本页面介绍如何使用 CPU 利用率指标和图表以及其他内省工具调查数据库中的 CPU 使用率高的情况。
确定是系统任务还是用户任务导致 CPU 使用率高的情况
Google Cloud 控制台为 Spanner 提供了多种监控工具,让您可以查看实例的最重要指标的状态。其中一个是名为 CPU 利用率 - 总计的图表。此图表显示总 CPU 利用率(以实例占用 CPU 资源的百分比表示),按任务优先级和操作类型细分。有两种类型的任务:用户任务(例如读取和写入)和系统任务(包括压缩和索引回填等自动化的后台任务)。
图 1 显示了 CPU 利用率 - 总计图表的示例。
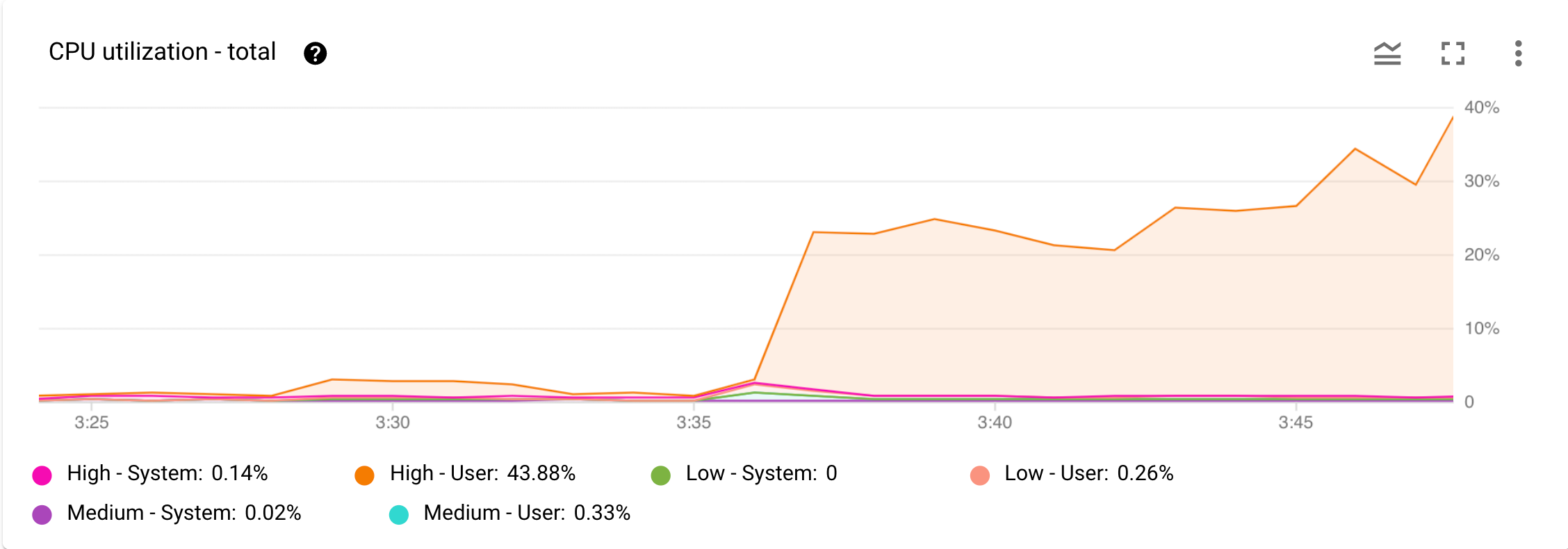
图 1. Google Cloud 控制台的“监控”信息中心内的 CPU 利用率 - 总计图表。
现在,假设您收到一条来自 Cloud Monitoring 的提醒,告诉您 CPU 使用率显著增加。您可以在 Google Cloud 控制台中打开实例的监控信息中心,并在 Cloud 控制台中检查 CPU 利用率 - 总计图表。如图 1 所示,您可以看到高优先级用户任务的 CPU 利用率有所增加。下一步是确定哪些高优先级用户操作导致此 CPU 使用率增加。
您可以使用 Query Insights 信息中心以时序直观呈现此指标和其他指标。这些预构建的信息中心可帮助您查看 CPU 利用率的峰值,并找出低效的查询。
确定哪些用户操作会导致 CPU 利用率高峰
图 1 中的 CPU 利用率 - 总计图表显示高优先级用户任务是导致 CPU 使用率较高的原因。
接下来,您将在 Cloud Console 中检查按操作类型分类的 CPU 利用率图表。此图表按高、中、低优先级用户发起的操作细分 CPU 利用率。
什么是用户发起的操作?
