人工知能(AI): わかりやすいガイド
どのようにしてスマートフォンが顔を認識できたり、ストリーミング サービスが次に自分が気に入る映画を正確に把握したり、自動車が自動運転できたりするのか、不思議に思ったことはありませんか?その答えは、人工知能(AI)です。
AI は、SF 世界の話でも、ご存じのよく利用されている chatbot に限ったことでもありません。数えきれないほど多くの方法で、私たちの日常生活の一部となっています。AI は現代のイノベーションを支えるエンジンとして機能し、現代において最も変革をもたらすテクノロジーの一つです。では、「人工知能」とは実際には何を意味するのでしょうか。
重要ポイント
AI を誰もが理解できるように分解してみましょう。
- AI とは: AI は、学習、推論、問題解決など、通常は人間の知能を必要とするタスクを実行できるスマートマシンを作成することに焦点を当てたコンピュータ サイエンスの分野です。
- 仕組み: AI システムは膨大な量のデータから学習し、パターンを特定することで、あらゆるシナリオに対して明示的にプログラミングしなくても予測や意思決定を行います。これは、100 万個のルールを記述する代わりに、100 万個の例を提示してコンピュータに学習させるようなものです。
- AI の活用例: Google マップなどのナビゲーション アプリ、ショッピング サイトでのパーソナライズされたおすすめ、メールの迷惑メールフィルタ、Gemini Live などのバーチャル アシスタントなど、私たちは毎日 AI を活用しています。
- 重要性: AI は、医学研究の加速から、より効率的なサプライ チェーンの構築、気候変動への取り組みまで、世界が直面する最も困難な課題の解決に役立ちます。
AI とは
AI は、コンピュータが、言語の理解、データの分析、さらには役立つ提案の提供など、これまで人間の知能を必要としていたさまざまな高度なタスクを学習、推論、実行できるようにする一連のテクノロジーです。これは世界中の人々や社会に有意義で前向きな変化をもたらすことのできる革新的な技術です。
AI は広範囲にわたる分野であり、そこにはコンピュータ サイエンス、データ分析と統計、ハードウェアおよびソフトウェア エンジニアリング、言語学、神経科学、さらには哲学や心理学などのさまざまな分野が包含されています。
AI とは、コンピュータに人間の脳と同じように、周囲の世界を理解したり、新しいことを学んだり、斬新なアイデアを生み出したりといった素晴らしいことをするように教えることです。たとえば、光学式文字認識(OCR)では、さまざまな画像やドキュメントからテキストやデータを抽出するために AI が使用されます。このプロセスでは、非構造化コンテンツが構造化されたビジネス対応のデータに変換され、貴重な分析情報を引き出すことができます。
AI の仕組み
AI 技術は多岐にわたりますが、そのすべてが基本的にデータ、アルゴリズム、コンピューティング能力に依存しています。AI システムは、膨大な量のデータを利用することで学習と改善を行い、人間が見逃す可能性のあるパターンや関係を特定します。このデータはトレーニング資料として機能し、その品質と量は AI のパフォーマンスにとって非常に重要です。
前述のように、AI は単一のテクノロジーではなく、いくつかの主要な領域にわたる広範な分野です。
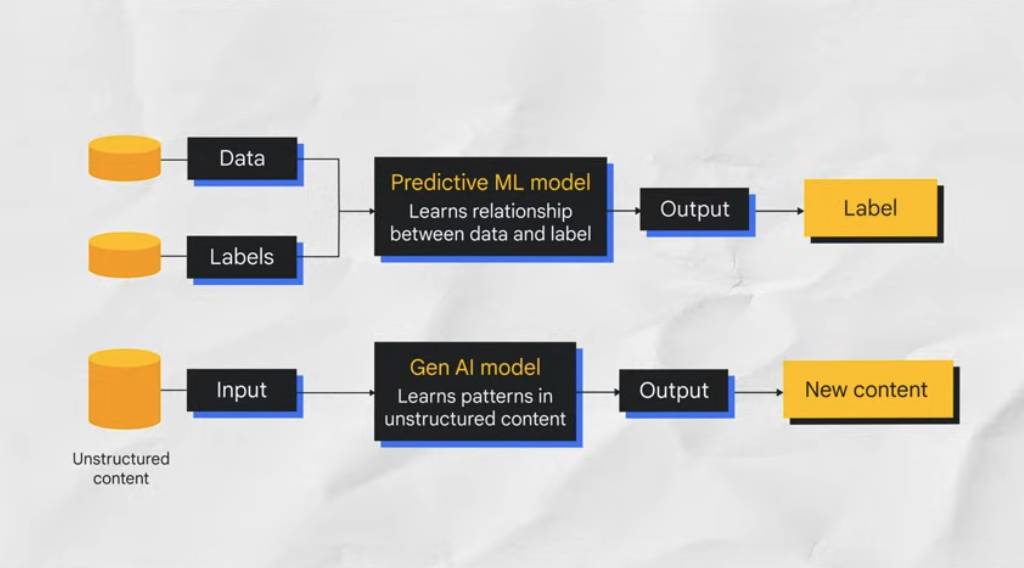
- ML(機械学習): これは AI の一種で、システムがデータから学習してパターンを特定し、直接プログラミングしなくても予測や意思決定を行います。何千枚もの鳥の画像を見せて、鳥を認識するようにコンピュータをトレーニングすると、コンピュータは鳥がどのようなものかを自分で学習します。
- ディープ ラーニング(DL): ML のサブ分野であるディープ ラーニングは、多くのレイヤを持つ(そのため「ディープ」)人工ニューラル ネットワークを使用してデータから学習します。人間の脳の構造に着想を得たこのネットワークは、画像認識や音声認識などの複雑なタスクに特に優れています。
