In einer Spanner-Datenbank erstellt Spanner automatisch einen Index für den Primärschlüssel jeder Tabelle. Sie müssen beispielsweise nichts tun, um den Primärschlüssel von Singers zu indexieren, da er bereits automatisch indexiert wird.
Sie können auch sekundäre Indexe für andere Spalten erstellen. Wenn Sie einen sekundären Index für eine Spalte hinzufügen, können Sie Daten in dieser Spalte effizienter nachschlagen. Wenn Sie beispielsweise schnell ein Album nach Titel suchen müssen, sollten Sie einen sekundären Index für AlbumTitle erstellen, damit Spanner nicht die gesamte Tabelle scannen muss.
Wenn die Suche im vorherigen Beispiel innerhalb einer Lese-/Schreibtransaktion erfolgt, speichert die effizientere Suche auch keine Sperren für die gesamte Tabelle, wodurch gleichzeitige Einfügungen und Aktualisierungen für Zeilen außerhalb des AlbumTitle-Suchbereichs der Tabelle durchgeführt werden.
Sekundäre Indexe bieten nicht nur Vorteile bei Suchvorgängen, sondern können auch dazu beitragen, dass Spanner Scans effizienter ausführt, indem Indexscans anstelle von vollständigen Tabellenscans verwendet werden.
In jedem sekundären Index speichert Spanner die folgenden Daten:
- Alle Schlüsselspalten aus der Basistabelle
- Alle Spalten, die im Index enthalten sind
- Alle in der optionalen
STORING-Klausel (GoogleSQL-Dialektdatenbanken) oderINCLUDE-Klausel (PostgreSQL-Dialektdatenbanken) der Indexdefinition angegebenen Spalten.
Im Laufe der Zeit analysiert Spanner Ihre Tabellen, damit Ihre sekundären Indexe für die geeigneten Abfragen verwendet werden.
Sekundären Index hinzufügen
Am effizientesten ist die Erweiterung einer Tabelle um einen sekundären Index gleich bei deren Erstellung. Wenn Sie eine Tabelle und ihre Indexe gleichzeitig erstellen möchten, senden Sie die DDL-Anweisungen für die neue Tabelle und die neuen Indexe in einer einzigen Anfrage an Spanner.
Sie können in Spanner auch einen neuen sekundären Index zu einer vorhandenen Tabelle hinzufügen, während die Datenbank weiterhin Traffic bereitstellt. Wie bei allen anderen Schemaänderungen in Spanner erfordert das Erstellen eines Indexes in einer vorhandenen Datenbank weder, dass die Datenbank offline geschaltet wird, noch, dass ganze Spalten oder Tabellen gesperrt werden.
Immer wenn ein neuer Index zu einer vorhandenen Tabelle hinzugefügt wird, führt Spanner automatisch einen Backfill durch, d. h., der Index wird mit einer aktuellen Ansicht der zu indexierenden Daten gefüllt. Spanner verwaltet diesen Backfill-Prozess für Sie. Der Prozess wird im Hintergrund mit Knotenressourcen mit niedriger Priorität ausgeführt. Die Geschwindigkeit des Index-Backfills passt sich während der Indexerstellung an die sich ändernden Knotenressourcen an. Der Backfill hat keine wesentlichen Auswirkungen auf die Leistung der Datenbank.
Die Indexerstellung kann mehrere Minuten bis hin zu vielen Stunden in Anspruch nehmen. Da die Indexerstellung eine Schemaaktualisierung ist, unterliegt sie denselben Leistungsbeschränkungen wie jede andere Schemaaktualisierung. Wie viel Zeit zum Erstellen eines sekundären Index benötigt wird, hängt von mehreren Faktoren ab:
- Größe des Datasets
- Rechenkapazität der Instanz
- Auslastung der Instanz
Den Fortschritt eines Index-Backfill-Prozesses können Sie im Abschnitt „Fortschritt“ aufrufen.
Die Verwendung der Spalte Commit-Zeitstempel als erster Teil des sekundären Index kann Hotspots erstellen und die Schreibleistung verringern.
Mit der Anweisung CREATE INDEX definieren Sie einen sekundären Index im Schema. Hier einige Beispiele:
So indexieren Sie alle Singers in der Datenbank nach ihrem Vor- und Nachnamen:
GoogleSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
PostgreSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
So erstellen Sie einen Index aller Songs in der Datenbank nach dem Wert von SongName:
GoogleSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
PostgreSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
Wenn Sie nur die Titel eines bestimmten Interpreten indexieren möchten, verwenden Sie die Klausel INTERLEAVE IN, um den Index in der Tabelle Singers zu verschachteln:
GoogleSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName),
INTERLEAVE IN Singers;
PostgreSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
So indexieren Sie nur die Titel eines bestimmten Albums:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName)
INTERLEAVE IN Albums;
So indexieren Sie nach SongName in absteigender Reihenfolge:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC)
INTERLEAVE IN Albums;
Die vorherige DESC-Anmerkung gilt nur für SongName. Wenn Sie nach anderen Indexschlüsseln in absteigender Reihenfolge indexieren möchten, versehen Sie sie ebenfalls mit DESC: SingerId DESC, AlbumId DESC.
