OCR (Optical Character Recognition)
OCR (Optical Character Recognition) with world-class Google Cloud AI
Extract text and data from images and documents, turn unstructured content into business-ready structured data, and unlock valuable insights.
Integrate OCR functionalities into your applications through APIs.
New customers get $300 in free credits on signup to apply towards document summarizing OCR solutions.
Overview
What is OCR?
Optical Character Recognition (OCR) is a foundational technology behind the conversion of typed, handwritten or printed text from images into machine-encoded text.
What types of OCR does Google Cloud offer?
Google Cloud offers two types of OCR: OCR for documents and OCR for images and videos.
While they share a foundational technology, Document AI is a document understanding platform optimized for document processing. Its Custom Extractor is powered by GenAI that processes both generic and domain-specific documents with higher accuracy and faster, without the need to choose a specialized processor.
Cloud Vision, is commonly used to detect text, handwriting and a wide range of objects from images and videos.
How does OCR work at Google Cloud?
Google Cloud powers OCR with best-in-class AI. It goes beyond traditional text recognition by understanding, organizing and enriching data, ultimately generating business-ready insights.
It gives you the flexibility to either use the OCR tools as a unified suite for streamlined efficiency (e.g. Document AI), or simply call the relevant APIs directly available in Google Cloud console to integrate OCR functionalities into your applications.
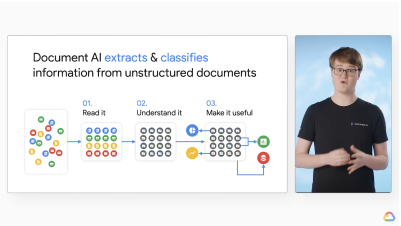
How Google Cloud AI and OCR work together?
All the OCR solutions mentioned above give you access to pre-trained ML models that you can deploy right away through an API, or uptrain to improve accuracy for your specific needs.
You can also train your own custom models with AutoML - no machine learning expertise needed.
Check out AutoML documentation on building custom ML models.
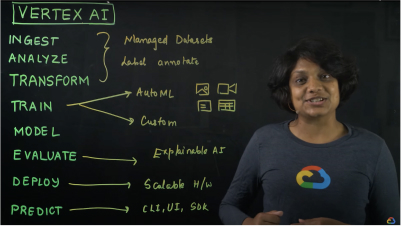
Which OCR solution is right for me?
If you are looking to analyze a document, or build an automated document processing pipeline, use Document AI—it takes care of the entire workflow all in one place, from understanding documents to search, store, govern and manage the documents alongside extracted data.
If you want to analyze and process images, use Cloud Vision alongside other Google Cloud products for best results—check the Common Uses section for details and quickstart guides.
Both APIs are free to try with a Google Cloud account.
Compare OCR offerings
| OCR offering | Best for | Key features | |
|---|---|---|---|
| General text-extraction use cases that require low latency and high capacity. | Pre-built features like image labeling, face & landmark detection, OCR, safe search. | |
Enterprise Document OCR | Digitize text from documents (PDFs, scanned documents as images, or Microsoft DocX files). | Extract text in 200+ languages, 50 handwritten languages. Add-ons to recognize math formulas, styles, etc. | |
| Document AI Workbench | Extract, classify and split any documents with generative ai (foundational models) | Custom Extractor: uses foundational models to quickly create parsers without extensive data labeling or training. Custom classifier and document splitter for efficient processing. |
| Pretrained models | Text and field extraction from domain-specific documents. | Text extraction and digitization across a variety of procurement, lending, identity and contractual documents. |
General text-extraction use cases that require low latency and high capacity.
Pre-built features like image labeling, face & landmark detection, OCR, safe search.
Enterprise Document OCR
Digitize text from documents (PDFs, scanned documents as images, or Microsoft DocX files).
Extract text in 200+ languages, 50 handwritten languages.
Add-ons to recognize math formulas, styles, etc.
Document AI Workbench
Extract, classify and split any documents with generative ai (foundational models)
Custom Extractor: uses foundational models to quickly create parsers without extensive data labeling or training.
Custom classifier and document splitter for efficient processing.
Pretrained models
Text and field extraction from domain-specific documents.
Text extraction and digitization across a variety of procurement, lending, identity and contractual documents.
How It Works
To understand and process documents, use Document AI.
For images, we recommend using Cloud Vision.
Both give you access to pre-trained ML models that you can deploy as-is through APIs or uptrain. You can also train your own custom models from scratch with AutoML - no ML expertise needed.
First 1000 units every month are free when you use Cloud Vision or Document OCR - try it with a simple API call.
To understand and process documents, use Document AI.
For images, we recommend using Cloud Vision.
Both give you access to pre-trained ML models that you can deploy as-is through APIs or uptrain. You can also train your own custom models from scratch with AutoML - no ML expertise needed.
First 1000 units every month are free when you use Cloud Vision or Document OCR - try it with a simple API call.
Demo
See Document OCR in action with your own documents
Try the Document AI API with a simple drag-and-drop.