- 自然言語処理(NLP): NLP により、コンピュータは人間の言語を理解、解釈、生成できます。これは Siri や Alexa などの音声アシスタント、翻訳サービス、chatbot の基盤となっています。
- コンピュータ ビジョン: この分野により、コンピュータは画像や動画などの視覚情報を「見て」解釈できます。顔認識から自動運転車まで、あらゆるものに使用されています。
AI の始め方を学びたいですか?初心者向けの無料講座生成 AI 入門を受講しましょう。
人工知能の種類
AI は、開発の段階または実行されるアクションに応じて、いくつかの形に整理できます。
AI の機能の種類
この分類では、インテリジェンス レベルと問題解決能力に基づいて AI モデルを定義します。
- 特化型人工知能(ANI): 現在存在する唯一の AI の形態です。ANI モデルは、画像の識別、チャット、メールのフィルタリングなど、単一の特定のタスクを実行するように設計されています。例としては、音声アシスタント、顔認識技術、Gemini などの生成 AI モデルやその他の大規模言語モデル(LLM)が挙げられます。名前とは裏腹に、ANI は推論や自己認識を持ちません。代わりに、データとアルゴリズムを組み合わせて、事前定義されたパラメータ内で予測を行います。ANI には多くのメリットがある一方で、リスクもあります。トレーニング データが不十分な場合、バイアスがかかった不正確な出力につながる可能性があります。これはローンの承認、採用の決定、予測ポリシングなどのアプリケーションでは重大な問題となります。サイバー犯罪者は、ANI を悪用して AI を活用した巧妙な詐欺行為をはたらく可能性もあります。
- 汎用人工知能(AGI): AI 技術の将来のステップとして提案されているものです。理論上、AGI は幅広いタスクを実行でき、人間のような推論を利用して学習、適応、改善を行います。AGI はまだ存在していません。ANI とは異なり、AGI は適応性、自律性、行動から学習する能力を備えていることが期待されています。架空の例としては、「スターウォーズ」のドロイドが挙げられます。しかし、AGI は安全性と倫理に関する重大な懸念を引き起こすことがあります。というのは、悪意のある行為者が有害な意図を持って AGI をプログラミングすると、規制がない場合、無限の破壊能力につながる可能性があります。
- 人工超知能(ASI): これは、AI の最も高度な理論上の形態です。ASI は、人間の制御を超えて動作する自己認識エンティティであり、推論、創造性、さらには感情的知性においても人間の知能をはるかに凌駕します。他の形式の AI と同様に、ASI が人類に存亡の危機をもたらす可能性があるという懸念があります。一部の AI 研究者は、人類の絶滅を含む極めて悪い結果が起こる可能性は無視できないと示唆しています。
機能別の AI の種類
この分類では、特定のコンテキストにおける AI の動作と対話に基づいて AI を分類します。
- リアクティブ マシン: 事前にプログラムされたルールに基づいて、さまざまな刺激にしか反応しない制限付き AI。メモリがないため、新しいデータから学習できません。有名な例として、1997 年にチェスの世界チャンピオンであるガルリ カスパロフを破った IBM のディープブルーがあります。
- メモリの制限: 最新の AI のほとんどはメモリが制限されています。AI は、通常は人工ニューラル ネットワークやその他のトレーニング モデルを通じて、新しいデータでトレーニングすることで、メモリを使用して時間の経過とともに改善できます。このメモリは短期的なもので、セッションが終了すると、メモリは多くの場合リセットされます。たとえば、自動運転車が他の車両を観察する場合や、Gemini のような chatbot が会話の以前のメッセージを記憶する場合が挙げられます。
- 心の理論: 心の理論 AI はまだ存在していませんが、その可能性を探る研究は続けられています。これは人間の心をエミュレートでき、人間と同等の意思決定機能を持つ AI を意味します。たとえば、社会的な状況において人間と同じように感情を認識して記憶し、対応できます。
AI の神話と現実
AI に関するよくある誤解を解いていきましょう。
