Artikel ini menjelaskan cara memigrasikan database Anda dari sistem Pemrosesan Transaksi Online (OLTP) Oracle® ke Spanner.
Spanner menggunakan konsep tertentu secara berbeda dari alat pengelolaan database perusahaan lainnya, jadi Anda mungkin perlu menyesuaikan aplikasi untuk memanfaatkan sepenuhnya kemampuannya. Anda mungkin juga perlu melengkapi Spanner dengan layanan lain dari Google Cloud untuk memenuhi kebutuhan Anda.
Batasan migrasi
Saat memigrasikan aplikasi ke Spanner, Anda harus mempertimbangkan berbagai fitur yang tersedia. Anda mungkin perlu mendesain ulang arsitektur aplikasi agar sesuai dengan set fitur Spanner dan terintegrasi dengan layanan tambahan. Google Cloud
Prosedur tersimpan dan pemicu
Spanner tidak mendukung menjalankan kode pengguna di tingkat database, jadi sebagai bagian dari migrasi, Anda harus memindahkan logika bisnis yang diterapkan oleh prosedur dan pemicu tersimpan tingkat database ke dalam aplikasi.
Urutan
Sebaiknya gunakan UUID Versi 4 sebagai metode default untuk membuat nilai kunci primer.
Fungsi GENERATE_UUID() (GoogleSQL,
PostgreSQL)
menampilkan nilai UUID Versi 4 sebagai jenis STRING.
Jika Anda perlu membuat nilai bilangan bulat 64-bit, Spanner mendukung urutan bit-reverse positif (GoogleSQL, PostgreSQL), yang menghasilkan nilai yang didistribusikan secara merata di seluruh ruang angka 64-bit positif. Anda dapat menggunakan angka-angka ini untuk menghindari masalah hotspotting.
Untuk mengetahui informasi selengkapnya, lihat strategi nilai default kunci utama.
Kontrol akses
Identity and Access Management (IAM) memungkinkan Anda mengontrol akses pengguna dan grup ke resource Spanner di tingkat project, instance Spanner, dan database Spanner. Untuk mengetahui informasi selengkapnya, lihat Ringkasan IAM.
Tinjau dan terapkan kebijakan IAM dengan mengikuti prinsip hak istimewa terendah untuk semua pengguna dan akun layanan yang mengakses database Anda. Jika aplikasi memerlukan akses terbatas ke tabel, kolom, tampilan, atau aliran perubahan tertentu, terapkan kontrol akses terperinci (FGAC). Untuk mengetahui informasi selengkapnya, lihat ringkasan kontrol akses terperinci.
Batasan validasi data
Spanner dapat mendukung serangkaian batasan validasi data terbatas di lapisan database.
Jika Anda memerlukan batasan data yang lebih kompleks, terapkan batasan tersebut di lapisan aplikasi.
Tabel berikut membahas jenis batasan yang umum ditemukan dalam database Oracle®, dan cara menerapkannya dengan Spanner.
| Batasan | Implementasi dengan Spanner |
|---|---|
| Tidak null | Batasan kolom NOT NULL |
| Unik | Indeks sekunder dengan batasan UNIQUE |
| Kunci asing (untuk tabel normal) | Lihat Membuat dan mengelola hubungan kunci asing. |
Tindakan kunci asing ON DELETE/ON UPDATE |
Hanya dapat dilakukan untuk tabel yang disisipkan, jika tidak, diterapkan di lapisan aplikasi |
Pemeriksaan dan validasi nilai melalui batasan atau pemicu CHECK
|
Diimplementasikan di lapisan aplikasi |
Jenis data yang didukung
Database Oracle® dan Spanner mendukung kumpulan jenis data yang berbeda. Tabel berikut mencantumkan jenis data Oracle dan padanannya di Spanner. Untuk mengetahui definisi mendetail setiap jenis data Spanner, lihat Jenis Data.
Anda mungkin juga harus melakukan transformasi tambahan pada data seperti yang dijelaskan di kolom Catatan agar data Oracle sesuai dengan database Spanner Anda.
