Ce tutoriel explique comment réduire les coûts en déployant un autoscaler planifié sur Google Kubernetes Engine (GKE). Ce type d'autoscaler effectue un scaling des clusters à la hausse ou à la baisse selon une planification basée sur l'heure de la journée ou le jour de la semaine. Un autoscaler planifié est utile si le flux d'activité de votre trafic est prévisible (par exemple, si vous êtes un revendeur régional ou si votre logiciel est destiné aux employés dont les heures de travail sont limitées à une partie spécifique de la journée).
Ce tutoriel s'adresse aux développeurs et aux opérateurs qui souhaitent augmenter de manière fiable la capacité des clusters avant l'arrivée des pics, puis la réduire à nouveau pour limiter les coûts la nuit, le week-end ou à tout autre moment où moins d'utilisateurs sont connectés. Dans cet article, nous partons du principe que vous maîtrisez Docker, Kubernetes, les tâches Cron de Kubernetes, GKE et Linux.
Introduction
De nombreuses applications connaissent des schémas de trafic inégaux. Par exemple, les employés d'une entreprise interagissent peut-être avec une application uniquement pendant la journée. Par conséquent, les serveurs de centres de données pour cette application sont inactifs la nuit.
Au-delà d'autres avantages, Google Cloud peut vous permettre d'économiser de l'argent en allouant l'infrastructure de manière dynamique en fonction de la charge du trafic. Dans certains cas, une configuration d'autoscaling simple peut répondre au défi d'allocation de trafic non uniforme. Si tel est le cas, conservez cette configuration. Toutefois, dans d'autres cas, des changements brusques des schémas de trafic nécessitent des configurations d'autoscaling plus précises afin d'éviter une instabilité du système lors du scaling à la hausse et le surprovisionnement du cluster.
Ce tutoriel se concentre sur les scénarios dans lesquels les changements brusques des modèles de trafic sont bien compris, et où vous souhaitez prévenir l'autoscaler que votre infrastructure est sur le point de rencontrer des pics. Ce document explique comment effectuer un scaling à la hausse des clusters GKE le matin et un scaling à la baisse la nuit. Cependant, vous pouvez utiliser une approche similaire pour augmenter et diminuer la capacité pour des événements connus, tels que des événements de grande envergure, des campagnes publicitaires ou le trafic du week-end.
Effectuer un scaling à la baisse d'un cluster si vous avez des remises sur engagement d'utilisation
Ce tutoriel explique comment réduire les coûts en effectuant un scaling à la baisse de vos clusters GKE à la valeur minimale pendant les heures creuses. Toutefois, si vous avez souscrit une remise sur engagement d'utilisation, il est important de comprendre comment ces remises fonctionnent conjointement avec l'autoscaling.
Les contrats d'engagement d'utilisation vous offrent des prix très réduits lorsque vous vous engagez à payer pour une quantité définie de ressources (processeurs virtuels, mémoire et autres). Toutefois, pour déterminer la quantité de ressources sur laquelle s'engager, vous devez savoir à l'avance le volume de ressources utilisé par vos charges de travail au fil du temps. Pour vous aider à réduire vos coûts, le diagramme suivant illustre les ressources que vous devez et ne devriez pas inclure dans votre planification.

Comme le montre le schéma, l'allocation des ressources dans le cadre d'un contrat d'engagement d'utilisation reste la même. Les ressources couvertes par le contrat doivent être utilisées la plupart du temps pour que l'engagement que vous avez souscrit soit rentable. Par conséquent, vous ne devez pas inclure les ressources utilisées lors des pics pour calculer les ressources à inclure dans l'engagement. Pour les ressources utilisées lors des pics, nous vous recommandons d'utiliser les options de l'autoscaler GKE. Ces options incluent l'autoscaler planifié décrit dans ce document ou d'autres options gérées qui sont présentées dans la section Bonnes pratiques pour l'exécution d'applications Kubernetes à coût maîtrisé sur GKE.
