Auf dieser Seite werden Produktionskontingente und -limits für Spanner beschrieben. Die Begriffe „Kontingente“ und „Limits“ werden in der Google Cloud Console möglicherweise synonym verwendet.
Die Werte für Kontingente und Limits können sich ändern.
Berechtigungen zum Prüfen und Bearbeiten von Kontingenten
Zum Aufrufen Ihrer Kontingente benötigen Sie die IAM-Berechtigung (Identity and Access Management) serviceusage.quotas.get.
Um Ihre Kontingente zu ändern, ist die IAM-Berechtigung serviceusage.quotas.update erforderlich. Diese ist standardmäßig in den vordefinierten Rollen Owner, Editor und Quota Administrator enthalten.
Diese Berechtigungen sind standardmäßig in den einfachen IAM-Rollen „Owner“ und „Editor“ sowie in der vordefinierten Rolle „Quota Administrator“ enthalten.
Kontingente prüfen
Die aktuell gültigen Kontingente für Ressourcen in Ihrem Projekt finden Sie in derGoogle Cloud Console:
Kontingente erhöhen
Bei einer intensiveren Nutzung von Spanner können Ihre Kontingente entsprechend erweitert werden. Wenn Sie eine deutlich höhere Nutzung erwarten, empfehlen wir Ihnen, schon einige Tage vorher entsprechend höhere Kontingente anzufordern.
Möglicherweise müssen Sie auch die Überschreibung des Nutzerkontingents erhöhen. Weitere Informationen finden Sie unter Überschreibung des Nutzerkontingents erstellen.
Sie können das aktuelle Knotenlimit für die Spanner-Instanzkonfiguration über die Google Cloud Console erhöhen.
Rufen Sie die Seite Kontingente auf.
Wählen Sie in der Drop-down-Liste Dienst die Option Spanner API aus.
Wenn Sie die Spanner API nicht sehen, wurde sie nicht aktiviert. Weitere Informationen finden Sie unter APIs aktivieren.
Wählen Sie die Kontingente aus, die Sie ändern möchten.
Klicken Sie auf Kontingente bearbeiten.
Geben Sie im angezeigten Bereich Kontingentänderungen Ihr neues Kontingentlimit ein.
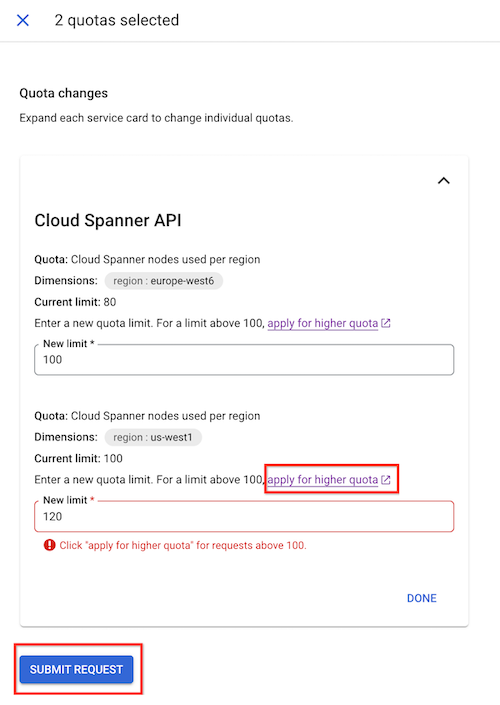
Klicken Sie auf Fertig und dann auf Anfrage senden.
Wenn Sie Ihr Knotenlimit nicht manuell auf das gewünschte Limit erhöhen können, klicken Sie auf Höheres Kontingent beantragen. Füllen Sie das Formular aus, um eine Anfrage an das Spanner-Team zu senden. Sie erhalten innerhalb von 48 Stunden nach Ihrer Anfrage eine Antwort.
Kontingent für eine benutzerdefinierte Instanzkonfiguration erhöhen
Sie können das Knotenkontingent für Ihre benutzerdefinierte Instanzkonfiguration erhöhen.
Prüfen Sie das Knotenlimit einer benutzerdefinierten Instanzkonfiguration, indem Sie das Knotenlimit der Basisinstanzkonfiguration prüfen.
Verwenden Sie den Befehl show instance configurations detail, wenn Sie die Basiskonfiguration Ihrer benutzerdefinierten Instanzkonfiguration nicht kennen oder sich nicht daran erinnern.