Misalnya, Anda dapat menyimpan BLOB besar sebagai objek di bucket Cloud Storage, bukan di database, lalu menyimpan referensi URI ke objek Cloud Storage di database sebagai STRING.
| Jenis data Oracle | Padanan Spanner | Catatan |
|---|---|---|
Jenis karakter (CHAR, VARCHAR, NCHAR,
NVARCHAR)
|
STRING
|
Catatan: Spanner menggunakan string Unicode di seluruhnya. Oracle mendukung panjang maksimum 32.000 byte atau karakter (bergantung pada jenis), sedangkan Spanner mendukung hingga 2.621.440 karakter. |
BLOB, LONG RAW, BFILE
|
BYTES atau STRING yang berisi URI ke objek.
|
Objek kecil (kurang dari 10 MiB) dapat disimpan sebagai BYTES.Pertimbangkan untuk menggunakan penawaran Google Cloud alternatif seperti Cloud Storage untuk menyimpan objek yang lebih besar. |
CLOB, NCLOB, LONG
|
STRING (berisi data atau URI ke objek eksternal)
|
Objek kecil (kurang dari 2.621.440 karakter) dapat disimpan sebagai
STRING. Pertimbangkan untuk menggunakan penawaran Google Cloud alternatif seperti
Cloud Storage untuk menyimpan objek yang lebih besar.
|
NUMBER, NUMERIC, DECIMAL
|
STRING, FLOAT64, INT64
|
Jenis data NUMBER Oracle setara dengan jenis data NUMERIC GoogleSQL. Setiap jenis data mendukung presisi 38 digit dan
skala sembilan digit: (P,S) = (38,9). Jenis data PostgreSQL
NUMERIC menyimpan
data numerik presisi arbitrer.
Jenis data GoogleSQL FLOAT64 mendukung presisi hingga 16 digit. |
INT, INTEGER, SMALLINT
|
INT64
|
|
BINARY_FLOAT, BINARY_DOUBLE
|
FLOAT64
|
|
DATE
|
DATE
|
Representasi STRING default dari jenis DATE Spanner adalah yyyy-mm-dd, yang berbeda dengan Oracle, jadi berhati-hatilah saat mengonversi secara otomatis ke dan dari representasi STRING tanggal. Fungsi SQL disediakan untuk
mengonversi tanggal menjadi string berformat.
|
DATETIME
|
TIMESTAMP
|
Spanner menyimpan waktu secara independen dari zona waktu. Jika Anda perlu menyimpan zona waktu, Anda harus menggunakan kolom STRING terpisah.
Fungsi SQL disediakan untuk mengonversi stempel waktu menjadi string yang diformat menggunakan
zona waktu.
|
XML
|
STRING (berisi data atau URI ke objek eksternal)
|
Objek XML kecil (kurang dari 2.621.440 karakter) dapat disimpan sebagai
STRING. Pertimbangkan untuk menggunakan penawaran Google Cloud alternatif
seperti Cloud Storage untuk menyimpan objek yang lebih besar. |
URI, DBURI, XDBURI,
HTTPURI
|
STRING
|
|
ROWID
|
PRIMARY KEY
|
Spanner menggunakan kunci utama tabel untuk mengurutkan dan mereferensikan baris secara internal, sehingga di Spanner, kunci utama sama efektifnya dengan jenis data ROWID. |
SDO_GEOMETRY, SDO_TOPO_GEOMETRY_SDO_GEORASTER
|
Spanner tidak mendukung jenis data geospasial. Anda harus menyimpan data ini menggunakan jenis data standar, dan menerapkan logika penelusuran dan pemfilteran di lapisan aplikasi. | |
ORDAudio, ORDDicom, ORDDoc,
ORDImage, ORDVideo, ORDImageSignature
|
Spanner tidak mendukung jenis data media. Pertimbangkan untuk menggunakan Cloud Storage untuk menyimpan data media. |
Proses migrasi
Linimasa keseluruhan proses migrasi Anda adalah:
- Konversi skema dan model data Anda.
- Menerjemahkan kueri SQL apa pun.
- Migrasikan aplikasi Anda untuk menggunakan Spanner selain Oracle.
- Ekspor data Anda secara massal dari Oracle dan impor data Anda ke Spanner menggunakan Dataflow.
- Pertahankan konsistensi antara kedua database selama migrasi.
- Migrasikan aplikasi Anda dari Oracle.
Langkah 1: Konversi database dan skema Anda
Anda mengonversi skema yang ada menjadi skema Spanner untuk menyimpan data. Skema ini harus cocok dengan skema Oracle yang ada sedekat mungkin untuk menyederhanakan modifikasi aplikasi. Namun, karena perbedaan fitur, beberapa perubahan akan diperlukan.
