Les technologies de stockage de Google alimentent certaines des plus grandes applications mondiales. Cependant, l'utilisation de ces systèmes n'entraîne pas nécessairement une mise à l'échelle. Les concepteurs doivent soigneusement réfléchir à la manière de concevoir leurs données pour que leur application puisse évoluer et fonctionner à mesure qu'elle grandit dans diverses dimensions.
Spanner est une base de données distribuée. Pour l'utiliser efficacement, vous devez penser la conception de schéma et les modèles d'accès différemment de ce que vous auriez fait pour une base de données traditionnelle. Les systèmes distribués, par leur nature, obligent les concepteurs à réfléchir aux données et à la localité du traitement.
Spanner accepte les requêtes SQL et les transactions avec la possibilité d'évoluer horizontalement. Il est souvent nécessaire de porter une attention particulière à la conception afin de tirer pleinement parti des avantages de Spanner. Le présent document présente certaines idées clés qui vous aideront à vous assurer que votre application peut évoluer à tous niveaux et à optimiser ses performances. Deux outils en particulier ont un impact important sur l'évolutivité : la définition de clé et l'entrelacement.
Structure des tables
Les lignes d'une table Spanner sont organisées lexicographiquement par PRIMARY
KEY. D'un point de vue conceptuel, les clés sont triées par la concaténation des colonnes selon l'ordre dans lequel elles sont déclarées dans la clause PRIMARY KEY. Cela présente toutes les propriétés standards de la localité :
- L'analyse de la table dans l'ordre lexicographique est efficace.
- Des lignes suffisamment proches seront stockées dans les mêmes blocs de disque et seront lues et mises en cache ensemble.
Spanner réplique vos données sur plusieurs zones pour des raisons de disponibilité et d'échelle. Chaque zone contient une instance dupliquée complète de vos données. Lorsque vous provisionnez un nœud d'instance Spanner, vous spécifiez sa capacité de calcul. La capacité de calcul correspond à la quantité de ressources de calcul allouées à votre instance dans chacune de ces zones. Bien que chaque instance dupliquée constitue un ensemble complet de vos données, les données contenues dans une instance sont partitionnées entre les ressources de calcul de cette zone.
Les données au sein de chaque instance dupliquée Spanner sont organisées sur deux niveaux de hiérarchie physique: les partitions de la base de données, puis les blocs. Les partitions contiennent des plages de lignes contiguës et constituent l'unité par laquelle Spanner distribue la base de données sur les ressources de calcul. Au fil du temps, les partitions peuvent être divisées en parties plus petites, fusionnées ou déplacées vers d'autres nœuds de votre instance pour accroître le parallélisme et permettre à votre application de s'adapter. Les opérations sont plus coûteuses si elles sont effectuées sur plusieurs partitions plutôt que sur une seule, en raison d'une communication nécessairement plus importante. Cela est également le cas si les partitions sont desservies par le même nœud.
Il existe deux types de tables dans Spanner: les tables racines (parfois appelées tables de niveau supérieur) et les tables entrelacées. Les tables entrelacées sont définies en spécifiant une autre table comme étant leur parent, ce qui entraîne la mise en cluster des lignes de la table entrelacée avec les lignes de la table parente. Les tables racines n'ont pas de parent et chaque ligne d'une table racine définit une nouvelle ligne de niveau supérieur ou une ligne racine. Les lignes entrelacées avec cette ligne racine sont appelées lignes enfants, et l'ensemble constitué d'une ligne racine et de tous ses descendants est appelée une arborescence de ligne. La ligne parent doit exister pour que vous puissiez insérer des lignes enfants. La ligne parent peut soit déjà exister dans la base de données, soit être ajoutée avant l'insertion des lignes enfants dans la même transaction.
Spanner divise automatiquement les partitions lorsqu'il le juge nécessaire en raison de la taille ou de la charge. Pour préserver la localité des données, Spanner préfère ajouter des limites de division aussi proches que des tables racines, afin que toute arborescence de ligne donnée puisse être conservée dans une division unique. Cela signifie que les opérations au sein d'une arborescence de ligne ont tendance à être plus efficaces, car elles sont peu susceptibles de nécessiter une communication avec d'autres partitions.
Toutefois, si une ligne enfant comporte un hotspot, Spanner tente d'ajouter des limites de division aux tables entrelacées afin d'isoler ce hotspot, ainsi que toutes les lignes enfants situées en dessous.
Le choix des tables à utiliser comme tables racines est une décision importante à prendre lors de la conception de l'application afin que celle-ci soit évolutive. Les tables racines sont généralement des éléments comme des utilisateurs, des comptes ou des projets, et leurs tables enfants contiennent la plupart des autres données relatives à l'entité en question.
Recommandations :
- Utilisez un préfixe de clé commun pour les lignes associées dans une même table afin d'améliorer la localité.
- Entrelacez les données connexes dans une autre table chaque fois que cela est pertinent.
