Auf dieser Seite finden Sie eine Anleitung zur Migration einer Open-Source-PostgreSQL-Datenbank zu Spanner.
Die Migration umfasst die folgenden Aufgaben:
- PostgreSQL-Schema einem Spanner-Schema zuordnen
- Spanner-Instanz, Datenbank und Schema erstellen
- Anwendung für die Arbeit mit der Spanner-Datenbank umgestalten
- Daten migrieren
- Neues System überprüfen und in Produktionsstatus übergehen
Auf dieser Seite finden Sie außerdem einige Beispielschemas, die Tabellen aus der PostgreSQL-Datenbank MusicBrainz verwenden.
PostgreSQL-Schema zu Spanner zuordnen
Bestimmen Sie beim Verschieben einer Datenbank von PostgreSQL zu Spanner zuerst, welche Änderungen am Schema erforderlich sind. Erstellen Sie dafür mit pg_dump DDL-Anweisungen (Data Definition Language, Datendefinitionssprache), die Objekte in der PostgreSQL-Datenbank definieren. Verändern Sie dann die Anweisungen, wie in den folgenden Abschnitten beschrieben. Nachdem Sie die DDL-Anweisungen aktualisiert haben, erstellen Sie mit den DDL-Anweisungen eine Datenbank in einer Spanner-Instanz.
Datentypen
In der folgenden Tabelle wird beschrieben, wie PostgreSQL-Datentypen den Spanner-Datentypen zugeordnet werden. Aktualisieren Sie die Datentypen in den DDL-Anweisungen von PostgreSQL-Datentypen zu Spanner-Datentypen.
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING mit der standardmäßigen CIDR-Schreibweise |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
INT64, wenn der Wert in Millisekunden gespeichert wird, oder STRING, wenn der Wert in einem anwendungsdefinierten Intervallformat gespeichert wird. |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING mit der standardmäßigen Schreibweise der MAC-Adresse |
money |
INT64 oder STRING für Zahlen mit beliebiger Genauigkeit. |
numeric [ (p, s) ]
|
In PostgreSQL unterstützen die Datentypen NUMERIC und DECIMAL eine Genauigkeit von bis zu 217 Stellen sowie 214–1 gemäß der Skalierung, wie in der Spaltendeklaration definiert.Der Spanner-Datentyp NUMERIC unterstützt eine Genauigkeit von bis zu 38 Stellen und eine Skalierung mit 9 Dezimalstellen.Wenn Sie eine höhere Genauigkeit benötigen, finden Sie unter Numerische Daten mit beliebiger Genauigkeit speichern alternative Mechanismen. |
path |
ARRAY<FLOAT64> |
pg_lsn |
Dies ist ein PostgreSQL-spezifischer Datentyp, daher gibt es kein Äquivalent in Spanner. |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING, mit der Schreibweise HH:MM:SS.sss |
time [ (p) ] with time zone
|
STRING, mit der Schreibweise HH:MM:SS.sss+ZZZZ Alternativ kann diese in zwei Spalten aufgeteilt werden. Dabei hat die eine den Typ TIMESTAMP und die andere enthält die Zeitzone. |
timestamp [ (p) ] [ without time zone ] |
Kein Äquivalent. Kann nach Belieben als STRING oder TIMESTAMP gespeichert werden. |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
Kein Äquivalent. Definieren Sie stattdessen einen Speichermechanismus in der Anwendung. |
tsvector |
Kein Äquivalent. Definieren Sie stattdessen einen Speichermechanismus in der Anwendung. |
txid_snapshot |
Kein Äquivalent. Definieren Sie stattdessen einen Speichermechanismus in der Anwendung. |
uuid |
STRING oder BYTES |
xml |
STRING |
Primärschlüssel
Sie sollten in der Spanner-Datenbank für häufig anzufügende Tabellen keine kontinuierlich größer oder kleiner werdende Primärschlüssel verwenden, da dies bei Schreibvorgängen Hotspots verursacht. Ändern Sie stattdessen die DDL-Anweisungen CREATE TABLE so, dass sie unterstützte Primärschlüsselstrategien verwenden. Wenn Sie eine PostgreSQL-Funktion wie einen UUID-Datentyp oder eine SERIAL-Funktion, IDENTITY-Spalte oder IDENTITY-Sequenz verwenden, können Sie die von uns empfohlenen automatisch generierten Migrationsstrategien für Schlüssel verwenden.