Beachten Sie außerdem, dass PRIMARY_KEY ein reserviertes Wort ist und nicht als Name eines Index verwendet werden kann. Dies ist der Name, der dem Pseudo-Index zugewiesen wird, der beim Erstellen einer Tabelle mit PRIMARY KEY-Spezifikation erstellt wird.
Weitere Informationen und Best Practices für die Auswahl nicht verschränkter Indexe und verschränkter Indexe finden Sie unter Indexoptionen und Verschränkte Indexe für eine Spalte verwenden, deren Wert monoton erhöht oder reduziert wird..
Indexe und Verschachtelung
Spanner-Indizes können mit anderen Tabellen verschachtelt werden, um Indexzeilen mit denen einer anderen Tabelle zu platzieren. Ähnlich wie bei der Spanner-Tabellenverschachtelung müssen die Primärschlüsselspalten des übergeordneten Elements des Index ein Präfix der indexierten Spalten sein, das in Typ und Sortierreihenfolge übereinstimmt. Im Gegensatz zu verschachtelten Tabellen ist kein Abgleich der Spaltennamen erforderlich. Jede Zeile eines verschachtelten Index wird physisch zusammen mit der zugehörigen übergeordneten Zeile gespeichert.
Betrachten Sie beispielsweise das folgende Schema:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo PROTO<Singer>(MAX)
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
PublisherId INT64 NOT NULL
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
PublisherId INT64 NOT NULL,
SongName STRING(MAX)
) PRIMARY KEY (SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE TABLE Publishers (
Id INT64 NOT NULL,
PublisherName STRING(MAX)
) PRIMARY KEY (Id);
Wenn Sie alle Singers in der Datenbank nach ihrem Vor- und Nachnamen indexieren möchten, müssen Sie einen Index erstellen. So definieren Sie den Index SingersByFirstLastName:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Wenn Sie einen Index von Songs für (SingerId, AlbumId, SongName) erstellen möchten, können Sie Folgendes tun:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName);
Sie können auch einen Index erstellen, der mit einem Ancestor von Songs verschachtelt ist, z. B. so:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
Außerdem können Sie einen Index von Songs für (PublisherId, SingerId, AlbumId, SongName) erstellen, der mit einer Tabelle verschränkt ist, die kein übergeordnetes Element von Songs ist, z. B. Publishers. Beachten Sie, dass der Primärschlüssel für die Tabelle Publishers (id) im folgenden Beispiel kein Präfix der indexierten Spalten ist. Das ist weiterhin zulässig, da Publishers.Id und Songs.PublisherId denselben Typ, dieselbe Sortierreihenfolge und dieselbe Nullable-Eigenschaft haben.
CREATE INDEX SongsByPublisherSingerAlbumSongName
ON Songs(PublisherId, SingerId, AlbumId, SongName),
INTERLEAVE IN Publishers;
Fortschritt des Index-Backfills prüfen
Console
Klicken Sie im Spanner-Navigationsmenü auf den Tab Vorgänge. Auf der Seite Vorgänge wird eine Liste der laufenden Vorgänge angezeigt.
Suchen Sie in der Liste nach dem Backfill-Vorgang. Wenn der Vorgang noch läuft, wird in der Spalte Ende ein Fortschrittsindikator mit dem Prozentsatz des abgeschlossenen Vorgangs angezeigt (siehe Abbildung):
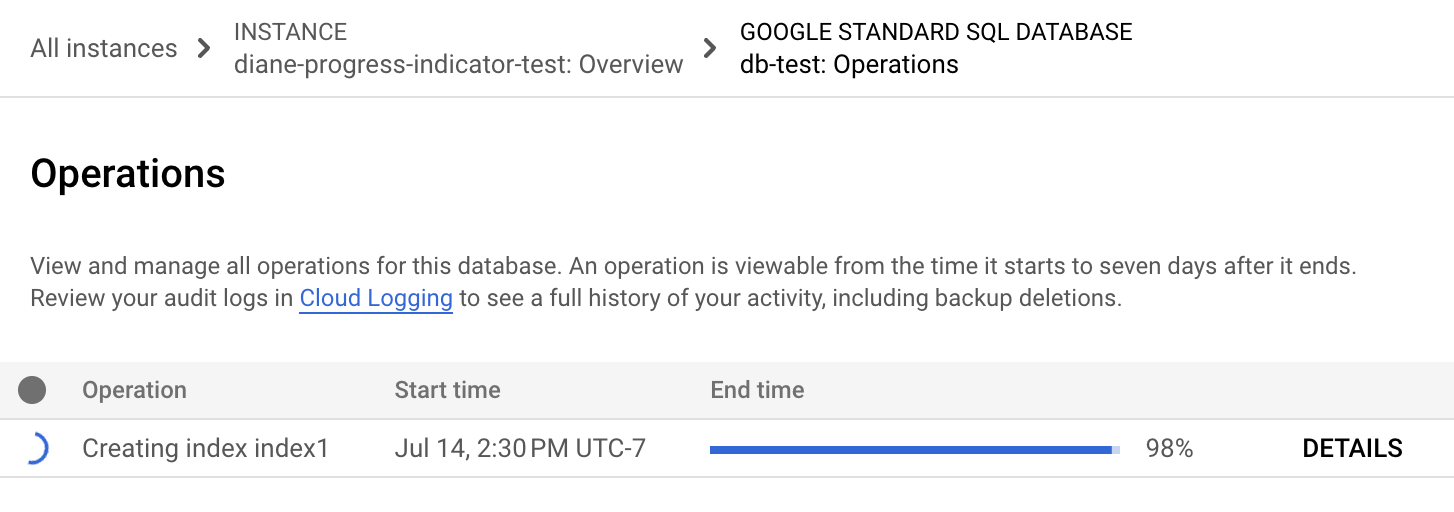
gcloud
Verwenden Sie gcloud spanner operations describe, um den Fortschritt eines Vorgangs zu prüfen.
