Neste artigo, explicamos como migrar seu banco de dados de sistemas de processamento de transações on-line (OLTP, na sigla em inglês) Oracle® para o Spanner.
Alguns conceitos do Spanner são diferentes de outras ferramentas de gerenciamento de bancos de dados corporativos, por isso poderá ser necessário ajustar seu aplicativo para aproveitar ao máximo os recursos do Cloud Spanner. Talvez seja necessário complementar o Spanner com outros serviços do Google Cloud para atender às suas necessidades.
Restrições de migração
Ao migrar seu aplicativo para o Spanner, considere os diferentes recursos disponíveis. Provavelmente será necessário reformular a arquitetura do aplicativo para se adequar ao conjunto de recursos do Spanner e fazer a integração com outros serviços do Google Cloud .
Acionadores e procedimentos armazenados
O Spanner não é compatível com a execução de código do usuário no nível do banco de dados. Portanto, como parte da migração, é necessário mover para o aplicativo qualquer lógica de negócios implementada por procedimentos e gatilhos armazenados no nível do banco de dados.
Sequências
Recomendamos usar o UUID versão 4 como o método padrão para gerar valores de chave primária.
A função GENERATE_UUID() (GoogleSQL, PostgreSQL) retorna valores da versão 4 do UUID como um tipo STRING.
Se você precisar gerar valores inteiros de 64 bits, o Spanner vai oferecer suporte a sequências positivas com bits invertidos (GoogleSQL, PostgreSQL), que produzem valores distribuídos uniformemente no espaço de números positivos de 64 bits. Use esses números para evitar problemas de uso excessivo do ponto de acesso.
Para mais informações, consulte estratégias de valor padrão de chave primária.
Controles de acesso
Identity and Access Management (IAM) permite controlar o acesso de usuários e grupos aos recursos do Spanner nos níveis do projeto, da instância e do banco de dados do Spanner. Para mais informações, consulte a Visão geral do IAM.
Revise e implemente políticas do IAM seguindo o princípio de privilégio mínimo para todos os usuários e contas de serviço que acessam seu banco de dados. Se o aplicativo exigir acesso restrito a tabelas, colunas, visualizações ou fluxo de alterações específicos, implemente o controle de acesso refinado (FGAC). Para mais informações, consulte a visão geral do controle de acesso detalhado.
Restrições de validação de dados
O Spanner é compatível com um conjunto limitado de restrições de validação de dados na camada do banco de dados.
Se você precisar de restrições de dados mais complexas, implemente-as na camada do aplicativo.
A tabela a seguir discute os tipos de restrições comumente encontrados nos bancos de dados Oracle® e como implementá-los com o Spanner.
| Restrição | Implementação com o Spanner |
|---|---|
| Não nulo | Restrição de coluna NOT NULL |
| Único | Índice secundário com restrição UNIQUE. |
| Chave estrangeira (para tabelas normais) | Consulte Criar e gerenciar relacionamentos de chave estrangeira. |
Ações ON DELETE/ON UPDATE de chaves estrangeiras |
Possível apenas em tabelas intercaladas. Em outros casos, deve ser implementado na camada do aplicativo. |
Verificações de valor e validação via restrições ou gatilhos CHECK
|
Implementada na camada do aplicativo |
Tipos de dados compatíveis
Oracle e Spanner são compatíveis com diferentes conjuntos de tipos de dados. A tabela a seguir apresenta os tipos de dados da Oracle e seus equivalentes no Spanner. Consulte definições detalhadas de cada tipo de dados do Spanner em Tipos de dados.
Talvez seja necessário realizar transformações adicionais nos dados, conforme descrito na coluna "Observações", para que os dados da Oracle se ajustem ao banco de dados do Spanner.