Nachdem Sie den Primärschlüssel festgelegt haben, können Sie keine Primärschlüsselspalte hinzufügen oder entfernen und auch keinen Primärschlüsselwert ändern, ohne die Tabelle zu löschen und neu zu erstellen. Weitere Informationen zum Zuweisen des Primärschlüssels finden Sie unter Schema und Datenmodell – Primärschlüssel.
Während der Migration ist es möglicherweise erforderlich, dass Sie einige vorhandene kontinuierlich steigende Ganzzahlschlüssel beibehalten. Wenn eine Aufbewahrung dieser Schlüssel in einer Tabelle erforderlich ist, die häufig aktualisiert wird und viele Vorgänge für diese Schlüssel enthält, können Sie Hotspots vermeiden. Stellen Sie dazu dem vorhandenen Schlüssel eine Pseudogenerierung zufälliger Zahlen voran. Dadurch verteilt Spanner die Zeilen neu. Weitere Informationen zu diesem Ansatz finden Sie unter Das sollten Datenbankadministratoren über Spanner wissen, Teil 1: Schlüssel und Indexe.
Fremdschlüssel und referenzielle Integrität
Weitere Informationen zur Unterstützung von Fremdschlüsseln in Spanner
Indexe
PostgreSQL-B-Tree-Indexe ähneln den sekundären Indexen in Spanner. In einer Spanner-Datenbank können Sie mit sekundären Indexen häufig gesuchte Spalten indizieren, um die Leistung zu verbessern, und UNIQUE Einschränkungen in den Tabellen ersetzen. Wenn die PostgreSQL-DDL beispielsweise folgende Anweisung enthält:
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
Dann würden Sie diese Anweisung in der Spanner-DDL verwenden:
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
Wenn Sie die Indexe in PostgreSQL-Tabellen suchen, führen Sie den Meta-Befehl \di in psql aus.
Nachdem Sie die benötigten Indexe ermittelt haben, fügen Sie CREATE INDEX-Anweisungen hinzu, um sie zu erstellen. Folgen Sie der Anleitung unter Indexe erstellen.
Spanner implementiert Indexe als Tabellen, sodass das Indizieren von kontinuierlich steigenden Spalten (wie solchen, die TIMESTAMP-Daten enthalten) einen Hotspot verursachen kann.
Weitere Informationen zu diesem Ansatz finden Sie unter Das sollten Datenbankadministratoren über Spanner wissen, Teil 1: Schlüssel und Indexe.
Einschränkungen prüfen
Weitere Informationen zur Unterstützung von CHECK-Einschränkungen in Spanner
Andere Datenbankobjekte
Es ist erforderlich, dass Sie die Funktionen der folgenden Objekte in der Anwendungslogik erstellen:
- Ansichten
- Trigger
- Gespeicherte Prozeduren
- Nutzerdefinierte Funktionen (UDFs)
- Spalten mit
serial-Datentypen als Sequenzgeneratoren
Beachten Sie bei der Migration dieser Funktionen in die Anwendungslogik die folgenden Hinweise:
- Es ist erforderlich, dass Sie alle von Ihnen verwendeten SQL-Anweisungen vom PostgreSQL-SQL-Dialekt zum GoogleSQL-Dialekt migrieren.
- Wenn Sie Cursor verwenden, können Sie die Abfrage für Offsets und Limits überarbeiten.
Spanner-Instanz erstellen
Nachdem Sie die DDL-Anweisungen so aktualisiert haben, dass sie den Anforderungen des Spanner-Schemas entsprechen, erstellen Sie die Datenbank in Spanner.
