En esta página se describe cómo preparar archivos Avro que haya exportado de bases de datos que no sean de Spanner y, a continuación, importarlos a Spanner. Estos procedimientos incluyen información sobre las bases de datos con dialecto GoogleSQL y con dialecto PostgreSQL. Si quieres importar una base de datos de Spanner que hayas exportado anteriormente, consulta Importar archivos Avro de Spanner.
El proceso usa Dataflow e importa datos de un segmento de Cloud Storage que contiene un conjunto de archivos Avro y un archivo de manifiesto JSON que especifica las tablas de destino y los archivos Avro que rellenan cada tabla.
Antes de empezar
Para importar una base de datos de Spanner, primero debes habilitar las APIs de Spanner, Cloud Storage, Compute Engine y Dataflow:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
También necesitas suficiente cuota y los permisos de gestión de identidades y accesos necesarios.
Requisitos de cuota
Los requisitos de cuota para las tareas de importación son los siguientes:
- Spanner: debes tener suficiente capacidad de computación para admitir la cantidad de datos que vas a importar. No se necesita capacidad de computación adicional para importar una base de datos, aunque es posible que tengas que añadir más capacidad de computación para que el trabajo se complete en un tiempo razonable. Para obtener más información, consulta Trabajos de Optimize.
- Cloud Storage: para importar, debes tener un segmento que contenga los archivos que hayas exportado anteriormente. No es necesario que defina un tamaño para el segmento.
- Dataflow: las tareas de importación están sujetas a las mismas cuotas de CPU, uso de disco y dirección IP de Compute Engine que otras tareas de Dataflow.
Compute Engine: antes de ejecutar el trabajo de importación, debes configurar las cuotas iniciales de Compute Engine, que utiliza Dataflow. Estas cuotas representan el número máximo de recursos que permites que Dataflow use en tu trabajo. Los valores iniciales recomendados son los siguientes:
- CPUs: 200
- Direcciones IP en uso: 200
- Disco persistente estándar: 50 TB
Por lo general, no tienes que hacer ningún otro ajuste. Dataflow proporciona autoescalado para que solo pagues por los recursos reales utilizados durante la importación. Si tu trabajo puede usar más recursos, la interfaz de usuario de Dataflow muestra un icono de advertencia. El trabajo debería finalizar aunque haya un icono de advertencia.
Roles obligatorios
Para obtener los permisos que necesitas para exportar una base de datos, pide a tu administrador que te conceda los siguientes roles de gestión de identidades y accesos en la cuenta de servicio de trabajador de Dataflow:
-
Lector de Cloud Spanner (
roles/spanner.viewer) -
Trabajador de Dataflow (
roles/dataflow.worker) -
Administrador de almacenamiento (
roles/storage.admin) -
Lector de las bases de datos de Spanner (
roles/spanner.databaseReader) -
Administrador de bases de datos (
roles/spanner.databaseAdmin)
Exportar datos de una base de datos que no es de Spanner a archivos Avro
El proceso de importación incorpora datos de archivos Avro ubicados en un segmento de Cloud Storage. Puedes exportar datos en formato Avro desde cualquier fuente y usar cualquier método disponible para hacerlo.
Para exportar datos de una base de datos que no usa Spanner a archivos Avro, sigue estos pasos:
Cuando exporte sus datos, tenga en cuenta lo siguiente:
- Puede exportar datos con cualquiera de los tipos primitivos de Avro, así como con el tipo complejo array.
Cada columna de sus archivos Avro debe usar uno de los siguientes tipos de columna:
ARRAYBOOLBYTES*DOUBLEFLOATINTLONG†STRING‡
* Se usa una columna de tipo
BYTESpara importar unNUMERICde Spanner. Consulta la siguiente sección sobre asignaciones recomendadas para obtener más información.†,‡ Puedes importar un
LONGque almacene una marca de tiempo o unSTRINGque almacene una marca de tiempo como unTIMESTAMPde Spanner. Consulta la sección Mapeos recomendados para obtener más información.No tienes que incluir ni generar metadatos al exportar los archivos Avro.
No es necesario que sigas ninguna convención de nomenclatura específica para tus archivos.
Si no exporta los archivos directamente a Cloud Storage, debe subirlos a un segmento de Cloud Storage. Para obtener instrucciones detalladas, consulta Subir objetos a Cloud Storage.
Importar archivos Avro de bases de datos que no son de Spanner a Spanner
Para importar archivos Avro de una base de datos que no es de Spanner a Spanner, sigue estos pasos:
- Crea tablas de destino y define el esquema de tu base de datos de Spanner.
