Cet article explique comment migrer votre base de données OLTP (OnLine Transactional Processing) Oracle® vers Spanner.
Spanner utilise certains concepts différemment des autres outils de gestion de base de données d'entreprise. Par conséquent, vous devrez peut-être ajuster votre application pour tirer pleinement parti de ses fonctionnalités. Vous devrez peut-être également compléter Spanner avec d'autres services de Google Cloud pour répondre à vos besoins.
Contraintes de migration
Lorsque vous migrez votre application vers Spanner, vous devez prendre en compte les différentes fonctionnalités disponibles. Il sera probablement nécessaire de revoir l'architecture de votre application pour l'adapter à l'ensemble des fonctionnalités de Spanner et pour l'intégrer à d'autres services Google Cloud .
Procédures et déclencheurs stockés
Spanner n'est pas compatible avec l'exécution de code utilisateur au niveau de la base de données. Par conséquent, dans le cadre de la migration, vous devez déplacer dans l'application la logique métier mise en œuvre par les procédures et les déclencheurs stockés au niveau de la base de données.
Séquences
Nous vous recommandons d'utiliser la version 4 de l'UUID comme méthode par défaut pour générer des valeurs de clé primaire.
La fonction GENERATE_UUID() (GoogleSQL, PostgreSQL) renvoie des valeurs UUID de version 4 sous forme de type STRING.
Si vous devez générer des valeurs entières sur 64 bits, Spanner accepte les séquences inversées positives (GoogleSQL, PostgreSQL), qui produisent des valeurs réparties de manière uniforme dans l'espace de nombres positifs sur 64 bits. Vous pouvez utiliser ces chiffres pour éviter les problèmes de hotspotting.
Pour en savoir plus, consultez Stratégies de valeur par défaut de clé primaire.
Contrôle des accès
Identity and Access Management (IAM) vous permet de contrôler l'accès des utilisateurs et des groupes aux ressources Spanner au niveau du projet, ainsi qu'à ceux de l'instance et de la base de données Spanner. Pour en savoir plus, consultez la présentation d'IAM.
Examinez et implémentez les stratégies IAM en suivant le principe du moindre privilège pour tous les utilisateurs et comptes de service qui accèdent à votre base de données. Si l'application nécessite un accès restreint à des tables, des colonnes, des vues ou des flux de modifications spécifiques, implémentez un contrôle précis des accès (FGAC). Pour en savoir plus, consultez la présentation du contrôle des accès ultraprécis.
Contraintes de validation des données
Spanner n'accepte qu'un ensemble limité de contraintes de validation des données dans la couche de base de données.
Si vous avez besoin de contraintes de données plus complexes, mettez-les en œuvre dans la couche d'application.
Le tableau suivant décrit les types de contraintes fréquemment rencontrés dans les bases de données Oracle® et explique comment les mettre en œuvre avec Spanner.
| Contrainte | Mise en œuvre avec Spanner |
|---|---|
| Non nul | Contrainte de colonne NOT NULL |
| Unique | Index secondaire avec contrainte UNIQUE |
| Clé étrangère (pour les tables normales) | Consultez la page Créer et gérer des relations avec des clés étrangères. |
Actions ON DELETE/ON UPDATE de la clé étrangère |
Possible uniquement pour les tables entrelacées, sinon, mis en œuvre dans la couche d'application |
Vérification de la valeur et validation par le biais de contraintes ou de déclencheurs CHECK
|
Mis en œuvre dans la couche d'application |
Types de données acceptés
Les bases de données Oracle® et Spanner acceptent différents ensembles de types de données. Le tableau ci-dessous répertorie les types de données Oracle et leur équivalent dans Spanner. Pour obtenir des définitions détaillées de chaque type de données Spanner, consultez la page Types de données.
Vous devrez peut-être également effectuer des transformations supplémentaires sur vos données, comme indiqué dans la colonne "Remarques", pour que les données Oracle puissent s'intégrer dans votre base de données Spanner.