Si vous avez déjà un contrat d'engagement d'utilisation pour une quantité donnée de ressources, vous ne réduisez pas vos coûts en effectuant un scaling à la baisse de votre cluster en dessous de ce seuil minimum. Dans de tels scénarios, nous vous recommandons d'essayer de planifier certaines tâches pour combler les écarts pendant les périodes de faible demande de calcul.
Architecture
Le schéma suivant illustre l'architecture de l'infrastructure et de l'autoscaler planifié que vous allez déployer dans ce tutoriel. Cet autoscaler planifié se compose d'un ensemble de composants qui fonctionnent ensemble pour gérer le scaling en fonction d'un programme.

Dans cette architecture, un ensemble de CronJobs Kubernetes exporte des informations connues sur les modèles de trafic vers une métrique personnalisée Cloud Monitoring. Ces données sont ensuite lues par un autoscaler horizontal de pods (HPA) Kubernetes en tant qu'entrée lorsque le HPA doit faire évoluer votre charge de travail. En plus des autres métriques de chargement, telles que l'utilisation du processeur cible, le HPA décide de la manière de faire évoluer les instances dupliquées pour un déploiement donné.
Objectifs
- Créer un cluster GKE
- Déployer un exemple d'application qui utilise un HPA Kubernetes
- Configurer les composants de l'autoscaler planifié, puis mettre à jour votre HPA pour pouvoir le lire à partir d'une métrique personnalisée planifiée
- Configurer une alerte pour qu'elle se déclenche lorsque l'autoscaler planifié ne fonctionne pas correctement
- Générer une charge dans l'application
- Examiner comment le HPA réagit aux augmentations normales du trafic et aux métriques personnalisées planifiées que vous configurez
Le code de ce tutoriel est disponible dans un dépôt GitHub.
Coûts
Dans ce document, vous utilisez les composants facturables de Google Cloudsuivants :
Vous pouvez obtenir une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the GKE, Artifact Registry and the Cloud Monitoring APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the GKE, Artifact Registry and the Cloud Monitoring APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Préparer votre environnement
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Dans Cloud Shell, configurez l'ID de votre projet Google Cloud , votre adresse e-mail, ainsi que votre zone de calcul et votre région :
PROJECT_ID=YOUR_PROJECT_ID ALERT_EMAIL=YOUR_EMAIL_ADDRESS gcloud config set project $PROJECT_ID gcloud config set compute/region us-central1 gcloud config set compute/zone us-central1-fRemplacez les éléments suivants :
YOUR_PROJECT_ID: nom de projet Google Cloud du projet que vous utilisez.YOUR_EMAIL_ADDRESS: adresse e-mail pour recevoir des notifications lorsque l'autoscaler planifié ne fonctionne pas correctement.
Si vous le souhaitez, vous pouvez choisir une région et une zone différentes pour ce tutoriel.
Clonez le dépôt GitHub
kubernetes-engine-samples:git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples/ cd kubernetes-engine-samples/cost-optimization/gke-scheduled-autoscalerLe code de cet exemple est structuré avec les dossiers suivants :
- Racine : contient le code utilisé par les tâches cron pour exporter des métriques personnalisées vers Cloud Monitoring.
k8s/: contient un exemple de déploiement comportant un HPA Kubernetes.k8s/scheduled-autoscaler/: contient les tâches cron qui exportent une métrique personnalisée et une version mise à jour du HPA pour lire une métrique personnalisée.k8s/load-generator/: contient un déploiement Kubernetes comportant une application pour simuler une utilisation horaire. Un déploiement est un objet de l'API Kubernetes qui vous permet d'exécuter plusieurs instances dupliquées de pods répartis entre les nœuds d'un cluster.monitoring/: contient les composants Cloud Monitoring que vous configurez dans ce tutoriel.
