Questo documento descrive come configurare un grafico temporaneo che mostri i dati delle serie temporali raccolti dal progetto. Esplora metriche può visualizzare solo dati numerici delle serie temporali.
Seleziona i dati da visualizzare
Per configurare le serie temporali da visualizzare in un grafico, puoi elaborare una query selezionando le opzioni dai menu oppure puoi scrivere una query. Quando scrivi una query, selezioni il linguaggio di query e poi utilizzi un editor di query o un'interfaccia basata su testo:
Le query Monitoring Query Language (MQL) specificano le serie temporali e come queste vengono raggruppate e allineate. L'interfaccia MQL supporta un editor di codice con suggerimenti e controllo della sintassi.
In genere non è possibile convertire le query MQL in moduli che possono essere utilizzati dalle altre interfacce. Le query non salvate vengono eliminate quando passi alla scheda MQL o esci da questa.
Le query Prometheus Query Language (PromQL) specificano le serie temporali e la modalità di raggruppamento e allineamento di queste. L'interfaccia PromQL supporta un editor con suggerimenti.
In genere non è possibile convertire le query PromQL in moduli che possono essere utilizzati dalle altre interfacce. Le query non salvate vengono eliminate quando passi alla scheda PromQL o esci da questa.
Le query del filtro di monitoraggio specificano la serie temporale, ma non includono istruzioni di raggruppamento o allineamento.
Qualsiasi serie temporale che Monitoring può rappresentare in un grafico può essere specificata utilizzando un filtro di monitoraggio. Ad esempio, per tracciare il numero di processi in esecuzione su una VM, devi utilizzare un filtro di monitoraggio che specifichi una funzione.
Non è sempre possibile convertire un filtro di monitoraggio nel formato richiesto da altre interfacce. Pertanto, la query potrebbe essere ignorata se passi a un'interfaccia diversa.
In genere, le query specificano un tipo di metrica, un tipo di risorsa e i filtri:
Un tipo di metrica identifica le misurazioni da raccogliere da una risorsa. Include una descrizione di ciò che viene misurato e di come vengono interpretate le misurazioni. A volte un tipo di metrica viene chiamato metrica. Un esempio di metrica è "Utilizzo della CPU". Per informazioni concettuali, consulta Tipi di metriche.
Un tipo di risorsa specifica da quale risorsa vengono acquisiti i dati delle metriche. Il tipo di risorsa viene a volte chiamato tipo di risorsa monitorata o semplicemente risorsa. Un esempio di risorsa è un'"istanza di macchina virtuale (VM) Compute Engine". Per informazioni concettuali, consulta Risorse monitorate.
Sia le query MQL che quelle PromQL includono istruzioni di raggruppamento e allineamento. Tuttavia, quando scrivi un filtro di monitoraggio o utilizzi i menu per selezionare la serie temporale da rappresentare in un grafico, puoi configurare le impostazioni di raggruppamento e allineamento utilizzando i menu.
Creare query utilizzando i menu
La creazione di query utilizzando i menu è la configurazione predefinita. In genere, se selezioni una metrica e un filtro e poi passi a un'interfaccia diversa, le selezioni vengono conservate e riformattate per l'interfaccia in questione. In altre parole, una query creata tramite i menu può essere convertita in una query MQL.
Puoi tornare dalle altre interfacce all'interfaccia basata su menu selezionando tune Generatore. Tuttavia, la query viene ignorata. In altre parole, una query MQL non può essere convertita in un modulo basato su menu equivalente.
Per creare la query utilizzando i menu:
-
Nella Google Cloud console, vai alla pagina leaderboard Esplora metriche:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
- Nella barra degli strumenti della Google Cloud console, seleziona il tuo Google Cloud progetto. Per le configurazioni di App Hub, seleziona il progetto host di App Hub o il progetto di gestione della cartella abilitata per le app.
Nella barra degli strumenti del riquadro delle query:
Nell'elemento Metrica, espandi il menu Seleziona una metrica.
Il menu Seleziona una metrica contiene funzionalità che ti aiutano a trovare i tipi di metriche disponibili:
Per trovare un tipo di metrica specifico, utilizza la filter_list barra dei filtri. Ad esempio, se inserisci
util, il menu mostrerà solo le voci che includonoutil. Le voci vengono mostrate quando superano un test "contiene" senza distinzione tra maiuscole e minuscole.Per visualizzare tutti i tipi di metriche, anche quelle senza dati, fai clic su Attiva. Per impostazione predefinita, i menu mostrano solo i tipi di metriche con dati.