Menggunakan praktik terbaik dalam desain skema dapat membantu Anda meningkatkan throughput dan mengurangi hot spot di database Spanner.
Kunci utama
Di Spanner, setiap tabel yang harus menyimpan lebih dari satu baris harus memiliki kunci utama yang terdiri dari satu atau beberapa kolom tabel. Kunci utama tabel Anda mengidentifikasi setiap baris dalam tabel secara unik, dan baris tabel diurutkan berdasarkan kunci utama. Karena Spanner sangat terdistribusi, Anda harus memilih teknik pembuatan kunci utama yang dapat diskalakan dengan baik seiring pertumbuhan data Anda. Untuk mengetahui informasi selengkapnya, lihat strategi migrasi kunci utama yang direkomendasikan.
Perhatikan bahwa setelah menetapkan kunci utama, Anda tidak dapat menambahkan atau menghapus kolom kunci utama, atau mengubah nilai kunci utama nanti tanpa menghapus dan membuat ulang tabel. Untuk mengetahui informasi selengkapnya tentang cara menetapkan kunci utama, lihat Skema dan model data - kunci utama.
Menyisipkan tabel
Spanner memiliki fitur yang memungkinkan Anda menentukan dua tabel yang memiliki hubungan induk-turunan one-to-many. Hal ini menyisipkan baris data turunan dengan baris induknya dalam penyimpanan, secara efektif menggabungkan tabel sebelumnya dan meningkatkan efisiensi pengambilan data saat induk dan turunan dikueri bersama-sama.
Kunci utama tabel turunan harus dimulai dengan kolom kunci utama tabel induk. Dari perspektif baris anak, kunci utama baris induk disebut sebagai kunci asing. Anda dapat menentukan hingga 6 tingkat hubungan induk-turunan.
Anda dapat menentukan tindakan saat penghapusan untuk tabel turunan guna menentukan apa yang terjadi saat baris induk dihapus: semua baris turunan dihapus, atau penghapusan baris induk diblokir saat baris turunan ada.
Berikut adalah contoh pembuatan tabel Album yang disisipkan dalam tabel induk Penyanyi yang ditentukan sebelumnya:
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
Membuat indeks sekunder
Anda juga dapat membuat indeks sekunder untuk mengindeks data dalam tabel di luar kunci utama.
Spanner menerapkan indeks sekunder dengan cara yang sama seperti tabel, sehingga nilai kolom yang akan digunakan sebagai kunci indeks memiliki batasan yang sama dengan kunci utama tabel. Artinya juga bahwa indeks memiliki jaminan konsistensi yang sama dengan tabel Spanner.
Pencarian nilai menggunakan indeks sekunder pada dasarnya sama dengan kueri dengan
penggabungan tabel. Anda dapat meningkatkan performa kueri menggunakan indeks dengan menyimpan
salinan nilai kolom tabel asli dalam indeks sekunder menggunakan
klausa STORING, sehingga menjadikannya
indeks cakupan.
Pengoptimal kueri Spanner hanya akan otomatis menggunakan indeks
sekunder jika indeks itu sendiri menyimpan semua kolom yang dikueri (kueri
yang tercakup). Untuk memaksa penggunaan indeks saat membuat kueri kolom dalam tabel
asli, Anda harus menggunakan
direktif FORCE INDEX
dalam pernyataan SQL, misalnya:
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
Indeks dapat digunakan untuk menerapkan nilai unik dalam kolom tabel, dengan menentukan
indeks
UNIQUE
pada kolom tersebut. Penambahan nilai duplikat akan dicegah oleh indeks.
Berikut adalah contoh pernyataan DDL yang membuat indeks sekunder untuk tabel Album:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Perhatikan bahwa jika Anda membuat indeks tambahan setelah data dimuat, pengisian indeks mungkin memerlukan waktu beberapa saat. Anda harus membatasi frekuensi penambahan hingga rata-rata tiga per hari. Untuk panduan selengkapnya tentang cara membuat indeks sekunder, lihat Indeks sekunder. Untuk mengetahui informasi selengkapnya tentang batasan pembuatan indeks, lihat Pembaruan skema.
Langkah 2: Terjemahkan kueri SQL apa pun
Spanner menggunakan dialek SQL ANSI 2011 dengan ekstensi, serta memiliki banyak fungsi dan operator untuk membantu menerjemahkan dan menggabungkan data Anda. Anda harus mengonversi kueri SQL yang menggunakan sintaksis, fungsi, dan jenis khusus Oracle agar kompatibel dengan Spanner.