Por exemplo, é possível armazenar um BLOB grande como objeto em um bucket do Cloud Storage, em vez de armazená-lo no banco de dados, e armazenar a referência do URI do objeto do Cloud Storage no banco de dados como STRING.
| Tipo de dados Oracle | Equivalente do Spanner | Observações |
|---|---|---|
Tipos de caracteres (CHAR, VARCHAR, NCHAR,
NVARCHAR)
|
STRING
|
Observação: o Spanner usa apenas strings Unicode. A Oracle aceita até 32.000 bytes ou caracteres (dependendo do tipo), enquanto o Spanner aceita até 2.621.440 caracteres. |
BLOB, LONG RAW, BFILE
|
BYTES ou STRING contendo o URI do objeto.
|
Objetos pequenos (menos de 10 MiB) podem ser armazenados como BYTES.Considere usar ofertas Google Cloud alternativas, como o Cloud Storage, para armazenar objetos maiores. |
CLOB, NCLOB, LONG
|
STRING (contendo dados ou o URI do objeto externo) |
Objetos pequenos (menos de 2.621.440 caracteres) podem ser armazenados como
STRING. Considere usar ofertas alternativas Google Cloud , como o Cloud Storage, para armazenar objetos maiores.
|
NUMBER, NUMERIC, DECIMAL
|
STRING, FLOAT64, INT64
|
O tipo de dados NUMBER do Oracle é equivalente ao tipo de dados NUMERIC do GoogleSQL. Cada um aceita 38 dígitos de precisão e nove dígitos de escala: (P,S) = (38,9). O tipo de dados NUMERIC do PostgreSQL armazena dados numéricos de precisão arbitrária.
O tipo de dados FLOAT64 do GoogleSQL aceita até 16 dígitos de precisão. |
INT, INTEGER, SMALLINT
|
INT64
|
|
BINARY_FLOAT, BINARY_DOUBLE
|
FLOAT64
|
|
DATE
|
DATE
|
A representação STRING padrão do tipo de dados DATE do Spanner é yyyy-mm-dd. Isso é diferente em bancos de dados Oracle, portanto, tenha cuidado ao converter automaticamente de/para representações de datas em STRING. Oferecemos funções SQL para converter datas em strings formatadas.
|
DATETIME
|
TIMESTAMP
|
O Spanner armazena horários independentemente do fuso horário. Para armazenar um fuso horário é necessários usar uma coluna STRING separada.
Oferecemos funções SQL para converter registros de data e hora em strings formatadas que usam fusos horários.
|
XML
|
STRING (contendo dados ou o URI do objeto externo)
|
Objetos XML pequenos (menos de 2.621.440 caracteres) podem ser armazenados como
STRING. Considere usar ofertas alternativas Google Cloud , como o Cloud Storage, para armazenar objetos maiores. |
URI, DBURI, XDBURI,
HTTPURI
|
STRING
|
|
ROWID
|
PRIMARY KEY
|
O Spanner usa a chave primária da tabela para classificar e referenciar as linhas internamente. Portanto, no Spanner esse chave é efetivamente igual ao tipo de dados ROWID. |
SDO_GEOMETRY, SDO_TOPO_GEOMETRY_SDO_GEORASTER
|
O Spanner não é compatível com tipos de dados geoespaciais. É necessário armazenar esses dados usando tipos de dados padrão e implementar alguma lógica de pesquisa e filtragem na camada do aplicativo. | |
ORDAudio, ORDDicom, ORDDoc,
ORDImage, ORDVideo, ORDImageSignature
|
O Spanner não é compatível com tipos de dados de mídia. Considere usar o Cloud Storage para armazenar dados de mídia. |
Processo de migração
Este é um exemplo do cronograma geral do processo de migração:
- Conversão do esquema e do modelo de dados
- Conversão de consultas SQL
- Migre seu aplicativo para usar o Spanner com o Oracle.
- Exportação em massa dos dados do Oracle e importação no Spanner usando o Dataflow
- Manter a consistência entre os dois bancos de dados durante a migração.
