag de solicitação potencialmente problemática.
Identificar uma consulta ou tag de solicitação potencialmente problemática
Para identificar uma consulta ou tag de solicitação potencialmente problemática, observe a seção "TopN queries":
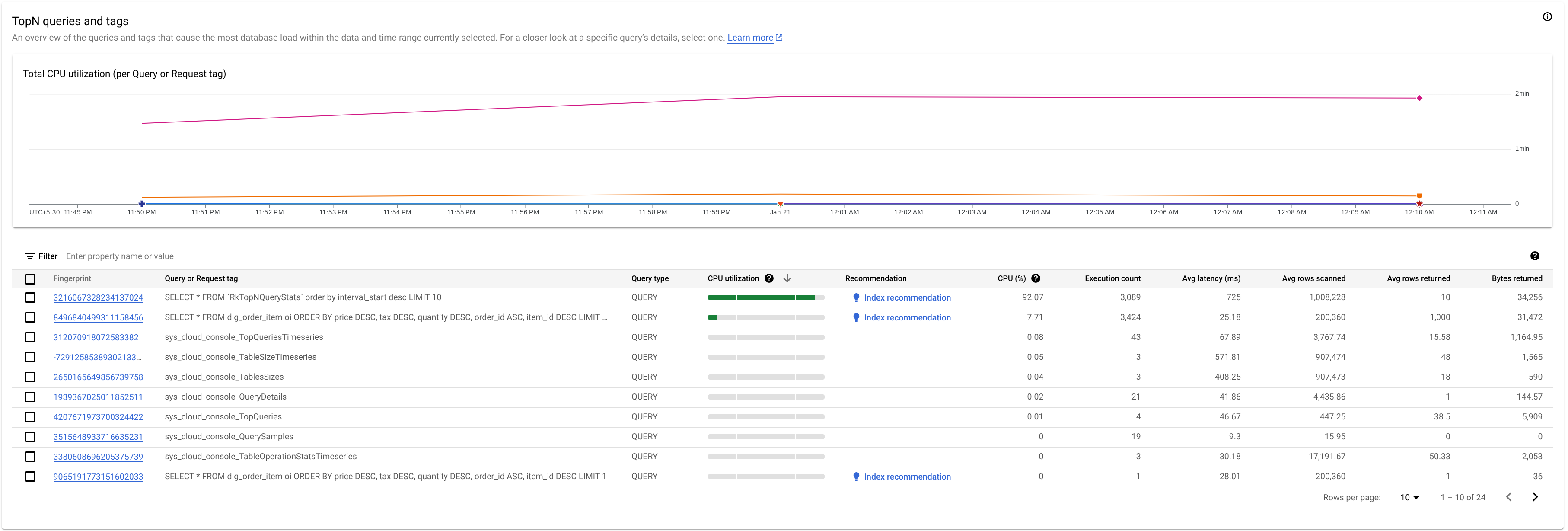
Aqui, vemos que a consulta com a impressão digital 3216067328234137024 tem uma alta utilização da CPU e pode ser problemática.
A tabela Consultas TopN oferece uma visão geral das consultas que usam mais CPU durante o período escolhido, classificadas da maior para a menor. O número de consultas TopN é limitado a 100.
Para os gráficos, buscamos os dados da tabela de estatísticas de consulta do TopN, que tem três granularidades diferentes: 1 minuto, 10 minutos e 1 hora. O valor de cada ponto de dados nos gráficos representa o valor médio em um intervalo de um minuto.
Recomendamos que você adicione tags às suas consultas SQL. A inclusão de tag de consulta ajuda a encontrar problemas em construções de nível superior, como na lógica de negócios ou em um microsserviço.

A tabela mostra as seguintes propriedades:
- Impressão digital: hash da tag de solicitação ou, se a tag não estiver presente, um hash do texto da consulta.
Tag de consulta ou solicitação: se a consulta tiver uma tag associada, a tag de solicitação será mostrada. As estatísticas de várias consultas que têm a mesma string de tag são agrupadas em uma única linha com o valor
REQUEST_TAGcorrespondente à string de tag. Para saber mais sobre o uso de tags de solicitação, consulte Solução de problemas com tags de solicitação e de transação.Se a consulta não tiver uma tag associada, a consulta SQL, truncada para aproximadamente 64 KB, será mostrada. Para a DML em lote, as instruções SQL são simplificadas em uma única linha e concatenadas usando um ponto e vírgula como delimitador. Textos SQL consecutivos idênticos são duplicados antes do truncamento.