Meskipun Spanner tidak mendukung data terstruktur sebagai definisi kolom, data terstruktur dapat digunakan dalam kueri SQL menggunakan jenis ARRAY dan STRUCT.
Misalnya, kueri dapat ditulis untuk menampilkan semua Album artis menggunakan
ARRAY dari STRUCTs dalam satu kueri (dengan memanfaatkan data yang telah digabungkan).
Untuk mengetahui informasi selengkapnya, lihat bagian
Catatan tentang subkueri
dalam dokumentasi.
Kueri SQL dapat diprofilkan menggunakan halaman Spanner Studio di Google Cloud Konsol untuk menjalankan kueri. Secara umum, kueri yang melakukan pemindaian tabel penuh pada tabel besar sangat mahal, dan harus digunakan dengan hemat.
Lihat dokumentasi praktik terbaik SQL untuk mengetahui informasi selengkapnya tentang mengoptimalkan kueri SQL.
Langkah 3: Migrasikan aplikasi Anda untuk menggunakan Spanner
Spanner menyediakan serangkaian Library klien untuk berbagai bahasa, dan kemampuan untuk membaca dan menulis data menggunakan panggilan API khusus Spanner, serta dengan menggunakan kueri SQL dan pernyataan Bahasa modifikasi data (DML). Penggunaan panggilan API mungkin lebih cepat untuk beberapa kueri, seperti pembacaan baris langsung menurut kunci, karena pernyataan SQL tidak perlu diterjemahkan.
Anda juga dapat menggunakan driver Java Database Connectivity (JDBC) untuk terhubung ke Spanner, dengan memanfaatkan alat dan infrastruktur yang ada yang tidak memiliki integrasi native.
Sebagai bagian dari proses migrasi, fitur yang tidak tersedia di Spanner harus diterapkan di aplikasi. Misalnya, pemicu untuk memverifikasi nilai data dan memperbarui tabel terkait harus diterapkan di aplikasi menggunakan transaksi baca/tulis untuk membaca baris yang ada, memverifikasi batasan, lalu menulis baris yang diperbarui ke kedua tabel.
Spanner menawarkan transaksi baca-tulis dan hanya baca, yang memastikan konsistensi eksternal data Anda. Selain itu, transaksi baca dapat menerapkan batas stempel waktu, tempat Anda membaca versi data yang konsisten yang ditentukan dengan cara berikut:
- Pada waktu yang tepat di masa lalu (hingga 1 jam yang lalu).
- Di masa mendatang (tempat bacaan akan diblokir hingga waktu tersebut tiba).
- Dengan jumlah keusangan terikat yang dapat diterima, yang akan menampilkan tampilan yang konsisten hingga beberapa waktu di masa lalu tanpa perlu memeriksa apakah data yang lebih baru tersedia di replika lain. Hal ini dapat memberikan manfaat performa dengan mengorbankan kemungkinan data yang tidak valid.
Langkah 4: Transfer data Anda dari Oracle ke Spanner
Untuk mentransfer data dari Oracle ke Spanner, Anda harus mengekspor database Oracle ke format file portabel, misalnya CSV, lalu mengimpor data tersebut ke Spanner menggunakan Dataflow.
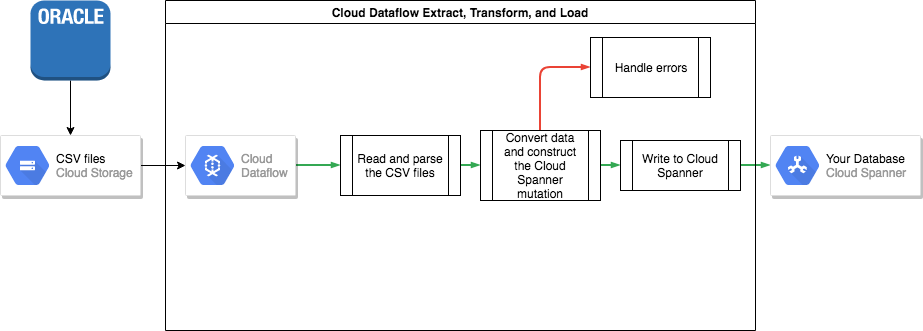
Ekspor massal dari Oracle
Oracle tidak menyediakan utilitas bawaan untuk mengekspor atau membatalkan pemuatan seluruh database Anda ke dalam format file portabel.