- Crea un archivo
spanner-export.jsonen tu segmento de Cloud Storage. - Ejecuta una tarea de importación de Dataflow con gcloud CLI.
Paso 1: Crea el esquema de tu base de datos de Spanner
Antes de ejecutar la importación, debes crear la tabla de destino en Spanner y definir su esquema.
Debe crear un esquema que utilice el tipo de columna adecuado para cada columna de los archivos Avro.
Asignaciones recomendadas
GoogleSQL
| Tipo de columna Avro | Tipo de columna de Spanner |
|---|---|
ARRAY |
ARRAY |
BOOL |
BOOL |
BYTES |
|
DOUBLE |
FLOAT64 |
FLOAT |
FLOAT64 |
INT |
INT64 |
LONG |
|
STRING |
|
PostgreSQL
| Tipo de columna Avro | Tipo de columna de Spanner |
|---|---|
ARRAY |
ARRAY |
BOOL |
BOOLEAN |
BYTES |
|
DOUBLE |
DOUBLE PRECISION |
FLOAT |
DOUBLE PRECISION |
INT |
BIGINT |
LONG |
|
STRING |
|
Paso 2: Crea un archivo spanner-export.json
También debes crear un archivo llamado spanner-export.json en tu segmento de Cloud Storage. Este archivo especifica el dialecto de la base de datos y contiene una matriz tables que incluye el nombre y las ubicaciones de los archivos de datos de cada tabla.
El contenido del archivo tiene el siguiente formato:
{ "tables": [ { "name": "TABLE1", "dataFiles": [ "RELATIVE/PATH/TO/TABLE1_FILE1", "RELATIVE/PATH/TO/TABLE1_FILE2" ] }, { "name": "TABLE2", "dataFiles": ["RELATIVE/PATH/TO/TABLE2_FILE1"] } ], "dialect":"DATABASE_DIALECT" }
Donde DATABASE_DIALECT = {GOOGLE_STANDARD_SQL | POSTGRESQL}
Si se omite el elemento de dialecto, se usará el dialecto GOOGLE_STANDARD_SQL de forma predeterminada.
Paso 3: Ejecuta un trabajo de importación de Dataflow con gcloud CLI
Para iniciar la tarea de importación, sigue las instrucciones para usar la CLI de Google Cloud y ejecutar una tarea con la plantilla de Avro a Spanner.
Una vez que hayas iniciado un trabajo de importación, puedes ver los detalles del trabajo en la Google Cloud consola.
Una vez que haya finalizado la tarea de importación, añada los índices secundarios y las claves externas que necesite.
Selecciona una región para la tarea de importación
Puede que quieras elegir otra región en función de la ubicación de tu segmento de Cloud Storage. Para evitar cargos por transferencia de datos saliente, elige una región que coincida con la ubicación de tu segmento de Cloud Storage.
Si la ubicación de tu segmento de Cloud Storage es una región, puedes aprovechar el uso de red gratuito eligiendo la misma región para tu tarea de importación, siempre que esté disponible.
Si la ubicación de tu segmento de Cloud Storage es una región doble, puedes aprovechar el uso de red gratuito eligiendo una de las dos regiones que componen la región doble para tu tarea de importación, siempre que una de las regiones esté disponible.
- Si no hay ninguna región colocada disponible para tu tarea de importación o si la ubicación de tu segmento de Cloud Storage es una multirregión, se aplicarán cargos por transferencia de datos saliente. Consulta los precios de la transferencia de datos de Cloud Storage para elegir una región que genere los cargos más bajos por transferencia de datos.
Ver o solucionar problemas de trabajos en la interfaz de Dataflow
Una vez que hayas iniciado un trabajo de importación, podrás ver los detalles del trabajo, incluidos los registros, en la sección Dataflow de la Google Cloud consola.
Ver los detalles de una tarea de Dataflow
Para ver los detalles de las tareas de importación o exportación que hayas ejecutado en la última semana, incluidas las que se estén ejecutando en este momento, sigue estos pasos:
- Vaya a la página Resumen de la base de datos de la base de datos.
- Haz clic en la opción de menú Importar/Exportar del panel de la izquierda. En la página Importar/Exportar de la base de datos se muestra una lista de las tareas recientes.