Compromis sur la localité
Si les données sont fréquemment écrites ou lues ensemble, il est pertinent en termes de latence et de débit de les regrouper en sélectionnant soigneusement les clés primaires et en utilisant l'entrelacement. En effet, la communication avec un serveur ou un bloc de disque a un coût fixe, alors pourquoi ne pas en profiter au maximum ? En outre, plus le nombre de serveurs avec lesquels vous communiquez est grand, plus vous risquez d'être confronté à un problème de serveur temporairement occupé, ce qui augmente les délais de latence. Enfin, les transactions couvrant plusieurs partitions, bien qu'elles soient automatiques et transparentes dans Spanner, ont un coût en termes de processeur et une latence légèrement plus élevés en raison de la nature distribuée de la validation en deux phases.
Inversement, si les données sont liées mais ne sont pas fréquemment consultées ensemble, envisagez de les séparer. Plus ces données sont volumineuses, plus le bénéfice de cette séparation est important. Par exemple, de nombreuses bases de données stockent un volume important de données binaires hors bande issues des données de la ligne principale, avec uniquement des références au gros volume de données entrelacées.
Notez qu'il est inévitable d'avoir un certain niveau de validation en deux phases et d'opérations sur des données non locales dans une base de données distribuée. Ne cherchez pas trop à atteindre la perfection en termes de localité pour chaque opération. Concentrez-vous sur l'obtention de la localité souhaitée pour les principales entités racines et les modèles d'accès les plus courants, et laissez les opérations distribuées moins fréquentes ou moins sensibles aux performances se produire lorsqu'elles en ont besoin. La validation en deux phases et les lectures distribuées ont pour objectif de simplifier les schémas et de faciliter la tâche aux programmeurs. Il est donc préférable de les laisser dans les cas les plus critiques en termes de performance.
Recommandations :
- Organisez vos données dans des hiérarchies telles que les données lues ou écrites ensemble soient les plus proches possible.
- Envisagez de stocker les colonnes volumineuses dans des tables non entrelacées si elles sont utilisées moins fréquemment.
Options d'index
Les index secondaires vous permettent de rechercher rapidement des lignes en fonction de valeurs autres que la clé primaire. Spanner est compatible avec les index entrelacés et non entrelacés. Les index non entrelacés sont les index par défaut et le type le plus semblable à celui accepté dans un SGBDR traditionnel. Ils n'imposent aucune restriction sur les colonnes indexées et, même s'ils sont performants, ils ne constituent pas toujours le meilleur choix. Les index entrelacés doivent être définis sur des colonnes qui partagent un préfixe avec la table parente et permettent un contrôle accru de la localité.
Spanner stocke les données d'index de la même manière que les tables, avec une ligne par entrée d'index. De nombreuses considérations de conception relatives aux tables s'appliquent également aux index. Les index non entrelacés stockent les données dans des tables racines. Les tables racines pouvant être divisées entre les lignes racines, cela garantit que les index non entrelacés peuvent être ajustés à une taille arbitraire et, en ignorant les points d'accès, à la plupart des charges de travail. Malheureusement, cela signifie également que les entrées d'index ne font généralement pas partie des mêmes partitions que les données primaires. Cela génère un travail et une latence supplémentaires pour les processus d'écriture, et ajoute des partitions à consulter lors de la lecture.
Les index entrelacés, en revanche, stockent les données dans des tables entrelacées. Ils sont appropriés lorsque vous effectuez une recherche dans le domaine d'une seule entité. Les index entrelacés forcent les données et les entrées d'index à rester dans la même arborescence de ligne, ce qui rend les jointures beaucoup plus efficaces. Exemples d'utilisation pour un index entrelacé :
- Accéder à vos photos par divers ordres de tri comme la date de prise de vue, la date de dernière modification, le titre ou l'album.
- Rechercher tous vos messages correspondant à un ensemble de balises donné.
- Rechercher les commandes passées contenant un article spécifique.
Recommandations :
- Utilisez des index non entrelacés lorsque vous devez rechercher des lignes à partir de n'importe quel emplacement de la base de données.
- Préférez les index entrelacés chaque fois que vos recherches concernent une seule entité.
Clause d'indexation STORING
Les index secondaires vous permettent de rechercher des lignes en fonction d'attributs autres que la clé primaire. Si toutes les données demandées se trouvent dans l'index lui-même, il peut être consulté seul sans lire l'enregistrement principal. Cela peut permettre d'économiser d'importantes ressources, puisqu'aucune jointure n'est requise.
Malheureusement, le nombre de clés d'index est limité à 16 et leur taille globale à 8 Kio, ce qui limite leur utilisation. Pour compenser ces limitations, Spanner a la possibilité de stocker des données supplémentaires dans n'importe quel index, via la clause STORING. Utiliser la clause STORING pour une colonne d'un index entraîne la duplication de ses valeurs, avec stockage d'une copie dans l'index. Vous pouvez considérer un index avec STORING comme une simple vue matérialisée à une seule table (les vues ne sont pas compatibles de manière native avec Spanner pour le moment).
La clause STORING est également utile dans le cadre d'un index NULL_FILTERED.