Beberapa opsi untuk melakukan ekspor tercantum dalam FAQ Oracle.
Fitur tersebut meliputi:
- Menggunakan SQL*plus atau SQLcl untuk meng-spool kueri ke file teks.
- Menulis fungsi PL/SQL menggunakan UTL_FILE untuk membongkar tabel secara paralel ke file teks.
- Menggunakan fitur dalam Oracle APEX atau Oracle SQL Developer untuk membatalkan pemuatan tabel ke file CSV atau XML.
Setiap metode ini memiliki kekurangan, yaitu hanya satu tabel yang dapat diekspor dalam satu waktu, yang berarti Anda harus menjeda aplikasi atau mengistirahatkan database agar database tetap dalam keadaan konsisten untuk diekspor.
Opsi lainnya mencakup alat pihak ketiga seperti yang tercantum di halaman FAQ Oracle, beberapa di antaranya dapat membatalkan pemuatan tampilan yang konsisten dari seluruh database.
Setelah dibongkar, Anda harus mengupload file data ini ke bucket Cloud Storage agar dapat diakses untuk diimpor.
Impor massal ke Spanner
Karena skema database mungkin berbeda antara Oracle dan Spanner, Anda mungkin perlu melakukan beberapa konversi data sebagai bagian dari proses impor.
Cara termudah untuk melakukan konversi data ini dan mengimpor data ke Spanner adalah dengan menggunakan Dataflow.
Dataflow adalah layanan Google Cloud ETL (Ekstraksi, Transformasi, dan Pemuatan) terdistribusi. Layanan ini menyediakan platform untuk menjalankan pipeline data yang ditulis menggunakan Apache Beam SDK untuk membaca dan memproses data dalam jumlah besar secara paralel di beberapa mesin.
Apache Beam SDK mengharuskan Anda menulis program Java sederhana untuk menetapkan pembacaan, transformasi, dan penulisan data. Konektor Beam tersedia untuk Cloud Storage dan Spanner, sehingga satu-satunya kode yang perlu ditulis adalah transformasi data itu sendiri.
Lihat contoh pipeline sederhana yang membaca dari file CSV dan menulis ke Spanner di repositori kode contoh yang menyertai artikel ini.
Jika tabel yang disisipkan induk-turunan digunakan dalam skema Spanner, maka kehati-hatian harus dilakukan dalam proses impor sehingga baris induk dibuat sebelum baris turunan. Kode pipeline Impor Spanner menangani hal ini dengan mengimpor semua data untuk tabel tingkat root terlebih dahulu, lalu semua tabel turunan tingkat 1, kemudian semua tabel turunan tingkat 2, dan seterusnya.
Pipeline impor Spanner dapat digunakan secara langsung untuk mengimpor data secara massal, tetapi hal ini mengharuskan data Anda ada dalam file Avro menggunakan skema yang benar.
Langkah 5: Menjaga konsistensi antara kedua database
Banyak aplikasi memiliki persyaratan ketersediaan yang membuat aplikasi tidak dapat tetap offline selama waktu yang diperlukan untuk mengekspor dan mengimpor data Anda. Saat Anda mentransfer data ke Spanner, aplikasi Anda terus mengubah database yang ada. Anda harus menduplikasi update ke database Spanner saat aplikasi berjalan.
Ada berbagai metode untuk menjaga kedua database Anda tetap sinkron, termasuk Pengambilan Data Perubahan, dan menerapkan update serentak di aplikasi.
Pengambilan Data Perubahan
Oracle GoldenGate dapat menyediakan aliran change data capture (CDC) untuk database Oracle Anda. LogMiner Oracle atau Oracle XStream Out adalah antarmuka alternatif untuk database Oracle guna mendapatkan aliran CDC yang tidak melibatkan Oracle GoldenGate.
Anda dapat menulis aplikasi yang berlangganan salah satu streaming ini dan yang menerapkan modifikasi yang sama (setelah konversi data, tentu saja) ke database Spanner Anda. Aplikasi pemrosesan streaming tersebut harus menerapkan beberapa fitur:
- Menghubungkan ke database Oracle (database sumber).
- Menghubungkan ke Spanner (database target).