Tipo de consulta: indica se uma consulta é
PARTITIONED_QUERYouQUERY. UmPARTITIONED_QUERYé uma consulta com umpartitionTokenobtido da API PartitionQuery. Todas as outras consultas e instruções DML são indicadas pelo tipo de consultaQUERY.Uso da CPU: consumo de recursos da CPU por uma consulta, como uma porcentagem do total de recursos da CPU usados por todas as consultas em execução nos bancos de dados naquele intervalo de tempo, mostrado em uma barra horizontal com um intervalo de 0 a 100.
Recomendação: o Spanner analisa suas consultas para determinar se elas podem se beneficiar de índices aprimorados. Se for o caso, ele recomenda índices novos ou alterados que podem melhorar o desempenho da consulta. Para mais informações, consulte Usar o consultor de índice do Spanner.
CPU (%): consumo de recursos da CPU por uma consulta, como uma porcentagem do total de recursos da CPU usados por todas as consultas em execução nos bancos de dados naquele intervalo de tempo.
Contagem de execuções: número de vezes que o Spanner viu a consulta durante o intervalo.
Latência média (ms): tempo médio, em microssegundos, para cada execução de consulta no banco de dados. Essa média exclui o tempo de codificação e transmissão do conjunto de resultados e também a sobrecarga.
Média de linhas verificadas: número médio de linhas que a consulta verificou, com exceção dos valores excluídos.
Média de linhas retornadas: número médio de linhas que a consulta retornou.
Bytes retornados: número de bytes de dados que a consulta retornou, excluindo a sobrecarga de codificação de transmissão.
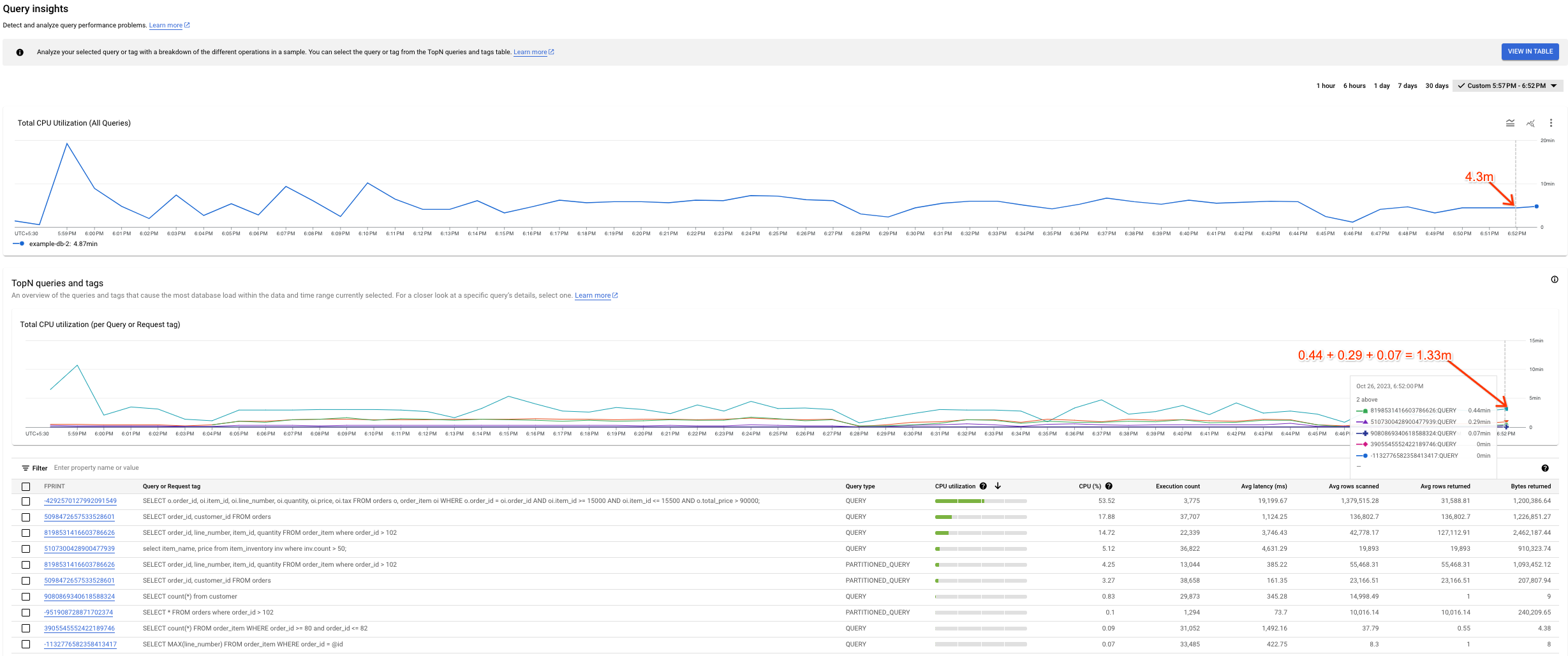
Possível variância entre os gráficos
Talvez você note alguma variação entre os gráficos Uso total da CPU (todas as consultas) e Uso total da CPU (por tag de solicitação ou consulta). Há duas coisas que podem levar a esse cenário:
Diferentes fontes de dados: os dados do Cloud Monitoring, que alimentam o gráfico "Utilização total da CPU (todas as consultas)", geralmente são mais precisos porque são enviados a cada minuto e têm um período de armazenamento de 45 dias. Por outro lado, os dados da tabela do sistema, que alimentam o gráfico "Uso total da CPU (por consulta ou tag de solicitação)", podem ser calculados em média em 10 minutos (ou 1 hora). Nesse caso, podemos perder dados de alta granularidade que vemos no gráfico "Uso total da CPU (todas as consultas)".
