이 페이지에서는 오픈소스 PostgreSQL 데이터베이스를 Spanner로 마이그레이션하는 방법을 안내합니다.
마이그레이션에는 다음 작업이 포함됩니다.
- PostgreSQL 스키마를 Spanner 스키마에 매핑
- Spanner 인스턴스, 데이터베이스, 스키마 만들기
- Spanner 데이터베이스를 사용하도록 애플리케이션 리팩터링
- 데이터 마이그레이션
- 새 시스템을 확인하여 프로덕션 상태로 전환
이 페이지에서는 MusicBrainz PostgreSQL 데이터베이스의 테이블을 사용하는 일부 스키마 예도 제공합니다.
PostgreSQL 스키마를 Spanner에 매핑
데이터베이스를 PostgreSQL에서 Spanner로 이동하는 첫 번째 단계는 스키마에서 변경해야 하는 사항을 결정하는 것입니다. pg_dump를 사용하여 PostgreSQL 데이터베이스의 객체를 정의하는 데이터 정의 언어(DDL) 문을 작성한 후 다음 섹션에 기술된 대로 문을 수정하세요. DDL 문을 업데이트한 후 이를 사용하여 Spanner 인스턴스에 데이터베이스를 만듭니다.
데이터 유형
다음 표에서는 PostgreSQL 데이터 유형이 Spanner 데이터 유형에 매핑되는 방식을 설명합니다. DDL 문의 데이터 유형을 PostgreSQL 데이터 유형에서 Spanner 데이터 유형으로 업데이트합니다.
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING(표준 CIDR 표기법 사용) |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
밀리초 단위로 값을 저장하는 경우 INT64 또는 애플리케이션 정의 간격 형식으로 값을 저장하는 경우 STRING |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING(표준 MAC 주소 표기법 사용) |
money |
INT64 또는 임의 정밀도 숫자의 경우 STRING |
numeric [ (p, s) ]
|
PostgreSQL에서 NUMERIC 및 DECIMAL 데이터 유형은 열 선언에 정의된 대로 최대 217자리의 정밀도와 214-1의 척도를 지원합니다.Spanner NUMERIC 데이터 유형은 최대 38자리의 정밀도와 소수점 9자리의 척도를 지원합니다.더 높은 정밀도가 필요한 경우 다른 메커니즘에 대해 임의 정밀도 숫자 데이터 저장을 참조하세요. |
path |
ARRAY<FLOAT64> |
pg_lsn |
이 데이터 유형은 PostgreSQL 전용이므로 Spanner에는 적용되지 않습니다. |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING(HH:MM:SS.sss 표기법 사용) |
time [ (p) ] with time zone
|
STRING(HH:MM:SS.sss+ZZZZ 표기법 사용) 또는 TIMESTAMP 유형과 다른 시간대를 포함하는 두 개의 열로 나눌 수 있습니다. |
timestamp [ (p) ] [ without time zone ] |
적용되지 않습니다. 원하는 대로 STRING 또는 TIMESTAMP로 보관할 수 있습니다. |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
적용되지 않습니다. 대신 애플리케이션에서 스토리지 메커니즘을 정의합니다. |
tsvector |
적용되지 않습니다. 대신 애플리케이션에서 스토리지 메커니즘을 정의합니다. |
txid_snapshot |
적용되지 않습니다. 대신 애플리케이션에서 스토리지 메커니즘을 정의합니다. |
uuid |
STRING 또는 BYTES |
xml |
STRING |
기본 키
자주 추가하는 Spanner 데이터베이스의 테이블의 경우 단조롭게 증가하거나 감소하는 기본 키를 사용하지 마세요. 사용하면 쓰기 중에 부하 집중이 발생할 수 있습니다. 대신 지원되는 기본 키 전략을 사용하도록 DDL CREATE TABLE 문을 수정하세요. UUID 데이터 유형 또는 함수, SERIAL 데이터 유형, IDENTITY 열 또는 시퀀스 같은 PostgreSQL 기능을 사용하는 경우 Google에서 권장하는 자동 생성 키 마이그레이션 전략을 사용할 수 있습니다.
기본 키를 지정한 후에는 테이블을 삭제하고 다시 만들어야 기본 키 열을 추가 또는 제거하거나 나중에 기본 키 값을 변경할 수 없습니다. 기본 키 지정 방법에 대한 자세한 내용은 스키마 및 데이터 모델 - 기본 키를 참조하세요.
이전 중에 단조롭게 증가하는 기존 정수 키를 유지해야 할 수 있습니다. 자주 업데이트되는 테이블에서 이러한 종류의 키를 유지해야 하고 키에 작업이 많이 수행되는 경우, 기존 키 앞에 의사 랜덤 숫자로 프리픽스를 지정하여 부하 집중 발생을 피할 수 있습니다. 이 기법을 사용하면 Spanner에서 행을 다시 분산합니다. 이 방법에 대한 자세한 내용은 Spanner에 대해 DBA가 알아야 하는 것-파트1: 키와 색인를 참조하세요.