En la página Importar/Exportar de la base de datos, haga clic en el nombre del trabajo de la columna Nombre del trabajo de Dataflow:
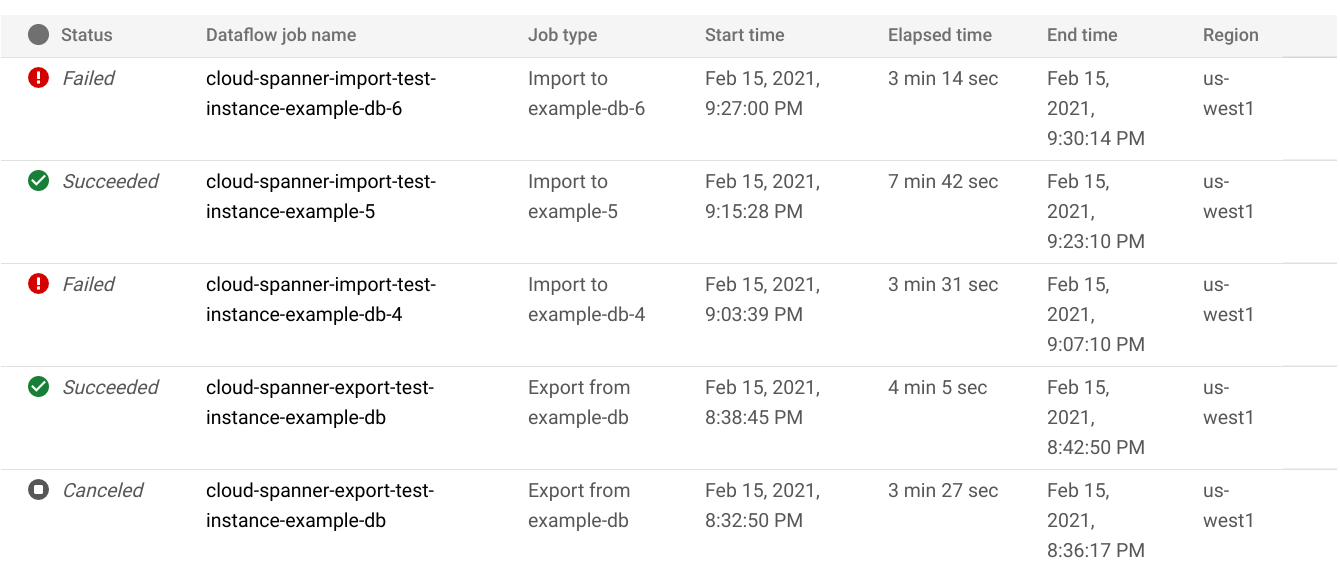
La consola Google Cloud muestra los detalles del trabajo de Dataflow.
Para ver un trabajo que ejecutaste hace más de una semana, sigue estos pasos:
Ve a la página de trabajos de Dataflow de la Google Cloud consola.
Busca el trabajo en la lista y haz clic en su nombre.
La consola Google Cloud muestra los detalles del trabajo de Dataflow.
Ver los registros de Dataflow de tu trabajo
Para ver los registros de un trabajo de Dataflow, ve a la página de detalles del trabajo y haz clic en Registros a la derecha del nombre del trabajo.
Si una tarea falla, busca errores en los registros. Si hay errores, el número de errores se mostrará junto a Registros:

Para ver los errores de las tareas, sigue estos pasos:
Haz clic en el número de errores situado junto a Registros.
La Google Cloud consola muestra los registros del trabajo. Puede que tengas que desplazarte para ver los errores.
Busca las entradas que tengan el icono de error
 .
.Haz clic en una entrada de registro para ver su contenido.
Para obtener más información sobre cómo solucionar problemas de trabajos de Dataflow, consulta el artículo Solucionar problemas de una canalización.
Solucionar problemas con tareas de importación fallidas
Si ves los siguientes errores en los registros de tu trabajo:
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
Consulta la latencia de escritura del 99% en la pestaña Monitorización de tu base de datos de Spanner en laGoogle Cloud consola. Si muestra valores altos (varios segundos), significa que la instancia está sobrecargada, lo que provoca que las escrituras se agoten y fallen.
Una de las causas de la alta latencia es que la tarea de Dataflow se ejecuta con demasiados trabajadores, lo que supone una carga excesiva para la instancia de Spanner.
Para especificar un límite en el número de trabajadores de Dataflow, en lugar de usar la pestaña Importar/Exportar de la página de detalles de la instancia de tu base de datos de Spanner en la Google Cloud consola, debes iniciar la importación con la plantilla de Avro de Cloud Storage a Spanner y especificar el número máximo de trabajadores tal como se describe a continuación:Consola
Si usas la consola de Dataflow, el parámetro Máximo de trabajadores se encuentra en la sección Parámetros opcionales de la página Crear trabajo a partir de plantilla.
gcloud
Ejecuta el comando gcloud dataflow jobs run
y especifica el argumento max-workers. Por ejemplo:
gcloud dataflow jobs run my-import-job \
--gcs-location='gs://dataflow-templates/latest/GCS_Avro_to_Cloud_Spanner' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,inputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Solucionar un error de red
Puede que se produzca el siguiente error al exportar tus bases de datos de Spanner:
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
Este error se produce porque Spanner da por hecho que quieres usar una red VPC de modo automático llamada default en el mismo proyecto que el trabajo de Dataflow. Si no tienes una red de VPC predeterminada en el proyecto o si tu red de VPC está en una red de VPC de modo personalizado, debes crear un trabajo de Dataflow y especificar una red o subred alternativa.