Rufen Sie die Vorgangs-ID ab:
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Ersetzen Sie Folgendes:
- INSTANCE-NAME durch den Namen der Spanner-Instanz.
- DATABASE-NAME durch den Namen der Datenbank.
Verwendungshinweise:
Wenn Sie die Liste einschränken möchten, geben Sie das Flag
--filteran. Beispiel:--filter="metadata.name:example-db"listet nur die Vorgänge für eine bestimmte Datenbank auf.--filter="error:*"listet nur die fehlgeschlagenen Sicherungsvorgänge auf.
Informationen zur Filtersyntax finden Sie unter gcloud topic filters. Informationen zum Filtern von Sicherungsvorgängen finden Sie im Feld
filterin ListBackupOperationsRequest.Beim Flag
--typewird nicht zwischen Groß- und Kleinschreibung unterschieden.
Die Ausgabe sieht dann ungefähr so aus:
OPERATION_ID STATEMENTS DONE @TYPE _auto_op_123456 CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName) False UpdateDatabaseDdlMetadata CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName), INTERLEAVE IN Albums _auto_op_234567 True CreateDatabaseMetadataFühren Sie
gcloud spanner operations describeaus:gcloud spanner operations describe \ --instance=INSTANCE-NAME \ --database=DATABASE-NAME \ projects/PROJECT-NAME/instances/INSTANCE-NAME/databases/DATABASE-NAME/operations/OPERATION_ID
Ersetzen Sie Folgendes:
- INSTANCE-NAME: Der Name der Spanner-Instanz.
- DATABASE-NAME: Der Name der Spanner-Datenbank.
- PROJECT-NAME: Der Projektname.
- OPERATION-ID: Die Vorgangs-ID des Vorgangs, den Sie prüfen möchten.
Im Abschnitt
progressder Ausgabe wird der Prozentsatz des abgeschlossenen Vorgangs angezeigt. Die Ausgabe sieht dann ungefähr so aus:done: true ... progress: - endTime: '2021-01-22T21:58:42.912540Z' progressPercent: 100 startTime: '2021-01-22T21:58:11.053996Z' - progressPercent: 67 startTime: '2021-01-22T21:58:11.053996Z' ...
REST Version 1
Rufen Sie die Vorgangs-ID ab:
gcloud spanner operations list --instance=INSTANCE-NAME
--database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Ersetzen Sie Folgendes:
- INSTANCE-NAME durch den Namen der Spanner-Instanz.
- DATABASE-NAME durch den Namen der Datenbank.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT-ID: Projekt-ID.
- INSTANCE-ID: Instanz-ID.
- DATABASE-ID: die Datenbank-ID.
- OPERATION-ID: Die Vorgangs-ID.
HTTP-Methode und URL:
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
...
"progress": [
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:27.366688Z",
"endTime": "2023-05-27T00:52:30.184845Z"
},
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:30.184845Z",
"endTime": "2023-05-27T00:52:40.750959Z"
}
],
...
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Bei gcloud und REST finden Sie den Fortschritt jeder Index-Backfill-Anweisung im Abschnitt progress. Für jede Anweisung im Anweisungsarray gibt es ein entsprechendes Feld im Fortschrittsarray. Die Reihenfolge dieses Fortschritts-Arrays entspricht der Reihenfolge des Statements-Arrays. Sobald die Felder startTime, progressPercent und endTime verfügbar sind, werden sie entsprechend ausgefüllt.
In der Ausgabe wird keine geschätzte Zeit für den Abschluss des Backfill-Vorgangs angezeigt.
Wenn der Vorgang zu lange dauert, können Sie ihn abbrechen. Weitere Informationen finden Sie unter Indexerstellung abbrechen.