誤解: AI には意識があり、感情がある
現実: AI システムは感情を処理し、シミュレートすることもできますが、意識、自己認識、真の感情は持ち合わせていません。これは複雑なパターン マッチング マシンです。
誤解: AI は常に客観的で偏りがない
現実: AI の品質は、トレーニングに使用するデータの質に左右されます。データが人間のバイアスを反映している場合、AI はそれを学習して助長します。
誤解: すべての技術職が AI に取って代わられる。
現実: AI は多くのタスクを自動化するのは確かですが、それだけでなく人間の能力を補強して、人間がより創造的で戦略的、共感的な仕事に時間を割けるようにしてくれます。
AI のメリット
自動化
自動化
AI は、ワークフローとプロセスを自動化したり、人間のチームから独立して自律的に作業したりできます。たとえば、AI は、ネットワーク トラフィックを継続的にモニタリングして分析することで、サイバーセキュリティの各側面を自動化できます。同様に、スマート ファクトリーには AI が何種類も使われています。たとえば、コンピュータ ビジョンを使用するロボットが工場の現場を移動したり製品の欠陥を検査する、デジタルツインを作成する、あるいは効率と出力を測定するためにリアルタイム分析を行う、といった用途に使用されています。
人的エラーの削減
人的エラーの削減
AI は、データ処理、分析、製造における組み立て、その他のタスクにおける手動によるエラーを、毎回同じプロセスに従う自動化とアルゴリズムによって最小化できます。
繰り返しのタスクを排除する
繰り返しのタスクを排除する
AI を使用して反復作業を行うことで、より複雑な問題に時間を費やすことができます。データの分析、ドキュメントの検証、電話の会話の文字起こし、コンテンツのモデレーション、「どこにありますか?」といったような顧客からの簡単な質問への回答など、AI は、このような反復的または手間のかかる業務を自動化することに優れています。
高速かつ正確
高速かつ正確
AI は人間よりも多くの情報を迅速に処理し、パターンを見つけ出し、人間が見落とす可能性のあるデータの関係性を検出できます。
無制限な可用性
無制限な可用性
AI は、時間帯、休憩の必要性、その他の人間のニーズに制限されません。クラウドで実行する場合、AI と ML は「常にオン」にでき、割り当てられたタスクに継続的に取り組みます。
研究開発の加速
研究開発の加速
大量のデータを迅速に分析する能力は、研究開発におけるブレークスルーの加速につながる可能性があります。たとえば、AI は潜在的な新しい医薬品治療の予測モデリングや、ヒトゲノムの定量化に役立ちます。
AI の活用事例: 世界を変革する
AI の影響は広範囲に及び、拡大し続けており、私たちの生活や産業のほぼあらゆる側面に及んでいます。次の分野でその影響を確認できます。
- 日常生活: スマートフォンのバーチャル アシスタント、ストリーミング サービスでのパーソナライズされたおすすめ、メールの迷惑メールフィルタ、Google マップなどのナビゲーション アプリは、すべて AI を活用して機能しています。
- ヘルスケア: AI は、医療画像の分析による病気の早期診断、治療計画のパーソナライズ、新薬開発の劇的な加速において医師を支援することで、医療に革命をもたらしています。
- 交通: 自動運転車は、安全に走行するために、ナビゲーション、物体検出、リアルタイムの意思決定に AI を使用してします。
- ビジネス オペレーション: 企業は、カスタマー サービスの chatbot や金融機関の不正行為の検出から、サプライ チェーンの最適化やマーケティング キャンペーンのパーソナライズまで、あらゆることに AI を使用しています。
- エンターテイメント: ビデオゲームでは、AI がよりリアルで難しいキャラクターを作成しています。コンテンツ制作では、生成 AI が作曲、脚本の執筆、美しいビジュアル アートの作成を行えるようになっています。
AI のユースケースをもっと知りたい方は、Google Cloud ブログで 1,000 件以上の実際の生成 AI ユースケースをご覧ください。
AI の歴史