Effettua una selezione nel menu Risorse, nel menu Categorie di metriche, nel menu Metriche e poi fai clic su Applica.
Ad esempio, per tracciare un grafico sull'utilizzo della CPU di una macchina virtuale Compute Engine, puoi selezionare Istanza VM, Istanza, Utilizzo CPU e fare clic su Applica.
Il menu Risorse elenca la risorsa da cui vengono raccolti i dati. Quando una metrica non è scritta in base a una risorsa, seleziona Senza specificare.
Dopo aver selezionato il tipo di risorsa e la metrica, il grafico mostra tutte le serie temporali disponibili per la coppia:
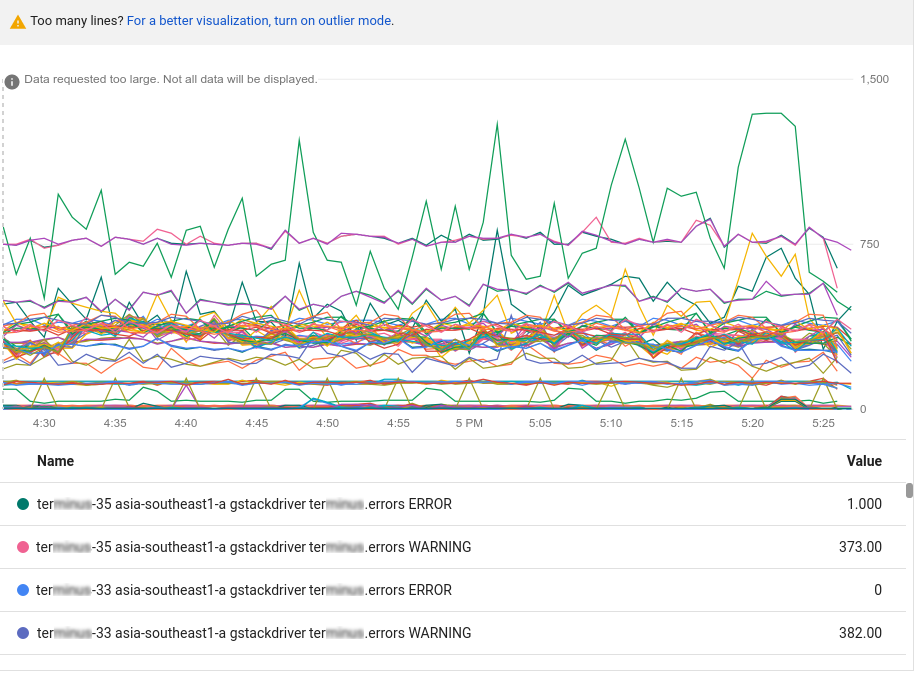
Il grafico precedente contiene più dati di quelli che possono essere visualizzati; i grafici sono limitati a 50 righe visualizzabili. Il grafico fornisce una notifica che indica che ci sono troppi dati da visualizzare. Per ridurre la quantità di dati, utilizza l'elemento Ordina e limita nella barra degli strumenti delle query. Per ulteriori informazioni, consulta la sezione Mostrare gli outlier.
Puoi anche utilizzare le opzioni di filtro e aggregazione per ridurre la quantità di dati visualizzati nel grafico. Queste tecniche rendono i grafici più utili per la diagnostica e l'analisi e aumentano il rendimento e la reattività dell'interfaccia utente stessa.
(Facoltativo) Aggiungi filtri per limitare le serie temporali visualizzate. La sezione successiva descrive le opzioni di filtro.
(Facoltativo) Configura la modalità di raggruppamento e allineamento delle serie temporali. Per ulteriori informazioni, consulta Scegliere come visualizzare i dati dei grafici.
Filtrare i dati dei grafici
I filtri assicurano che vengano tracciate solo le serie temporali che soddisfano un insieme di criteri. Quando applichi i filtri, potresti ridurre il numero di righe nel grafico, in modo da migliorarne le prestazioni. Un altro modo per migliorare la reattività di un grafico è configurare le opzioni di aggregazione, ordinare e limitare il numero di serie temporali visualizzate. Per ulteriori informazioni, consulta Mostrare gli outlier.