Dans Cloud Shell, créez un cluster GKE pour exécuter l'autoscaler planifié :
gcloud container clusters create scheduled-autoscaler \ --enable-ip-alias \ --release-channel=stable \ --machine-type=e2-standard-2 \ --enable-autoscaling --min-nodes=1 --max-nodes=10 \ --num-nodes=1 \ --autoscaling-profile=optimize-utilizationLe résultat ressemble à ce qui suit :
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS scheduled-autoscaler us-central1-f 1.22.15-gke.100 34.69.187.253 e2-standard-2 1.22.15-gke.100 1 RUNNINGIl ne s'agit pas d'une configuration de production, mais d'une configuration adaptée à ce tutoriel. Dans cette configuration, vous configurez l'autoscaler de cluster avec un minimum de un nœud et un maximum de 10 nœuds. Vous activez également le profil
optimize-utilizationpour accélérer le processus de scaling à la baisse.Déployez l'exemple d'application sans l'autoscaler planifié :
kubectl apply -f ./k8sOuvrez le fichier
k8s/hpa-example.yaml.La liste suivante indique le contenu du fichier.
Notez que le nombre minimal d'instances dupliquées (
minReplicas) est défini sur 10. Cette configuration définit également le cluster à faire évoluer en fonction de l'utilisation du processeur (paramètresname: cpuettype: Utilization).Attendez que l'application soit disponible :
kubectl wait --for=condition=available --timeout=600s deployment/php-apache EXTERNAL_IP='' while [ -z $EXTERNAL_IP ] do EXTERNAL_IP=$(kubectl get svc php-apache -o jsonpath={.status.loadBalancer.ingress[0].ip}) [ -z $EXTERNAL_IP ] && sleep 10 done curl -w '\n' http://$EXTERNAL_IPLorsque l'application est disponible, le résultat est le suivant :
OK!Vérifiez les paramètres :
kubectl get hpa php-apacheLe résultat ressemble à ce qui suit :
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 9%/60% 10 20 10 6d19hLa colonne
REPLICASaffiche la valeur10, qui correspond à la valeur du champminReplicasdu fichierhpa-example.yaml.Vérifiez si le nombre de nœuds est passé à 4 :
kubectl get nodesLe résultat ressemble à ce qui suit :
NAME STATUS ROLES AGE VERSION gke-scheduled-autoscaler-default-pool-64c02c0b-9kbt Ready <none> 21S v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-ghfr Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-gvl9 Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-t9sr Ready <none> 21s v1.17.9-gke.1504Lors de la création du cluster, vous avez défini une configuration minimale à l'aide de l'option
min-nodes=1. Toutefois, l'application que vous avez déployée au début de cette procédure demande une infrastructure supplémentaire, carminReplicasdans le fichierhpa-example.yamlest défini sur 10.Définir
minReplicassur une valeur telle que 10 est une stratégie courante utilisée par des entreprises comme les points de vente, qui s'attendent à une augmentation soudaine du trafic dans les premières heures d'un jour ouvré. Toutefois, la définition de valeurs élevées pour l'HPAminReplicaspeut augmenter vos coûts, car le cluster ne peut pas se réduire, pas même la nuit lorsque le trafic de l'application est faible.Dans Cloud Shell, installez l'adaptateur Cloud Monitoring – Métriques personnalisées dans votre cluster GKE :
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml kubectl wait --for=condition=available --timeout=600s deployment/custom-metrics-stackdriver-adapter -n custom-metricsCet adaptateur active l'autoscaling des pods en fonction des métriques personnalisées de Cloud Monitoring.
