Auf dieser Seite wird beschrieben, wie Sie Avro-Dateien vorbereiten, die Sie aus Nicht-Spanner-Datenbanken exportiert haben, und diese Dateien anschließend in Spanner importieren. Diese Verfahren enthalten Informationen sowohl für Datenbanken mit GoogleSQL-Dialekt als auch für Datenbanken mit PostgreSQL-Dialekt. Wenn Sie eine zuvor exportierte Spanner-Datenbank importieren möchten, finden Sie weitere Informationen unter Spanner-Avro-Dateien importieren.
Der Vorgang verwendet Dataflow; Es importiert Daten aus einem Cloud Storage-Bucket, der eine Reihe von Avro-Dateien und eine JSON-Manifestdatei enthält, die die Zieltabellen und Avro-Dateien angibt, mit denen die einzelnen Tabellen gefüllt werden.
Hinweise
Zum Importieren einer Spanner-Datenbank müssen Sie zuerst die APIs für Spanner, Cloud Storage, Compute Engine und Dataflow aktivieren:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Außerdem brauchen Sie ein ausreichend großes Kontingent und die erforderlichen IAM-Berechtigungen.
Kontingentanforderungen
Für Importjobs gelten folgende Kontingentanforderungen:
- Spanner: Sie müssen für die zu importierenden Daten ausreichend Rechenkapazität haben. Für den Import einer Datenbank ist keine zusätzliche Rechenkapazität erforderlich. Allerdings benötigen Sie möglicherweise weitere Rechenkapazität, damit der Job in angemessener Zeit abgeschlossen werden kann. Weitere Informationen finden Sie unter Jobs optimieren.
- Cloud Storage: Zum Importieren benötigen Sie einen Bucket mit Ihren zuvor exportierten Dateien. Für den Bucket muss keine Größe festgelegt werden.
- Dataflow: Für Importjobs gelten dieselben Compute Engine-Kontingente für CPU, Laufwerksnutzung und IP-Adressen wie für andere Dataflow-Jobs.
Compute Engine: Bevor Sie den Importjob ausführen, müssen Sie zuerst Kontingente für Compute Engine einrichten, die von Dataflow verwendet werden. Diese Kontingente stellen die maximale Anzahl von Ressourcen dar, die Dataflow für Ihren Job verwenden darf. Empfohlene Anfangswerte sind:
- CPUs: 200
- Verwendete IP-Adressen: 200
- Nichtflüchtiger Standardspeicher: 50 TB
In der Regel sind keine weiteren Anpassungen erforderlich. Dataflow bietet Autoscaling, sodass Sie nur für die Ressourcen zahlen, die beim Import tatsächlich verwendet werden. Wenn Ihr Job mehr Ressourcen verwenden kann, wird in der Dataflow-UI ein Warnsymbol angezeigt. Der Job sollte trotz dieses Warnsymbols beendet werden.
Erforderliche Rollen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen für das Dataflow-Worker-Dienstkonto zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Exportieren einer Datenbank benötigen:
-
Cloud Spanner-Betrachter (
roles/spanner.viewer) -
Dataflow-Worker (
roles/dataflow.worker) -
Storage-Administrator (
roles/storage.admin) -
Spanner-Datenbankleser (
roles/spanner.databaseReader) -
Datenbankadministrator (
roles/spanner.databaseAdmin)
Daten aus einer Nicht-Spanner-Datenbank in Avro-Dateien exportieren
Beim Importvorgang werden Daten aus Avro-Dateien in einem Cloud Storage-Bucket übernommen. Sie können Daten im Avro-Format aus jeder Quelle exportieren und dazu jede verfügbare Methode verwenden.
So exportieren Sie Daten aus einer Nicht-Spanner-Datenbank in Avro-Dateien:
Beachten Sie beim Exportieren Ihrer Daten folgende Punkte:
- Der Export lässt sich mit einem der primitiven Avro-Typen sowie mit dem komplexen Array-Typ ausführen.