Un filtro è composto da un'etichetta, un comparatore e un valore. Ad esempio, per trovare corrispondenze con tutte le serie temporali la cui etichetta zone inizia con "us-central1", puoi utilizzare il filtro zone=~"us-central1.*", che utilizza un'espressione regolare per eseguire il confronto. Esistono quattro operatori di confronto:
- è uguale a
= - non uguale,
!= - corrispondenza con espressione regolare,
=~ - L'espressione regolare non corrisponde,
!=~
Quando filtri in base all'ID progetto o al contenitore delle risorse,
devi utilizzare l'operatore di uguaglianza (=). Quando filtri in base ad altre etichette, puoi utilizzare qualsiasi comparatore supportato.
In genere, puoi filtrare le etichette delle metriche e delle risorse e per
gruppo di risorse.
Quando fornisci più criteri di filtro, il grafico corrispondente mostra solo le serie temporali che soddisfano tutti i criteri, un AND logico.
Per aggiungere un filtro quando utilizzi l'interfaccia basata su menu della Google Cloud console:
Nell'elemento Filtro, fai clic su Aggiungi filtro ed effettua una selezione dal menu.
Per modificare il confronto, seleziona un valore dal menu Criterio di confronto.
Nel campo Valore, inserisci o seleziona un valore:
Per un confronto diretto,
=o!=, seleziona il valore dal menu o inserisci un valore e fai clic su Ok. Puoi inserire valori comeus-central1-aoppure creare una stringa di filtro che inizi constarts_withoends_with. Ad esempio, per visualizzare i dati per qualsiasi zonaus-central1, puoi inserire la stringa filtrostarts_with("us-central1"). Per saperne di più sulle stringhe di filtro, consulta Filtri di monitoraggio.Poiché le voci del menu derivano dalle serie temporali ricevute, quando una risorsa monitorata non genera dati per la metrica selezionata, devi inserire un valore per l'etichetta.
Per un confronto con un'espressione regolare,
=~o!=~, inserisci un'espressione regolare RE2 nel campo Valore e fai clic su Ok. Ad esempio, l'espressione regolareus-central1-.*corrisponde a tutte le zoneus-central1.Per trovare una corrispondenza con qualsiasi zona degli Stati Uniti che termina con "a", puoi utilizzare l'espressione regolare
^us.*.a$.Non puoi utilizzare espressioni regolari per filtrare l'
project_idetichetta della risorsa.Ad esempio, per visualizzare solo la serie temporale di una delle zone
us-central1, applica un filtrozone=~"us-central1.*".
Quando aggiungi più filtri, si applicano i seguenti punti:
Puoi utilizzare la stessa etichetta più volte, il che ti consente di specificare un filtro per un intervallo di valori.
Tutti i criteri di filtro devono essere soddisfatti; costituiscono un
ANDlogico.
Per modificare il valore o il comparatore di un filtro, fai clic su arrow_drop_down Menu sull'elemento del filtro, apporta le modifiche e poi fai clic su Ok.
Per eliminare un filtro, fai clic su cancel Annulla.
Scrivere query MQL
Per inserire una query MQL o PromQL:
-
Nella Google Cloud console, vai alla pagina leaderboard Esplora metriche:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
- Nella barra degli strumenti della Google Cloud console, seleziona il tuo Google Cloud progetto. Per le configurazioni di App Hub, seleziona il progetto host di App Hub o il progetto di gestione della cartella abilitata per le app.
- Nella barra degli strumenti del riquadro Query Builder, seleziona il pulsante code MQL o code PromQL.
- Verifica che sia selezionato MQL nel pulsante di attivazione/disattivazione Lingua. Il pulsante di attivazione/disattivazione della lingua si trova nella stessa barra degli strumenti che consente di formattare la query.
- (Facoltativo) Disattiva l'opzione di attivazione/disattivazione Esecuzione automatica.
-
Inserisci la query nell'editor delle query. Ad esempio, per tracciare un grafico sull'utilizzo della CPU delle istanze VM nel tuo Google Cloud progetto, utilizza la seguente query:
fetch gce_instance | metric 'compute.googleapis.com/instance/cpu/utilization' | group_by 1m, [value_utilization_mean: mean(value.utilization)] | every 1mPer ulteriori informazioni su MQL, consulta i seguenti documenti:
Fai clic su Esegui query.
Quando l'opzione di attivazione/disattivazione Esecuzione automatica è attivata, il pulsante Esegui query non viene visualizzato.
Scrivere query PromQL
Per inserire una query MQL o PromQL:
-
Nella Google Cloud console, vai alla pagina leaderboard Esplora metriche:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
- Nella barra degli strumenti della Google Cloud console, seleziona il tuo Google Cloud progetto. Per le configurazioni di App Hub, seleziona il progetto host di App Hub o il progetto di gestione della cartella abilitata per le app.