Par exemple, vous pouvez stocker un BLOB volumineux en tant qu'objet dans un bucket Cloud Storage plutôt que dans la base de données, puis stocker la référence URI de l'objet Cloud Storage dans la base de données sous forme de STRING.
| Type de donnée Oracle | Équivalent dans Spanner | Notes |
|---|---|---|
Types caractères (CHAR, VARCHAR, NCHAR, NVARCHAR) |
STRING
|
Remarque : Spanner utilise des chaînes Unicode. Oracle accepte une longueur maximale de 32 000 octets ou caractères (selon le type), tandis que Spanner accepte jusqu'à 2 621 440 caractères. |
BLOB, LONG RAW, BFILE |
BYTES ou STRING contenant l'URI de l'objet.
|
Les petits objets (moins de 10 Mio) peuvent être stockés sous forme de BYTES.Pensez à utiliser des offres Google Cloud alternatives, telles que Cloud Storage, pour stocker des objets plus volumineux. |
CLOB, NCLOB, LONG
|
STRING (contenant des données ou un URI vers un objet externe)
|
Les petits objets (moins de 2 621 440 caractères) peuvent être stockés sous forme de STRING. Pensez à utiliser des offres Google Cloud alternatives, telles que Cloud Storage, pour stocker des objets plus volumineux.
|
NUMBER, NUMERIC, DECIMAL
|
STRING, FLOAT64, INT64
|
Le type de données Oracle NUMBER est équivalent au type de données GoogleSQL NUMERIC. Chacun accepte 38 chiffres de précision et neuf chiffres d'échelle : (P,S) = (38,9). Le type de données PostgreSQL NUMERIC stocke des données numériques de précision arbitraire.
Le type de données GoogleSQL FLOAT64 accepte jusqu'à 16 chiffres de précision. |
INT, INTEGER, SMALLINT
|
INT64
|
|
BINARY_FLOAT BINARY_DOUBLE |
FLOAT64
|
|
DATE
|
DATE
|
La représentation STRING par défaut du type DATE de Spanner est yyyy-mm-dd, ce qui est différent de celle d'Oracle. Par conséquent, soyez prudent lorsque vous convertissez automatiquement depuis et vers des représentations de dates de type STRING. Les fonctions SQL sont fournies pour convertir les dates en une chaîne formatée.
|
DATETIME
|
TIMESTAMP
|
Spanner stocke l'heure indépendamment du fuseau horaire. Si vous devez stocker un fuseau horaire, vous devez utiliser une colonne STRING distincte.
Les fonctions SQL permettent de convertir les horodatages en chaînes de caractères formatées utilisant les fuseaux horaires.
|
XML
|
STRING (contenant des données ou un URI pour un objet externe)
|
Les petits objets XML (moins de 2 621 440 caractères) peuvent être stockés sous forme de STRING. Pensez à utiliser des offres Google Cloud alternatives, telles que Cloud Storage, pour stocker des objets plus volumineux. |
URI, DBURI, XDBURI, HTTPURI |
STRING
|
|
ROWID
|
PRIMARY KEY
|
Spanner utilise la clé primaire de la table pour trier et référencer les lignes en interne. Par conséquent, dans Spanner, ce type est identique au type de donnée ROWID. |
SDO_GEOMETRY SDO_TOPO_GEOMETRY_SDO_GEORASTER |
Spanner n'accepte pas les données de type géospatial. Vous devez stocker ces données à l'aide de types de données standards et mettre en œuvre une logique de recherche et filtrage dans la couche d'application. | |
ORDAudio, ORDDicom, ORDDoc,
ORDImage, ORDVideo, ORDImageSignature
|
Spanner n'accepte pas les données de type multimédia. Pensez à utiliser Cloud Storage pour stocker les données multimédias. |
Processus de migration
La chronologie générale de votre processus de migration peut se décomposer ainsi :
- Convertissez votre schéma et votre modèle de données.
- Traduisez les requêtes SQL.
- Migrez votre application pour utiliser Spanner en plus d'Oracle.
- Exportez vos données de manière groupée à partir d'Oracle et importez-les dans Spanner à l'aide de Dataflow.
- Maintenez la cohérence entre les deux bases de données lors de votre migration.
- Migrez votre application hors d'Oracle.