Jede Spalte der Avro-Dateien muss einen der folgenden Spaltentypen verwenden:
ARRAYBOOLBYTES*DOUBLEFLOATINTLONG†STRING‡
* Eine Spalte vom Typ
BYTESwird zum Importieren einer Spanner-NUMERICverwendet. Weitere Informationen finden Sie unten im Abschnitt Empfohlene Zuordnungen.†,‡ Sie können einen
LONGimportieren, der einen Zeitstempel speichert, oder einenSTRING, der einen Zeitstempel als Spanner-TIMESTAMPspeichert. Weitere Informationen finden Sie unten im Abschnitt Empfohlene Zuordnungen.Beim Exportieren der Avro-Dateien müssen Sie Metadaten weder hinzufügen noch generieren.
Für Ihre Dateien müssen keine bestimmten Namenskonventionen eingehalten werden.
Wenn Sie Ihre Dateien nicht direkt nach Cloud Storage exportieren, müssen Sie die Avro-Dateien in einen Cloud Storage-Bucket hochladen. Eine detaillierte Anleitung finden Sie unter Objekte in Cloud Storage hochladen.
Avro-Dateien aus Nicht-Spanner-Datenbanken in Spanner importieren
So importieren Sie Avro-Dateien aus einer Nicht-Spanner-Datenbank in Spanner:
- Erstellen Sie Zieltabelle und definieren Sie das Schema für Ihre Spanner-Datenbank.
- Erstellen Sie in Ihrem Cloud Storage-Bucket eine Datei mit dem Namen
spanner-export.json. - Führen Sie einen Dataflow-Importjob mit der gcloud CLI aus.
Schritt 1: Schema für die Spanner-Datenbank erstellen
Bevor Sie den Import ausführen, müssen Sie die Zieltabelle in Spanner erstellen und ein Schema definieren.
Sie müssen ein Schema erstellen, das den entsprechenden Spaltentyp für jede Spalte in den Avro-Dateien verwendet.
Empfohlene Zuordnungen
GoogleSQL
| Avro-Spaltentyp | Spanner-Spaltentyp |
|---|---|
ARRAY |
ARRAY |
BOOL |
BOOL |
BYTES |
|
DOUBLE |
FLOAT64 |
FLOAT |
FLOAT64 |
INT |
INT64 |
LONG |
|
STRING |
|
PostgreSQL
| Avro-Spaltentyp | Spanner-Spaltentyp |
|---|---|
ARRAY |
ARRAY |
BOOL |
BOOLEAN |
BYTES |
|
DOUBLE |
DOUBLE PRECISION |
FLOAT |
DOUBLE PRECISION |
INT |
BIGINT |
LONG |
|
STRING |
|
Schritt 2: spanner-export.json-Datei erstellen
Außerdem müssen Sie in Ihrem Cloud Storage-Bucket eine Datei mit dem Namen spanner-export.json erstellen. In dieser Datei wird der Datenbankdialekt angegeben. Sie enthält ein tables-Array, in dem Name und Speicherort der Datendatei für jede Tabelle aufgeführt sind.
Der Inhalt der Datei hat folgendes Format:
{ "tables": [ { "name": "TABLE1", "dataFiles": [ "RELATIVE/PATH/TO/TABLE1_FILE1", "RELATIVE/PATH/TO/TABLE1_FILE2" ] }, { "name": "TABLE2", "dataFiles": ["RELATIVE/PATH/TO/TABLE2_FILE1"] } ], "dialect":"DATABASE_DIALECT" }
Dabei gilt: DATABASE_DIALECT = {GOOGLE_STANDARD_SQL | POSTGRESQL}
Wenn das Dialektelement weggelassen wird, wird standardmäßig der Dialekt GOOGLE_STANDARD_SQL verwendet.
Schritt 3: Dataflow-Importjob mit der gcloud CLI ausführen
Folgen Sie der Anleitung zum Ausführen eines Importvorgangs über die Google Cloud CLI mit der Vorlage "Avro zu Spanner", um einen Importjob zu starten.
Nachdem Sie einen Importjob gestartet haben, können Sie in der Google Cloud Console Details zum Job aufrufen.
Fügen Sie nach Abschluss des Importjobs alle erforderlichen sekundären Indexe und Fremdschlüssel hinzu.
Region für den Importjob auswählen
Welche Region Sie auswählen, hängt vom Standort Ihres Cloud Storage-Bucket ab. Um Gebühren für ausgehenden Datentransfer zu vermeiden, wählen Sie eine Region aus, die mit dem Speicherort Ihres Cloud Storage-Bucket übereinstimmt.
