会話分析は、Gemini for Google Cloud を活用したデータとのチャット機能です。会話分析を使用すると、ビジネス インテリジェンスの専門知識を持たないユーザーでも、静的なダッシュボードでは得られないデータを、普段使う自然な言葉で質問できます。会話分析は、Looker(Google Cloud コア)、Looker(オリジナル)インスタンス、Looker Studio Pro サブスクリプションの一部として Looker Studio で利用できます。
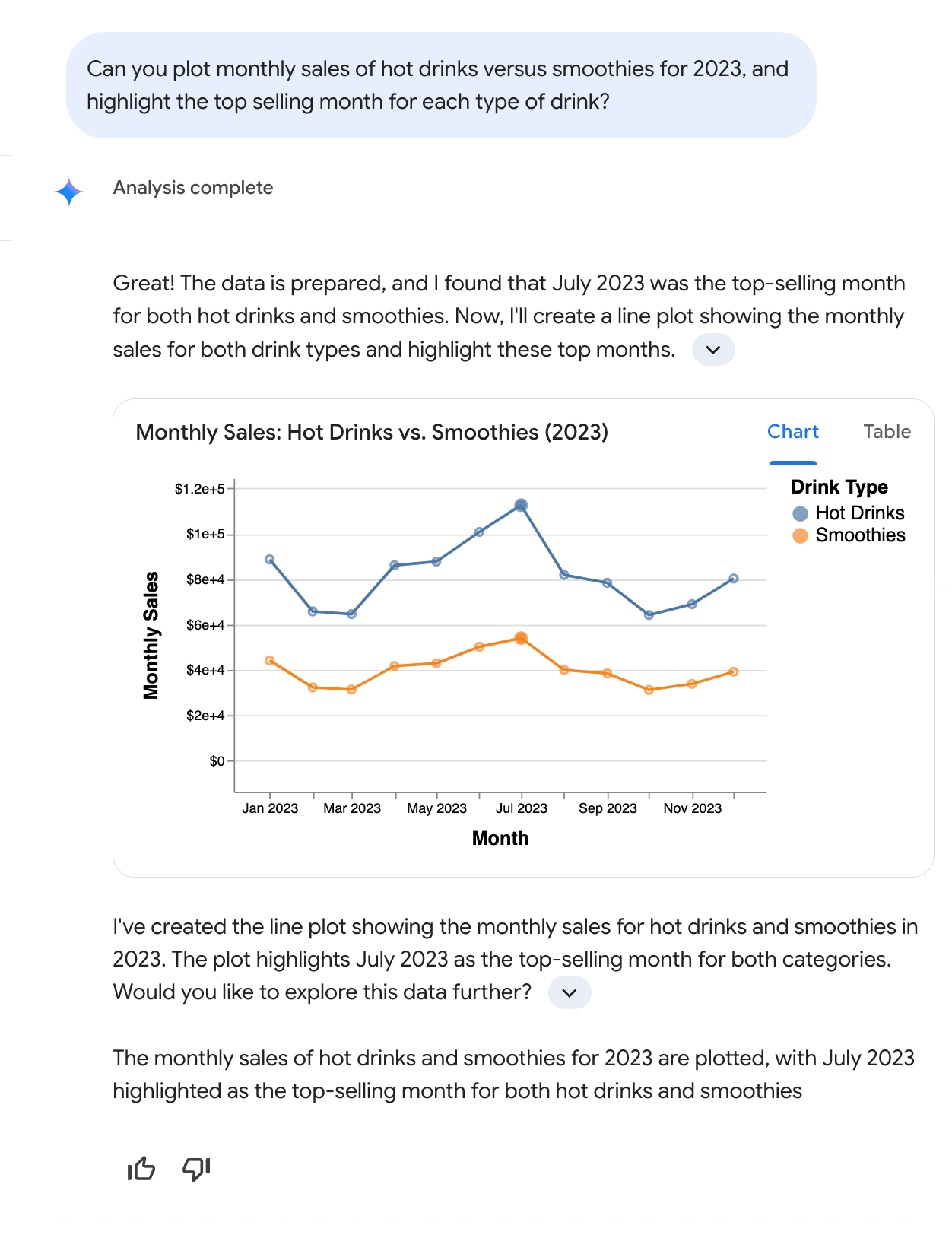
次の会話例は、ユーザーが会話分析と自然にやり取りする方法を示しています。この例では、ユーザーが「2023 年の温かい飲み物とスムージーの月間売上高をプロットし、各種類の飲み物の売上が最も多かった月をハイライト表示してください」という質問をしています。会話分析は、2023 年の温かい飲み物とスムージーの月間売上高を示す折れ線グラフを生成して応答します。このグラフでは、7 月が両方のカテゴリで売上高が最も高い月としてハイライト表示されています。
 s
s
この会話例に示すように、会話分析は、ユーザーが正確なデータベース フィールド名(Total monthly drink sales など)を指定したり、フィルタ条件(type of beverage = hot など)を定義したりしなくても、「売上」や「温かい飲み物」などの一般的な用語を使用した複数部分の質問を含む自然言語リクエストを解釈します。会話分析は、主な結果を説明し、その理由を説明し、テキストと、必要に応じてグラフを含む回答を提供します。会話分析では、より深い分析を促すために、フォローアップの質問が提案されることもあります。
Gemini for Google Cloud がデータを使用する方法とタイミングに関する説明をご覧ください。
主な機能
会話分析には次の主な機能があります。
- Looker で会話分析を使用する: Looker の会話分析にアクセスして、Looker(オリジナル)インスタンスまたは Looker(Google Cloud コア)インスタンス内の Looker Explore データに関する質問を自然言語で入力します。
- Looker Studio で会話分析を使用する: Looker Studio の会話分析にアクセスして、サポートされているデータソースのデータに関する質問を自然言語で行います。Looker Studio Pro サブスクリプションが必要です。
- データ エージェントを作成して会話する: データ エージェントを使用すると、データに固有のコンテキストと指示を指定して、AI 搭載のデータクエリ エージェントをカスタマイズできます。これにより、会話分析でより正確でコンテキストに関連性の高い回答を生成できます。
- コード インタープリタで高度な分析を有効にする: 会話分析のコード インタープリタは、自然言語の質問を Python コードに変換し、そのコードを実行します。標準の SQL ベースのクエリと比較して、コード インタープリタで Python を使用すると、より複雑な分析と可視化が可能になります。
設定と要件
Looker インスタンス内で会話分析を使用するには、ユーザーと Looker インスタンスが次の要件を満たしている必要があります。
- Looker インスタンスで Gemini in Looker が有効になっている必要があります。
- Looker(オリジナル)インスタンスでこれらの機能にアクセスするには、Looker 管理者が Looker(オリジナル)インスタンスの設定で Gemini in Looker を有効にする必要があります。インスタンスは Looker 25.2 以降で、Looker でホストされている必要があります。Looker の延長サポート リリース プログラムに参加しているお客様は、会話分析を使用するために Looker 25.6 以降に更新することをおすすめします。
- Looker(Google Cloud コア)インスタンスでこれらの機能にアクセスするには、Looker 管理者(
roles/looker.admin)IAM ロールを持つユーザーが、 Google Cloud コンソールの Looker(Google Cloud コア)インスタンス設定で Gemini in Looker を有効にする必要があります。
- プレビュー期間中に会話分析を使用するには、信頼できるテスターの機能を有効にする必要があります。