Extract text from documents with gen AI
Unlock insights from nuanced documents with Document AI
Powered by a foundational model, Document AI Custom Extractor extracts text and data from documents, generic and domain-specific, faster and with higher accuracy. Easily fine-tune with just 5-10 documents for even better performance.
If you want to train your own model, auto-label your datasets with the foundational model for faster time to production.
You can also choose to use pre-trained specialized processors - see the full list of processors.




How-tos
Unlock insights from nuanced documents with Document AI
Powered by a foundational model, Document AI Custom Extractor extracts text and data from documents, generic and domain-specific, faster and with higher accuracy. Easily fine-tune with just 5-10 documents for even better performance.
If you want to train your own model, auto-label your datasets with the foundational model for faster time to production.
You can also choose to use pre-trained specialized processors - see the full list of processors.
Build an end-to-end document solution
Build a document processing and understanding pipeline
Powered by GenAI, Document AI delivers great accuracy in extracting data from documents of varying layouts and quality. You can connect it with Cloud Storage so your unstructured documents have enterprise-grade compliance. BigQuery helps batch process and analyze the extracted data any way you like. With Looker, you can easily build visualizations based on your BigQuery tables. Agent Search on Gemini Enterprise Agent Platform enables you to query and search your documents in Cloud Storage, conversationally or traditionally.
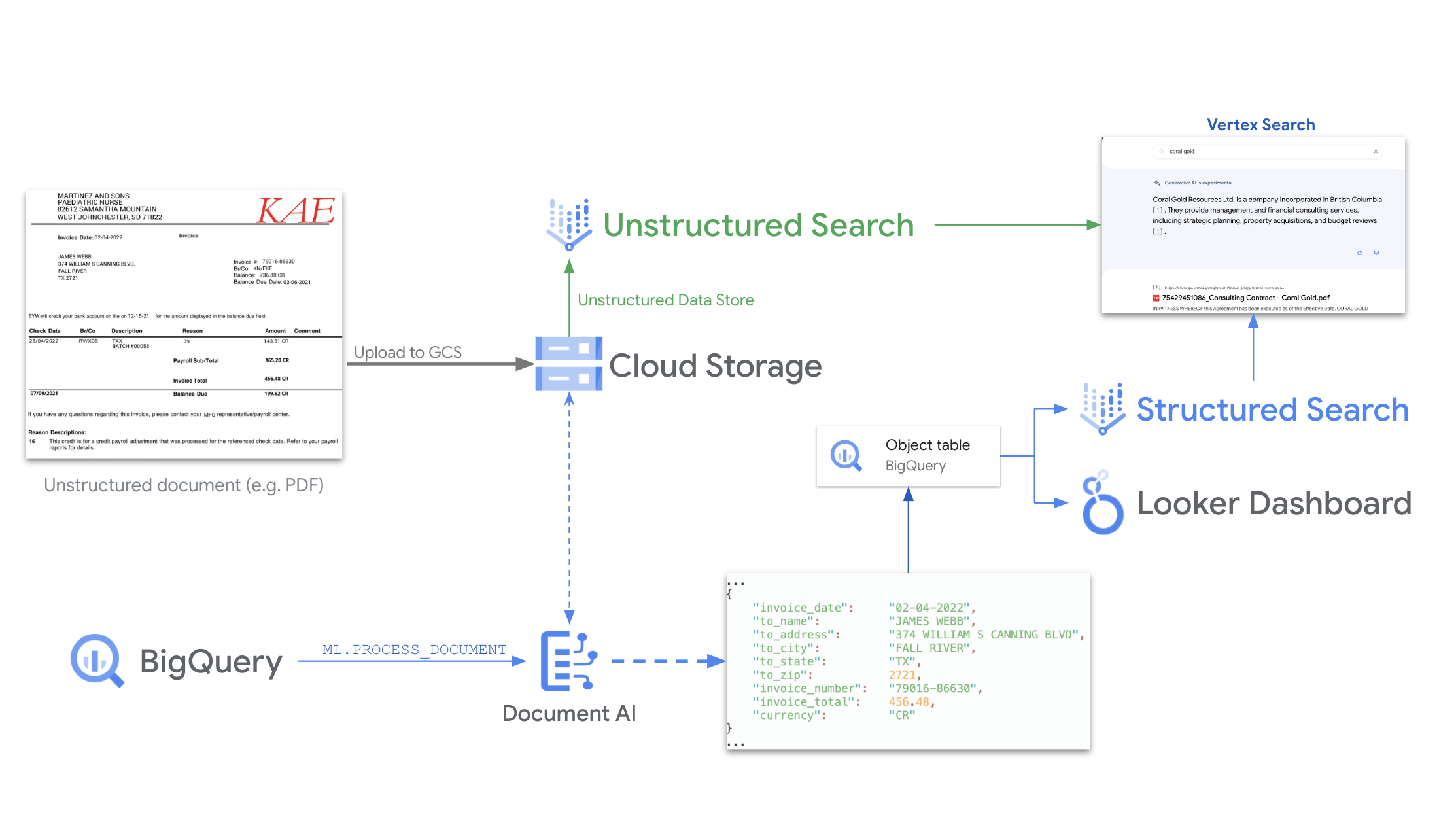

It takes 60-90 minutes to set up the entire pipeline as seen, the Document AI portion takes 10 minutes.