Wenn der Speicherort Ihres Cloud Storage-Bucket eine Region ist, können Sie die kostenlose Netzwerknutzung nutzen, indem Sie dieselbe Region für Ihren Importjob auswählen, sofern diese Region verfügbar ist.
Wenn der Speicherort Ihres Cloud Storage-Bucket eine Region mit zwei Standorten ist, können Sie die kostenlose Netzwerknutzung nutzen, indem Sie eine der beiden Regionen auswählen, aus denen die Region mit zwei Standorten für Ihren Importjob besteht, sofern eine der Regionen verfügbar ist.
- Wenn für Ihren Importjob keine Region mit gemeinsamem Standort verfügbar ist oder der Speicherort Ihres Cloud Storage-Bucket eine Multiregion ist, fallen Gebühren für ausgehenden Datentransfer an. Wählen Sie anhand der Cloud Storage-Preisliste für Datenübertragung eine Region aus, in der die Gebühren für die Datenübertragung möglichst gering sind.
Jobs in der Dataflow-UI ansehen und Probleme beheben
Nachdem Sie einen Importjob gestartet haben, können Sie in der Google Cloud -Konsole im Abschnitt „Dataflow“ Details zum Job einschließlich der Logs ansehen.
Details zum Dataflow-Job ansehen
So rufen Sie Details zu allen Import- oder Exportjobs auf, die Sie in der letzten Woche ausgeführt haben, einschließlich aller derzeit ausgeführten Jobs:
- Wechseln Sie zur Seite Datenbanküberblick für die Datenbank.
- Klicken Sie im linken Bereich auf den Menüpunkt Import/Export. Auf der Datenbankseite Import/Export wird eine Liste der letzten Jobs angezeigt.
Klicken Sie auf der Seite Import/Export der Datenbank in der Spalte Dataflow-Jobname auf den Jobnamen:
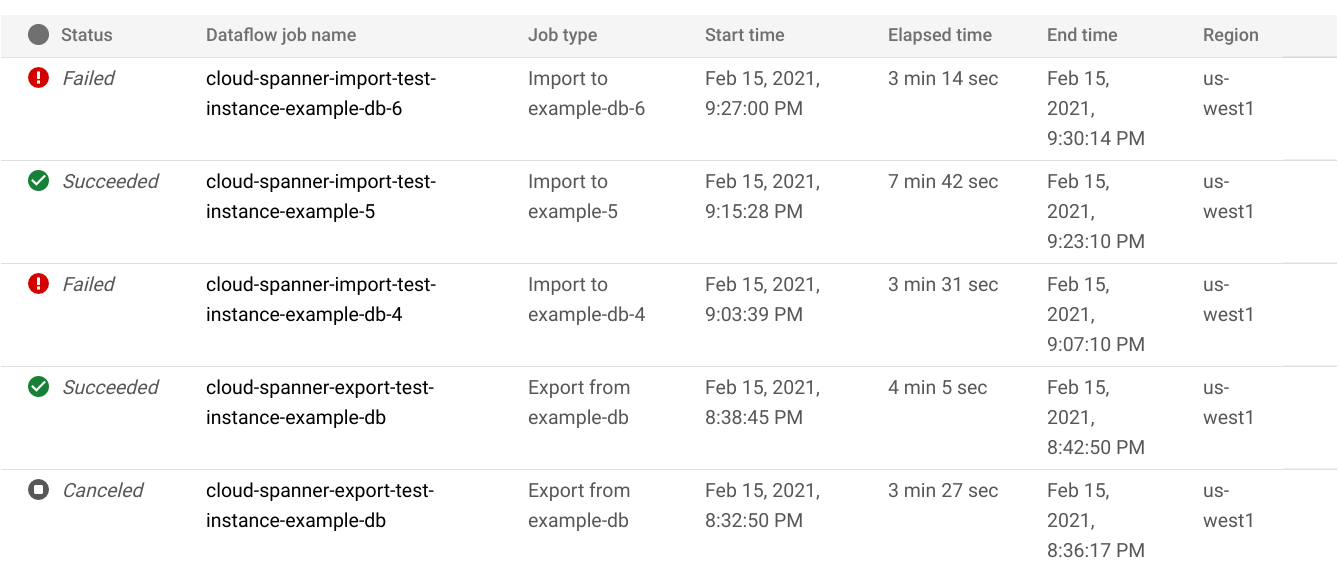
In der Google Cloud Console werden Details des Dataflow-Jobs angezeigt.