Créez un dépôt dans Artifact Registry et accordez des autorisations de lecture :
gcloud artifacts repositories create gke-scheduled-autoscaler \ --repository-format=docker --location=us-central1 gcloud auth configure-docker us-central1-docker.pkg.dev gcloud artifacts repositories add-iam-policy-binding gke-scheduled-autoscaler \ --location=us-central1 --member=allUsers --role=roles/artifactregistry.readerCréez et transférez le code de l'exportateur de métriques personnalisées :
docker build -t us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporter . docker push us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporterDéployez les tâches cron qui exportent des métriques personnalisées et déployez la version mise à jour du HPA qui lit ces métriques personnalisées :
sed -i.bak s/PROJECT_ID/$PROJECT_ID/g ./k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml kubectl apply -f ./k8s/scheduled-autoscalerOuvrez et examinez le fichier
k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml.La liste suivante indique le contenu du fichier.
Cette configuration spécifie que les tâches cron doivent exporter le nombre suggéré de pods dupliqués vers une métrique personnalisée appelée
custom.googleapis.com/scheduled_autoscaler_exampleen fonction de l'heure de la journée. Pour faciliter la section de surveillance de ce tutoriel, la configuration du champ de planification définit les scalings à la hausse et les scalings à la baisse toutes les heures. Pour la production, vous pouvez personnaliser ce programme pour répondre aux besoins de votre entreprise.Ouvrez et examinez le fichier
k8s/scheduled-autoscaler/hpa-example.yaml.La liste suivante indique le contenu du fichier.
Cette configuration spécifie que l'objet HPA doit remplacer le HPA déployé précédemment. Notez que la configuration réduit la valeur de
minReplicasà 1. Cela signifie que la charge de travail peut être réduite à sa valeur minimale. La configuration ajoute également une métrique externe (type: External). Cela signifie que l'autoscaling est désormais déclenché par deux facteurs.Dans ce scénario comportant plusieurs métriques, le HPA calcule un nombre d'instances dupliquées proposé pour chaque métrique, puis choisit la métrique qui renvoie la valeur la plus élevée. Il est important de comprendre que l'autoscaler planifié peut proposer qu'à un moment donné, le nombre de pods doive être égal à 1. Toutefois, si l'utilisation réelle du processeur est supérieure à ce qui est prévu pour un pod, le HPA crée davantage d'instances dupliquées.
Vérifiez à nouveau le nombre de nœuds et d'instances dupliquées HPA en exécutant une nouvelle fois chacune des commandes suivantes :
kubectl get nodes kubectl get hpa php-apacheLe résultat affiché dépend de ce que l'autoscaler planifié a récemment effectué. En particulier, les valeurs de
minReplicaset denodesseront différentes à certains moments du cycle de scaling.Par exemple, environ de la 51e à la 60e minute de chaque heure (ce qui représente une période de pic de trafic), la valeur HPA pour
minReplicasest 10 et celle denodesest de 4.Par opposition, pour les minutes 1 à 50 (ce qui représente une période de trafic plus faible), la valeur HPA
minReplicasest 1 et la valeurnodessera 1 ou 2, selon le nombre de pods qui ont été alloués et supprimés. Pour les valeurs inférieures (minutes 1 à 50), le scaling à la baisse du cluster peut prendre jusqu'à 10 minutes.Dans Cloud Shell, créez un canal de notification :
gcloud beta monitoring channels create \ --display-name="Scheduled Autoscaler team (Primary)" \ --description="Primary contact method for the Scheduled Autoscaler team lead" \ --type=email \ --channel-labels=email_address=${ALERT_EMAIL}Le résultat ressemble à ce qui suit :
Created notification channel NOTIFICATION_CHANNEL_ID.Cette commande crée un canal de notification de type
emailpour simplifier les étapes du tutoriel. Dans les environnements de production, nous vous recommandons d'utiliser une stratégie moins asynchrone en définissant le canal de notification sursmsoupagerduty.Définissez une variable dont la valeur est celle qui a été affichée dans l'espace réservé
NOTIFICATION_CHANNEL_ID:NOTIFICATION_CHANNEL_ID=NOTIFICATION_CHANNEL_IDDéployez la règle d'alerte :
gcloud alpha monitoring policies create \ --policy-from-file=./monitoring/alert-policy.yaml \ --notification-channels=$NOTIFICATION_CHANNEL_IDLe fichier
alert-policy.yamlcontient la spécification permettant d'envoyer une alerte si la métrique est absente après cinq minutes.Accédez à la page Alertes de Cloud Monitoring pour afficher la règle d'alerte.