Étape 1 : Convertissez votre base de données et votre schéma
Convertissez votre schéma existant en un schéma Spanner pour stocker vos données. Il doit correspondre au schéma Oracle existant aussi fidèlement que possible pour simplifier les modifications d'application. Cependant, en raison des différences de fonctionnalités, certaines modifications seront indispensables.
L'utilisation des bonnes pratiques de conception de schéma peut vous permettre d'augmenter le débit et de réduire les hotspots dans votre base de données Spanner.
Clés primaires
Dans Spanner, toute table devant stocker plus d'une ligne doit avoir une clé primaire composée d'une ou de plusieurs colonnes de la table. La clé primaire de votre table identifie de manière unique chaque ligne de la table, et les lignes de la table sont triées par clé primaire. Spanner étant hautement distribué, il est important de choisir une technique de génération de clés primaires qui s'adapte bien à la croissance de vos données. Pour en savoir plus, consultez les stratégies de migration des clés primaires recommandées.
Notez qu'une fois que vous avez désigné une clé primaire, vous ne pouvez plus ajouter ni supprimer de colonne de clé primaire, ni modifier la valeur d'une clé primaire ultérieurement sans supprimer et recréer la table. Pour en savoir plus sur la manière de désigner votre clé primaire, consultez Schéma et modèle de données – clés primaires.
Entrelacer vos tables
Spanner propose une fonctionnalité dans laquelle vous pouvez définir deux tables comme ayant une relation parent-enfant de type un à plusieurs. Cette fonctionnalité entrelace les lignes de données enfants avec leur ligne parente dans le stockage. L'entrelacement signifie que les tables sont pré-jointes, ce qui permet d'améliorer l'efficacité de la récupération des données lorsque le parent et les enfants sont recherchés ensemble.
La clé primaire de la table enfant doit commencer par la ou les colonnes de clé primaire de la table parente. Du point de vue de la ligne enfant, la clé primaire de la ligne parente est appelée clé étrangère. Vous pouvez définir jusqu'à six niveaux de relations parent-enfant.
Vous pouvez définir des actions lors de la suppression pour les tables enfants afin de déterminer ce qui se passe lorsque la ligne parente est supprimée : soit toutes les lignes enfants sont supprimées, soit la suppression de la ligne parente est bloquée tant qu'il existe des lignes enfants.
Voici un exemple de création d'une table Albums entrelacée dans la table parente Singers définie précédemment :
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
Créer des index secondaires
Vous pouvez également créer des index secondaires pour indexer des données dans la table en dehors de la clé primaire.
Spanner met en œuvre les index secondaires de la même manière que les tables, de sorte que les valeurs de colonne à utiliser comme clés d'index présentent les mêmes contraintes que les clés primaires des tables. Cela signifie également que les index ont la même garantie de cohérence que les tables Spanner.
Les recherches de valeurs utilisant des index secondaires sont en réalité les mêmes que les requêtes avec jointure de table. Vous pouvez améliorer les performances des requêtes utilisant des index en stockant des copies des valeurs de colonnes de la table d'origine dans l'index secondaire à l'aide de la clause STORING, ce qui en fait un index de couverture.
L'optimiseur de requêtes de Spanner n'utilise automatiquement un index secondaire que lorsqu'il stocke lui-même toutes les colonnes interrogées (une requête couverte). Pour forcer l'utilisation d'un index lors de la recherche de colonnes dans la table d'origine, vous devez utiliser une directive FORCE INDEX dans l'instruction SQL, par exemple :
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
Les index peuvent être utilisés pour imposer des valeurs uniques dans une colonne de table en définissant un index UNIQUE sur cette colonne. L'index empêchera l'ajout de valeurs en double.
Voici un exemple d'instruction DDL créant un index secondaire pour la table Albums :
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Si vous créez des index supplémentaires après le chargement de vos données, le remplissage de l'index peut prendre un certain temps. Nous vous recommandons de limiter la fréquence à laquelle vous les ajoutez à une moyenne de trois par jour. Pour obtenir plus de conseils sur la création d'index secondaires, consultez la section Index secondaires. Pour en savoir plus sur les limitations relatives à la création d'index, consultez la section Mises à jour de schémas.