So rufen Sie einen Job auf, den Sie vor mehr als einer Woche ausgeführt haben:
Rufen Sie in der Google Cloud -Console die Seite „Dataflow-Jobs“ auf.
Suchen Sie den Job in der Liste und klicken Sie auf seinen Namen.
In der Google Cloud Console werden Details des Dataflow-Jobs angezeigt.
Dataflow-Logs für einen Job aufrufen
Rufen Sie die Detailseite des Jobs auf und klicken Sie rechts neben dem Jobnamen auf Logs, um die Logs eines Dataflow-Jobs anzusehen.
Wenn ein Job fehlschlägt, suchen Sie in den Logs nach Fehlern. Falls Fehler aufgetreten sind, ist neben Logs die Fehleranzahl zu sehen:

So sehen Sie sich Jobfehler genauer an:
Klicken Sie auf die Fehleranzahl neben Logs.
In der Google Cloud -Console können Sie die Logs des Jobs ansehen. Unter Umständen müssen Sie scrollen, um die Fehler einzublenden.
Suchen Sie nach Einträgen mit dem Fehlersymbol
 .
.Klicken Sie auf einen Logeintrag, um ihn zu maximieren.
Weitere Informationen zur Fehlerbehebung bei Dataflow-Jobs finden Sie unter Pipelinefehler beheben.
Fehlerbehebung bei fehlgeschlagenen Importjobs
Wenn in Ihren Joblogs die folgenden Fehler angezeigt werden:
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
Prüfen Sie die Schreiblatenz von 99% auf dem Tab Monitoring Ihrer Spanner-Datenbank in derGoogle Cloud Console. Wenn hohe Werte angezeigt werden (mehrere Sekunden), bedeutet dies, dass die Instanz überlastet ist, was zu Schreibfehlern führt.
Eine Ursache für eine hohe Latenz ist, dass der Dataflow-Job mit zu vielen Workern ausgeführt wird und die Spanner-Instanz zu stark belastet wird.
Wenn Sie die Anzahl der Dataflow-Worker begrenzen möchten, anstatt den Tab „Import/Export“ auf der Seite mit den Instanzdetails Ihrer Spanner-Datenbank in der Google Cloud Console zu verwenden, müssen Sie den Import mit der Dataflow-Vorlage „Cloud Storage Avro in Spanner“ starten und die maximale Anzahl der Worker angeben, wie beschrieben:Console
Wenn Sie die Dataflow Console verwenden, befindet sich der Parameter Max. Worker im Abschnitt Optionale Parameter auf der Seite Job aus Vorlage erstellen.
gcloud
Führen Sie den Befehl gcloud dataflow jobs run aus und geben Sie das Argument max-workers an. Beispiel:
gcloud dataflow jobs run my-import-job \
--gcs-location='gs://dataflow-templates/latest/GCS_Avro_to_Cloud_Spanner' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,inputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Netzwerkfehler beheben
Der folgende Fehler kann auftreten, wenn Sie Ihre Spanner-Datenbanken exportieren:
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
Dieser Fehler tritt auf, weil Spanner davon ausgeht, dass Sie ein VPC-Netzwerk im automatischen Modus namens default im selben Projekt wie den Dataflow-Job verwenden möchten. Wenn Sie im Projekt kein Standard-VPC-Netzwerk haben oder für Ihr VPC-Netzwerk der benutzerdefinierte Modus gilt, müssen Sie einen Dataflow-Job erstellen und ein alternatives Netzwerk oder Subnetzwerk angeben.
Langsam laufende Importjobs optimieren
Wenn Sie die Vorschläge für die Anfangseinstellungen befolgt haben, sollten in der Regel keine weiteren Anpassungen nötig sein. Falls der Job jedoch langsam ausgeführt wird, können Sie einige andere Optimierungen versuchen:
Job- und Datenspeicherort optimieren: Führen Sie den Dataflow-Job in der Region der Spanner-Instanz und des Cloud Storage-Bucket aus.