외래 키 및 참조 무결성
Spanner에서 외래 키 지원을 알아보세요.
색인
PostgreSQL b-tree 색인은 Spanner의 보조 색인과 유사합니다. Spanner 데이터베이스에서 보조 색인으로 일반적으로 자주 검색되는 열의 색인을 생성해 성능을 개선하고 테이블에 지정된 모든 UNIQUE 제약조건을 대체합니다. 예를 들어 PostgreSQL DDL에 다음 문이 있는 경우
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
Spanner DDL에서 이 문을 사용합니다.
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
psql에서 \di 메타 명령어를 실행하면 PostgreSQL 테이블에 대한 색인을 찾을 수 있습니다.
필요한 색인을 결정한 후 CREATE INDEX 문을 추가하여 색인을 만듭니다. 색인 만들기의 안내를 따르세요.
Spanner는 색인을 테이블로 구현하므로 단조롭게 증가하는 열(예: TIMESTAMP 데이터가 있는 열)의 색인을 생성하면 부하 집중이 발생할 수 있습니다.
부하 집중을 피하는 방법에 대한 자세한 내용은 Spanner에 대해 DBA가 알아야 하는 것-파트1: 키와 색인를 참조하세요.
제약조건 확인
Spanner에서 CHECK 제약조건 지원을 알아보세요.
기타 데이터베이스 객체
애플리케이션 로직에서 다음 객체의 기능을 만들어야 합니다.
- 뷰
- 트리거
- 저장 프로시저
- 사용자 정의 함수(UDF)
serial데이터 유형을 시퀀스 생성기로 사용하는 열
이 기능을 애플리케이션 로직으로 이전할 때 다음 팁에 유의하세요.
- 사용하는 모든 SQL 문을 PostgreSQL SQL 언어에서 GoogleSQL 언어로 마이그레이션해야 합니다.
- 커서를 사용하는 경우 쿼리를 재작업하여 오프셋 및 제한을 사용할 수 있습니다.
Spanner 인스턴스 만들기
Spanner 스키마 요구사항을 준수하도록 DDL 문을 업데이트한 후 이를 사용하여 Spanner에 데이터베이스를 만듭니다.
Spanner 인스턴스 만들기. 인스턴스의 안내에 따라 성능 목표를 지원하는 올바른 리전별 구성과 컴퓨팅 용량을 결정합니다.
Google Cloud 콘솔 또는
gcloud명령줄 도구를 사용하여 데이터베이스를 만듭니다.
콘솔
- 인스턴스 페이지로 이동
- 데이터베이스 예를 만들려는 인스턴스의 이름을 클릭하여 인스턴스 세부정보 페이지를 엽니다.
- 데이터베이스 만들기를 클릭합니다.
- 데이터베이스의 이름을 입력하고 계속을 클릭합니다.
- 데이터베이스 스키마 정의 섹션에서 텍스트로 수정 컨트롤을 전환합니다.
- DDL 문을 복사하여 DDL 문 필드에 붙여넣습니다.
- 만들기를 클릭합니다.
gcloud
- gcloud CLI 설치
gcloud spanner databases create명령어를 사용하여 데이터베이스를 만듭니다.gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME은 데이터베이스의 이름입니다.
- INSTANCE_NAME은 만든 Spanner 인스턴스입니다.
- DDLn은 수정된 DDL 문입니다.
데이터베이스를 만든 후 IAM 역할 적용의 안내에 따라 사용자 계정을 만들고 Spanner 인스턴스와 데이터베이스에 권한을 부여합니다.
애플리케이션 및 데이터 액세스 계층 리팩토링
이전 데이터베이스 객체를 대체하기 위해 필요한 코드 외에, 다음 기능을 처리하기 위한 애플리케이션 로직을 추가해야 합니다.
- 순차 키에 대해 쓰기 속도가 높은 테이블의 경우 쓰기에 대한 기본 키 해싱
- 데이터 확인 중,
CHECK제약조건에서 아직 다루지 않음 - PostgreSQL 스키마의 트리거를 통해 처리되는 기능을 포함하여 외래 키, 테이블 인터리브 처리 또는 애플리케이션 로직에서 아직 다루지 않는 참조 무결성 검사
리팩토링할 때 다음 프로세스를 사용하는 것이 좋습니다.
- 데이터베이스에 액세스하는 모든 애플리케이션 코드를 찾아서 단일 모듈 또는 라이브러리로 리팩토링합니다. 이렇게 하면 데이터베이스에 액세스하는 코드를 정확하게 알 수 있으므로 수정해야 하는 코드도 정확하게 알 수 있습니다.
- PostgreSQL에 읽고 쓰는 원본 코드와 같은 기능을 구현하도록 Spanner 인스턴스에서 읽기 및 쓰기를 수행하는 코드를 작성합니다. Spanner의 데이터가 PostgreSQL의 데이터와 동일하도록 쓰기 중에 변경된 열뿐만 아니라 전체 행을 업데이트합니다.