Szenarien beim Ansehen des Index-Backfill-Fortschritts
Es gibt verschiedene Szenarien, denen Sie beim Versuch, den Fortschritt eines Index-Backfills zu prüfen, gegenüberstehen könnten. Anweisungen zur Indexerstellung, die einen Index-Backfill erfordern, sind Teil von Schemaaktualisierungsvorgängen. Es können mehrere Anweisungen vorhanden sein, die Teil eines Schemaaktualisierungsvorgangs sind.
Das erste Szenario ist das einfachste, nämlich wenn die Anweisung zur Indexerstellung die erste Anweisung im Schemaaktualisierungsvorgang ist. Da die Anweisung zur Indexerstellung die erste Anweisung ist, wird sie aufgrund der Ausführungsreihenfolge als erstes verarbeitet und ausgeführt.
Das Feld startTime der Anweisung zur Indexerstellung wird sofort mit der Startzeit des Schemaaktualisierungsvorgangs ausgefüllt. Als Nächstes wird das Feld progressPercent der Anweisung zur Indexerstellung ausgefüllt, wenn der Fortschritt des Index-Backfills über 0 % liegt. Das Feld endTime wird ausgefüllt, sobald die Anweisung mit Commit ausgeführt wurde.
Das zweite Szenario ist, wenn die Anweisung zur Indexerstellung nicht die erste Anweisung im Schemaaktualisierungsvorgang ist. Aufgrund der Ausführungsreihenfolge werden keine Felder im Zusammenhang mit der Anweisung zur Indexerstellung ausgefüllt, bis die vorherigen Anweisungen mit Commit ausgeführt wurden.
Ähnlich wie im vorherigen Szenario wird nach dem Commit der vorherigen Anweisungen zuerst das Feld startTime der Anweisung zur Indexerstellung und dann das Feld progressPercent ausgefüllt. Das Feld endTime wird erst ausgefüllt, wenn die Anweisung abgeschlossen ist.
Indexerstellung abbrechen
Sie können die Google Cloud CLI verwenden, um die Indexerstellung abzubrechen. Zum Abrufen einer Liste von Schemaaktualisierungsvorgängen für eine Spanner-Datenbank verwenden Sie den Befehl gcloud spanner operations list und fügen die Option --filter ein:
gcloud spanner operations list \
--instance=INSTANCE \
--database=DATABASE \
--filter="@TYPE:UpdateDatabaseDdlMetadata"
Suchen Sie nach der OPERATION_ID des Vorgangs, den Sie abbrechen möchten, und brechen Sie ihn mit dem Befehl gcloud spanner operations cancel ab:
gcloud spanner operations cancel OPERATION_ID \
--instance=INSTANCE \
--database=DATABASE
Vorhandene Indexe ansehen
Um Informationen zu vorhandenen Indexen in einer Datenbank aufzurufen, können Sie dieGoogle Cloud -Konsole oder die Google Cloud CLI verwenden:
Console
Rufen Sie in der Google Cloud Console die Seite Spanner-Instanzen auf.
Klicken Sie auf den Namen der Instanz, die Sie aufrufen möchten.
Klicken Sie im linken Bereich auf die Datenbank, die Sie sich ansehen möchten, und klicken Sie dann auf die Tabelle, die Sie aufrufen möchten.
Klicken Sie auf den Tab Indexe. In der Google Cloud -Console wird eine Liste der Indexe angezeigt.
Optional: Klicken Sie auf den Namen eines Index, um Details zu diesem zu erhalten, z. B. die Spalten, die er enthält.
gcloud
Führen Sie den Befehl gcloud spanner databases ddl describe aus:
gcloud spanner databases ddl describe DATABASE \
--instance=INSTANCE
Die gcloud CLI gibt die DDL-Anweisungen (Data Definition Language – Datendefinitionssprache) zum Erstellen der Tabellen und Indexe der Datenbank aus. Die CREATE
INDEX-Anweisungen beschreiben die vorhandenen Indexe. Beispiel:
--- |-
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY(SingerId)
---
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName)
Abfrage mit einem bestimmten Index
In den folgenden Abschnitten wird erläutert, wie Sie einen Index in einer SQL-Anweisung und mit der Leseschnittstelle für Spanner angeben. In den Beispielen in diesen Abschnitten wird davon ausgegangen, dass Sie der Tabelle Albums eine Spalte MarketingBudget hinzugefügt und einen Index mit dem Namen AlbumsByAlbumTitle erstellt haben:
GoogleSQL
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64,
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
PostgreSQL
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR,
MarketingBudget BIGINT,
PRIMARY KEY (SingerId, AlbumId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Index in einer SQL-Anweisung angeben
Wenn Sie eine Spanner-Tabelle mit SQL abfragen, verwendet Spanner automatisch alle Indexe, die die Effizienz der Abfrage wahrscheinlich erhöhen. Daher müssen Sie für SQL-Abfragen keinen Index angeben. Bei Abfragen, die für Ihre Arbeitslast entscheidend sind, empfiehlt Google jedoch, FORCE_INDEX-Anweisungen in Ihren SQL-Anweisungen zu verwenden, um eine konsistentere Leistung zu erzielen.