Erstellen Sie eine Spanner-Instanz. Folgen Sie der Anleitung unter Instanzen, um die korrekte regionale Konfiguration und die Rechenkapazität zu ermitteln, die Ihre Leistungsziele unterstützen.
Erstellen Sie die Datenbank mithilfe der Google Cloud Console oder dem
gcloud-Befehlszeilentool:
Console
- Zur Seite "Instanzen"
- Klicken Sie auf den Namen der Instanz, in der Sie die Beispieldatenbank erstellen möchten, um die Seite mit den Instanzdetails zu öffnen.
- Klicken Sie auf Datenbank erstellen.
- Geben Sie einen Namen für die Datenbank ein und klicken Sie auf Weiter.
- Schalten Sie im Abschnitt Datenbankschema definieren das Steuerelement Als Text bearbeiten ein.
- Kopieren Sie Ihre DDL-Anweisungen und fügen Sie sie in das Feld DDL-Anweisungen ein.
- Klicken Sie auf Erstellen.
gcloud
- Installieren Sie die gcloud CLI.
- Erstellen Sie die Datenbank mit dem Befehl
gcloud spanner databases create:gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME ist der Name der Datenbank.
- INSTANCE_NAME ist die von Ihnen erstellte Spanner-Instanz.
- DDLn sind Ihre geänderten DDL-Anweisungen.
Folgen Sie nach dem Erstellen der Datenbank der Anleitung unter IAM-Rollen anwenden, um Nutzerkonten zu erstellen und Berechtigungen für die Spanner-Instanz und ‑Datenbank zu erteilen.
Anwendungen und Datenzugriffsschichten überarbeiten
Zusätzlich zum Code, der zum Ersetzen der vorhergehenden Datenbankobjekte erforderlich ist, ist es notwendig, dass Sie Anwendungslogik zur Verarbeitung der folgenden Funktionen hinzufügen:
- Hash-Primärschlüssel für Schreibvorgänge, für Tabellen mit hohen Schreibraten für sequenzielle Schlüssel.
- Daten validieren, die noch nicht durch
CHECK-Einschränkungen abgedeckt sind. - Referenzielle, noch nicht durch Fremdschlüssel, Tabellenverschränkungen oder Anwendungslogik abgedeckte Integritätsprüfungen, einschließlich Funktionen, die von Triggern im PostgreSQL-Schema verarbeitet werden.
Wir empfehlen bei der Refaktorierung den folgenden Prozess:
- Suchen Sie nach dem gesamten auf die Datenbank zugreifenden Anwendungscode und wandeln Sie ihn in ein einzelnes Modul oder eine Bibliothek um. So wissen Sie genau, welcher Code auf die Datenbank zugreift und welcher Code geändert werden muss.
- Schreiben Sie Code, der Lese- und Schreibvorgänge in der Spanner-Instanz ausführt und parallele Funktionen zum ursprünglichen Code bietet, der Lese- und Schreibvorgänge in PostgreSQL ausführt. Aktualisieren Sie beim Schreiben die gesamte Zeile, nicht nur die geänderten Spalten, damit die Daten in Spanner mit denen in PostgreSQL identisch sind.
- Schreiben Sie Code, der die Funktionalität der nicht in Spanner verfügbaren Datenbankobjekte und Funktionen ersetzt.
Daten migrieren
Nachdem Sie Ihre Spanner-Datenbank erstellt und den Anwendungscode umgestaltet haben, können Sie Ihre Daten zu Spanner migrieren.
- Sichern Sie mit dem PostgreSQL-Befehl
COPYDaten in CSV-Dateien. Laden Sie die CSV-Dateien in Cloud Storage hoch.
- Erstellen Sie einen Cloud Storage-Bucket.
- Klicken Sie in der Cloud Storage-Konsole auf den Bucket-Namen, um den Bucket-Browser zu öffnen.
- Klicken Sie auf Dateien hochladen.
- Gehen Sie zum Verzeichnis mit den CSV-Dateien und wählen Sie die Dateien aus.
- Klicken Sie auf Öffnen.