- Spanner에서 사용할 수 없는 데이터베이스 객체와 함수의 기능을 대체하는 코드를 작성합니다.
데이터 이전
Spanner 데이터베이스를 만들고 애플리케이션 코드를 리팩토링한 후에 데이터를 Spanner에 마이그레이션할 수 있습니다.
- PostgreSQL
COPY명령어를 사용하여 데이터를 .csv 파일에 덤프합니다. .csv 파일을 Cloud Storage에 업로드합니다.
- Cloud Storage 버킷을 생성합니다.
- Cloud Storage 콘솔에서 버킷 이름을 클릭하여 버킷 브라우저를 엽니다.
- 파일 업로드를 클릭합니다.
- .csv 파일이 있는 디렉토리로 이동하여 파일을 선택합니다.
- 열기를 클릭합니다.
애플리케이션을 만들어 데이터를 Spanner로 가져옵니다. 이 애플리케이션은 Dataflow를 사용할 수도 있고 클라이언트 라이브러리를 직접 사용할 수도 있습니다. 최고의 성능을 얻으려면 데이터 일괄 로드 권장사항의 안내를 따라야 합니다.
테스트
Spanner 인스턴스에 대해 모든 애플리케이션 함수를 테스트하여 예상대로 작동하는지 확인합니다. 프로덕션 수준 작업 부하를 실행하여 성능이 요구사항을 충족하는지 확인합니다. 성능 목표를 달성하도록 필요에 맞게 컴퓨팅 용량을 업데이트하세요.
새 시스템으로 이동
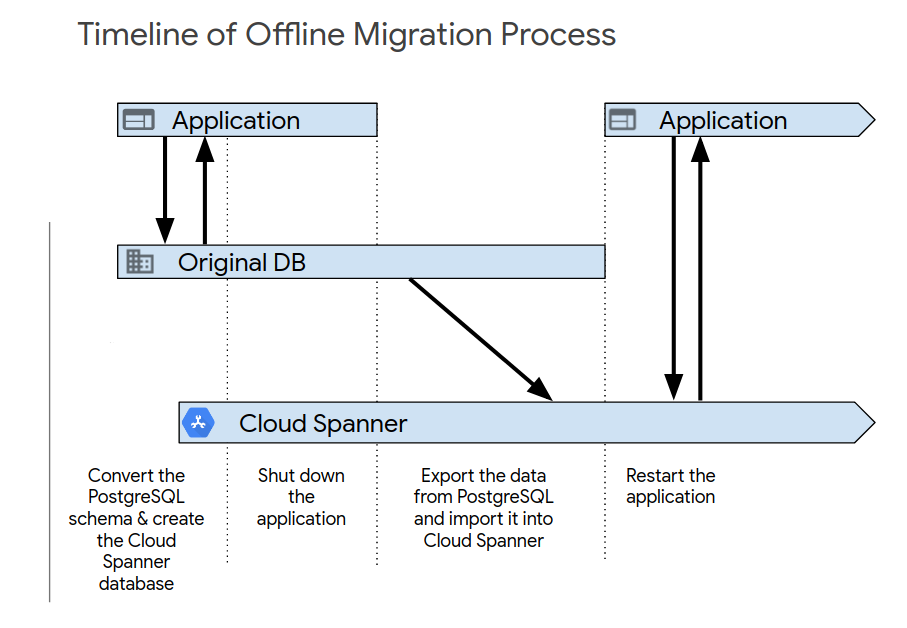
초기 애플리케이션 테스트를 완료한 후 다음 프로세스 중 하나를 사용하여 새로운 시스템을 설정합니다. 이전하는 가장 간단한 방법은 오프라인 이전입니다. 하지만 이 방법은 일정 기간 동안 애플리케이션을 사용할 수 없게 만들고, 나중에 데이터 문제를 발견해도 롤백할 방법이 제공되지 않습니다. 오프라인 이전을 수행하려면 다음 단계를 따르세요.
- Spanner 데이터베이스에서 모든 데이터를 삭제합니다.
- PostgreSQL 데이터베이스를 대상으로 하는 애플리케이션을 종료합니다.
- 마이그레이션 개요에 설명된 대로 PostgreSQL 데이터베이스에서 모든 데이터를 내보내고 Spanner 데이터베이스로 가져옵니다.
Spanner 데이터베이스를 타겟팅하는 애플리케이션을 시작합니다.
라이브 마이그레이션도 가능하지만 마이그레이션을 지원하려면 애플리케이션을 대대적으로 변경해야 합니다.
스키마 이전 예
이 예시에서는 MusicBrainz PostgreSQL 데이터베이스 스키마의 여러 테이블에 대한 CREATE TABLE 문을 보여줍니다.
각 예시에는 PostgreSQL 스키마와 Spanner 스키마가 모두 포함되어 있습니다.
artist_credit 테이블
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
recording 테이블
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
recording-alias 테이블
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);