In einigen Fällen wählt Spanner unter Umständen einen Index aus, mit dem die Latenz der Abfrage zunimmt. Wenn Sie die Schritte zur Fehlerbehebung bei Leistungsabfällen ausgeführt haben und bestätigt haben, dass es sinnvoll ist, die Abfrage mit einem anderen Index zu versuchen, können Sie den Index als Teil Ihrer Abfrage angeben:
Um einen Index in einer SQL-Anweisung anzugeben, verwenden Sie den Hinweis FORCE_INDEX, um eine Indexanweisung bereitzustellen. Indexanweisungen verwenden die folgende Syntax:
GoogleSQL
FROM MyTable@{FORCE_INDEX=MyTableIndex}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
Mit einer Indexanweisung können Sie Spanner auch dazu veranlassen, in der Basistabelle zu suchen, statt einen Index zu verwenden:
GoogleSQL
FROM MyTable@{FORCE_INDEX=_BASE_TABLE}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = _BASE_TABLE */
Mit einer Indexanweisung können Sie Spanner anweisen, einen Index in einer Tabelle mit benannten Schemas zu scannen:
GoogleSQL
FROM MyNamedSchema.MyTable@{FORCE_INDEX="MyNamedSchema.MyTableIndex"}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
Das folgende Beispiel zeigt eine SQL-Abfrage, die einen Index angibt:
GoogleSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums@{FORCE_INDEX=AlbumsByAlbumTitle}
WHERE AlbumTitle >= "Aardvark" AND AlbumTitle < "Goo";
PostgreSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums /*@ FORCE_INDEX = AlbumsByAlbumTitle */
WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo';
Eine Indexanweisung kann den Abfrageprozessor von Spanner zwingen, zusätzliche Spalten zu lesen, die für die Abfrage erforderlich, aber nicht im Index gespeichert sind.
Der Abfrageprozessor ruft diese Spalten ab, indem er den Index und die Basistabelle zusammenfügt. Um diesen zusätzlichen Join zu vermeiden, speichern Sie die zusätzlichen Spalten mit einer STORING-Klausel (GoogleSQL-Dialekt-Datenbanken) oder einer INCLUDE-Klausel (PostgreSQL-Dialekt-Datenbanken) im Index.
Im vorherigen Beispiel wird die Spalte MarketingBudget nicht im Index gespeichert, aber die SQL-Abfrage wählt diese Spalte aus. Deshalb muss Spanner die Spalte MarketingBudget aus der Basistabelle abrufen und mit Daten aus dem Index verknüpfen, ehe er die Abfrageergebnisse zurückgeben kann.
Spanner gibt einen Fehler aus, wenn die Indexanweisung eines der folgenden Probleme aufweist:
- Der Index existiert nicht.
- Der Index befindet sich in einer anderen Basistabelle.
- Der Abfrage fehlt ein erforderlicher
NULL-Filterausdruck für einenNULL_FILTERED-Index.
Die folgenden Beispiele zeigen, wie Abfragen geschrieben und ausgeführt werden, die die Werte von AlbumId, AlbumTitle und MarketingBudget mithilfe des Index AlbumsByAlbumTitle abrufen:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Index in der Leseschnittstelle angeben
Wenn Sie die Leseschnittstelle zu Spanner verwenden und Spanner einen Index verwenden soll, müssen Sie den Index angeben. Die Leseschnittstelle wählt den Index nicht automatisch aus.
Darüber hinaus muss Ihr Index alle Daten enthalten, die in den Abfrageergebnissen angezeigt werden, mit Ausnahme der Spalten, die Teil des Primärschlüssels sind. Diese Einschränkung besteht, weil die Leseschnittstelle keine Joins zwischen dem Index und der Basistabelle unterstützt. Wenn Sie weitere Spalten mit in die Abfrageergebnisse einbeziehen möchten, haben Sie mehrere Möglichkeiten:
- Speichern Sie die zusätzlichen Spalten mit einer
STORING- oderINCLUDE-Klausel im Index. - Machen Sie Ihre Abfrage, ohne die zusätzlichen Spalten einzubeziehen, und senden Sie dann mithilfe der Primärschlüssel eine weitere Abfrage, die die zusätzlichen Spalten liest.
Spanner gibt Werte aus dem Index in aufsteigender Reihenfolge nach Indexschlüssel zurück. Führen Sie die folgenden Schritte aus, um Werte in absteigender Reihenfolge abzurufen:
Kommentieren Sie den Indexschlüssel mit
DESC. Beispiel:CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle DESC);Die Anmerkung
DESCgilt für einen einzelnen Indexschlüssel. Wenn der Index mehr als einen Schlüssel enthält und die Abfrageergebnisse auf Basis aller Schlüssel in absteigender Reihenfolge angezeigt werden sollen, fügen Sie für jeden Schlüssel eineDESC-Anmerkung ein.Wenn der Lesevorgang einen Schlüsselbereich angibt, muss der Schlüsselbereich ebenfalls in absteigender Reihenfolge angegeben werden. Mit anderen Worten: Der Wert des Startschlüssels muss größer sein als der Wert des Endschlüssels.
