Auf dieser Seite werden die Spanner-Rechenkapazität und die beiden Maßeinheiten beschrieben, die zur Quantifizierung verwendet werden: Knoten und Verarbeitungseinheiten.
Rechenkapazität
Wenn Sie eine Instanz erstellen, wählen Sie eine Instanzkonfiguration und eine Menge an Rechenkapazität für die Instanz aus. Die Rechenkapazität Ihrer Instanz hat die folgenden Merkmale:
- Sie bestimmt die Menge an Server- und Speicherressourcen, die den Datenbanken in Ihrer Instanz zur Verfügung stehen, einschließlich der Festplattenlast. Die Festplattenlast gilt nur für Arbeitslasten, die auf Daten zugreifen, die auf HDD-Speicher gespeichert sind. Weitere Informationen finden Sie unter Übersicht zu abgestuften Speicheroptionen.
Sie wird in Verarbeitungseinheiten oder Knoten gemessen, wobei 1.000 Verarbeitungseinheiten 1 Knoten entsprechen.
- Ein Knoten oder 1.000 Verarbeitungseinheiten ist eine logische Einheit für die Rechenkapazität und entspricht nicht einem einzelnen physischen Server. Die Rechenressourcen für jeden Knoten werden auf mehrere zugrunde liegende physische Maschinen oder Server verteilt. Die Anzahl der Server pro Knoten hängt von der Konfiguration Ihrer Instanz ab. Eine regionale Instanz verwendet beispielsweise mindestens drei Server pro Knoten, während eine Instanz mit mehreren Regionen mindestens fünf Server verwendet. Weitere Informationen finden Sie unter Rechenkapazität und Instanzkonfigurationen.
- Wenn Sie die Rechenkapazität einer Instanz definieren oder ändern, müssen Sie die Verarbeitungseinheiten in Vielfachen von 100 angeben (z. B. 100, 200, 300). Wenn die Anzahl der Verarbeitungseinheiten 1.000 erreicht, können Sie größere Mengen entweder als Vielfache von 1.000 Verarbeitungseinheiten (z. B. 1.000, 2.000, 3.000) oder als Knoten (z. B. 1, 2, 3) angeben.
Spanner stellt die angegebene Rechenkapazität (repliziert) in jeder Zone, in der sich ein Replikat Ihrer Daten befindet, vollständig zur Verfügung. Wenn Sie beispielsweise 1.000 Verarbeitungseinheiten für eine regionale Instanz bereitstellen, die in der Regel Replikate in drei Zonen hat, stehen in jeder dieser drei Zonen die vollen 1.000 Verarbeitungseinheiten an Rechenleistung zur Verfügung, um das jeweilige Replikat zu bedienen. Spanner teilt die Gesamtzahl der Verarbeitungseinheiten nicht auf die Zonen auf und verteilt sie nicht auf die Zonen. Die Maßeinheit, die Sie verwenden, spielt keine Rolle, es sei denn, Sie erstellen eine Instanz mit einer Rechenkapazität, die kleiner als 1.000 Verarbeitungseinheiten (1 Knoten) ist. In diesem Fall müssen Sie die Rechenkapazität der Instanz in Verarbeitungseinheiten angeben.
Instanzen mit weniger als 1.000 Verarbeitungseinheiten sind für kleinere Datenmengen, Abfragen und Arbeitslasten konzipiert. Sie haben begrenzte Rechenressourcen, was bei einigen Arbeitslasten zu einer nicht linearen Skalierung und Leistungsproblemen führen kann. Bei diesen Instanzen kann es auch zu zeitweiligen Latenzerhöhungen kommen.
Verfügbarkeit von Spanner
Spanner ist auf Hochverfügbarkeit ausgelegt. Da die Rechenkapazität jeder Instanz auf mehrere Server in verschiedenen Zonen verteilt ist, ist Spanner widerstandsfähig gegen den Ausfall eines einzelnen Servers. Der Verlust eines einzelnen Servers führt nicht zu einem Knotenausfall. Spanner verwaltet die zugrunde liegenden Ressourcen automatisch, um eine kontinuierliche Verfügbarkeit Ihrer Instanz zu gewährleisten.
