默认情况下,Ops Agent 和旧版 Monitoring 代理均配置为收集用于捕获 Compute Engine 虚拟机 (VM) 上运行的进程相关信息的指标。您还可以使用 Monitoring 代理在 Amazon Elastic Compute Cloud (EC2) 虚拟机上收集这些指标。这组指标称为“进程指标”,可通过前缀 agent.googleapis.com/processes 识别。 不会在 Google Kubernetes Engine (GKE) 上收集这些指标。
如收费指标中所述,自 2021 年 8 月 6 日起,我们将针对这些指标收取费用。这组流程指标被归类为应收费,但从未实施过费用。
本文档介绍了直观呈现进程指标的工具、如何确定从这些指标注入的数据量,以及如何最大限度地减少相关费用。
使用进程指标
您可以通过使用 Metrics Explorer 或自定义信息中心创建的图表来直观呈现流程指标数据。如需了解详情,请参阅使用信息中心和图表。 此外,Cloud Monitoring 还包含两个预定义信息中心内进程指标的数据:
- Monitoring 中的虚拟机实例信息中心
- Compute Engine 中的虚拟机实例详情信息中心
以下部分介绍了这些信息中心。
监控:查看汇总的进程指标
如需查看指标范围内的聚合进程指标,请转到虚拟机实例信息中心中的进程标签页:
-
在 Google Cloud 控制台中,转到
 信息中心页面:
信息中心页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
从列表中选择虚拟机实例信息中心。
点击进程。
以下屏幕截图显示了 Monitoring 进程页面的示例:
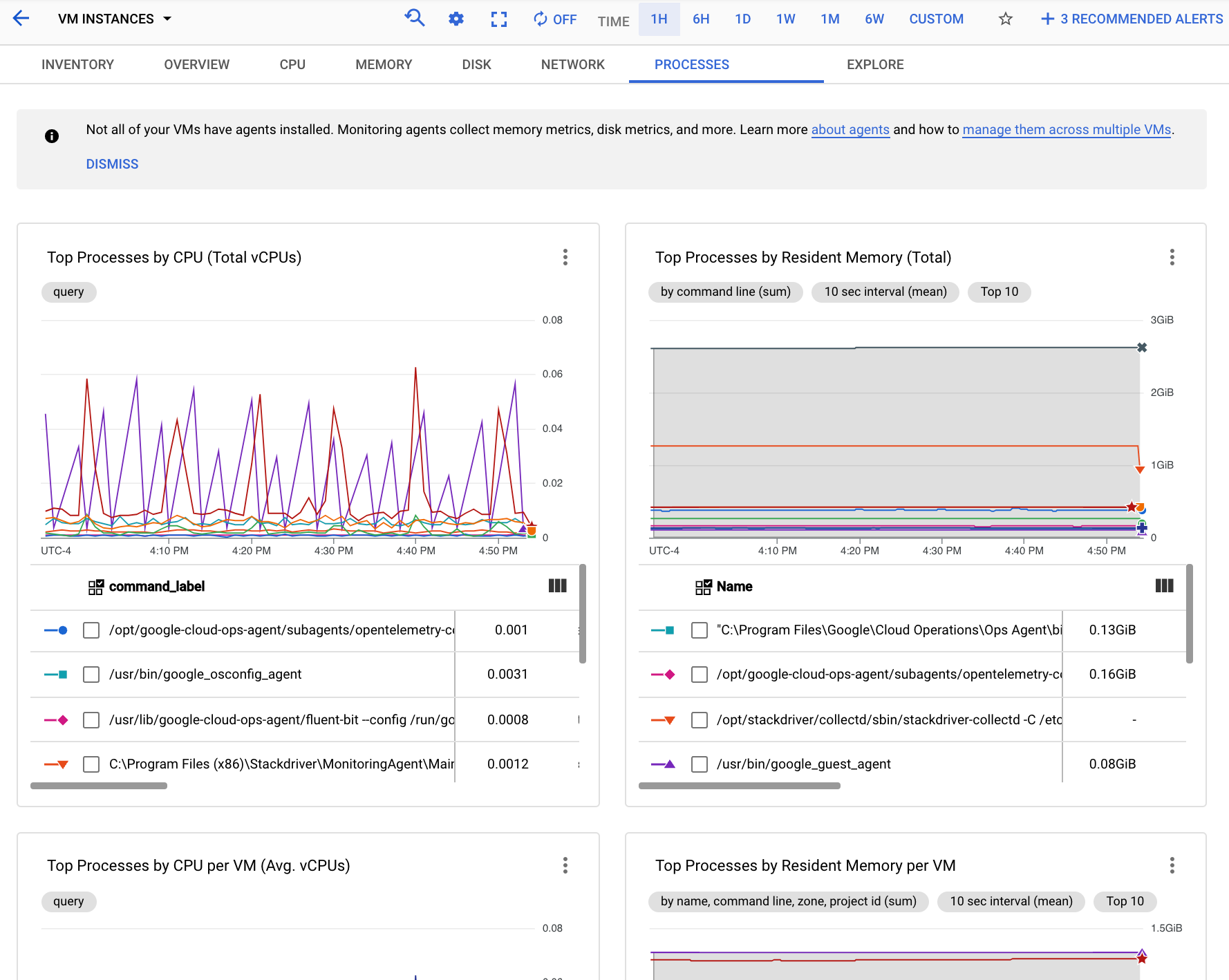
您可以使用进程标签页上的图表来识别指标范围中占用最多 CPU 和内存的进程以及磁盘利用率最高的进程。
Compute Engine:查看资源消耗量最高的虚拟机的性能指标
如需查看显示 Google Cloud 项目中消耗资源最多的五个虚拟机的性能图表,请前往虚拟机实例的可观测性标签页:
-
在 Google Cloud 控制台中,转到虚拟机实例页面:
如果您使用搜索栏查找此页面,请选择子标题为 Compute Engine 的结果。
- 点击可观测性。
以下屏幕截图显示了 Compute Engine 可观测性页面的示例。
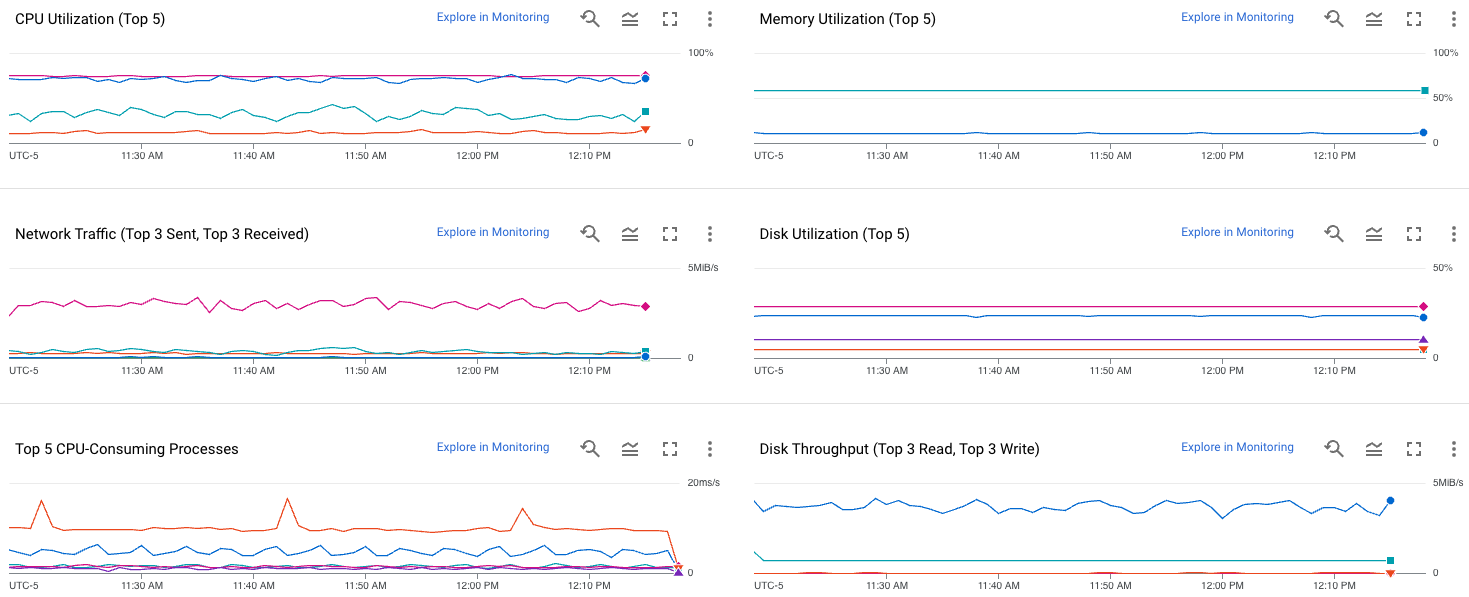
如需了解如何使用这些指标诊断虚拟机问题,请参阅排查虚拟机性能问题。
Compute Engine:查看每个虚拟机进程指标
如需查看在单个 Compute Engine 虚拟机 (VM) 上运行的进程列表以及资源使用率最高的进程的图表,请转到该虚拟机的可观测性标签页:
-
在 Google Cloud 控制台中,转到虚拟机实例页面:
如果您使用搜索栏查找此页面,请选择子标题为 Compute Engine 的结果。
在实例标签页上,点击要检查的虚拟机的名称。
点击可观测性,查看此虚拟机的指标。
在可观测性标签页的导航窗格中,选择进程。
以下屏幕截图显示了 Compute Engine 进程页面的示例:
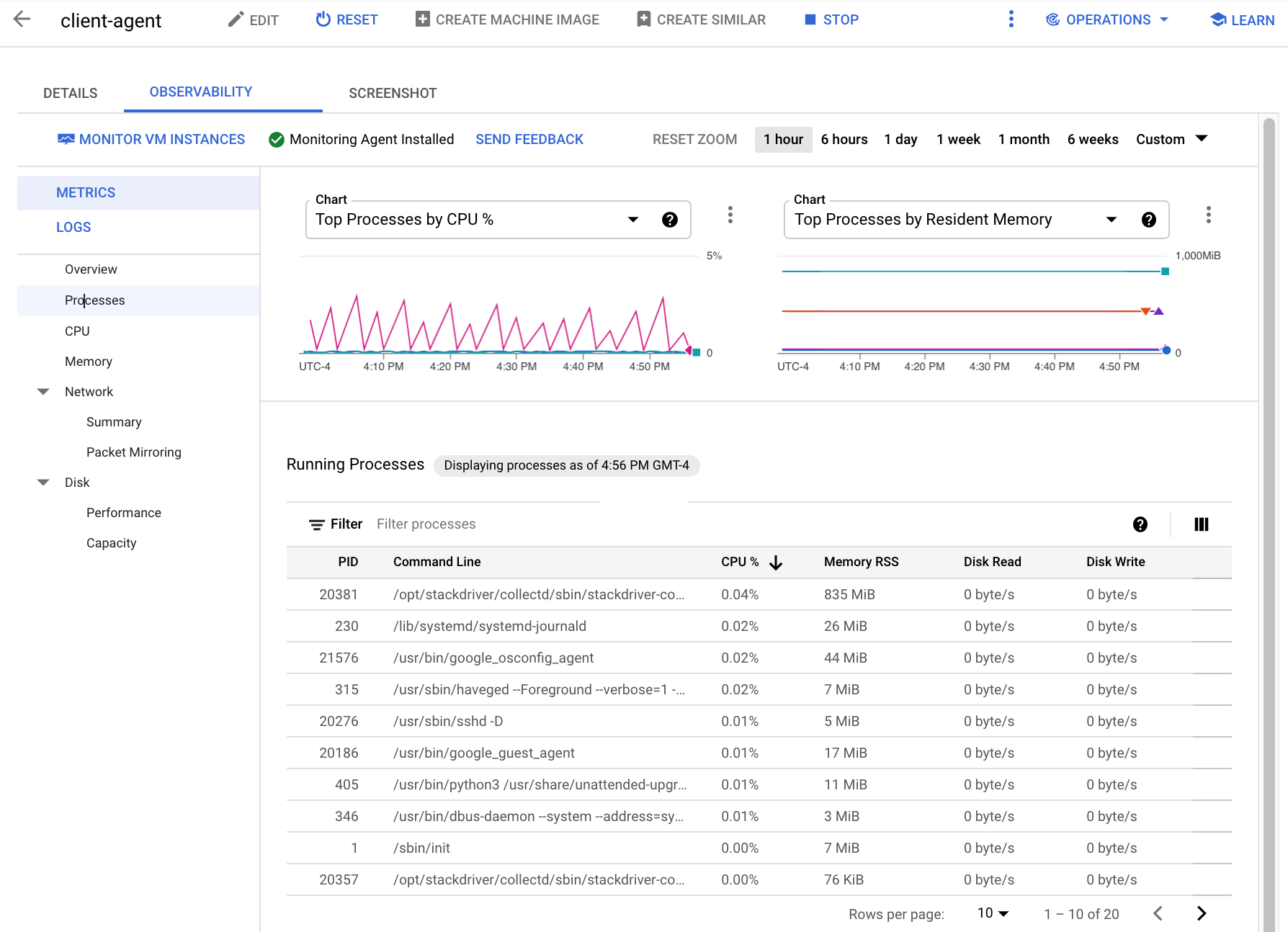