Ausreichende Dataflow-Ressourcen bereitstellen: Sind die Ressourcen für den Dataflow-Job durch die entsprechenden Compute Engine-Kontingente eingeschränkt, sind auf der Dataflow-Seite des Jobs in der Google Cloud -Konsole ein Warnsymbol
 und Logmeldungen zu sehen:
und Logmeldungen zu sehen: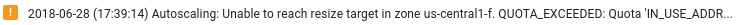
In diesem Fall kann das Erhöhen der Kontingente für CPUs, verwendete IP-Adressen und nichtflüchtigen Standardspeicher die Ausführungszeit des Jobs verkürzen, aber auch höhere Compute Engine-Gebühren zur Folge haben.
Spanner-CPU-Auslastung prüfen: Wenn die CPU-Auslastung für die Instanz über 65 % liegt, können Sie die Rechenkapazität in dieser Instanz erhöhen. Die zusätzliche Kapazität liefert mehr Spanner-Ressourcen, damit der Job schneller ausgeführt wird, aber es fallen auch höhere Spanner-Gebühren an.
Faktoren, die sich auf die Leistung von Importjobs auswirken
Mehrere Faktoren beeinflussen die Zeit, die für einen Importjob benötigt wird.
Größe der Spanner-Datenbank: Die Verarbeitung von mehr Daten erfordert mehr Zeit und Ressourcen.
Cloud Spanner-Datenbankschema, einschließlich:
- Anzahl der Tabellen
- Die Größe der Zeilen
- Anzahl der sekundären Indexe
- Anzahl der Fremdschlüssel
- Anzahl der Änderungsstreams
Datenspeicherort: Daten werden mit Dataflow zwischen Spanner und Cloud Storage übertragen. Idealerweise befinden sich alle drei Komponenten in derselben Region. Wenn das nicht der Fall ist, dauert das regionsübergreifende Verschieben der Daten länger.
Anzahl der Dataflow-Worker: Optimale Dataflow-Worker sind für eine gute Leistung erforderlich. Mithilfe von Autoscaling wählt Dataflow die Anzahl der Worker für einen Job abhängig vom Arbeitsumfang aus. Diese Anzahl wird jedoch durch die Kontingente für CPUs, verwendete IP-Adressen und nichtflüchtigen Standardspeicher begrenzt. In der Dataflow-UI ist ein Warnsymbol zu sehen, wenn Kontingentobergrenzen erreicht werden. In diesem Fall dauert die Verarbeitung länger, aber der Job sollte dennoch abgeschlossen werden. Autoscaling kann Spanner überlasten und zu Fehlern führen, wenn eine große Datenmenge zum Importieren vorliegt.
Bestehende Auslastung von Spanner: Ein Importjob erhöht die CPU-Auslastung für eine Spanner-Instanz erheblich. Wenn die Instanz jedoch bereits eine erhebliche bestehende Auslastung aufweist, wird der Job langsamer ausgeführt.
Menge der Spanner-Rechenkapazität: Wenn die CPU-Auslastung für die Instanz über 65 % liegt, wird der Job langsamer ausgeführt.
Worker für eine gute Importleistung optimieren
Beim Starten eines Spanner-Importjobs müssen Dataflow-Worker für eine gute Leistung auf einen optimalen Wert gesetzt sein. Eine zu große Anzahl von Workern überlastet Spanner und zu wenige Worker führen zu einer enttäuschenden Importleistung.
Die maximale Anzahl von Workern hängt stark von der Datengröße ab. Im Idealfall sollte die gesamte CPU-Auslastung von Spanner zwischen 70% und 90 % liegen. Dies bietet ein gutes Gleichgewicht zwischen Spanner-Effizienz und fehlerfreier Jobvervollständigung.
Damit dieses Auslastungsziel bei den meisten Schemas und Szenarien erreicht wird, empfehlen wir eine maximale Anzahl von Worker-vCPUs zwischen dem Vier- und Sechsfachen der Anzahl der Spanner-Knoten.
Beispiel: Für eine 10-Knoten-Spanner-Instanz, die n1-standard-2-Worker verwendet, würden Sie die maximale Anzahl an Workern auf 25 setzen, was 50 vCPUs ergibt.