- Migração do aplicativo do Oracle
Etapa 1: converter o banco de dados e o esquema
Converta o esquema atual em um esquema do Spanner para armazenar seus dados. Isso deve fazer a melhor correspondência possível com o esquema Oracle existente, simplificando as modificações no aplicativo. No entanto, devido às diferenças nos recursos, algumas alterações serão necessárias.
Usar as práticas recomendadas do design de esquemas ajuda a aumentar a capacidade e reduzir os gargalos no banco de dados do Spanner.
Chaves primárias
No Spanner, toda tabela que precisa armazenar mais de uma linha precisa ter uma chave primária composta por uma ou mais colunas da tabela. A chave primária da tabela identifica exclusivamente cada linha de uma tabela, e as linhas da tabela são classificadas por chave primária. Como o Spanner é altamente distribuído, é importante escolher uma técnica de geração de chave primária que seja bem escalonada com o crescimento dos dados. Para mais informações, consulte as estratégias de migração de chave primária recomendadas.
Depois de designar a chave primária, não é possível adicionar ou remover uma coluna de chave primária nem mudar um valor de chave primária sem excluir e recriar a tabela. Para mais informações sobre como designar sua chave primária, consulte Esquema e modelo de dados – chaves primárias.
Intercalar as tabelas
Um recurso do Spanner permite definir um relacionamento pai-filho um para muitos entre duas tabelas. Isso intercala as linhas de dados filhas com a linha mãe no armazenamento, efetivamente realizando a mesclagem prévia da tabela e melhorando a eficiência da recuperação de dados quando mãe e filhas são consultadas juntas.
A chave primária da tabela filha precisa começar com as colunas da chave primária da tabela mãe. Da perspectiva da linha filha, a chave primária da linha mãe é chamada de chave estrangeira. Você pode definir até seis níveis de relacionamentos pai-filho.
Você pode definir ações acionadas na exclusão para tabelas filhas, determinando o que acontece quando a linha mãe é excluída: todas as linhas filhas são excluídas ou a exclusão da linha mãe é bloqueada enquanto existem linhas filhas.
Veja um exemplo da criação de uma tabela de álbuns intercalada com a tabela mãe de intérpretes definida anteriormente:
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
Criar índices secundários
Você também pode criar índices secundários para indexar dados da tabela fora da chave primária.
O Spanner implementa índices secundários da mesma forma que as tabelas, então os valores das colunas que serão usados como chaves de índice têm as mesmas restrições das chaves primárias das tabelas. Isso também significa que os índices têm as mesmas garantias de consistência das tabelas do Spanner.
Pesquisas de valor por índices secundários são, na prática, iguais a consultas com uma mesclagem de tabela. Para melhorar o desempenho das consultas que usam índices armazenando cópias dos valores de coluna da tabela original no índice secundário, use a cláusula STORING, o que as transforma em índice abrangente.
O otimizador de consultas do Spanner usará automaticamente os índices secundários somente quando o próprio índice armazenar todas as colunas consultadas (uma consulta coberta). Para forçar o uso de um índice ao consultar colunas na tabela original, é necessário usar uma diretiva FORCE INDEX na instrução SQL. Por exemplo:
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
É possível usar índices para aplicar valores exclusivos em uma coluna da tabela, basta definir um índice UNIQUE nessa coluna. O índice impedirá a inclusão de valores duplicados.
Veja um exemplo de instrução DDL que cria um índice secundário para a tabela de álbuns:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Se você criar mais índices depois de carregar os dados, o preenchimento do índice poderá levar algum tempo. Evite adicionar mais de três por dia. Consulte mais orientações sobre como criar índices secundários em Índices secundários. Para mais informações sobre as limitações na criação de índice, consulte Atualizações de esquema.
Etapa 2: converter consultas SQL
O Spanner usa o dialeto ANSI 2011 do SQL com extensões e tem muitas funções e operadores para ajudar a converter e agregar seus dados. É necessário converter consultas SQL que usam sintaxe, funções e tipos específicos do Oracle para que sejam compatíveis com o Spanner.