- Nella barra degli strumenti del riquadro Query Builder, seleziona il pulsante code MQL o code PromQL.
- Verifica che PromQL sia selezionato nel pulsante di attivazione/disattivazione Lingua. Il pulsante di attivazione/disattivazione della lingua si trova nella stessa barra degli strumenti che consente di formattare la query.
- (Facoltativo) Disattiva l'opzione di attivazione/disattivazione Esecuzione automatica.
-
Inserisci la query nell'editor delle query. Ad esempio, per tracciare un grafico sull'utilizzo medio della CPU delle istanze VM nel tuo Google Cloud progetto, utilizza la seguente query:
avg(compute_googleapis_com:instance_cpu_utilization)Per ulteriori informazioni sull'utilizzo di PromQL, consulta PromQL in Cloud Monitoring.
Fai clic su Esegui query.
Quando l'opzione di attivazione/disattivazione Esecuzione automatica è attivata, il pulsante Esegui query non viene visualizzato.
Scrivere query con filtri di monitoraggio
Quando vuoi eseguire una delle seguenti operazioni, devi utilizzare la modalità di filtro diretto, che ti consente di inserire un filtro di monitoraggio:
- Visualizza un obiettivo del livello di servizio (SLO).
- Mostra il conteggio dei processi in esecuzione sulle macchine virtuali (VM).
- Visualizza una metrica personalizzata per la quale non disponi ancora di dati.
- Filtra una serie temporale in base a un'etichetta per la quale non disponi ancora di dati.
Un filtro di monitoraggio, o equivalentemente un
filtro delle metriche, è un'espressione utilizzata da Monitoring
per identificare la serie temporale da rappresentare in un grafico.
Ad esempio, la seguente espressione genera un grafico che mostra il conteggio dei processi il cui nome include nginx:
select_process_count("monitoring.regex.full_match(\".*nginx.*\")")
resource.type="gce_instance"
Puoi anche utilizzare i filtri di monitoraggio per identificare le serie temporali in base al tipo di risorsa e metrica. La seguente espressione genera un
grafico che mostra il conteggio delle voci di log per tutte le Google Cloud istanze di macchine virtuali nella zona us-east1-b:
metric.type="logging.googleapis.com/log_entry_count"
resource.type="gce_instance"
resource.label."zone"="us-east1-b"
Per inserire un filtro di monitoraggio:
-
Nella Google Cloud console, vai alla pagina leaderboard Esplora metriche:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
- Nella barra degli strumenti della Google Cloud console, seleziona il tuo Google Cloud progetto. Per le configurazioni di App Hub, seleziona il progetto host di App Hub o il progetto di gestione della cartella abilitata per le app.
Fai clic su help_outline Guida nell'elemento Metrica e poi seleziona Modalità di filtro diretto.
Gli elementi Metrica e Filtro vengono eliminati e viene creato un elemento Filtri che consente di inserire del testo.
Se hai selezionato un tipo di risorsa, una metrica o filtri prima di passare alla modalità Filtro diretto, queste impostazioni vengono visualizzate nell'elemento Filtri.
Nell'area di testo dell'elemento Filtri, inserisci un'espressione di filtro di monitoraggio. Per informazioni sulla sintassi, consulta i seguenti documenti:
Quando utilizzi la modalità di filtro diretto e non sono disponibili dati che soddisfino il filtro, viene visualizzato un errore. Alcuni messaggi di errore comuni sono
Chart definition invalideNo data is available for the selected timeframe.(Facoltativo) Configura la modalità di raggruppamento e allineamento delle serie temporali. Per ulteriori informazioni, consulta Scegliere come visualizzare i dati dei grafici.
Per tornare all'interfaccia basata su menu, fai clic su tune Esci dalla modalità di filtro diretto.
Scegli come visualizzare i dati dei grafici
La sezione spiega come visualizzare i dati selezionati impostando i campi di aggregazione. L'aggregazione consiste nell'allineamento dei punti dati all'interno di una serie temporale e nella combinazione di diverse serie temporali. Per una spiegazione dettagliata dell'aggregazione, consulta Filtro e aggregazione: manipolazione delle serie temporali.
- Per informazioni sulle opzioni di visualizzazione, consulta Impostare le opzioni di visualizzazione dei grafici.
- Per ulteriori informazioni su come interagire con il grafico stesso, consulta Esplorare i dati dei grafici.