Das folgende Beispiel veranschaulicht, wie die Werte von AlbumId und AlbumTitle mit dem Index AlbumsByAlbumTitle abgerufen werden:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Index für Scans nur mit Index erstellen
Optional können Sie mit der Klausel STORING (für GoogleSQL-Dialektdatenbanken) oder INCLUDE (für PostgreSQL-Dialektdatenbanken) eine Kopie einer Spalte im Index speichern. Dieser Indextyp bietet Vorteile für Abfragen und Leseaufrufe unter Verwendung des Index, allerdings beansprucht das zusätzliche Speicherkapazität:
- SQL-Abfragen, die den Index verwenden und in der
STORING- oderINCLUDE-Klausel gespeicherte Spalten auswählen, benötigen keine zusätzliche Verknüpfung mit der Basistabelle. read()-Aufrufe, die den Index verwenden, können Spalten lesen, die durch dieSTORING-/INCLUDE-Klausel gespeichert wurden.
Beispiel: Sie haben eine alternative Version von AlbumsByAlbumTitle erstellt, die eine Kopie der Spalte MarketingBudget im Index speichert. (Beachten Sie die STORING- oder INCLUDE-Klausel in Fettschrift.)
GoogleSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
PostgreSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) INCLUDE (MarketingBudget);
Beim alten AlbumsByAlbumTitle-Index muss Spanner den Index mit der Basistabelle verknüpfen und dann die Spalte aus der Basistabelle abrufen. Beim neuen Index AlbumsByAlbumTitle2 liest Spanner die Spalte direkt aus dem Index, was effizienter ist.
Wenn Sie statt SQL die Leseschnittstelle verwenden, können Sie mit dem neuen Index AlbumsByAlbumTitle2 auch direkt die Spalte MarketingBudget lesen:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Index ändern
Mit der ALTER INDEX-Anweisung können Sie einem vorhandenen Index zusätzliche Spalten hinzufügen oder Spalten entfernen. Dadurch kann die Spaltenliste, die durch die STORING-Klausel (GoogleSQL-Dialektdatenbanken) oder die INCLUDE-Klausel (PostgreSQL-Dialektdatenbanken) definiert wird, aktualisiert werden, wenn Sie den Index erstellen. Mit dieser Anweisung können Sie dem Indexschlüssel keine Spalten hinzufügen und keine Spalten daraus entfernen. Anstatt beispielsweise einen neuen Index AlbumsByAlbumTitle2 zu erstellen, können Sie mit ALTER INDEX eine Spalte in AlbumsByAlbumTitle einfügen, wie im folgenden Beispiel gezeigt:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle ADD STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle ADD INCLUDE COLUMN MarketingBudget
Wenn Sie einem vorhandenen Index eine neue Spalte hinzufügen, verwendet Spanner einen Backfill-Prozess im Hintergrund. Während des Backfills ist die Spalte im Index nicht lesbar. Daher ist es möglich, dass die erwartete Leistungssteigerung nicht eintritt. Mit dem Befehl gcloud spanner operations können Sie den Vorgang mit langer Ausführungszeit auflisten und seinen Status ansehen.
Weitere Informationen finden Sie unter describe operation.
Sie können auch Vorgang abbrechen verwenden, um einen laufenden Vorgang abzubrechen.
Nachdem das Backfill abgeschlossen ist, fügt Spanner die Spalte in den Index ein. Wenn der Index größer wird, kann dies die Abfragen verlangsamen, die den Index verwenden.
Im folgenden Beispiel wird gezeigt, wie eine Spalte aus einem Index entfernt wird:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle DROP STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle DROP INCLUDE COLUMN MarketingBudget
Index von NULL-Werten
NULL-Werte werden von Spanner standardmäßig indexiert. Erinnern Sie sich beispielsweise an die Definition des Index SingersByFirstLastName in der Tabelle Singers:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Alle Zeilen von Singers werden auch dann indexiert, wenn FirstName oder LastName oder beide NULL sind.

Wenn NULL-Werte indexiert werden, können Sie auf Daten, die NULL-Werte enthalten, effiziente SQL-Abfragen und Leseaufrufe durchführen. Verwenden Sie beispielsweise diese SQL-Abfrageanweisung, um alle Singers mit einem NULL FirstName zu finden:
GoogleSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastName} AS s
WHERE s.FirstName IS NULL;
PostgreSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers /* @ FORCE_INDEX = SingersByFirstLastName */ AS s
WHERE s.FirstName IS NULL;
Sortierreihenfolge für NULL-Werte
Spanner sortiert NULL als kleinsten Wert für den jeweiligen Typ ein. Bei einer Spalte in aufsteigender (ASC) Reihenfolge werden NULL-Werte als Erstes einsortiert. Bei einer Spalte in absteigender (DESC) Reihenfolge werden NULL-Werte als Letztes einsortiert.