进程指标最多可保留 24 小时,因此您可以使用它们进行回溯,将资源消耗中的异常情况归因于特定进程,或识别成本最高的资源使用者。例如,下图显示了占用 CPU 资源百分比最多的进程。您可以使用时间范围选择器更改图表的时间范围。时间范围选择器提供预设值(例如最近一小时),还允许您输入自定义时间范围。
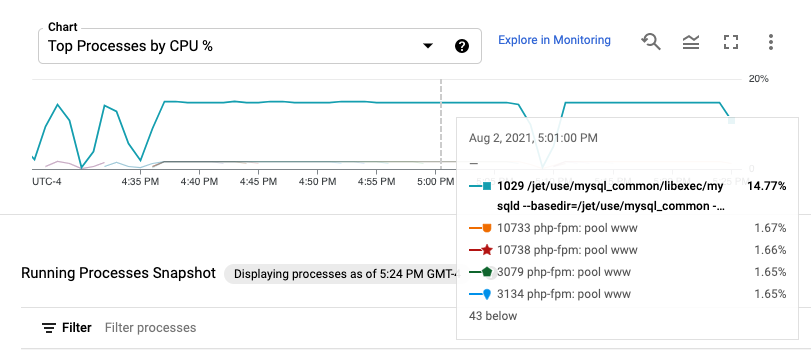
正在运行的进程表提供了与 Linux top 命令的输出类似的资源消耗量列表。默认情况下,该表会显示最新数据的快照。但是,如果您在图表上选择过去结束的时间范围,该表将显示在该范围结束时运行的进程。
如需了解如何使用这些指标诊断虚拟机问题,请参阅排查虚拟机性能问题。
代理收集的流程指标
Linux 代理会从 Compute Engine 虚拟机上运行的进程并使用 Monitoring 代理(Amazon Elastic Compute Cloud (EC2) 虚拟机)收集下表中列出的所有指标。您可以通过 Ops Agent(2.0.0 及更高版本)和旧版 Monitoring 代理停用其收集功能。
您还可以针对在 Windows 虚拟机上运行的 Ops Agent(2.0.0 及更高版本)停用收集进程指标的功能。
如需了解详情,请参阅停用进程指标。
如果要在 Windows 上停用对这些指标的收集,我们建议您升级到 Ops Agent 2.0.0 或更高版本。如需了解详情,请参阅安装 Ops Agent。
流程指标
此表中的“指标类型”字符串必须以 agent.googleapis.com/processes/ 为前缀。表中的条目已省略该前缀。
查询标签时,请使用 metric.labels. 前缀;例如 metric.labels.LABEL="VALUE"。
| 指标类型发布阶段 (资源层次结构级别 显示名称 |
|
|---|---|
| 种类、类型、单位 受监控的资源 |
说明 标签 |
count_by_state
GA
(项目)
进程 |
|
GAUGE、DOUBLE、1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
指定状态的流程计数。仅限 Linux。每 60 秒采样一次。state:正在运行、正在休眠、僵化等。 |
cpu_time
GA
(项目)
流程 CPU |
|
CUMULATIVE、INT64、us{CPU}
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
给定流程的 CPU 时间。每 60 秒采样一次。process:流程名称。user_or_syst:用户或系统流程。command:流程命令。command_line:流程命令行,最多 1024 个字符。owner:流程所有者。pid:流程 ID。 |
disk/read_bytes_count
GA
(项目)
流程磁盘读取 I/O |
|
CUMULATIVE、INT64、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
流程磁盘读取 I/O。仅限 Linux。每 60 秒采样一次。process:流程名称。command:流程命令。command_line:流程命令行,最多 1024 个字符。owner:流程所有者。pid:流程 ID。 |