Janelas de agregação diferentes: os dois gráficos têm janelas de agregação diferentes. Por exemplo, ao inspecionar um evento com mais de seis horas, consultaríamos a tabela
SPANNER_SYS.QUERY_STATS_TOTAL_10MINUTE. Nesse caso, um evento que ocorre às 10h01 é agregado em 10 minutos e fica presente na tabela do sistema correspondente ao carimbo de data/hora das 10h10.
A captura de tela a seguir mostra um exemplo dessa variância.
Analisar uma consulta ou tag de solicitação específica
Para determinar se uma consulta ou tag de solicitação é a causa raiz do problema, clique na consulta ou tag de solicitação que parece ter a carga mais alta ou que está demorando mais que as outras. É possível selecionar várias consultas e tags de solicitação de uma vez.
Mantenha o ponteiro do mouse sobre o gráfico para consultas na linha do tempo e saiba a utilização da CPU (em segundos).
Para restringir o problema, observe o seguinte:
- Quanto tempo a carga tem sido alta? Está alta no momento? Ou faz muito tempo? Altere os intervalos de tempo para encontrar a data e a hora em que a consulta começou a apresentar baixo desempenho.
- Houve picos no uso da CPU? É possível mudar o período para estudar o uso histórico da CPU na consulta.
- Qual é o consumo de recursos? Como ele se relaciona com outras consultas? Analise a tabela e compare os dados de outras consultas com a selecionada. Existe uma diferença significativa?
Para confirmar que a consulta selecionada está contribuindo para o alto uso da CPU, analise os detalhes da forma de consulta específica (ou tag de solicitação) na página "Detalhes da consulta".
Acessar a página "Detalhes da consulta"
Para conferir os detalhes de uma forma de consulta ou tag de solicitação específica em um formato gráfico, clique na impressão digital associada à consulta ou à tag de solicitação. A página "Detalhes da consulta" é aberta.