Wenn das für Ihre benutzerdefinierte Instanzkonfiguration erforderliche Knotenlimit weniger als 85 beträgt, folgen Sie der Anleitung im vorherigen Abschnitt Kontingente erhöhen. Erhöhen Sie das Knotenlimit der Basisinstanzkonfiguration, die mit Ihrer benutzerdefinierten Instanzkonfiguration verknüpft ist, über die Google Cloud Console.
Wenn das für Ihre benutzerdefinierte Instanzkonfiguration erforderliche Knotenlimit mehr als 85 beträgt, füllen Sie das Formular zum Anfordern einer Kontingenterhöhung für Ihre Spanner-Knoten aus. Geben Sie die ID Ihrer benutzerdefinierten Instanzkonfiguration im Formular an.
Knotenlimits
| Wert | Limit |
|---|---|
| Knoten pro Instanzkonfiguration |
Die Standardlimits variieren je nach Projekt- und Instanzkonfiguration. Informationen zum Ändern von Projektkontingentlimits oder zum Anfordern einer Limiterhöhung finden Sie unter Kontingente erhöhen. |
Instanzlimits
| Wert | Limit |
|---|---|
| Länge der Instanz-ID | 2 bis 64 Zeichen |
Limits für Instanzen im kostenlosen Testzeitraum
Für eine kostenlose Spanner-Testinstanz gelten die folgenden zusätzlichen Limits. Wenn Sie diese Limits erhöhen oder entfernen möchten, führen Sie ein Upgrade Ihrer Testinstanz auf eine kostenpflichtige Instanz durch.
| Wert | Limit |
|---|---|
| Speicherkapazität | 10 GiB |
| Datenbanklimit | Bis zu fünf Datenbanken erstellen |
| Nicht unterstützte Funktionen | Sichern und wiederherstellen |
| SLA | Kein SLA |
| Dauer des Testzeitraums | 90‑tägiger kostenloser Testzeitraum |
Beschränkungen für die Geopartitionierung
| Wert | Limit |
|---|---|
| Maximale Anzahl von Partitionen pro Instanz | 20 |
| Maximale Anzahl von Platzierungen pro Datenbank | 50 |
| Maximale Anzahl von Platzierungszeilen pro Knoten in Ihrer Partition | 100 Millionen |
Limits für gespeicherte Abfragen
| Wert | Limit |
|---|---|
| Maximale Anzahl gespeicherter Abfragen pro Projekt (einschließlich gespeicherter Abfragen für andere Google Cloud -Produkte) | 10.000 |
| Maximale Größe für jede Anfrage | 1 MiB |
Limits für die Instanzkonfiguration
| Wert | Limit |
|---|---|
| Maximale Anzahl benutzerdefinierter Instanzkonfigurationen pro Projekt | 100 |
| Länge der benutzerdefinierten Instanzkonfigurations-ID | 8 bis 64 Zeichen Eine benutzerdefinierte Instanzkonfigurations-ID muss mit |
Datenbanklimits
| Wert | Limit |
|---|---|
| Datenbanken pro Instanz |
|
| Rollen pro Datenbank | 100 |
| Länge der Datenbank-ID | 2 bis 30 Zeichen |
| Speichergröße1 |
In den meisten regionalen, biregionalen und multiregionalen Spanner-Instanzkonfigurationen ist eine erhöhte Speicherkapazität von 10 TiB pro Knoten verfügbar. Weitere Informationen finden Sie unter Leistungs- und Speicherverbesserungen. Wenn Sie mehrstufigen Speicher verwenden, können Sie einen kombinierten Speicher (SSD und HDD) mit bis zu 10 TiB pro Knoten verwenden. Sicherungen werden separat gespeichert und nicht auf dieses Limit angerechnet. Weitere Informationen finden Sie unter Messwerte zur Speicherauslastung. Hinweis: In Spanner wird der tatsächlich genutzte Speicherplatz in einer Instanz in Rechnung gestellt, nicht der insgesamt verfügbare Speicherplatz. |
Limits für Sicherung und Wiederherstellung
| Wert | Limit |
|---|---|
| Anzahl der laufenden Vorgänge zum Erstellen von Sicherungen pro Datenbank | 1 |