Cliquez sur Scheduled Autoscaler Policy (Règle d'autoscaler planifié) et vérifiez les détails de la règle d'alerte.
Dans Cloud Shell, déployez le générateur de charge :
kubectl apply -f ./k8s/load-generatorLa liste suivante affiche le script
load-generator:command: ["/bin/sh", "-c"] args: - while true; do RESP=$(wget -q -O- http://php-apache.default.svc.cluster.local); echo "$(date +%H)=$RESP"; sleep $(date +%H | awk '{ print "s("$0"/3*a(1))*0.5+0.5" }' | bc -l); done;Ce script s'exécute dans votre cluster jusqu'à ce que vous supprimiez le déploiement
load-generator. Des requêtes sont envoyées à votre servicephp-apachetoutes les quelques millisecondes. La commandesleepsimule les modifications de la répartition de la charge tout au long de la journée. En utilisant un script qui génère du trafic de cette manière, vous pouvez comprendre ce qui se passe lorsque vous combinez l'utilisation du processeur et les métriques personnalisées dans votre configuration HPA.Dans Cloud Shell, créez un tableau de bord :
gcloud monitoring dashboards create \ --config-from-file=./monitoring/dashboard.yamlAccédez à la page Tableaux de bord de Cloud Monitoring :
Cliquez sur Scheduled Autoscaler Dashboard (Tableau de bord de l'autoscaler planifié).
Le tableau de bord affiche trois graphiques. Vous devez attendre au moins deux heures (dans l'idéal, 24 heures ou plus) pour voir la dynamique des scalings à hausse et à la baisse, ainsi que l'impact de différentes répartitions de charge pendant la journée sur l'autoscaling.
Pour vous donner une idée de ce que les graphiques affichent, vous pouvez étudier les graphiques suivants, qui offrent une vue pendant une journée entière :
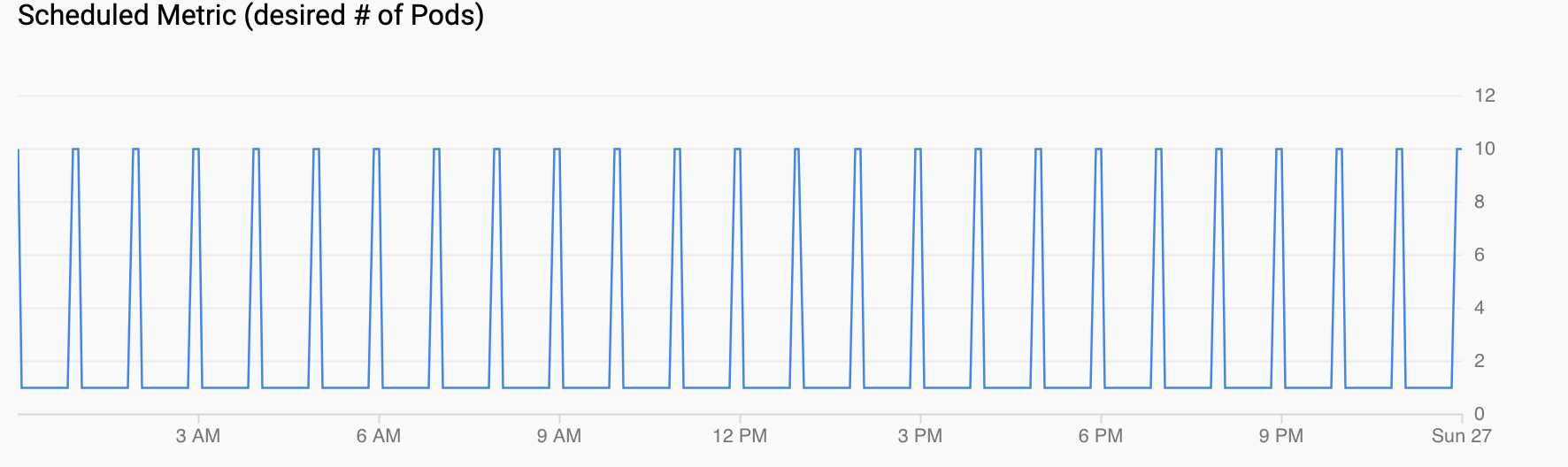
Le graphique Métrique planifiée (# pod(s) souhaité(s)) affiche une série temporelle de la métrique personnalisée en cours d'exportation vers Cloud Monitoring via des tâches cron que vous avez configurées à la section Configurer un autoscaler planifié.