I contenuti di questa sezione non si applicano quando hai selezionato i dati da includere nel grafico utilizzando un'espressione MQL o PromQL.
Combinare le serie temporali
Puoi ridurre la quantità di dati restituiti per una metrica combinando diverse serie temporali. Per combinare più serie temporali, in genere specifichi una o più etichette e una funzione. Le serie temporali che hanno lo stesso valore per tutte le etichette specificate vengono raggruppate e la funzione specificata le combina in una nuova serie temporale.
Le impostazioni nell'elemento Aggregation possono modificare il numero di serie temporali visualizzate nel grafico. Le impostazioni predefinite per questo elemento sono determinate dal tipo di metrica che hai selezionato. Per modificare la visualizzazione, puoi procedere in uno dei seguenti modi:
Per visualizzare ogni serie temporale, nell'elemento Aggregazione, assicurati che il primo menu sia impostato su Nessuna aggregazione e il secondo su Nessuna.
Per combinare le serie temporali, nell'elemento Aggregation (Aggregazione), procedi nel seguente modo:
Espandi il primo menu e seleziona una funzione.
Il grafico viene aggiornato e mostra una singola serie temporale. Ad esempio, se selezioni Media, la serie temporale visualizzata è la media di tutte le serie temporali.
Il menu delle funzioni supporta le funzioni algebriche comuni, come media, minimo, massimo e somma. L'opzione Conta serie temporali conteggia il numero di serie temporali che corrispondono alle impostazioni di metriche e filtri. Le opzioni di percentile, come il percentile 99, sono valori statistici ricavati dalle serie temporali che corrispondono alle impostazioni di metriche e filtri.
Per combinare le serie temporali con gli stessi valori delle etichette, espandi il secondo menu e seleziona una o più etichette.
Il grafico viene aggiornato e mostra una serie temporale per ogni combinazione univoca di valori delle etichette. Ad esempio, per visualizzare le serie temporali per zona, imposta il secondo menu su zona.
Per configurare la spaziatura tra i punti dati, fai clic su add Aggiungi elemento query, seleziona Intervallo min, quindi inserisci un valore.
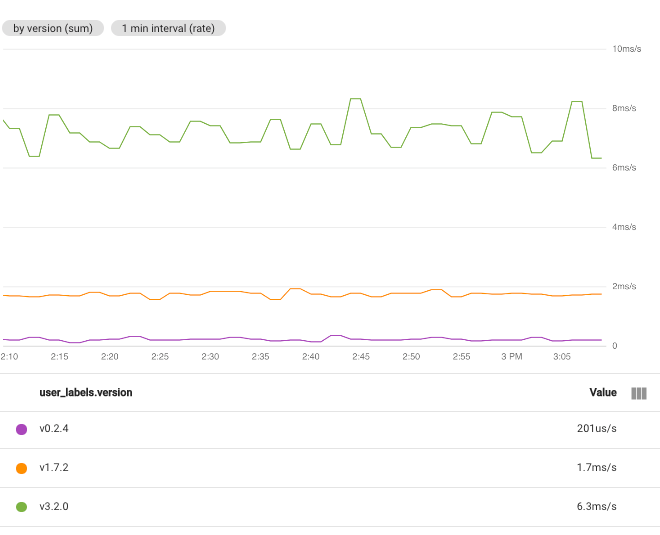
Ad esempio, se imposti la funzione su Somma e selezioni l'etichetta user_labels.version, esiste una serie temporale per ogni valore dell'etichetta user_labels.version. I punti dati di ogni serie temporale vengono calcolati dalla somma di tutti i valori per le singole serie temporali di una versione specifica:
Quando selezioni più etichette, le serie temporali che hanno gli stessi valori per le etichette selezionate vengono combinate. Il grafico risultante mostra una serie temporale per ogni combinazione di valori delle etichette. L'ordine in cui specifichi le etichette non è importante. Lo screenshot seguente mostra un grafico in cui le serie temporali sono combinate in base alle etichette user_labels.version e system_labels.machine_image:
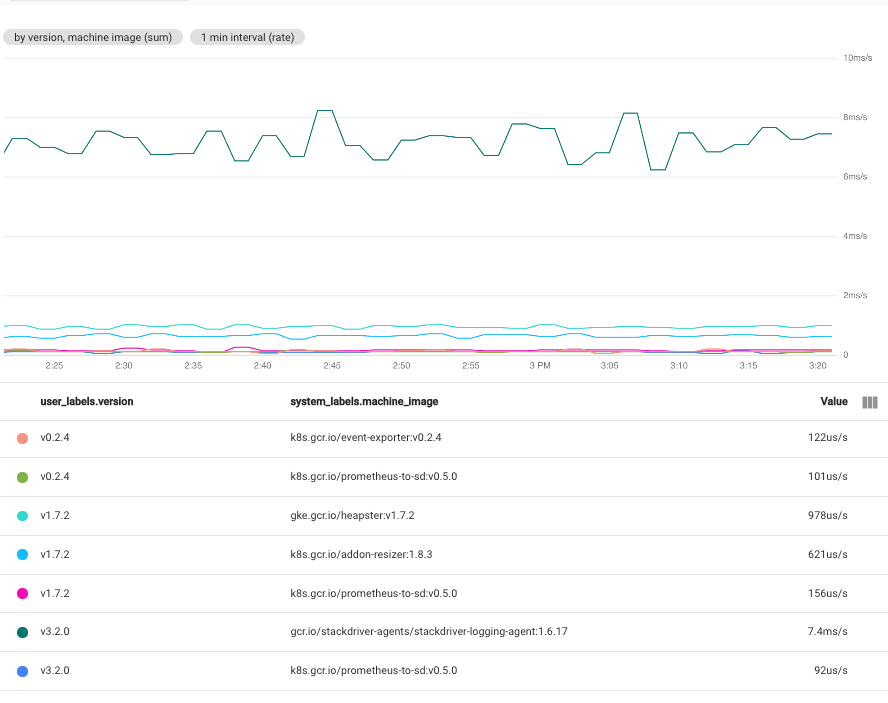
Come mostrato, il grafico mostra una serie temporale per ogni coppia di valori dell'etichetta. Il fatto che tu ottenga una serie temporale per ogni combinazione di etichette significa che questa tecnica può creare più dati di quelli che puoi inserire in un singolo grafico.
Mostra tutte le serie temporali
Per visualizzare tutte le serie temporali, nell'elemento Aggregazione, imposta il primo menu su Nessuna aggregazione e il secondo su Nessuna.
Allinea le serie temporali
L'allineamento è il processo di conversione dei dati delle serie temporali ricevuti dal monitoraggio in una nuova serie temporale con punti dati a intervalli fissi. Il processo di allineamento consiste nel raccogliere tutti i punti dati ricevuti in una durata di tempo fissa, applicando una funzione per combinare quei punti dati e assegnando un timestamp al risultato. Questa funzione potrebbe calcolare la media di tutti i campioni o estrarre il massimo di tutti i campioni.
Impostare l'intervallo di allineamento
Per specificare la durata fissa dei punti da combinare, fai clic su add Aggiungi elemento query nel riquadro della query, seleziona Intervallo min e poi completa la finestra di dialogo.
Ad esempio, considera una metrica con un periodo di campionamento di un minuto. Se un grafico è configurato per mostrare 1 ora di dati, può mostrare tutti i 60 punti dati. Se il campo Intervallo min è impostato su 10 minutes, il grafico mostra 6 punti dati. Tuttavia, se ora configuri il grafico in modo da visualizzare una settimana di dati, i punti da visualizzare sono troppi, pertanto l'intervallo in cui vengono combinati i punti viene modificato automaticamente.
In questo esempio, l'intervallo modificato è di un'ora.
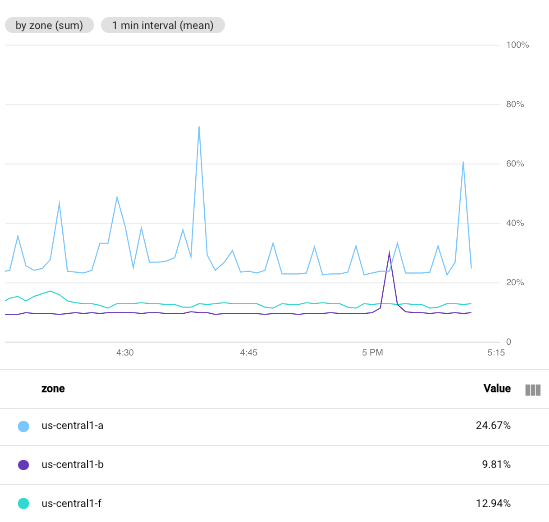
Lo screenshot seguente mostra l'utilizzo della CPU delle istanze VM Compute Engine in un determinato Google Cloud progetto.