disk/write_bytes_count
GA
(项目)
流程磁盘写入 I/O |
|
CUMULATIVE、INT64、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
流程磁盘写入 I/O。仅限 Linux。每 60 秒采样一次。process:流程名称。command:流程命令。command_line:流程命令行,最多 1024 个字符。owner:流程所有者。pid:流程 ID。 |
fork_count
GA
(项目)
叉数 |
|
CUMULATIVE、INT64、1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
分支流程总数。仅限 Linux。每 60 秒采样一次。 |
rss_usage
GA
(项目)
进程常驻内存 |
|
GAUGE、DOUBLE、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
给定进程的常驻内存使用量。仅限 Linux。每 60 秒采样一次。process:流程名称。command:流程命令。command_line:流程命令行,最多 1024 个字符。owner:流程所有者。pid:流程 ID。 |
vm_usage
GA
(项目)
处理虚拟内存 |
|
GAUGE、DOUBLE、By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
给定流程的虚拟机使用情况。每 60 秒采样一次。process:流程名称。command:流程命令。command_line:流程命令行,最多 1024 个字符。owner:流程所有者。pid:流程 ID。 |
世界协调时间 (UTC) 2024-09-12 02:25:45 生成的表。
确定当前提取
您可以使用 Metrics Explorer 查看目前为进程指标注入的数据量。请按以下步骤操作:
-
在 Google Cloud 控制台中,转到 leaderboard Metrics Explorer 页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
在查询构建器窗格的工具栏中,选择名为 code MQL 或 code PromQL 的按钮。
验证已在MQL切换开关中选择 MQL。语言切换开关位于同一工具栏中,用于设置查询的格式。
要查看
gce_instance和aws_ec2_instance资源的进程指标点总数,请执行以下操作:输入以下查询:
def tagged_process_metric name = metric 'agent.googleapis.com/processes/'$name | add [metric_suffix: $name]; def process_metrics resource_type = fetch $resource_type | { @tagged_process_metric 'cpu_time' ; @tagged_process_metric 'disk/read_bytes_count' ; @tagged_process_metric 