Indexierung von NULL-Werten deaktivieren
GoogleSQL
Um die Indexierung von Null-Werten zu deaktivieren, fügen Sie das Schlüsselwort NULL_FILTERED zur Indexdefinition hinzu. NULL_FILTERED-Indexe sind besonders nützlich, wenn es um die Indexierung von dünnbesetzten Spalten geht, bei denen die meisten Zeilen einen NULL-Wert enthalten. In diesen Fällen kann der NULL_FILTERED-Index erheblich kleiner und effizienter zu pflegen sein als ein normaler Index, der NULL-Werte enthält.
Hier eine alternative Definition von SingersByFirstLastName, die keine NULL-Werte indexiert:
CREATE NULL_FILTERED INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName);
Das Keyword NULL_FILTERED gilt für alle Indexschlüsselspalten. Eine NULL-Filterung kann nicht pro Spalte angegeben werden.
PostgreSQL
Wenn Sie Zeilen mit Nullwerten in einer oder mehreren indexierten Spalten herausfiltern möchten, verwenden Sie das Prädikat WHERE COLUMN IS NOT NULL.
Null-gefilterte Indexe sind besonders nützlich, wenn es um die Indexierung von dünnbesetzten Spalten geht, bei denen die meisten Zeilen einen NULL-Wert enthalten. In diesen Fällen kann der Index mit Nullfilter erheblich kleiner und effizienter zu pflegen sein als ein normaler Index, der NULL-Werte enthält.
Hier eine alternative Definition von SingersByFirstLastName, die keine NULL-Werte indexiert:
CREATE INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName)
WHERE FirstName IS NOT NULL
AND LastName IS NOT NULL;
Wenn Sie NULL-Werte herausfiltern, kann Spanner sie für einige Abfragen nicht verwenden. Cloud Spanner verwendet den Index beispielsweise nicht für diese Abfrage, da der Index keine Singers-Zeilen enthält, für die LastName NULL ist. Daher würde die Verwendung des Index verhindern, dass die Abfrage die richtigen Zeilen zurückgibt:
GoogleSQL
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = "John";
PostgreSQL
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John';
Damit Spanner den Index verwenden kann, müssen Sie die Abfrage so umschreiben, dass sie dieselben Zeilen ausschließt, die ebenfalls aus dem Index ausgeschlossen sind:
GoogleSQL
SELECT FirstName, LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = 'John' AND LastName IS NOT NULL;
PostgreSQL
SELECT FirstName, LastName
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John' AND LastName IS NOT NULL;
Index-Protofelder
Verwenden Sie generierte Spalten, um Felder in Protocol Buffers zu indexieren, die in PROTO-Spalten gespeichert sind, sofern die zu indexierenden Felder die primitiven oder ENUM-Datentypen verwenden.
Wenn Sie einen Index für ein Protokollnachrichtenfeld definieren, können Sie dieses Feld nicht mehr ändern oder aus dem Protokollschema entfernen. Weitere Informationen finden Sie unter Aktualisierungen von Schemas, die einen Index für Proto-Felder enthalten.
Das Folgende ist ein Beispiel für die Tabelle Singers mit einer SingerInfo-Protokollnachrichtenspalte. Wenn Sie einen Index für das Feld nationality der PROTO definieren möchten, müssen Sie eine gespeicherte generierte Spalte erstellen:
GoogleSQL
CREATE PROTO BUNDLE (googlesql.example.SingerInfo, googlesql.example.SingerInfo.Residence);
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
...
SingerInfo googlesql.example.SingerInfo,
SingerNationality STRING(MAX) AS (SingerInfo.nationality) STORED
) PRIMARY KEY (SingerId);
Er hat die folgende Definition des googlesql.example.SingerInfo-Prototyps:
GoogleSQL
package googlesql.example;
message SingerInfo {
optional string nationality = 1;
repeated Residence residence = 2;
message Residence {
required int64 start_year = 1;
optional int64 end_year = 2;
optional string city = 3;
optional string country = 4;
}
}
Definieren Sie dann einen Index für das Feld nationality des Protos:
GoogleSQL
CREATE INDEX SingersByNationality ON Singers(SingerNationality);
Mit der folgenden SQL-Abfrage werden Daten mit dem vorherigen Index gelesen:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers AS s
WHERE s.SingerNationality = "English";
Hinweise:
- Verwenden Sie eine Indexanweisung, um auf Indexe für die Felder von Protocol Buffer-Spalten zuzugreifen.
- Sie können keinen Index für wiederholte Protokollpufferfelder erstellen.
Aktualisierungen von Schemas, die einen Index für Proto-Felder enthalten
Wenn Sie einen Index für ein Protokollnachrichtenfeld definieren, können Sie dieses Feld nicht mehr ändern oder aus dem Protokollschema entfernen. Das liegt daran, dass nach der Definition des Index jedes Mal eine Typüberprüfung durchgeführt wird, wenn das Schema aktualisiert wird. Spanner erfasst die Typinformationen für alle Felder im Pfad, die in der Indexdefinition verwendet werden.