Embora o Spanner não aceite dados estruturados como definições de coluna, os dados estruturados podem ser usados em consultas SQL por meio dos tipos ARRAY e STRUCT.
Por exemplo, é possível escrever uma consulta para retornar todos os álbuns de um artista usando um ARRAY de STRUCTs em uma única consulta (aproveitando os dados pré-combinados).
Para mais informações, consulte a seção Observações sobre subconsultas da documentação.
É possível perfilar consultas SQL usando a página do Spanner Studio no Google Cloud Console para executá-las. Em geral, as consultas que realizam varreduras completas em tabelas grandes exigem muitos recursos e devem ser usadas com moderação.
Consulte a documentação de práticas recomendadas de SQL para mais informações sobre como otimizar consultas SQL.
Etapa 3: migrar o aplicativo para usar o Spanner
O Spanner oferece um conjunto de bibliotecas de cliente para várias linguagens e a capacidade de ler e gravar dados usando chamadas de API específicas do Spanner, consultas SQL e instruções da linguagem de manipulação de dados (DML, na sigla em inglês). Algumas consultas podem ser mais rápidas por chamadas de API, como leituras diretas de linha por chave, porque não é necessário converter a instrução SQL.
Você tem a opção de usar o driver Java Database Connectivity (JDBC) para se conectar ao Spanner, aproveitando as ferramentas e a infraestrutura atuais que não têm integração nativa.
Como parte do processo de migração, os recursos não disponíveis no Spanner precisam ser implementados no aplicativo. Por exemplo, um gatilho para verificar valores de dados e atualizar uma tabela relacionada precisaria ser implementado no aplicativo usando uma transação de leitura/gravação para ler a linha atual, verificar a restrição e gravar as linhas atualizadas em ambas as tabelas.
O Spanner oferece transações de leitura e gravação e somente leitura, o que garante a consistência externa de seus dados. Além disso, as transações de leitura podem ter limites de data e hora, assim você lê uma versão consistente dos dados especificados das seguintes formas:
- Em um momento exato no passado (até uma hora atrás).
- No futuro (a leitura será bloqueada até que chegue a hora).
- Com uma quantidade aceitável de inatividade definida, o que retornará uma visualização consistente até algum tempo no passado sem a necessidade de verificar se dados posteriores estão disponíveis em outra réplica. Isso pode aumentar o desempenho, mas pode retornar dados obsoletos.
Etapa 4: transferir os dados do Oracle para o Spanner
Para transferir dados do Oracle para o Spanner, será necessário exportar o banco de dados Oracle para um formato de arquivo portátil, como CSV, e importar esses dados no Spanner usando o Dataflow.
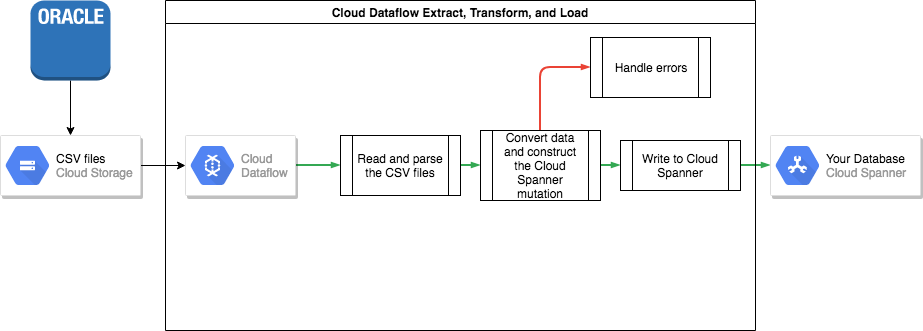
Exportação em massa do Oracle
O Oracle não oferece utilitários integrados para exportar ou descarregar todo o banco de dados em um formato de arquivo portátil.