Beschränkungen für die Datenspeicherung
Wie in Kontingente und Limits beschrieben, verwendet Spanner die Rechenkapazität einer Instanz als Grundlage für die Bestimmung von Speicherlimits, um eine hohe Verfügbarkeit und eine niedrige Latenz beim Zugriff auf eine Datenbank zu bieten. Dabei werden die folgenden Richtlinien verwendet:
- Bei Instanzen, die kleiner als 1 Knoten (1.000 Verarbeitungseinheiten) sind, weist Cloud Spanner jeweils 1.024,0 GiB Daten pro 100 Verarbeitungseinheiten in der Datenbank zu.
- Bei Instanzen, die mindestens eine Größe von einem Knoten haben, weist Spanner für jeden Knoten 10 TiB Daten zu.
Wenn Sie beispielsweise eine Instanz für eine 300 GB-Datenbank erstellen möchten, können Sie die Rechenkapazität auf 100 Verarbeitungseinheiten festlegen. Mit dieser Rechenkapazität wird die Instanz unter dem Limit gehalten, bis die Datenbank größer als 1024,0 GiB ist. Bei Erreichen dieser Größe müssen Sie jedoch weitere 100 Verarbeitungseinheiten hinzufügen, damit die Datenbank kontinuierlich wachsen kann. Andernfalls werden Schreibvorgänge in die Datenbank möglicherweise abgelehnt. Weitere Informationen finden Sie unter Empfehlungen für die Datenbankspeicherauslastung.
Bei Spanner wird der Speicherplatz in Rechnung gestellt, der von Instanzen tatsächlich genutzt wird, und nicht das gesamte Speicherkontingent.
Leistung
Die Spitzenwerte, die mit einer bestimmten Rechenkapazität für den Durchsatz für Lese- und Schreibvorgänge erreicht werden können, hängen von der Instanzkonfiguration sowie vom Schemadesign und von den Dataset-Eigenschaften ab. Weitere Informationen finden Sie unter Leistungsübersicht.
Instanzen mit weniger als 1.000 PUs werden für kleinere Datenmengen, Abfragen und Arbeitslasten verwendet. Bei größeren Arbeitslasten können die begrenzten Rechenressourcen zu einer nicht linearen Skalierung und Leistung mit zeitweiligen Latenzerhöhungen führen.
Rechenkapazität und Instanzkonfigurationen
Wie unter Regionale, biregionale und multiregionale Konfigurationen beschrieben, verteilt Spanner eine Instanz auf Zonen einer oder mehrerer Regionen, um hohe Leistung und hohe Verfügbarkeit zu bieten. Folglich verteilt Spanner auch die Serverressourcen, die durch die Rechenkapazität der Instanz bereitgestellt werden.
Das folgende Diagramm veranschaulicht diese Verteilung der Serverressourcen.
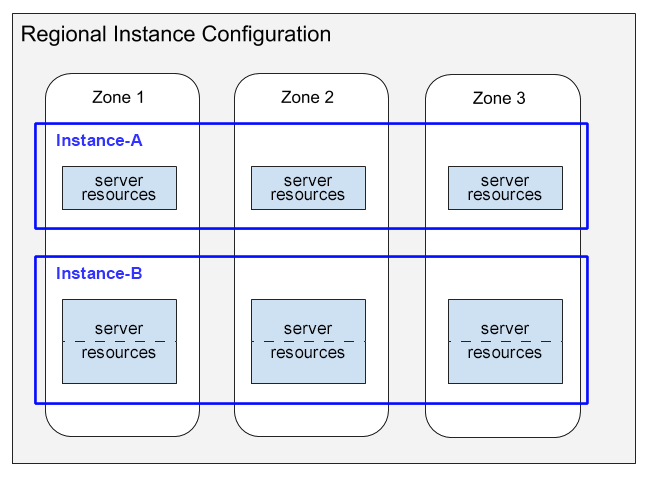
In diesem Diagramm sind zwei Instanzen mit regionalen Konfigurationen dargestellt:
- Instanz-A zeigt eine Instanz mit 1.000 Verarbeitungseinheiten (1 Knoten) mit ihrer Verteilung der Rechenkapazität, die Serverressourcen in jeder der drei Zonen verbraucht.
- Instanz-B zeigt eine Instanz von 2.000 Verarbeitungseinheiten (2 Knoten) mit ihrer Verteilung der Rechenkapazität, die die Serverressourcen in jeder der drei Zonen verbraucht.