用户发起的操作是通过 API 请求发起的操作。Spanner 将这些请求分组到操作类型或类别中,您可以将每种操作类型显示为 CPU 利用率(按操作类型)图表上的一条线。下表介绍了每种操作类型中包含的 API 方法。
| 操作 | API 方法 | 说明 |
|---|---|---|
| read_readonly | Read StreamingRead |
包括使用键查找和扫描从数据库中获取行的读取操作。 |
| read_readwrite | Read StreamingRead |
包括读写事务内部的读取操作。 |
| read_withpartitiontoken | Read StreamingRead |
包括使用一组分区令牌执行的读取操作。 |
| executesql_select_readonly | ExecuteSql ExecuteStreamingSql |
包括 execute Select SQL 语句和变更数据流查询。 |
| executesql_select_readwrite | ExecuteSql ExecuteStreamingSql |
在读写事务中包含 execute Select 语句。 |
| executesql_select_withpartitiontoken | ExecuteSql ExecuteStreamingSql |
包括使用一组分区令牌执行的 execute Select 语句。 |
| executesql_dml_readwrite | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
包括 execute DML SQL 语句。 |
| executesql_dml_partitioned | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
包括 execute Partitioned DML SQL 语句。 |
| beginorcommit | BeginTransaction Commit Rollback |
包括开始事务、提交事务和回滚事务。 |
| misc | PartitionQuery PartitionRead GetSession CreateSession |
包括分区查询、分区读取、创建数据库、创建实例、会话相关操作、内部时效性服务操作等。 |
下面是一个按操作类型分类的 CPU 利用率指标的图表示例。
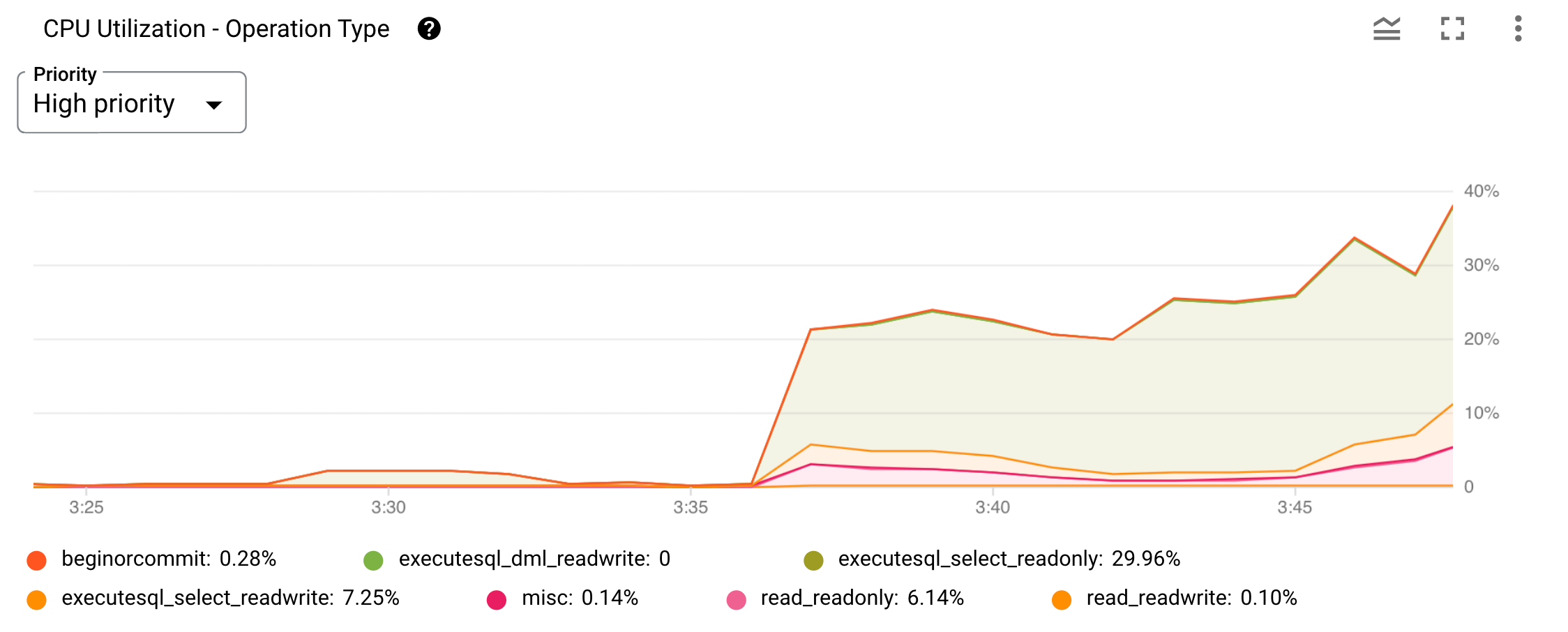
图 2. Google Cloud 控制台中的 CPU 利用率(按操作类型)图表。
您可以使用图表顶部的优先级菜单将显示范围限制为特定优先级。它在折线图上绘制每个操作类型或类别。图表下方列出的类别用于识别每个图表。您可以通过选中或取消选中相应类别的过滤条件来隐藏和显示各图。
或者,您也可以在 Metrics Explorer 中创建此图表,如下所述:
在 Metrics Explorer 中按操作类型创建 CPU 利用率图表
- 在 Google Cloud 控制台中,选择监控,或使用以下按钮:
- 在导航窗格中选择 Metrics Explorer。
- 在 Find resource type and metric(查找资源类型和指标)字段中,输入值
spanner.googleapis.com/instance/cpu/utilization_by_operation_type,然后选择该框下方显示的行。 -
在过滤字段中,输入值
instance_id,然后输入要检查的实例 ID,并点击>应用。 -
在分组依据字段中,从下拉列表中选择