| Anzahl der laufenden Vorgänge zum Wiederherstellen von Datenbanken pro Instanz (in der Instanz der wiederhergestellten Datenbank, nicht der Sicherung) | 10 |
| Maximale Aufbewahrungsdauer für Sicherungen | 1 Jahr (einschließlich des zusätzlichen Tages in Schaltjahren) |
Schemalimits
Schemaobjekte
| Wert | Limit |
|---|---|
| Die Gesamtzahl der Schemaobjekte in allen Datenbanken in derselben Instanz | Die Standardlimits variieren je nach Instanzkonfiguration2 |
DDL-Anweisungen
| Wert | Limit |
|---|---|
| Größe der DDL-Anweisung für eine einzelne Schemaänderung | 10 MiB |
Größe der DDL-Anweisung für das gesamte Schema einer Datenbank, wie von GetDatabaseDdl zurückgegeben |
10 MiB |
Grafiken
| Wert | Limit |
|---|---|
| Attributgrafiken pro Datenbank | 16 |
| Länge des Namens der Attributgrafik | 1 bis 128 Zeichen |
Tabellen
| Wert | Limit |
|---|---|
| Tabellen pro Datenbank | 5.000 |
| Länge des Tabellennamens | 1 bis 128 Zeichen |
| Spalten pro Tabelle | 1.024 |
| Länge des Spaltennamens | 1 bis 128 Zeichen |
| Maximale Datengröße pro Zelle | 10 MiB |
Größe einer STRING-Zelle |
2.621.440 Unicode-Zeichen |
| Anzahl der Spalten in einem Tabellenschlüssel | 16 Schließt Schlüsselspalten ein, die für eine übergeordnete Tabelle freigegeben sind |
| Tabellen-Verschachtelungstiefe | 7 Eine Tabelle der obersten Ebene mit untergeordneten Tabellen hat die Tiefe 1. Eine Tabelle der obersten Ebene mit um zwei Ebenen untergeordneten Tabellen hat die Tiefe 2. Bei weiteren verschachtelten Tabellen erhöht sich die Tiefe entsprechend. |
| Maximale Größe eines Primärschlüssels oder Indexschlüssels pro Zeile | 8 KiB Beinhaltet die Größe aller Spalten, aus denen der Schlüssel besteht |
| Gesamtgröße der Nicht-Schlüsselspalten pro Zeile | 1.600 MiB Beinhaltet die Größe aller Nicht-Schlüsselspalten pro Zeile für eine Tabelle |
Indexe
| Wert | Limit |
|---|---|
| Indexe pro Datenbank | 10.000 |
| Indexe pro Tabelle | 128 |
| Länge des Indexnamens | 1 bis 128 Zeichen |
| Anzahl der Spalten in einem Indexschlüssel | 16 Die Anzahl der indexierten Spalten (außer für STORING-Spalten) plus der Anzahl der primären Schlüsselspalten in der Basistabelle |
Ansichten
| Wert | Limit |
|---|---|
| Ansichten pro Datenbank | 5.000 |
| Länge des Namens aufrufen | 1 bis 128 Zeichen |
| Verschachtelungstiefe | 10 Eine Ansicht, die auf eine andere Ansicht verweist, hat eine Verschachtelungstiefe 1. Eine Ansicht, die auf eine andere Ansicht verweist, die auf eine andere Ansicht verweist, hat eine Verschachtelungstiefe 2 usw. |
Standortgruppen
| Wert | Limit |
|---|---|
| Maximale Anzahl von Standortgruppen pro Datenbank | 16 (1 Standardgruppe für Standorte und 15 optionale zusätzliche Standortgruppen) |
Mindestzeit für die Option „ssd_to_hdd_spill_timespan“ |
1 Stunde |
Maximal zulässige Zeit für die Option „ssd_to_hdd_spill_timespan“ |
365 Tage |
Abfragelimits
| Wert | Limit |
|---|---|
Spalten in einer GROUP BY-Anweisung |
1.000 |
Werte in einem IN-Operator |
10.000 |
| Funktionsaufrufe | 1.000 |
| Joins | 20 |
| Verschachtelte Funktionsaufrufe | 75 |
Verschachtelte GROUP BY-Klauseln |
35 |
| Verschachtelte Unterabfrageausdrücke | 25 |
| Verschachtelte Subselect-Anweisungen | 60 |
| Joins, die durch Abfrage eines Graph erstellt werden | 100 |
| Parameter | 950 |