Eindeutige Indexe
Indexe können als UNIQUE deklariert werden. UNIQUE-Indexe fügen den indexierten Daten eine Einschränkung hinzu, die doppelte Einträge für einen bestimmten Indexschlüssel verbietet.
Diese Einschränkung wird von Spanner zum Zeitpunkt des Transaktions-Commit erzwungen.
Genauer gesagt kann eine Transaktion, die dazu führen würde, dass mehrere Indexeinträge für denselben Schlüssel existieren, nicht ausgeführt werden.
Wenn eine Tabelle anfänglich keine UNIQUE-Daten enthält, schlägt der Versuch fehl, einen UNIQUE-Index zu erstellen.
Ein Hinweis zu UNIQUE NULL_FILTERED-Indexen
Ein UNIQUE NULL_FILTERED-Index erzwingt keine Eindeutigkeit des Indexschlüssels, wenn mindestens eine der Schlüsselkomponenten des Index NULL ist.
Angenommen, Sie haben die folgende Tabelle und den folgenden Index erstellt:
GoogleSQL
CREATE TABLE ExampleTable (
Key1 INT64 NOT NULL,
Key2 INT64,
Key3 INT64,
Col1 INT64,
) PRIMARY KEY (Key1, Key2, Key3);
CREATE UNIQUE NULL_FILTERED INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1);
PostgreSQL
CREATE TABLE ExampleTable (
Key1 BIGINT NOT NULL,
Key2 BIGINT,
Key3 BIGINT,
Col1 BIGINT,
PRIMARY KEY (Key1, Key2, Key3)
);
CREATE UNIQUE INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1)
WHERE Key1 IS NOT NULL
AND Key2 IS NOT NULL
AND Col1 IS NOT NULL;
Die folgenden zwei Zeilen in ExampleTable weisen die gleichen Werte für die Sekundärindexschlüssel Key1, Key2 und Col1 auf:
1, NULL, 1, 1
1, NULL, 2, 1
Da Key2 NULL ist und der Index nach Nullwerten gefiltert wird, sind die Zeilen nicht im Index ExampleIndex vorhanden. Da sie nicht in den Index eingefügt werden, wird der Index sie nicht für den Verstoß gegen die Eindeutigkeit von (Key1, Key2,
Col1) abweisen.
Wenn der Index die Eindeutigkeit von Werten des Tupels (Key1, Key2, Col1) erzwingen soll, müssen Sie Key2 in der Tabellendefinition mit NOT NULL kommentieren oder den Index ohne Filtern von Nullwerten erstellen.
Index löschen
Mit der Anweisung DROP INDEX entfernen Sie einen sekundären Index aus Ihrem Schema.
So löschen Sie den Index mit dem Namen SingersByFirstLastName:
DROP INDEX SingersByFirstLastName;
Index für schnelleres Scannen
Wenn Spanner einen Tabellenscan (und nicht eine indexierte Suche) ausführen muss, um Werte aus einer oder mehreren Spalten abzurufen, können Sie schnellere Ergebnisse erhalten, wenn ein Index für diese Spalten in der von der Abfrage angegebenen Reihenfolge vorhanden ist. Wenn Sie häufig Abfragen ausführen, für die Scans erforderlich sind, sollten Sie sekundäre Indexe erstellen, um diese Scans effizienter zu gestalten.
Wenn Spanner häufig den Primärschlüssel oder einen anderen Index einer Tabelle in umgekehrter Reihenfolge scannen muss, können Sie die Effizienz durch einen sekundären Index steigern, der die gewählte Reihenfolge explizit macht.
Die folgende Abfrage gibt beispielsweise immer ein schnelles Ergebnis zurück, obwohl Spanner Songs scannen muss, um den niedrigsten Wert von SongId zu finden:
SELECT SongId FROM Songs LIMIT 1;
SongId ist der Primärschlüssel der Tabelle, der (wie alle Primärschlüssel) in aufsteigender Reihenfolge gespeichert ist. Spanner kann den Index dieses Schlüssels scannen und das erste Ergebnis schnell finden.
Ohne einen sekundären Index würde die folgende Abfrage jedoch nicht so schnell zurückgegeben werden, insbesondere wenn Songs viele Daten enthält:
SELECT SongId FROM Songs ORDER BY SongId DESC LIMIT 1;
Obwohl SongId der Primärschlüssel der Tabelle ist, kann Spanner den höchsten Wert der Spalte nur durch einen vollständigen Tabellenscan abrufen.
Durch Hinzufügen des folgenden Index könnte diese Abfrage schneller Ergebnisse zurückgeben:
CREATE INDEX SongIdDesc On Songs(SongId DESC);
Mit diesem Index würde Spanner ihn verwenden, um viel schneller ein Ergebnis für die zweite Abfrage zurückzugeben.
Nächste Schritte
- Weitere Informationen zu SQL-Best-Practices für Spanner
- Abfrageausführungspläne für Spanner
- Weitere Informationen zur Fehlerbehebung bei Leistungsregressionen in SQL-Abfragen