Algumas opções para exportar estão nas perguntas frequentes sobre o Oracle.
São elas:
- Usar SQL*plus ou SQLcl para fazer spool de uma consulta em um arquivo de texto.
- Escrever uma função PL/SQL usando UTL_FILE para descarregar uma tabela em paralelo a arquivos de texto.
- Usar recursos do Oracle APEX ou Oracle SQL Developer para descarregar uma tabela em um arquivo CSV ou XML.
Cada uma delas tem a desvantagem de exportar apenas uma tabela por vez, o que significa que será necessário pausar seu aplicativo ou desativar o banco de dados para que ele permaneça em um estado consistente para exportação.
Outras opções incluem as ferramentas de terceiros apresentadas na página de perguntas frequentes sobre o Oracle, sendo que algumas podem descarregar uma visualização consistente de todo o banco de dados.
Depois de descarregar, faça o upload dos arquivos de dados para um bucket do Cloud Storage para que possam ser acessados e importados.
Importação em massa para o Spanner
Como os esquemas do banco de dados provavelmente são diferentes entre o Oracle e o Spanner, o processo de importação pode exigir algumas conversões de dados.
A maneira mais fácil de realizá-las e importar os dados para o Spanner é por meio do Dataflow.
O Dataflow é o serviço distribuído de extração, transformação e carregamento (ETL, na sigla em inglês). Google Cloud Ele oferece uma plataforma para executar canais de dados criados com o SDK do Apache Beam, além de ler e processar grandes quantidades de dados em paralelo em várias máquinas.
O SDK do Apache Beam exige a criação de um programa Java simples para definir a leitura, a transformação e a gravação dos dados. Existem conectores do Beam para Cloud Storage e Spanner, portanto, o único código que precisa ser escrito é a própria transformação dos dados.
Veja um exemplo de canal simples que lê arquivos CSV e grava no Spanner no repositório de exemplos de código que acompanha este artigo.
Se as tabelas mães-filhas intercaladas forem usadas no esquema do Spanner, você deverá tomar cuidado durante o processo de importação para que a linha mãe seja criada antes da linha filha. O código do canal de importação do Spanner lida com essa situação ao importar primeiro todos os dados para as tabelas de nível superior, depois todas as tabelas filhas de primeiro nível, todas as tabelas filhas de segundo nível e assim por diante.
O canal de importação do Spanner pode ser usado diretamente para importar seus dados em massa,mas isso exige que os dados estejam em arquivos Avro com o esquema correto.
Etapa 5: manter a consistência entre os dois bancos de dados
Muitos aplicativos têm requisitos de disponibilidade que impossibilitam que fiquem off-line pelo tempo necessário para exportar e importar os dados. Enquanto você está transferindo os dados para o Spanner, seu aplicativo continua modificando o banco de dados existente. É necessário duplicar as atualizações no banco de dados do Spanner enquanto o aplicativo estiver em execução.
Existem vários métodos para manter os dois bancos de dados em sincronia, incluindo o Change Data Capture e a implementação de atualizações simultâneas no aplicativo.
Change Data Capture
O Oracle GoldenGate pode fornecer um fluxo de captura de dados alterados (CDC) para seu banco de dados Oracle. O Oracle LogMiner ou o Oracle XStream Out são interfaces alternativas para que o banco de dados da Oracle receba um stream CDC que não envolva o Oracle GoldenGate.
É possível gravar um aplicativo que se inscreve em um desses streams e que aplica as mesmas modificações (após a conversão de dados, é claro) ao banco de dados do Spanner. Esse aplicativo de processamento de stream precisa implementar vários recursos:
- Como se conectar ao banco de dados Oracle (banco de dados de origem).
- Como se conectar ao Spanner (banco de dados de destino).
- Executar repetidamente o seguinte:
- Receber os dados produzidos por um dos fluxos de CDC do banco de dados Oracle.