Beachten Sie in diesem Diagramm Folgendes:
Für jede Instanz weist Spanner Serverressourcen in jeder Zone der regionalen Konfiguration zu. Jede Serverressource pro Zone verwendet das Datenreplikat in ihrer Zone. Informationen zu Datenreplikaten in Instanzkonfigurationen finden Sie unter Regionale, biregionale und multiregionale Konfigurationen. Informationen dazu, wie Spanner diese Datenreplikate synchronisiert, finden Sie unter Replikation.
Die Serverressourcen für Instanz-A werden in einfachen Feldern angezeigt, während die Ressourcen für Instanz-B in Feldern angezeigt werden, die in zwei Teile unterteilt sind. Dieser Unterschied zeigt, dass Spanner die Serverressourcen unterschiedlich großer Instanzen unterschiedlich zuweist:
- Bei Instanzen mit 1.000 Verarbeitungseinheiten (1 Knoten) und kleiner weist Spanner Serverressourcen in einer einzelnen Serveraufgabe pro Zone zu.
- Bei Instanzen, die größer als 1.000 Verarbeitungseinheiten (1 Knoten) sind, weist Spanner Serverressourcen in mehreren Serveraufgaben pro Zone zu, mit einer Aufgabe pro 1.000 Verarbeitungseinheiten. Die Verwendung mehrerer Serveraufgaben pro Zone bietet eine bessere Leistung und ermöglicht es Spanner, Datenbank-Splits zu erstellen und eine noch bessere Leistung zu erzielen.
Rechenkapazität ändern
Nachdem Sie eine Instanz erstellt haben, können Sie ihre Rechenkapazität erhöhen. In den meisten Fällen werden Anfragen innerhalb weniger Minuten bearbeitet. In seltenen Fällen kann es bis zu einer Stunde dauern, bis eine Skalierung abgeschlossen ist.
Sie können die Rechenkapazität einer Spanner-Instanz reduzieren, außer in den folgenden Fällen:
Sie können nicht mehr als 10 TiB Daten pro Knoten (1.000 Verarbeitungseinheiten) speichern.
Es gibt eine große Anzahl von Splits für die Daten der Instanz. In diesem Szenario kann Spanner die Splits möglicherweise nicht verwalten, nachdem Sie die Rechenkapazität reduziert haben. Sie können versuchen, die Rechenkapazität schrittweise um kleinere Werte zu reduzieren, bis Sie die Mindestkapazität herausfinden, die Spanner zum Verwalten aller Splits der Instanz benötigt.
Spanner kann eine große Anzahl von Splits erstellen, um Ihren Nutzungsmustern gerecht zu werden. Wenn sich Ihre Nutzungsmuster ändern, kann Spanner nach ein oder zwei Wochen einige Splits zusammenführen und Sie können versuchen, die Rechenkapazität der Instanz zu reduzieren.
Beobachten Sie beim Entfernen von Rechenkapazität die CPU-Auslastung und die Anfragelatenzen in Cloud Monitoring, damit die CPU-Auslastung bei regionalen Instanzen unter 65% und bei Instanzen mit mehreren Regionen bei jeder Region unter 45% liegt. Beim Entfernen von Rechenkapazität kann es vorübergehend zu einer Anfragelatenz kommen.
Spanner hat keinen Sperrmodus. Die Rechenkapazität von Spanner ist eine dedizierte Ressource. Auch wenn keine Arbeitslast ausgeführt wird, führt Spanner häufig Hintergrundaufgaben zur Optimierung und zum Schutz Ihrer Daten aus.
Sie können die Rechenkapazität über die Google Cloud Console, die Google Cloud CLI oder die Spanner-Clientbibliotheken ändern. Weitere Informationen finden Sie unter Rechenkapazität ändern.
Rechenkapazität im Vergleich zu Replikaten
Wenn Sie die Server- und Speicherressourcen in Ihrer Instanz vertikal skalieren müssen, erhöhen Sie die Rechenkapazität der Instanz. Beachten Sie, dass die Erhöhung der Rechenkapazität nicht zu einer Erhöhung der Anzahl an Replikaten führt, da diese für eine bestimmte Instanzkonfiguration festgelegt sind. Stattdessen wird die Anzahl der Ressourcen erhöht, die jedem Replikat in der Instanz zur Verfügung stehen. Durch Erhöhen der Rechenkapazität erhält jedes Replikat mehr CPU und Arbeitsspeicher, wodurch der Durchsatz des Replikats erhöht wird. Das heißt, dass pro Sekunde mehr Lese- und Schreibvorgänge ausgeführt werden können.