In questa immagine, il campo Intervallo min è impostato su 1 minute:
Per fare un confronto, lo screenshot seguente mostra l'effetto della modifica
dell'intervallo da 1 minute a 5 minutes:
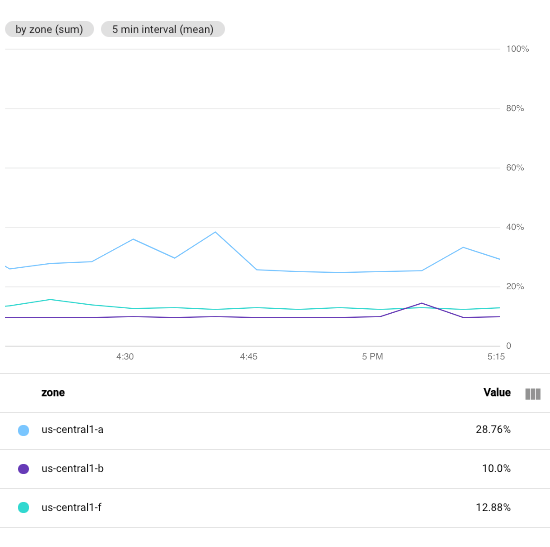
Aumentando il periodo, il grafico risultante avrà meno punti, passando da 60 punti per serie temporale a 10 punti per serie temporale. Aumentando il campo Intervallo min, vengono combinati più punti, il che ha un effetto di spianamento sui dati tracciati.
Impostare la funzione di allineamento
Quando selezioni la funzione di aggregazione, Cloud Monitoring seleziona la funzione di allineamento per te. Cloud Monitoring determina la funzione di allineamento ottimale in base al tipo di metrica selezionato e alla tua scelta per la funzione di aggregazione. Tuttavia, puoi specificare una funzione di allineamento e ignorare la scelta fatta da Cloud Monitoring.
Per specificare la funzione di allineamento, procedi nel seguente modo:
- Nell'elemento Aggregazione, espandi il primo menu e seleziona Configura allineatore. Vengono aggiunti gli elementi Funzione di allineamento e Raggruppamento.
- Espandi l'elemento Funzione di allineamento ed effettua una selezione.
Sebbene la maggior parte delle funzioni di allineamento supportate esegua funzioni matematiche comuni, alcune eseguono azioni più complicate:
next older: per conservare solo il campione più recente all'interno di un periodo di allineamento, seleziona next older. Questa funzione viene comunemente utilizzata con i controlli di uptime ed è una buona scelta se ti interessa solo il valore più recente.
Questa funzione è valida solo per le metriche indicatore.
percentile: per visualizzare una metrica di distribuzione su un tipo di grafico a linee, grafico ad area impigliato o grafico a barre impigliato, devi selezionare il percentile della distribuzione da visualizzare. Un modo per specificare questo percentile è selezionare una funzione percentile. Puoi selezionare il 5°, il 50°, il 95° e il 99° percentile. Il punto dati allineato viene determinato calcolando il percentile specificato utilizzando tutti i punti dati nel periodo di allineamento.
Questa funzione è valida solo per le metriche indicatore e delta quando hanno un tipo di dati di distribuzione.
delta: per convertire una metrica cumulativa o una metrica delta in una metrica delta con un campione per periodo di allineamento, utilizza questa funzione. Quando utilizzi questa funzione, potrebbe verificarsi l'interpolazione dei dati. Per un esempio, consulta Tipi, generi e conversioni.
Questa funzione è valida solo per le metriche cumulative e delta.
rate: per convertire una metrica cumulativa o delta in una metrica indicatore, utilizza questa funzione. Se scegli questa funzione, puoi considerare la serie temporale come trasformata come con una funzione delta e poi divisa per il periodo di allineamento. Ad esempio, se l'unità della serie temporale originale è MiB e l'unità del periodo di allineamento è secondo, il grafico ha un'unità di MiB al secondo. Per ulteriori informazioni, consulta Tipi, conversioni e tipi di conversione.
Questa funzione è valida solo per le metriche cumulative e delta.
Per ulteriori informazioni sulle funzioni di allineamento disponibili, consulta Aligner nel riferimento all'API.
Raggruppamento e allineamento secondari
Quando hai più serie temporali che rappresentano già aggregazioni, puoi ridurre tutte le serie temporali nel grafico a una singola serie temporale scegliendo un aggregatore secondario. Ad esempio, se raggruppi i dati per zona, il grafico mostra una serie temporale per ogni zona. Per creare un grafico con una singola serie temporale, utilizza i campi di aggregazione secondaria.