- Interpretação dos dados produzidos pelo fluxo do CDC.
- Como converter os dados em instruções
INSERTdo Spanner. - Como executar as instruções
INSERTdo Spanner.
A tecnologia de migração de banco de dados é uma tecnologia de middleware que implementou os recursos necessários como parte de sua funcionalidade. A plataforma de migração de banco de dados é instalada como um componente separado no local de origem ou de destino, de acordo com os requisitos do cliente. A plataforma de migração de banco de dados requer apenas a configuração de conectividade dos bancos de dados envolvidos para especificar e iniciar a transferência contínua de dados da origem para o banco de dados de destino.
O Striim é uma plataforma de tecnologia de migração de banco de dados disponível no Google Cloud. Ela fornece conectividade para streams de CDC do Oracle GoldenGate, assim como do Oracle LogMiner e do Oracle XStream Out. O Striim fornece uma ferramenta gráfica que permite configurar a conectividade do banco de dados e as regras de transformação necessárias para transferir dados do Oracle para o Spanner.
Você pode instalar o Striim a partir do Marketplace do Google Cloud para se conectar aos bancos de dados de origem e de destino, implementar regras de transformação e começar a transferir dados sem precisar criar um aplicativo de processamento de stream.
Atualizações simultâneas no aplicativo em ambos os bancos de dados
Um método alternativo seria o de modificar o aplicativo para executar gravações em ambos os bancos de dados. Um banco de dados (inicialmente Oracle) seria considerado a fonte da verdade e, após cada gravação do banco de dados, a linha inteira seria lida, convertida e gravada no banco de dados do Spanner.
Dessa forma, o aplicativo substitui constantemente as linhas do Spanner pelos dados mais recentes.
Depois de ter certeza de que todos os seus dados foram transferidos corretamente, é possível mudar a lugar confiável para o banco de dados do Spanner.
Com esse mecanismo, você tem um caminho de reversão caso tenha problemas ao mudar para o Spanner.
Verificar a consistência dos dados
À medida que os dados são transmitidos para o banco de dados do Spanner, é possível executar periodicamente uma comparação entre os dados do Spanner e os dados da Oracle para garantir que os dados sejam consistentes.
Você pode validar a consistência consultando as duas fontes de dados e comparando os resultados.
Use o Dataflow para realizar uma comparação detalhada de grandes conjuntos de dados usando a transformação de mesclagem. Essa transformação usa dois conjuntos de dados com chaves e corresponde os valores pelas chaves. Você pode comparar os valores correspondentes por igualdade.
Execute essa verificação regularmente até que o nível de consistência corresponda aos requisitos do seu negócio.
Etapa 6: mudar para o Spanner como a fonte da verdade do aplicativo
Quando você confiar na migração de dados, poderá mudar seu aplicativo para usar o Spanner como lugar confiável. Continue gravando alterações no banco de dados Oracle para mantê-lo atualizado, assim você tem um caminho de reversão em caso de problemas.
Por fim, você poderá desabilitar e remover o código de atualização do banco de dados Oracle e desativar esse banco.
Exportar e importar bancos de dados do Spanner
Como opção, é possível exportar as tabelas do Spanner para um bucket do Cloud Storage usando um modelo do Dataflow para realizar a exportação. A pasta resultante incluirá um conjunto de arquivos Avro e arquivos de manifesto JSON contendo as tabelas exportadas. Esses arquivos podem ter várias funções, como:
- fazer backup do banco de dados para conformidade com a política de retenção de dados ou recuperação de desastres;
- importar o arquivo Avro para outras ofertas do Google Cloud , como o BigQuery.
Para mais informações sobre o processo de exportação e importação, consulte Como exportar bancos de dados e Como importar bancos de dados.
A seguir
- Leia sobre como otimizar seu esquema do Spanner.
- Saiba como usar o Dataflow para situações mais complexas.