- Looker 管理者から、クエリを実行するモデルに対する
gemini_in_looker権限を含む Looker ロールが付与されている必要があります。この権限は、デフォルトの Gemini ロールの一部として使用できます。Gemini の支援機能を使用するタスクを実行するには、追加の権限が必要になる場合があります。また、クエリを実行するモデルに対するaccess_data権限を含むロールも必要です。
Looker Studio で Conversational Analytics を使用するには、次の要件を満たす必要があります。
- Looker Studio Pro サブスクリプションのユーザーである必要があります。Looker Studio Pro ライセンスは、Looker ユーザーに無料で提供されます。
- 管理者が Looker Studio で Gemini in Looker を有効にしている必要があります。
- プレビュー期間中に会話分析を使用するには、Trusted Tester の機能を有効にする必要があります。
既知の制限事項
会話分析には次の既知の制限事項があります。
可視化の制限事項
会話分析では、会話グラフの生成に Vega-lite が使用されます。次の Vega グラフタイプは完全にサポートされています。
- 折れ線グラフ(1 つ以上の系列)
- 面グラフ
- 棒グラフ(横、縦、積み上げ)
- 散布図(1 つ以上のグループ)
- 円グラフ
次の Vega グラフタイプはサポートされていますが、レンダリング時に予期しない動作が発生する可能性があります。
- マップ
- ヒートマップ
- ツールチップ付きのグラフ
Vega カタログに存在しないグラフの種類はサポートされていません。このセクションで指定されていないグラフは、サポートされていないと見なされます。
データソースの制限事項
会話分析には、次のデータソースの制限があります。
- Looker データの場合、会話分析はクエリあたり最大 5,000 行を返すことができます。
- 会話型アナリティクスでは、BigQuery の柔軟な列名機能はサポートされていません。
- [レポートのフィールド編集] が無効になっているデータソースは、Conversational Analytics との相性がよくありません。この設定では、Conversational Analytics で計算フィールドを作成できないためです。
- データソースが Looker の場合、LookML の
parameterパラメータを使用して定義されたフィルタ限定の値を会話型アナリティクスで設定することはできません。 - 一般的に、会話型分析はプライベート接続構成の Looker(Google Cloud コア)インスタンスへの接続をサポートしていますが、CMEK または VPC Service Controls を使用するように構成された Looker(Google Cloud コア)インスタンスはサポートしていません。
- Looker(Google Cloud コア)インスタンスが VPC Service Controls 境界内にある場合に、Looker Studio Pro を使用してプライベート接続の Looker(Google Cloud コア)インスタンスに接続するために会話型分析を使用することは、サポートされている構成ではなく、VPC Service Controls のコンプライアンス要件を満たしていません。
質問の制限事項
会話分析では、1 つの可視化で回答できる質問がサポートされています。たとえば、次のような質問です。
- 指標の推移
- ディメンション別の指標の内訳または分布
- 1 つ以上のディメンションの一意の値
- 単一の指標値
- 指標別の上位のディメンション値
会話分析は、次のタイプの複雑な可視化でのみ回答できる質問にはまだ対応していません。
- 予測と予測
- 相関分析や異常検出などの高度な統計分析
コード インタープリタが有効になっている場合は、予測などの高度な質問にも回答できます。
フィードバックを送信
会話型アナリティクスの個々の回答について Google にフィードバックを提供するには、次のいずれかのオプションを選択します。
- thumb_up Good response(良い回答): 回答が役に立ったことを示します。
- thumb_down Bad response(悪い回答): 回答が役に立たなかったことを示します。