Étape 2 : Traduire les requêtes SQL
Spanner utilise le dialecte SQL ANSI 2011 avec extensions et dispose de nombreux opérateurs et fonctions pour vous permettre de traduire et d'agréger vos données. Toutes les requêtes SQL utilisant une syntaxe, des fonctions et des types spécifiques à Oracle devront être converties pour être compatibles avec Spanner.
Même si Spanner n'accepte pas les données structurées en tant que définitions de colonne, celles-ci peuvent être utilisées dans les requêtes SQL à l'aide des types ARRAY et STRUCT.
Par exemple, vous pouvez écrire une requête unique qui renvoie tous les albums d'un artiste à l'aide d'un ARRAY de STRUCTs (en exploitant les données prédéfinies).
Pour en savoir plus, consultez la section Remarques sur les sous-requêtes de la documentation.
Les requêtes SQL peuvent être profilées à l'aide de la page Spanner Studio de la console Google Cloud pour exécuter la requête. En général, les requêtes qui effectuent des analyses complètes de tables sur des tables volumineuses sont très coûteuses et doivent être utilisées avec parcimonie.
Pour en savoir plus sur l'optimisation des requêtes SQL, consultez la documentation relative aux bonnes pratiques SQL.
Étape 3 : Migrer votre application pour utiliser Spanner
Spanner fournit un ensemble de bibliothèques clientes pour différents langages, ainsi que la possibilité de lire et d'écrire des données en utilisant des appels d'API spécifiques à Spanner ou des requêtes SQL et des instructions LMD (langage de manipulation de données). L'utilisation d'appels d'API peut être plus rapide pour certaines requêtes, telles que les lectures directes de lignes par clé, car il n'est pas nécessaire de traduire l'instruction SQL.
Vous pouvez également utiliser le pilote JDBC (Java DataBase Connectivity) pour vous connecter à Cloud Spanner, en exploitant les outils et l'infrastructure existants dépourvus d'intégration native.
Dans le cadre du processus de migration, les fonctionnalités non disponibles dans Spanner doivent être mises en œuvre dans l'application. Par exemple, un déclencheur permettant de vérifier les valeurs de données et de mettre à jour une table associée devrait être mis en œuvre dans l'application à l'aide d'une transaction de lecture/écriture pour lire la ligne existante, vérifier la contrainte, puis écrire les lignes mises à jour dans les deux tables.
Spanner offre des transactions en lecture/écriture et en lecture seule qui garantissent la cohérence externe de vos données. De plus, les limites d'horodatage peuvent être appliquées aux transactions en lecture si vous lisez une version cohérente des données :
- à une heure exacte dans le passé (jusqu'à il y a une heure) ;
- dans l’avenir (où la lecture bloquera jusqu'au moment indiqué) ;
- avec une limite acceptable d'obsolescence, ce qui retournera une vue cohérente jusqu’à un certain moment sans qu’il soit nécessaire de vérifier que des données ultérieures sont disponibles sur une autre instance dupliquée. Cela peut améliorer les performances au détriment de données éventuellement obsolètes.
Étape 4 : Transférez vos données d'Oracle vers Spanner
Pour transférer vos données d'Oracle vers Spanner, vous devez exporter votre base de données Oracle vers un format de fichier portable (le format CSV par exemple), puis importer ces données dans Spanner à l'aide de Dataflow.
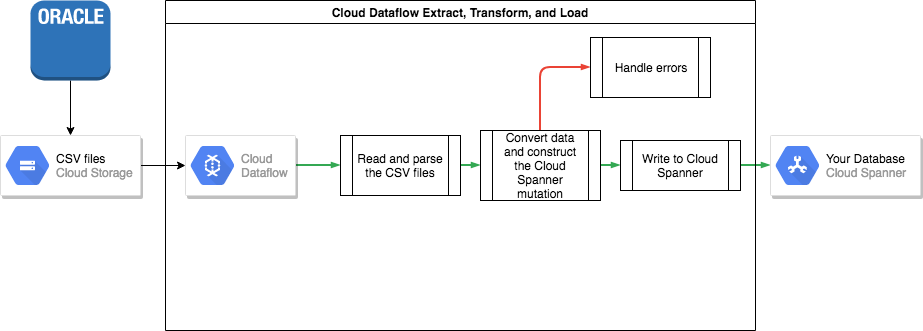
Exporter en masse depuis Oracle
Oracle ne fournit pas d'utilitaire intégré pour exporter ou décharger toute votre base de données dans un format de fichier portable.