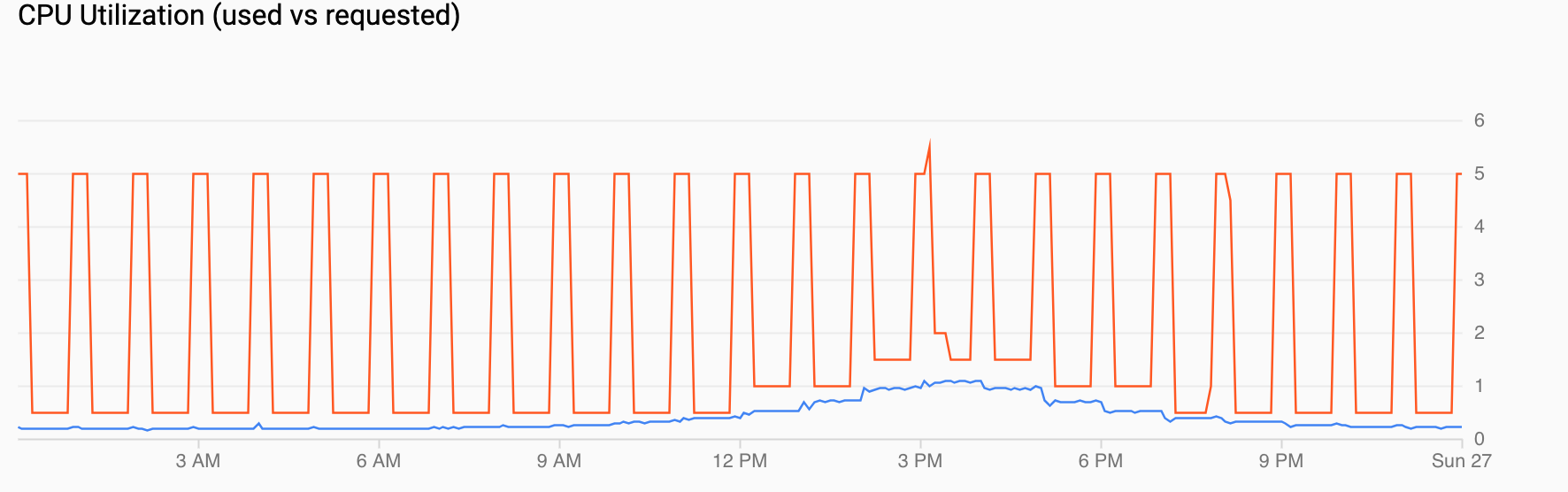
Le graphique Utilisation du processeur (demande/utilisation) présente une série temporelle d'utilisation demandée du processeur (en rouge) et d'utilisation réelle (en bleu). Lorsque la charge est faible, le HPA respecte la décision d'utilisation de l'autoscaler planifié. Toutefois, lorsque le trafic augmente, le HPA augmente le nombre de pods si nécessaire, comme vous pouvez le voir pour les points de données entre 12h et 18h.