Per alcuni tipi di metriche, hai la possibilità di trasformare i dati. Se questa opzione è disponibile e se imposti il campo Trasforma su un valore diverso da Nessuna, tutti gli altri campi sono le impostazioni di aggregazione secondaria.
Quando i campi di aggregazione secondaria sono configurabili, per accedervi, effettua i seguenti passaggi:
- Fai clic su add Aggiungi elemento di query e poi seleziona Aggregazione secondaria.
- Configura l'elemento Aggregazione secondaria.
Lo screenshot seguente mostra diverse serie temporali risultanti dal raggruppamento di un insieme di dati filtrati. L'utilizzo del raggruppamento richiede l'aggregazione; ogni gruppo di righe viene aggregato in un unico gruppo. Lo screenshot seguente mostra le serie temporali raggruppate per zona:
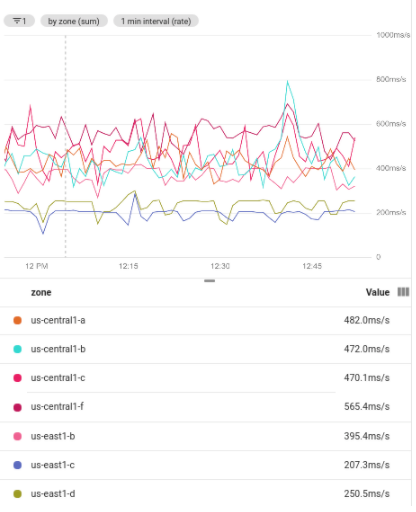
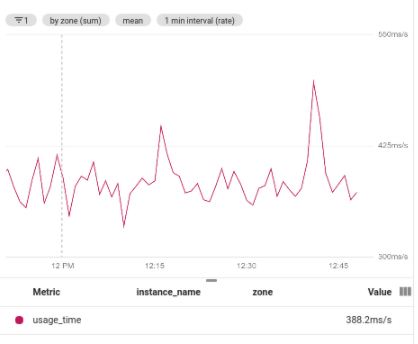
Lo screenshot seguente mostra il risultato dell'utilizzo dell'aggregazione secondaria per trovare il valore medio nelle serie temporali raggruppate:
Configurare il nome di una colonna della legenda
Il campo Alias legenda consente di personalizzare una descrizione per la serie temporale nel grafico. Queste descrizioni vengono visualizzate nella descrizione comando per il grafico e nella legenda del grafico nella colonna Nome. Per impostazione predefinita, le descrizioni nella legenda vengono create automaticamente a partire dai valori di etichette diverse nella serie temporale. Poiché è il sistema a selezionare le etichette, i risultati potrebbero non essere utili. Per creare un modello per le descrizioni, utilizza questo campo.
Puoi inserire testo normale e modelli nel campo Legend Alias (Alias legenda). Quando aggiungi un modello, aggiungi un'espressione che viene valutata quando viene visualizzata la legenda.
Per aggiungere un modello di legenda a un grafico:
- Nel riquadro Visualizza, espandi expand_more Alias legenda.
- Fai clic su add Mostra suggerimenti sulle variabili del modello
e seleziona una voce dal menu.
Ad esempio, se selezioni
zone, viene aggiunto il modello${resource.labels.zone}.
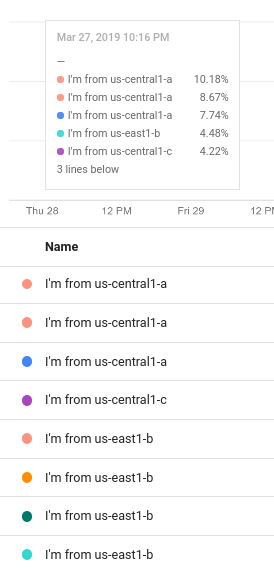
Ad esempio, lo screenshot seguente mostra un modello di legenda contenente testo normale e l'espressione ${resource.labels.zone}:

Nella legenda del grafico, i valori generati dal modello vengono visualizzati in una colonna con l'intestazione Nome e nella descrizione comando:
Puoi configurare il modello della legenda in modo da includere più stringhe di testo e modelli. Tuttavia, lo spazio di visualizzazione disponibile nella descrizione comando è limitato.
Passaggi successivi
- Esplorare i dati dei grafici
- Panoramica delle metriche definite dall'utente
- Configurare il modello di legenda
- Impostare le opzioni di visualizzazione del grafico