Certaines options d'export sont répertoriées dans la section Questions fréquentes sur Oracle.
Y compris :
- Utiliser SQL*plus ou SQLcl pour spouler une requête dans un fichier texte.
- Écrire une fonction PL/SQL en utilisant UTL_FILE pour décharger une table en parallèle de fichiers texte.
- Utiliser des fonctionnalités dans Oracle APEX ou Oracle SQL Developer pour décharger une table dans un fichier CSV ou XML.
Ces options présentent toutes l'inconvénient de ne pouvoir exporter qu'une seule table à la fois, ce qui signifie que vous devez mettre en pause votre application ou suspendre votre base de données afin que son état reste cohérent pour l'exportation.
Parmi les autres options, citons les outils tiers répertoriés dans la page Questions fréquentes sur Oracle, dont certains peuvent décharger une vue cohérente de l'intégralité de la base de données.
Une fois ces fichiers de données déchargés, vous devez les importer dans un bucket Cloud Storage afin qu'ils soient accessibles pour l'importation.
Importer en masse dans Spanner
Étant donné que les schémas de base de données diffèrent probablement entre Oracle et Spanner, vous devrez peut-être inclure des conversions de données dans le processus d'importation.
Le moyen le plus simple d'effectuer ces conversions de données et de les importer dans Spanner consiste à utiliser Dataflow.
Dataflow est le service d'extraction, de transformation et de chargement (ETL, Extract Transform and Load) distribué de Google Cloud . Il fournit une plate-forme pour l'exécution de pipelines de données écrits à l'aide du SDK Apache Beam afin de lire et de traiter de grandes quantités de données en parallèle sur plusieurs machines.
Le SDK Apache Beam nécessite l’écriture d’un programme Java simple permettant de définir la lecture, la transformation et l’écriture des données. Les connecteurs Beam existent pour Cloud Storage et Spanner. Par conséquent, le seul code à écrire est la transformation de données elle-même.
Pour obtenir un exemple de pipeline simple qui lit des fichiers CSV et écrit dans Spanner, consultez l'exemple de dépôt de code associé à cet article.
Si vous utilisez des tables entrelacées parent-enfant dans votre schéma Spanner, veillez, lors du processus d'importation, à ce que la ligne parente soit créée avant la ligne enfant. Le code de pipeline d'importation Spanner résout ce problème en important d'abord toutes les données des tables de niveau racine, puis toutes les tables enfants de niveau 1, puis toutes les tables enfants de niveau 2, etc.
Vous pouvez utiliser le pipeline d'importation Spanner directement pour importer vos données de manière groupée,à condition qu'elles soient stockées dans des fichiers Avro utilisant le schéma approprié.
Étape 5 : Maintenir la cohérence entre les deux bases de données
De nombreuses applications ont des exigences de disponibilité rendant impossible le maintien de l'application hors ligne pendant le temps nécessaire à l'exportation et l'importation des données. Pendant que vous transférez vos données vers Spanner, votre application continue à modifier la base de données existante. Vous devez dupliquer les mises à jour de la base de données Spanner pendant l'exécution de l'application.
Il existe différentes méthodes pour synchroniser vos deux bases de données, comme par exemple la capture de données modifiées et la mise en œuvre de mises à jour simultanées dans l'application.
Capture de données modifiées
Oracle GoldenGate peut fournir un flux de capture de données modifiées (CDC, Change Data Capture) pour votre base de données Oracle. Les interfaces LogMiner et Oracle XStream Out sont des interfaces alternatives permettant à la base de données Oracle d'obtenir un flux CDC n'impliquant pas Oracle GoldenGate.