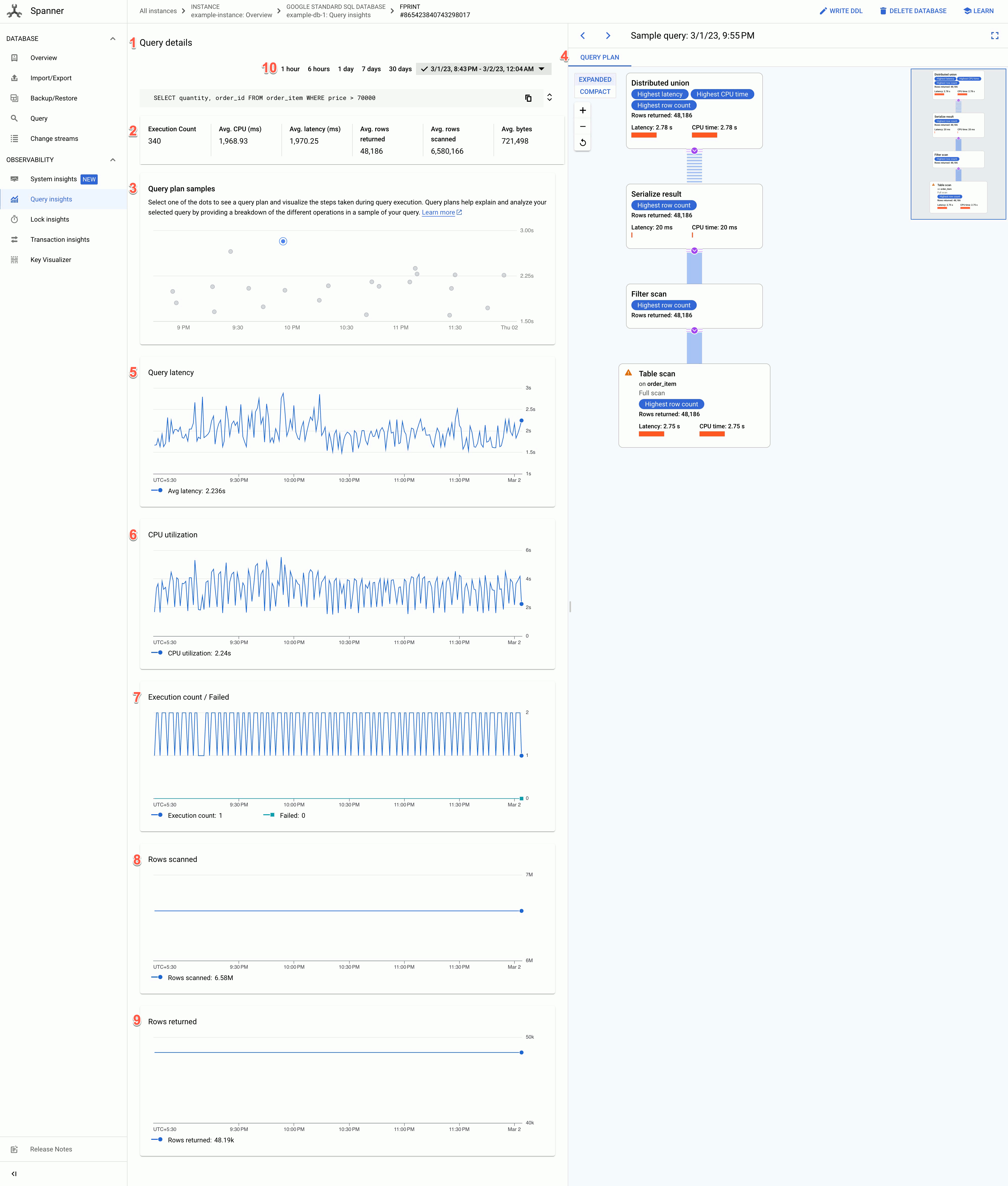
A página "Detalhes da consulta" mostra as seguintes informações:
- Texto dos detalhes da consulta: texto da consulta SQL, truncado para aproximadamente 64 KB. As estatísticas de várias consultas que têm a mesma string de tag são agrupadas em uma única linha com o REQUEST_TAG correspondente a essa string de tag. Somente o texto de uma dessas consultas é mostrado neste campo. Para a DML em lote, o conjunto de instruções SQL é simplificado em uma única linha, concatenado usando um delimitador de ponto e vírgula. Textos SQL idênticos consecutivos são duplicados antes do truncamento.