Optimizar las tareas de importación lentas
Si has seguido las sugerencias de la sección Configuración inicial, no deberías tener que hacer ningún otro ajuste. Si tu trabajo se ejecuta lentamente, puedes probar otras optimizaciones:
Optimizar la ubicación de la tarea y de los datos: ejecuta la tarea de Dataflow en la misma región en la que se encuentran tu instancia de Spanner y tu segmento de Cloud Storage.
Asegúrate de que haya suficientes recursos de Dataflow: si las cuotas de Compute Engine pertinentes limitan los recursos de tu tarea de Dataflow, en la página de Dataflow de la Google Cloud consola se mostrará un icono de advertencia
 y mensajes de registro:
y mensajes de registro: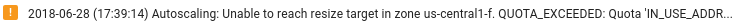
En esta situación, aumentar las cuotas de CPUs, direcciones IP en uso y discos persistentes estándar podría acortar el tiempo de ejecución del trabajo, pero es posible que incurras en más cargos de Compute Engine.
Comprueba la utilización de la CPU de Spanner: si ves que la utilización de la CPU de la instancia supera el 65%, puedes aumentar la capacidad de computación de esa instancia. La capacidad añade más recursos de Spanner y el trabajo debería acelerarse, pero incurrirás en más cargos de Spanner.
Factores que afectan al rendimiento de las tareas de importación
Hay varios factores que influyen en el tiempo que se tarda en completar una tarea de importación.
Tamaño de la base de datos de Spanner: procesar más datos requiere más tiempo y recursos.
Esquema de la base de datos de Spanner, que incluye lo siguiente:
- El número de tablas
- El tamaño de las filas
- Número de índices secundarios
- Número de claves externas
- El número de flujos de cambios
Ubicación de los datos: los datos se transfieren entre Spanner y Cloud Storage mediante Dataflow. Lo ideal es que los tres componentes estén en la misma región. Si los componentes no están en la misma región, mover los datos entre regiones ralentiza el trabajo.
Número de trabajadores de Dataflow: se necesitan trabajadores de Dataflow óptimos para conseguir un buen rendimiento. Con el autoescalado, Dataflow elige el número de trabajadores de la tarea en función de la cantidad de trabajo que se debe realizar. Sin embargo, el número de trabajadores estará limitado por las cuotas de CPUs, direcciones IP en uso y discos persistentes estándar. La interfaz de usuario de Dataflow muestra un icono de advertencia si se encuentra con límites de cuota. En esta situación, el progreso es más lento, pero el trabajo debería completarse igualmente. El autoescalado puede sobrecargar Spanner, lo que provoca errores cuando hay una gran cantidad de datos que importar.
Carga existente en Spanner: una tarea de importación añade una carga de CPU significativa a una instancia de Spanner. Si la instancia ya tiene una carga considerable, la tarea se ejecutará más lentamente.
Cantidad de capacidad de computación de Spanner: si la utilización de la CPU de la instancia supera el 65%, el trabajo se ejecuta más lentamente.
Ajustar los workers para que el rendimiento de la importación sea bueno
Al iniciar una tarea de importación de Spanner, los trabajadores de Dataflow deben tener un valor óptimo para que el rendimiento sea bueno. Si hay demasiados trabajadores, se sobrecarga Spanner, y si hay muy pocos, el rendimiento de la importación es mediocre.
El número máximo de trabajadores depende en gran medida del tamaño de los datos, pero, idealmente, el uso total de la CPU de Spanner debería estar entre el 70% y el 90%. De esta forma, se consigue un buen equilibrio entre la eficiencia de Spanner y la finalización de los trabajos sin errores.
Para alcanzar ese objetivo de utilización en la mayoría de los esquemas y las situaciones, recomendamos que el número máximo de vCPUs de trabajador sea entre 4 y 6 veces el número de nodos de Spanner.
Por ejemplo, en una instancia de Spanner de 10 nodos, si usas trabajadores n1-standard-2, deberías definir el número máximo de trabajadores en 25, lo que te daría 50 vCPUs.