Vous pouvez écrire une application qui s'abonne à l'un de ces flux et applique les mêmes modifications (après la conversion des données, bien sûr) à votre base de données Spanner. Une telle application du traitement par flux doit mettre en œuvre plusieurs fonctionnalités :
- Connexion à la base de données Oracle (base de données source)
- Connexion à Spanner (base de données cible)
- Effectuer les actions suivantes de manière répétée :
- Recevoir les données générées par l'un des flux CDC de la base de données Oracle
- Interpréter les données générées par le flux CDC
- Convertir les données en instructions
INSERTde Spanner - Exécuter les instructions
INSERTde Spanner
La technologie de migration de bases de données est un middleware qui a mis en œuvre les fonctionnalités requises. La plate-forme de migration de bases de données est installée en tant que composant distinct, soit à l'emplacement source, soit à l'emplacement cible, conformément aux exigences du client. Elle ne nécessite qu'une configuration de la connectivité des bases de données impliquées pour spécifier et démarrer un transfert de données continu de la base de données source vers la base de données cible.
Striim est une plate-forme impliquant une technologie de migration de bases de données, disponible surGoogle Cloud. Cette plate-forme fournit une connectivité aux flux CDC à partir d'Oracle GoldenGate, d'Oracle LogMiner et d'Oracle XStream Out. Striim offre un outil graphique qui vous permet de configurer la connectivité des bases de données ainsi que toutes les règles de transformation nécessaires pour transférer des données d'Oracle vers Spanner.
Vous pouvez installer Striim depuis Google Cloud Marketplace, vous connecter aux bases de données source et cible, mettre en œuvre des règles de transformation et commencer à transférer des données sans devoir créer vous-même une application de traitement par flux.
Mettre à jour les deux bases de données simultanément depuis l'application
Une autre méthode consiste à modifier votre application pour effectuer des écritures dans les deux bases de données. L'une d'entre elles (initialement Oracle) serait considérée comme source fiable. Après chaque écriture dans la base de données, la ligne entière est lue, convertie et écrite dans la base de données Spanner.
De cette manière, l'application remplace en permanence les lignes Spanner par les données les plus à jour.
Lorsque vous êtes sûr que toutes vos données ont été transférées correctement, vous pouvez basculer la source fiable vers la base de données Spanner.
Ce mécanisme permet d'effectuer un rollback si des problèmes sont détectés lors du passage à Spanner.
Vérifier la cohérence des données
Lorsque les données sont diffusées dans votre base de données Spanner, vous pouvez effectuer périodiquement une comparaison entre les données Spanner et les données Oracle pour vous assurer de leur cohérence.
Vous pouvez valider la cohérence en interrogeant les deux sources de données et en comparant les résultats.
Vous pouvez utiliser Cloud Dataflow pour effectuer une comparaison détaillée sur des ensembles de données volumineux à l'aide de la transformation de jointure. Cette transformation prend deux ensembles de données disposant de clés et fait correspondre les valeurs par clé. Les valeurs correspondantes peuvent ensuite être comparées pour vérifier l'égalité.
Vous pouvez effectuer cette vérification régulièrement jusqu'à ce que le niveau de cohérence corresponde à vos besoins.
Étape 6 : Basculer vers Spanner comme source fiable de votre application
Lorsque vous êtes sûr de la migration des données, vous pouvez basculer votre application de sorte qu'elle utilise Spanner comme source fiable. Continuez à écrire les modifications apportées à la base de données Oracle afin que celle-ci reste à jour, laissant une possibilité de retour en arrière en cas de problème.
Enfin, vous pouvez désactiver et supprimer le code de mise à jour de la base de données Oracle et arrêter cette dernière.
Exporter et importer des bases de données Spanner
Vous pouvez éventuellement exporter vos tables de Spanner vers un bucket Cloud Storage à l'aide d'un modèle Dataflow. Le dossier résultant contient un ensemble de fichiers Avro et de fichiers manifestes JSON contenant vos tables exportées. Ces fichiers peuvent avoir divers usages, y compris :
- sauvegarder votre base de données pour la conformité aux règles de conservation des données ou la reprise après sinistre ;
- importer le fichier Avro dans d'autres offres Google Cloud telles que BigQuery.
Pour en savoir plus sur les processus d'exportation et d'importation, consultez les pages Exporter des bases de données et Importer des bases de données.
Étapes suivantes
- Découvrez comment optimiser le schéma Cloud Spanner.
- Découvrez comment utiliser Dataflow dans des situations plus complexes.