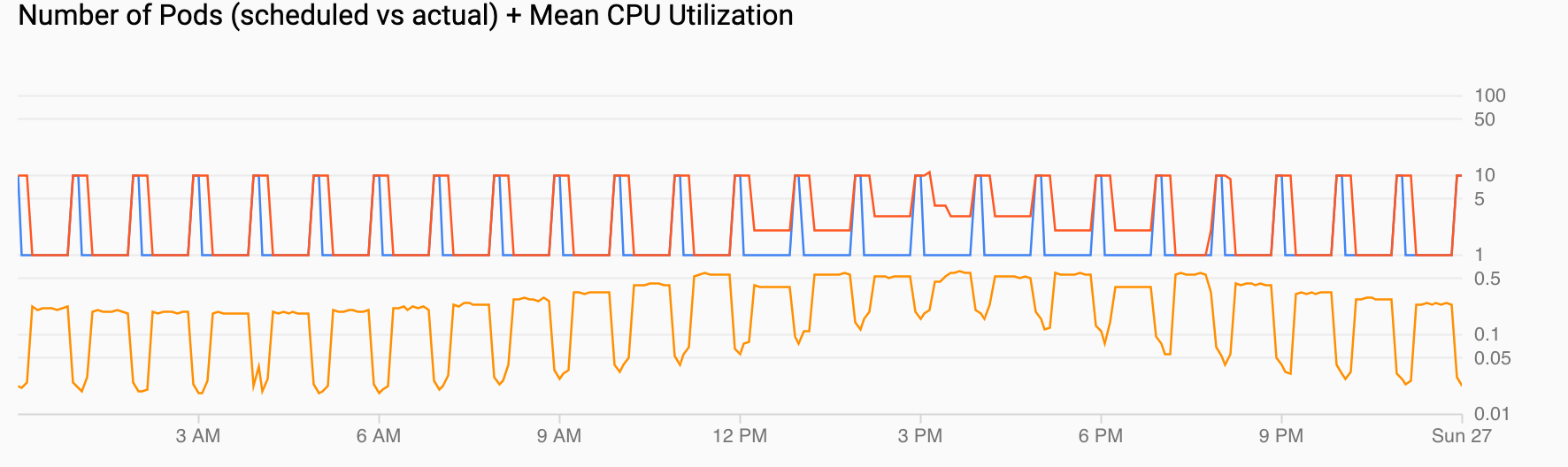
Le graphique Nombre de pods (planifiés et réels) + utilisation moyenne du processeur affiche une vue semblable aux pods précédents. Le nombre de pods (en rouge) est passé à 10 chaque heure selon la planification (en bleu). Le nombre de pods augmente et diminue naturellement au fil du temps en fonction du chargement (de 12h et 18h). L'utilisation moyenne du processeur (en orange) reste inférieure à la cible que vous avez définie (60 %).
Créer le cluster GKE
Déployer l'exemple d'application
Configurer un autoscaler planifié
Configurer des alertes lorsque l'autoscaler planifié ne fonctionne pas correctement
Dans un environnement de production, vous souhaitez généralement savoir quand les tâches Cron ne renseignent pas la métrique personnalisée. Pour ce faire, vous pouvez créer une alerte qui se déclenche lorsqu'un flux custom.googleapis.com/scheduled_autoscaler_example est absent pendant une période de cinq minutes.
Générer une charge pour l'exemple d'application
Visualiser le scaling en réponse au trafic ou aux métriques planifiées
Dans cette section, vous allez examiner les visualisations qui présentent les effets du scaling à la hausse et à la baisse.
Nettoyer
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Étapes suivantes
- Consultez la section Bonnes pratiques pour l'exécution d'applications Kubernetes à coût maîtrisé sur GKE pour en savoir plus sur l'optimisation des coûts sur GKE.
- Découvrez des recommandations de conception et des bonnes pratiques pour optimiser le coût des charges de travailGoogle Cloud dans le framework Well-Architected : optimisation des coûts.Google Cloud
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.