Cela vous permet de définir exactement ce que représente une vue matérialisée d'un sous-ensemble creux d'une table que vous pouvez analyser de manière efficace. Par exemple, vous pourriez créer un tel index dans la colonne is_unread d'une boîte aux lettres pour pouvoir afficher les messages non lus dans une seule analyse de table, mais sans payer pour la copie complète de chaque boîte aux lettres.
Recommandations :
- Soyez prudent lorsque vous utilisez
STORINGpour concilier les performances de temps de lecture avec la taille de stockage et les performances de temps d'écriture. - Utilisez
NULL_FILTEREDpour contrôler les coûts de stockage des index creux.
Anti-modèles
Anti-modèle : ordonner par horodatage
De nombreux concepteurs de schéma envisagent de définir une table racine ordonnée par horodatage et mise à jour à chaque écriture. Malheureusement, il s'agit de l'une des possibilités les moins évolutives. La raison en est que cette conception génère un énorme point chaud à la fin de la table qui ne peut pas être facilement atténué. Au fur et à mesure que les taux d'écriture augmentent, les RPC augmentent également sur une même partition, entraînant une augmentation des conflits liés aux verrous et à d'autres problèmes. Ces types de problèmes n'apparaissent généralement pas lors des tests de faible charge, mais surviennent lorsque l'application est en production depuis un certain temps. Il est alors trop tard !
Si votre application doit absolument inclure un journal ordonné par horodatage, voyez si vous pouvez le rendre local en l'entrelaçant dans l'une de vos autres tables racines. Cela présente l'avantage de répartir le point chaud sur plusieurs racines. Mais vous devez toujours faire attention à ce que chaque racine distincte ait un taux d'écriture suffisamment bas.
Si vous avez besoin d'une table globale (sur plusieurs racines) ordonnée par horodatage, sur laquelle le nombre d'écritures est supérieur à ce qu'un nœud unique peut accepter, utilisez la segmentation au niveau de l'application. Segmenter une table signifie la diviser en un nombre N de parties équivalentes appelées segments. Cela se fait généralement en préfixant la clé primaire d'origine avec une colonne ShardId supplémentaire contenant des valeurs entières comprises entre [0, N). La valeur ShardId pour une écriture donnée est généralement sélectionnée de manière aléatoire ou par hachage d'une partie de la clé de base. Le hachage est souvent privilégié car il permet de s'assurer que tous les enregistrements d'un type donné sont placés dans le même segment, améliorant ainsi les performances de récupération. Dans les deux cas, l'objectif est de s'assurer que, au fil du temps, les écritures sont réparties de manière équitable sur tous les segments.
Cette approche signifie parfois que les lectures doivent analyser tous les segments pour reconstruire l'intégralité de l'ordre d'origine des écritures.
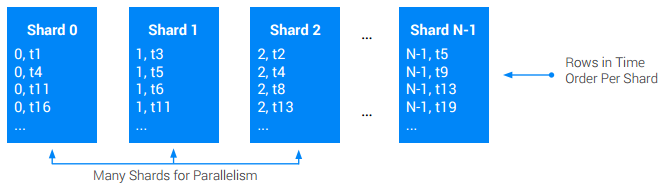
Recommandations :
- Évitez à tout prix les tables et les index à taux d'écriture élevé ordonnés par horodatage.
- Utilisez une technique pour répartir les points chauds, que ce soit par entrelacement dans une autre table ou par segmentation.
Anti-modèle : séquences
Les développeurs d'applications adorent utiliser des séquences de base de données (ou une incrémentation automatique) pour générer des clés primaires. Malheureusement, cette habitude de la période SGBDR (appelée clé de substitution) est presque aussi préjudiciable que l'anti-modèle de l'ordonnancement par horodatage décrit ci-dessus. Cela est dû au fait que les séquences de bases de données ont tendance, au fil du temps, à émettre des valeurs d'une manière quasi monotone pour produire des valeurs regroupées les unes à côté des autres. Cela produit généralement des points chauds lorsqu'elles sont utilisées comme clés primaires, en particulier pour les lignes racines.
Contrairement aux usages en vigueur pour le SGBDR, nous vous recommandons d'utiliser des attributs réels pour les clés primaires chaque fois que cela est utile. Ceci est particulièrement pertinent s'il n'est pas prévu que l'attribut change.
Si vous souhaitez générer des clés primaires numériques uniques, essayez de faire en sorte que les bits de poids fort des nombres qui suivent soient distribués de manière équitable sur tout l'espace de nombres. Une astuce consiste à générer des nombres séquentiels par des moyens conventionnels, puis à inverser les bits pour obtenir une valeur finale. Vous pouvez également consulter un générateur UUID, mais attention : toutes les fonctions UUID ne sont pas créées de manière égale, certaines stockent l'horodatage dans les bits de poids fort, ce qui va à l'encontre des avantages escomptés. Assurez-vous que votre générateur d'UUID choisit des bits de poids fort de manière pseudo-aléatoire.
Recommandations :
- Évitez d'utiliser des valeurs de séquences incrémentales comme clés primaires. Préférez l'inversion des bits d'une valeur de séquence ou utilisez un UUID choisi avec soin.
- Utilisez des valeurs réelles pour les clés primaires plutôt que des clés de substitution.