| Länge der Abfrageanweisung | 1 Million Zeichen |
STRUCT Felder |
1.000 |
| Untergeordnete Unterabfrageausdrücke | 50 |
| Unions in einer Abfrage | 200 |
| Tiefe des quantifizierten Pfad-Durchlaufs | 100 |
Limits beim Erstellen, Lesen, Aktualisieren und Löschen von Daten
| Wert | Limit |
|---|---|
| Commit-Größe (einschließlich Indexe und Änderungsstreams) | 100 MiB |
| Gleichzeitige Lesevorgänge pro Sitzung | 100 |
| Mutationen pro Commit (einschließlich Indexe)3 | 80.000 |
| Mutationen pro Mutationsgruppe in einer Batch-Schreibanfrage | 80.000 |
| Gleichzeitige partitionierte DML-Anweisungen pro Datenbank | 20.000 |
Administrative Limits
| Wert | Limit |
|---|---|
| Anfragegröße bei administrativen Aktionen4 | 1 MiB |
| Ratenbegrenzung für administrative Aktionen5 | 5 pro Sekunde, Projekt und Nutzer (gemittelt über 100 Sekunden) |
Anfragelimits
| Wert | Limit |
|---|---|
| Anfragegröße außer Commits6 | 10 MiB |
Limits für Änderungsstreams
| Wert | Limit |
|---|---|
| Änderungsstreams pro Datenbank | 10 |
| Änderungsstreams, die eine beliebige Nicht-Schlüsselspalte überwachen7 | 3 |
| Gleichzeitige Leser pro Änderungsstream-Datenpartition8 | 20 |
Data Boost-Limits
| Wert | Limit |
|---|---|
| Gleichzeitige Data Boost-Anfragen pro Projekt in us-central1 | 1000 9 |
| Gleichzeitige Data Boost-Anfragen pro Projekt und Region in anderen Regionen | 400 9 |
API-Limits vor der Aufteilung
| Wert | Limit |
|---|---|
| Pro API-Anfrage hinzugefügte Aufteilungspunkte | 100 |
| API-Anfragegröße für Aufteilungspunkt | 1 MiB |
| Pro Knoten hinzugefügte Aufteilungspunkte für alle Datenbanken in der Instanz | 50 |
| Pro Knoten und Minute hinzugefügte oder aktualisierte Aufteilungspunkte | 10 |
| Pro Tag und Knoten hinzugefügte oder aktualisierte Aufteilungspunkte | 200 |
Hinweise
1. Um beim Zugriff auf eine Datenbank Hochverfügbarkeit und niedrige Latenz zu bieten, definiert Spanner Speicherlimits basierend auf der Rechenkapazität der Instanz:
- Bei Instanzen, die kleiner als 1 Knoten (1.000 Verarbeitungseinheiten) sind, weist Spanner jeweils 1.024,0 GiB Daten pro 100 Verarbeitungseinheiten in der Datenbank zu.
- Bei Instanzen, die mindestens eine Größe von einem Knoten haben, weist Spanner für jeden Knoten 10 TiB Daten zu.
Wenn Sie beispielsweise eine Instanz für eine 1500 GiB große Datenbank erstellen möchten, müssen Sie die Rechenkapazität auf 200 Verarbeitungseinheiten festlegen. Mit dieser Rechenkapazität bleibt die Instanz unter dem Limit, bis die Datenbank größer als 2.048,0 GiB ist. Bei Erreichen dieser Größe müssen Sie jedoch weitere 100 Verarbeitungseinheiten hinzufügen, damit die Datenbank kontinuierlich wachsen kann. Andernfalls werden Schreibvorgänge in die Datenbank möglicherweise abgelehnt. Weitere Informationen finden Sie unter Empfehlungen für die Datenbankspeicherauslastung.
Fügen Sie Rechenkapazität hinzu, bevor das Limit für Ihre Datenbank erreicht wird.
2. Zu den berücksichtigten Schemaobjekten gehören alle in DDL beschriebenen Objekttypen wie Tabellen, Spalten, Indexe, Sequenzen usw. Das Limit für Schemaobjekte wird auf Instanzebene durchgesetzt und hängt von den für Ihre Instanz verfügbaren Verarbeitungseinheiten ab.
- Bei Instanzen mit mindestens einem Knoten liegt das Standardlimit bei einer Million Objekten.