'disk/write_bytes_count' ; @tagged_process_metric 'rss_usage' ; @tagged_process_metric 'vm_usage' ; @tagged_process_metric 'count_by_state' ; @tagged_process_metric 'fork_count' } | within 1d | group_by [metric_suffix], 1m, [row_count: row_count()] | union; { @process_metrics 'gce_instance' ; @process_metrics 'aws_ec2_instance' } | outer_join 0, 0 | { rename [], [out: val(0)] | add [resource_type: 'gce_instance'] ; rename [], [out: val(1)] | add [resource_type: 'aws_ec2_instance'] } | union | group_by drop[metric_suffix], 1d, .sum点击运行查询。生成的图表显示了每种资源类型的值。
估算指标的费用
Monitoring 价格示例说明了如何估算指标的提取费用。这些示例可应用于处理指标。
所有流程指标均每 60 秒采样一次,所有这些指标都写入数据点为 8 个字节,以计算价格。
流程指标的价格设置为价格示例中所用标准量费用的 5%。因此,如果您假设这些示例中描述的场景中的所有指标都是流程指标,则可以使用每个场景总费用的 5% 来估算流程费用指标。
停用进程指标收集
您可以通过多种方式对 Ops Agent(2.0.0 及更高版本)以及 Linux 上的旧版 Monitoring 代理停用对这些指标的收集功能。
这些代理仅在 Compute Engine 虚拟机上运行;对于 Monitoring 代理,则仅在 Amazon Elastic Compute Cloud (EC2) 虚拟机上运行;这些步骤仅适用于这些平台。
如果您运行的是版本低于 2.0.0 的 Ops Agent 或是在 Windows 上运行的旧版 Monitoring 代理,则无法停用收集功能。如果要在 Windows 上停用对这些指标的收集,我们建议您升级到 Ops Agent 2.0.0 或更高版本。如需了解详情,请参阅安装 Ops Agent。
常规流程如下所示:
连接到虚拟机。
创建现有配置文件的副本作为备份。将备份副本存储在代理的配置目录之外,这样代理便不会尝试同时加载这两个文件。例如,以下命令会为 Linux 上的 Monitoring 代理创建配置文件的副本:
cp /etc/stackdriver/collectd.conf BACKUP_DIR/collectd.conf.bak
使用下述选项之一更改配置:
重启代理以选取新配置:
- Monitoring 代理:
sudo service stackdriver-agent restart - Ops Agent:
sudo service google-cloud-ops-agent restart
- Monitoring 代理:
验证系统不再收集此虚拟机的流程指标:
选择 Metrics Explorer。
点击 MQL。
对于
gce_instance资源,输入以下查询,并将 VM_NAME 替换为此虚拟机的名称:fetch gce_instance | metric 'agent.googleapis.com/processes/cpu_time' | filter (metadata.system_labels.name == 'VM_NAME') | align rate(1m) | every 1m
对于
aws_ec2_instance资源,替换查询中的gce_instance。点击运行查询。
Linux 或 Windows 上的 Ops Agent
Ops Agent 配置文件的位置取决于操作系统:
- 对于 Linux:
/etc/google-cloud-ops-agent/config.yaml - 对于 Windows:
C:\Program Files\Google\Cloud Operations\Ops Agent\config\config.yaml
如需停用 Ops Agent 对所有进程指标的收集,请将以下内容添加到 config.yaml 文件中:
metrics:
processors:
metrics_filter:
type: exclude_metrics
metrics_pattern:
- agent.googleapis.com/processes/*
这会在 metrics_filter 处理器中从应用于 metrics 服务中默认流水线的收集中排除进程指标。
如需详细了解 Ops Agent 的配置选项,请参阅配置 Ops Agent。
Linux 上的 Monitoring 代理
您可以通过以下选项停用旧版 Monitoring 代理对进程指标的收集:
以下部分介绍了每个选项并列出了与该选项相关的优势和风险。
修改代理的配置文件
使用此选项,您直接修改代理的主配置文件 /etc/stackdriver/collectd.conf,以移除支持收集进程指标的部分。
过程
您需要对 collectd.conf 文件进行三组删除:
删除以下
LoadPlugin指令和插件配置:LoadPlugin processes <Plugin "processes"> ProcessMatch "all" ".*" Detail "ps_cputime" Detail "ps_disk_octets" Detail "ps_rss" Detail "ps_vm" </Plugin>删除以下
PostCacheChain指令和PostCache链的配置:PostCacheChain "PostCache" <Chain "PostCache"> <Rule "processes"> <Match "regex"> Plugin "^processes$" Type "^(ps_cputime|disk_octets|ps_rss|ps_vm)$" </Match> <Target "jump"> Chain "MaybeThrottleProcesses" </Target> Target "stop" </Rule> <Rule "otherwise"> <Match "throttle_metadata_keys"> OKToThrottle false HighWaterMark 5700000000 # 950M * 6 LowWaterMark 4800000000 # 800M * 6 </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>删除