- Melakukan tindakan berikut berulang kali:
- Menerima data yang dihasilkan oleh salah satu aliran CDC database Oracle.
- Menafsirkan data yang dihasilkan oleh aliran CDC.
- Mengonversi data menjadi pernyataan
INSERTSpanner. - Menjalankan pernyataan
INSERTSpanner.
Teknologi migrasi database adalah teknologi middleware yang telah menerapkan fitur yang diperlukan sebagai bagian dari fungsinya. Platform migrasi database diinstal sebagai komponen terpisah di lokasi sumber atau lokasi target, sesuai dengan persyaratan pelanggan. Platform migrasi database hanya memerlukan konfigurasi konektivitas database yang terlibat untuk menentukan dan memulai transfer data berkelanjutan dari database sumber ke database target.
Striim adalah platform teknologi migrasi database yang tersedia di Google Cloud. Konektor ini menyediakan konektivitas ke aliran CDC dari Oracle GoldenGate, serta dari Oracle LogMiner dan Oracle XStream Out. Striim menyediakan alat grafis yang memungkinkan Anda mengonfigurasi konektivitas database dan aturan transformasi apa pun yang diperlukan untuk mentransfer data dari Oracle ke Spanner.
Anda dapat menginstal Striim dari Google Cloud Marketplace, terhubung ke database sumber dan target, menerapkan aturan transformasi apa pun, dan mulai mentransfer data tanpa harus membuat aplikasi pemrosesan streaming sendiri.
Update simultan ke kedua database dari aplikasi
Metode alternatifnya adalah mengubah aplikasi Anda untuk melakukan penulisan ke kedua database. Satu database (awalnya Oracle) akan dianggap sebagai sumber kebenaran, dan setelah setiap penulisan database, seluruh baris dibaca, dikonversi, dan ditulis ke database Spanner.
Dengan cara ini, aplikasi akan terus mengganti baris Spanner dengan data terbaru.
Setelah yakin bahwa semua data Anda telah ditransfer dengan benar, Anda dapat mengalihkan sumber tepercaya ke database Spanner.
Mekanisme ini menyediakan jalur rollback jika masalah ditemukan saat beralih ke Spanner.
Memverifikasi konsistensi data
Saat data di-streaming ke database Spanner, Anda dapat menjalankan perbandingan secara berkala antara data Spanner dan data Oracle untuk memastikan data konsisten.
Anda dapat memvalidasi konsistensi dengan membuat kueri pada kedua sumber data dan membandingkan hasilnya.
Anda dapat menggunakan Dataflow untuk melakukan perbandingan mendetail pada set data besar menggunakan transformasi Gabung. Transformasi ini mengambil 2 set data yang diberi kunci, dan mencocokkan nilai berdasarkan kunci. Nilai yang cocok kemudian dapat dibandingkan untuk kesetaraan.
Anda dapat menjalankan verifikasi ini secara rutin hingga tingkat konsistensi sesuai dengan persyaratan bisnis Anda.
Langkah 6: Beralih ke Spanner sebagai sumber kebenaran aplikasi Anda
Setelah yakin dengan migrasi data, Anda dapat mengalihkan aplikasi untuk menggunakan Spanner sebagai sumber kebenaran. Terus tulis kembali perubahan ke database Oracle agar database Oracle tetap terbaru, sehingga Anda memiliki jalur rollback jika terjadi masalah.
Terakhir, Anda dapat menonaktifkan dan menghapus kode update database Oracle serta menonaktifkan database Oracle.
Mengekspor dan mengimpor database Spanner
Anda dapat secara opsional mengekspor tabel dari Spanner ke bucket Cloud Storage menggunakan template Dataflow untuk melakukan ekspor. Folder yang dihasilkan berisi serangkaian file Avro dan file manifes JSON yang berisi tabel yang diekspor. File ini dapat memenuhi berbagai tujuan, termasuk:
- Mencadangkan database Anda untuk kepatuhan terhadap kebijakan retensi data atau pemulihan dari bencana.
- Mengimpor file Avro ke penawaran Google Cloud lain seperti BigQuery.
Untuk mengetahui informasi selengkapnya tentang proses ekspor dan impor, lihat Mengekspor Database dan Mengimpor Database.
Langkah berikutnya
- Baca cara mengoptimalkan skema Spanner.
- Pelajari cara menggunakan Dataflow untuk situasi yang lebih kompleks.