category。该图表将显示按操作类型或类别分组的用户任务的 CPU 利用率。
虽然前面部分中按优先级分类的 CPU 利用率指标有助于确定是用户任务还是系统任务导致 CPU 资源使用率增加,但通过按操作类型分类的 CPU 利用率,您可以深入挖掘并了解这次 CPU 使用率增长背后用户发起的操作类型。
确定哪个用户请求导致 CPU 使用率增加
如需确定哪个特定用户请求会导致在executesql_select_readonly 中看到的 executesql_select_readonly 操作类型图中的 CPU 利用率高峰的情况,您将使用内置的自检统计信息表获取更多数据洞见。
以下表为指导,您可以根据导致高 CPU 使用率的操作类型确定要查询哪些统计信息表。
| 操作类型 | 查询 | 读取 | 事务 |
|---|---|---|---|
| read_readonly | 否 | 是 | 否 |
| read_readwrite | 否 | 是 | 是 |
| read_withpartitiontoken | 否 | 是 | 否 |
| executesql_select_readonly | 是 | 否 | 否 |
| executesql_select_withpartitiontoken | 是 | 否 | 否 |
| executesql_select_readwrite | 是 | 否 | 是 |
| executesql_dml_readwrite | 是 | 否 | 是 |
| executesql_dml_partitioned | 否 | 否 | 是 |
| beginorcommit | 否 | 否 | 是 |
例如,如果 read_withpartitiontoken 存在问题,请使用读取统计信息进行问题排查。
在此场景中,executesql_select_readonly 操作似乎是您观察到的 CPU 使用率增加的原因。根据上表,接下来您应该查看查询统计信息,以找出哪些查询开销大、运行频繁或扫描大量数据。
为了找出前一小时 CPU 使用率最高的查询,您在 query_stats_top_hour 统计表上运行以下查询。
SELECT text,
execution_count AS count,
avg_latency_seconds AS latency,
avg_cpu_seconds AS cpu,
execution_count * avg_cpu_seconds AS total_cpu
FROM spanner_sys.query_stats_top_hour
WHERE interval_end =
(SELECT MAX(interval_end)
FROM spanner_sys.query_stats_top_hour)
ORDER BY total_cpu DESC;
输出将显示按 CPU 使用率排序的查询。确定 CPU 使用率最高的查询后,您可以尝试使用以下方法进行调整。
查看查询执行计划,确定可能导致高 CPU 利用率的任何低效问题。
查看您的查询,确保其符合 SQL 最佳实践。
查看数据库架构设计并更新架构,以使查询更高效。
为 Spanner 在一个时间间隔内执行查询的次数建立基准。借助此基准,您可以检测和调查与正常行为的意外偏差的原因。
如果您找不到 CPU 密集型查询,请向实例添加计算容量。添加计算容量可提供更多 CPU 资源,并使 Spanner 能够处理更大的工作负载。如需了解详情,请参阅增加计算容量。
后续步骤
了解 CPU 利用率指标
了解其他内省工具。
详细了解适用于 Spanner 的 SQL 最佳实践。
参阅来自 Spanner 的指标列表。