- Os valores dos seguintes campos:
- Contagem de execuções: número de vezes que o Spanner viu a consulta durante o intervalo.
- CPU média (ms): consumo médio de recursos da CPU, em milissegundos, por uma consulta dos recursos da CPU da instância em um intervalo de tempo.
- Latência média (ms): tempo médio, em milissegundos, para cada execução de consulta no banco de dados. Essa média exclui o tempo de codificação e transmissão do conjunto de resultados e também a sobrecarga.
- Média de linhas retornadas: número médio de linhas que a consulta retornou.
- Média de linhas verificadas: número médio de linhas que a consulta verificou, excluindo valores excluídos.
- Média de bytes: número de bytes de dados que a consulta retornou, excluindo a sobrecarga de codificação de transmissão.
- Gráfico de amostras de planos de consulta: cada ponto no gráfico representa um plano de consulta amostrado em um momento específico e a latência de consulta específica. Clique em um dos pontos no gráfico para ver o plano de consulta e as etapas realizadas durante a execução dela. Observação: os planos de consulta não são compatíveis com consultas que têm partitionTokens obtidos da API PartitionQuery e consultas de DML particionada.
Visualizador do plano de consulta: mostra o plano de consulta selecionado. O Spanner oferece as seguintes opções de layout:
- Visualização em árvore: a visualização em árvore mostra o plano de consulta como um gráfico em que cada nó ou card representa um iterador que consome linhas das entradas e produz linhas para o pai. Clique em cada iterador para ver mais informações.
Visualização sequencial: mostra o plano de consulta em uma tabela hierárquica em que cada linha representa um operador. Clique em cada linha para ver mais informações.

A tabela mostra as seguintes colunas:
- Nome: o nome do operador.
- Grupo de máquinas: o grupo de máquinas em que esse operador foi executado.
- Latência: a quantidade de tempo decorrido durante a execução da operação atual. Esse valor pode ser maior que o tempo de CPU, por exemplo, se o operador aguardou chamadas remotas ou atrasos no sistema de arquivos.
- Latência cumulativa: o tempo decorrido durante a execução de toda a subárvore com acesso root neste operador. Isso não inclui o tempo de criação do plano e outras sobrecargas. Por isso, a latência cumulativa pode ser menor que a duração total da consulta.
- Tempo de CPU: tempo total que a CPU levou para executar a consulta. Não inclui latência da rede. Algumas partes da execução da consulta podem continuar em paralelo. Portanto, é possível que o tempo de CPU seja maior que o tempo decorrido total. Por exemplo, se uma consulta executar 10 operações em paralelo em 1 milissegundo (ms), o tempo decorrido será de 1 ms, mas o tempo de CPU será de 10 ms.
- Linhas retornadas: o número de linhas retornadas pelo operador.
Gráfico de latência da consulta: mostra o valor da latência de uma consulta selecionada durante um período. Ela também mostra a latência média.
Gráfico de uso da CPU: mostra o uso da CPU por uma consulta, em porcentagem, durante um período. Ele também mostra a utilização média da CPU.
Gráfico de contagem de execuções/falhas: mostra a contagem de execuções de uma consulta em um período e o número de vezes que a execução da consulta falhou.
Gráfico de linhas verificadas: mostra o número de linhas que a consulta verificou durante um período.
Gráfico de linhas retornadas: mostra o número de linhas que a consulta retornou em um período.
Filtro de período: filtra os detalhes da consulta por períodos, como hora, dia ou um intervalo personalizado.
Para os gráficos, buscamos os dados da tabela de estatísticas de consulta do TopN, que tem três granularidades diferentes: 1 minuto, 10 minutos e 1 hora. O valor de cada ponto de dados nos gráficos representa o valor médio em um intervalo de um minuto.
Pesquisar todas as execuções de uma consulta no registro de auditoria
Para pesquisar todas as execuções de uma determinada impressão digital de consulta nos Registros de auditoria do Cloud, consulte o registro de auditoria e pesquise qualquer query_fingerprint que corresponda ao campo Fingerprint na tabela de estatísticas de consulta TopN. Para mais informações, consulte a Visão geral dos registros de consulta e visualização. Use esse método para identificar o usuário que iniciou a consulta.