PostCache链使用的MaybeThrottleProcesses链:<Chain "MaybeThrottleProcesses"> <Rule "default"> <Match "throttle_metadata_keys"> OKToThrottle true TrackedMetadata "processes:pid" TrackedMetadata "processes:command" TrackedMetadata "processes:command_line" TrackedMetadata "processes:owner" </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>
优势和风险
- 优势
- 这样即可减少代理消耗的资源,因为系统永远不会收集指标。
- 如果您对
collectd.conf文件进行了其他更改,也许可以轻松保留这些更改。
- 风险
- 您必须使用
root账号来修改此配置文件。 - 文件中存在排版错误。
- 您必须使用
替换代理的配置文件
使用此选项,您可以将代理的主配置文件替换为预修改版本,并为您移除相关部分。
过程
将预修改的文件
collectd-no-process-metrics.conf从 GitHub 代码库下载到/tmp目录,然后执行以下操作:cd /tmp && curl -sSO https://raw.githubusercontent.com/Stackdriver/agent-packaging/master/collectd-no-process-metrics.conf将现有的
collectd.conf文件替换为预修改的文件:cp /tmp/collectd-no-process-metrics.conf /etc/stackdriver/collectd.conf
优势和风险
- 优势
- 这样即可减少代理消耗的资源,因为系统永远不会收集指标。
- 您无需手动将文件修改为
root。 - 配置管理工具可以轻松替换文件。
- 风险
- 如果您对
collectd.conf文件进行了其他更改,则必须将这些更改合并到替换文件中。
- 如果您对
问题排查
本文档中所述的过程是代理配置的更改,因此可能会出现下列问题:
- 权限不足,无法修改配置文件。必须通过
root账号修改配置文件。 - 直接对配置文件中的排版错误引入直接修改。
如需了解如何解决其他问题,请参阅 Monitoring 代理问题排查。
Windows 上的 Monitoring 代理
您无法停用在 Windows 虚拟机上运行的旧版 Monitoring 代理对进程指标的收集。此代理不可配置。如果要在 Windows 上停用对这些指标的收集,我们建议您升级到 Ops Agent 2.0.0 或更高版本。如需了解详情,请参阅安装 Ops Agent。
如果您正在运行 Ops Agent,请参阅 Linux 或 Windows 上的 Ops Agent。