自分で考えることができる機械というアイデアは、新しいものではありません。知性を持つ人工生命体の概念は数十年前から存在していましたが、現代の AI 分野が本格的に形になり始めたのは 20 世紀半ばです。AI の歴史を振り返ってみましょう。
- AI の萌芽(1940 年代~ 1950 年代): 1940 年代にプログラミング可能なコンピュータが発明されたことで、想像力が刺激されました。1950 年、アラン チューリングは「チューリング テスト」を提案しました。これは、機械が人間と区別できない知的な行動を見せられるかどうかを測る方法です。これは、哲学と科学の面で重要な一歩でした。
- 分野の誕生(1956 年): ジョン マッカーシーなどの先駆者によって組織されたダートマス夏季研究プロジェクトは、学術分野としての AI の正式な誕生として広く知られています。ここで「人工知能」という言葉が生まれました。
- 初期の成功と課題(1960 年代~ 1970 年代): 研究者たちは、会話をシミュレートできる chatbot である ELIZA や、環境について推論できる最初のロボットの一つである Shakey the Robot など、初期の AI プログラムを開発しました。しかし、真のインテリジェンスを構築する複雑さから、資金や進捗が低下する時期が訪れました。これは「AI の冬」と呼ばれることがよくあります。
- 復活と成長(1980 年代~ 2000 年代): エキスパート システムの開発と、その後の ML の台頭により、AI 研究に新たな活気がもたらされました。1997 年に IBM のディープブルーがチェスのグランドマスターを破ったなどのマイルストーンが、AI の能力が向上していることを示しました。
- 現代の AI ブーム(2010 年代~現在): コンピューティング能力の向上、膨大なデータセットの利用、ディープ ラーニング(特にニューラル ネットワーク)のブレークスルーが、現在の AI 革命を促進しています。この時代には、業界を変革する強力なツールが登場しました。
最近の動向: 生成 AI、LLM、AI エージェントの台頭
近年、AI の分野で最も注目すべき進歩として、生成 AI と大規模言語モデル(LLM)が挙げられます。しかし、AI エージェントとエージェント型 AI の登場により、フロンティアは急速に拡大しています。これらは、より自律的で有能な AI システムに向けた大きな一歩となります。
- 生成 AI: これは、データを分析するだけでなく、新しいコンテンツを作成する AI の一種です。AI アーティスト、AI ライター、AI コーダーのようなものだと考えてください。生成 AI は、膨大な量のデータ(テキスト、画像、コードなど)内のパターンと構造を学習し、その知識を使用して、プロンプトに基づいてまったく新しいオリジナル コンテンツを生成します。画像用の DALL-E やテキスト用の ChatGPT などのツールがその代表例です。
- 大規模言語モデル(LLM): これは、今日の最先端の AI アプリケーションの多くを支えるエンジンであり、特にテキストベースのタスクで活躍しています。LLM は、テキストとコードの膨大なデータセットでトレーニングされた大規模な AI モデルで、人間の言語を理解、生成、操作することに優れています。LLM は大量の情報を処理しているため、複雑な質問への回答、ドキュメントの要約、言語の翻訳、クリエイティブなコンテンツの作成のほか、コンピュータ コードの生成もできます。これらのモデルはますます高性能になっており、数学の問題を解いたりコードを書いたりといった「創発的能力」も発揮しています。とはいえ、デベロッパーは AI が生成したコードを必ず確認して検証するのが賢明です。LLM はマルチモーダル化も進んでおり、テキストだけでなく、画像、音声、動画も理解し、処理できるようになっています。
- AI エージェント: 環境を認識し、意思決定を行い、行動して特定の目標を達成するように設計された AI システムです。直接的なコマンドに応答するだけの単純な chatbot とは異なり、AI エージェントは次のようなことができます。
- 計画: 複雑な目標を、扱いやすい小さなステップに分解する