- Bei Instanzen, die kleiner als ein Knoten (1.000 Verarbeitungseinheiten) sind, sinkt das Limit proportional zur Größe der Instanz. Das Limit liegt beispielsweise bei 100.000 Schemaobjekten für Instanzen mit 100 Verarbeitungseinheiten.
Wenn Sie die Anzahl der Schemaobjekte für Ihre Datenbanken und das Objektlimit für Ihre Instanz prüfen möchten, suchen Sie im Metrics Explorer nach den Messwerten spanner.googleapis.com/instance/schema_objects und spanner.googleapis.com/instance/schema_object_count.
Weitere Informationen zum Monitoring finden Sie unter Instanzen mit Cloud Monitoring überwachen.
Wenn Sie das Limit erreichen, verhindert Spanner Vorgänge, die Sie das Limit überschreiten lassen. Dazu gehören:
- Ändern des Datenbankschemas (z. B. Hinzufügen eines Index).
- Erstellen einer neuen Datenbank in der Instanz.
- Eine Datenbank aus einer Sicherung in derselben Instanz wiederherstellen. In diesem Fall können Sie die Sicherung in einer anderen Instanz mit derselben Konfiguration wiederherstellen oder eine neue Instanz mit derselben Konfiguration erstellen und die Sicherung in der neuen Instanz wiederherstellen.
3. Einfüge- und Aktualisierungsvorgänge werden nach der Vielzahl der Spalten gezählt, die sie beeinflussen. Primärschlüsselspalten sind immer betroffen. Das Einfügen eines neuen Eintrags kann als fünf Mutationen zählen, wenn Werte in fünf Spalten eingefügt werden. Das Aktualisieren von drei Spalten in einem Eintrag kann auch als fünf Mutationen zählen, wenn der Datensatz zwei Primärschlüsselspalten enthält. Lösch- und Bereichslöschvorgänge zählen als eine Mutation, unabhängig von der Anzahl der betroffenen Spalten.
Ebenso zählt das Löschen einer Zeile aus einer übergeordneten Tabelle mit der Anmerkung ON DELETE
CASCADE als eine Mutation, unabhängig von der Anzahl der verschachtelten untergeordneten Zeilen. Eine Ausnahme gibt es dann, wenn für zu löschende Zeilen Sekundärindexe definiert sind. Die Änderungen an den Sekundärindexen werden dann einzeln gezählt. Wenn es für eine Tabelle beispielsweise zwei Sekundärindexe gibt, zählt das Löschen eines Bereichs von Zeilen in der Tabelle als eine Mutation für die Tabelle plus zwei Mutationen für jede gelöschte Zeile, weil die Zeilen im Sekundärindex über den Schlüsselbereich verteilt sein könnten. Dadurch ist es für Spanner unmöglich, einen einzelnen „Bereich löschen“-Vorgang für die Sekundärindexe aufzurufen. Sekundärindexe beinhalten die Sicherungsindexe für Fremdschlüssel.
Informationen zum Ermitteln der Anzahl der Mutationen für eine Transaktion finden Sie unter Commit-Statistiken für eine Transaktion abrufen.
Durch Änderungsstreams werden keine Mutationen hinzugefügt, die auf dieses Limit angerechnet werden.
4. Das Limit für Anfragen nach administrativen Aktionen betrifft keine Commits, in Anmerkung 9 aufgelisteten Anfragen oder Schemaänderungen.
5. Diese Ratenbegrenzung gilt für alle Aufrufe der Admin API, also auch solche zum Aufrufen von Vorgängen mit langer Ausführungszeit für eine Instanz, Datenbank oder Sicherung.
6. Dieses Limit umfasst folgende Anfragen: Erstellen einer Datenbank, Aktualisieren einer Datenbank, Lesen, Streamen von Lesevorgängen, Ausführen von SQL-Abfragen und Ausführen von Streaming-SQL-Abfragen.
7. Ein Änderungsstream, der eine ganze Tabelle oder Datenbank überwacht, überwacht implizit jede Spalte in dieser Tabelle oder Datenbank und wird daher auf dieses Limit angerechnet.
8. Dieses Limit gilt für gleichzeitige Leser derselben Änderungsstream-Partition, unabhängig davon, ob es sich um Dataflow-Pipelines oder direkte API-Abfragen handelt.
9. Die Standardlimits variieren je nach Projekt und Region. Weitere Informationen finden Sie unter Data Boost-Kontingentnutzung überwachen und verwalten.