Erstellen Sie eine Anwendung für den Import von Daten in Spanner. Diese Anwendung kann Dataflow oder die Clientbibliotheken direkt verwenden. Folgen Sie der Anleitung unter Best Practices für das Laden im Bulk, um die beste Leistung zu erzielen.
Tests
Testen Sie alle Anwendungsfunktionen mit der Spanner-Instanz, damit sie auch erwartungsgemäß funktionieren. Führen Sie Arbeitslasten auf Produktionsebene aus, damit die Leistung Ihren Anforderungen tatsächlich entspricht. Aktualisieren Sie die Rechenkapazität nach Bedarf, damit Sie Ihre Leistungsziele erreichen können.
Auf das neue System umsteigen
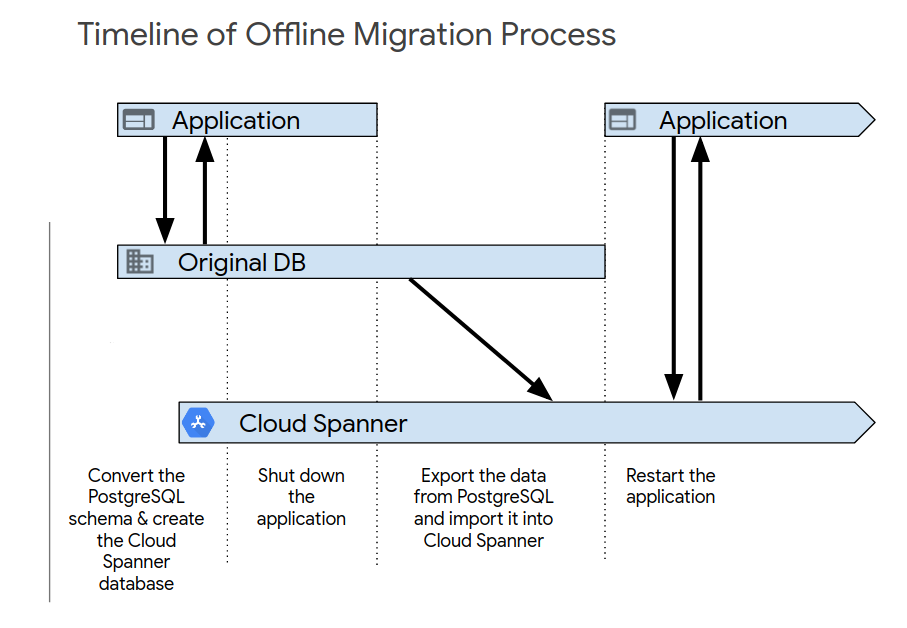
Nachdem Sie die ersten Anwendungstests abgeschlossen haben, aktivieren Sie das neue System mit einem der folgenden Prozesse. Die Offline-Migration ist die einfachste Methode für die Migration. Bei diesem Ansatz ist Ihre Anwendung jedoch für einen bestimmten Zeitraum nicht verfügbar und es wird kein Rollback-Pfad bereitgestellt, falls später Datenprobleme auftreten sollten. So führen Sie eine Offline-Migration durch:
- Löschen Sie alle Daten in der Spanner-Datenbank.
- Fahren Sie die Anwendung herunter, die die PostgreSQL-Datenbank als Ziel hat.
- Exportieren Sie alle Daten aus der PostgreSQL-Datenbank und importieren Sie sie in die Spanner-Datenbank, wie unter Migration – Übersicht beschrieben.
Starten Sie die Anwendung, die die Spanner-Datenbank als Ziel hat.
Eine Live-Migration ist möglich und erfordert umfangreiche Änderungen an Ihrer Anwendung zur Unterstützung der Migration.
Beispiele für Schemamigration
Diese Beispiele zeigen Anweisungen CREATE TABLE für mehrere Tabellen in dem PostgreSQL-DatenbankschemaMusicBrainz.
Jedes Beispiel enthält sowohl das PostgreSQL-Schema als auch das Spanner-Schema.
Tabelle "artist_credit"
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
Tabelle "recording"
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
Tabelle "recording-alias"
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);