- 推論: 知識と理解力を使用して各ステップで意思決定を行う
- 行動: デジタル環境や物理環境と(API またはロボット インターフェース経由で)やり取りして計画を実行する
- 学習 / 適応: 経験から学習し、時間の経過とともにパフォーマンスを向上させる可能性がある
- エージェント AI: AI システムが上記のように自律的に動作する能力を指します。
AI エージェントはソフトウェア開発ツール、API、さらには既存のコードベースとやり取りするようにプログラムできるため、ソフトウェア デベロッパーにとってこれは特に興味深いものでしょう。これにより、新しい機能の自動テスト、コードの大部分のリファクタリング、プロジェクト ワークフローの管理など、AI がより複雑な開発タスクを支援する可能性が開かれます。現在進行中の研究では、エージェントの自律性が高まるにつれて、エージェントの信頼性、効率性、安全性を高めることに重点が置かれています。
関連プロダクトとサービス
Google は、信頼できるクラウド プラットフォーム上に高度な人工知能関連プロダクト、ソリューション、アプリケーションを多数提供し、企業が AI のアルゴリズムやモデルを簡単に構築して実装できるようにします。
Gemini Enterprise Agent Platform、CCAI、DocAI、AI API などのプロダクトを使用することで、組織は、作成、収集、分析しているデータを、形式を問わずにすべて理解して、有効なビジネス上の意思決定を行うことができます。
 すべての AI プロダクトとソリューションを見るGoogle の研究とテクノロジーを活用して、革新的な AI と機械学習のプロダクト、ソリューション、サービスを提供します。
すべての AI プロダクトとソリューションを見るGoogle の研究とテクノロジーを活用して、革新的な AI と機械学習のプロダクト、ソリューション、サービスを提供します。 Gemini Enterprise Agent Platform統合 AI プラットフォーム内のトレーニング済みのカスタムツールを使用して、ML モデルの構築、デプロイ、スケーリングを高速化します。
Gemini Enterprise Agent Platform統合 AI プラットフォーム内のトレーニング済みのカスタムツールを使用して、ML モデルの構築、デプロイ、スケーリングを高速化します。- Agent Studio生成 AI モデルを迅速にプロトタイピングおよびテストするためのツール
 Document AI大規模なデータ キャプチャを自動化してドキュメントの処理費用を削減します。
Document AI大規模なデータ キャプチャを自動化してドキュメントの処理費用を削減します。 AlloyDB AI使い慣れた PostgreSQL を使用して幅広い生成 AI アプリケーションを構築し、Agent Platform でモデルを実行します。
AlloyDB AI使い慣れた PostgreSQL を使用して幅広い生成 AI アプリケーションを構築し、Agent Platform でモデルを実行します。- Vision AI使いやすい REST API に高度な機械学習モデルを凝縮することで、画像の内容を把握できます。画像を何千ものカテゴリに高速に分類し、画像内の個々の物体や顔を検出して、印刷されたテキストを見つけて読み取ります。
- Customer Engagement Suite with Google AIお客様のことを理解し、お客様のニーズを予測し、あらゆるタッチポイントで優れたカスタマー エクスペリエンスを提供するエンドツーエンドの AI アプリケーションで、人間のようなパーソナライズされたエンゲージメントを実現してお客様の満足度を高めます。
- 会話エージェント個々のニーズに沿った自発的なセルフサービスを可能にする、人間のような自然な音声の会話型 AI エージェントを構築し、魅力的なカスタマー エクスペリエンスを実現できます。
開始にあたりサポートが必要な場合
お問い合わせ信頼できるパートナーと連携する
パートナーを探すGoogle から最新のニュースを受け取りたい場合
月刊ニュースレターに登録する


