How-tos
Build a document processing and understanding pipeline
Powered by GenAI, Document AI delivers great accuracy in extracting data from documents of varying layouts and quality. You can connect it with Cloud Storage so your unstructured documents have enterprise-grade compliance. BigQuery helps batch process and analyze the extracted data any way you like. With Looker, you can easily build visualizations based on your BigQuery tables. Agent Search on Gemini Enterprise Agent Platform enables you to query and search your documents in Cloud Storage, conversationally or traditionally.
It takes 60-90 minutes to set up the entire pipeline as seen, the Document AI portion takes 10 minutes.
Image tagging, processing and search
Use Cloud Vision API and AutoML to tag and process images
Image tagging is also referred to as image labeling.
Cloud Vision API can identify and label general objects, landmarks, locations, logos, activities, animal species, products, and more in an image. Once the images are tagged with the detected labels, image search, processing and management are automated and easier.
If you need targeted custom labels, use Cloud AutoML to train a custom ML model.
To use Google OCR technologies on premise, use OCR On-Prem, available in the Cloud Marketplace.
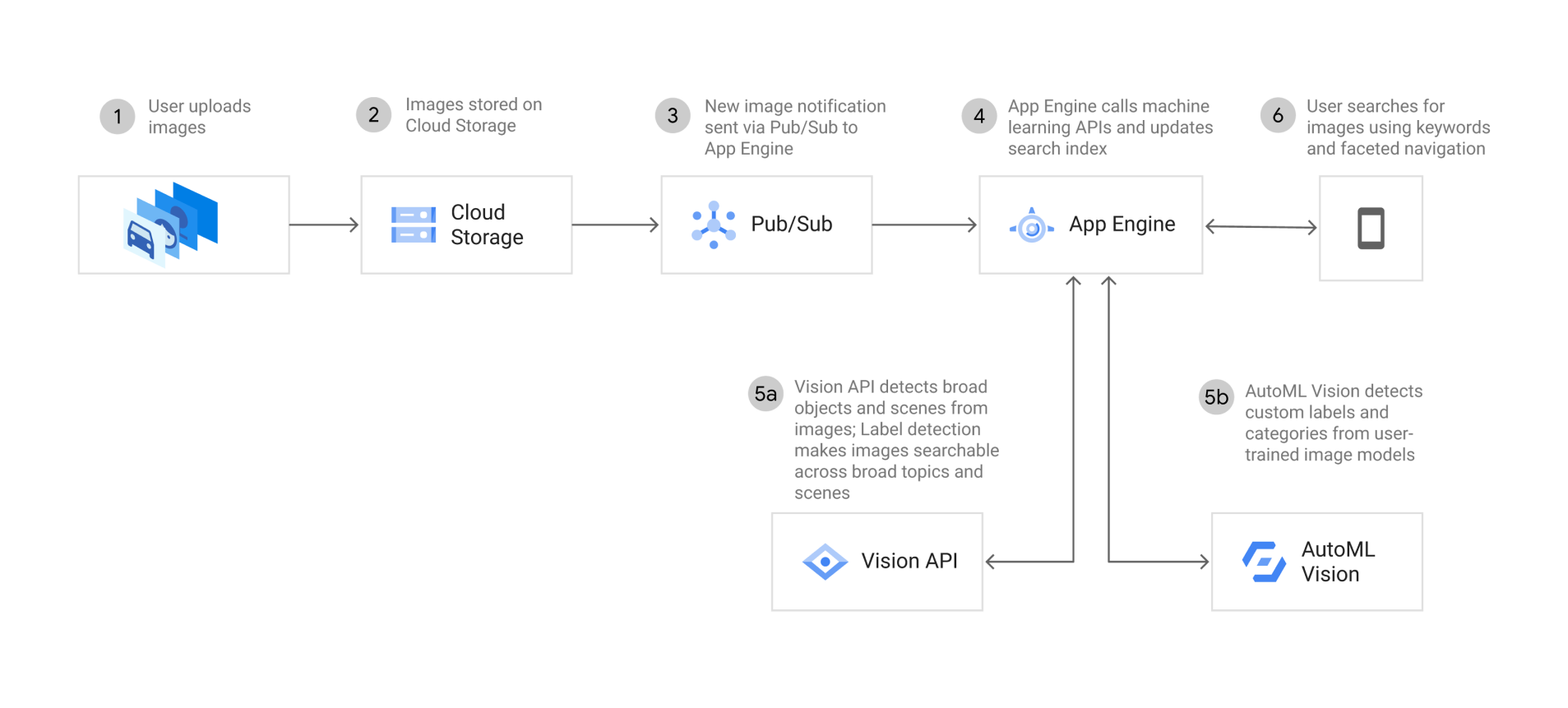



Pricing example
To run a basic image processing pipeline that detects labels as shown on the right, your monthly cost would be $27.36.
You can check the usage assumptions made to arrive at this number in the pricing calculator.
First 1,000 units per month is free.
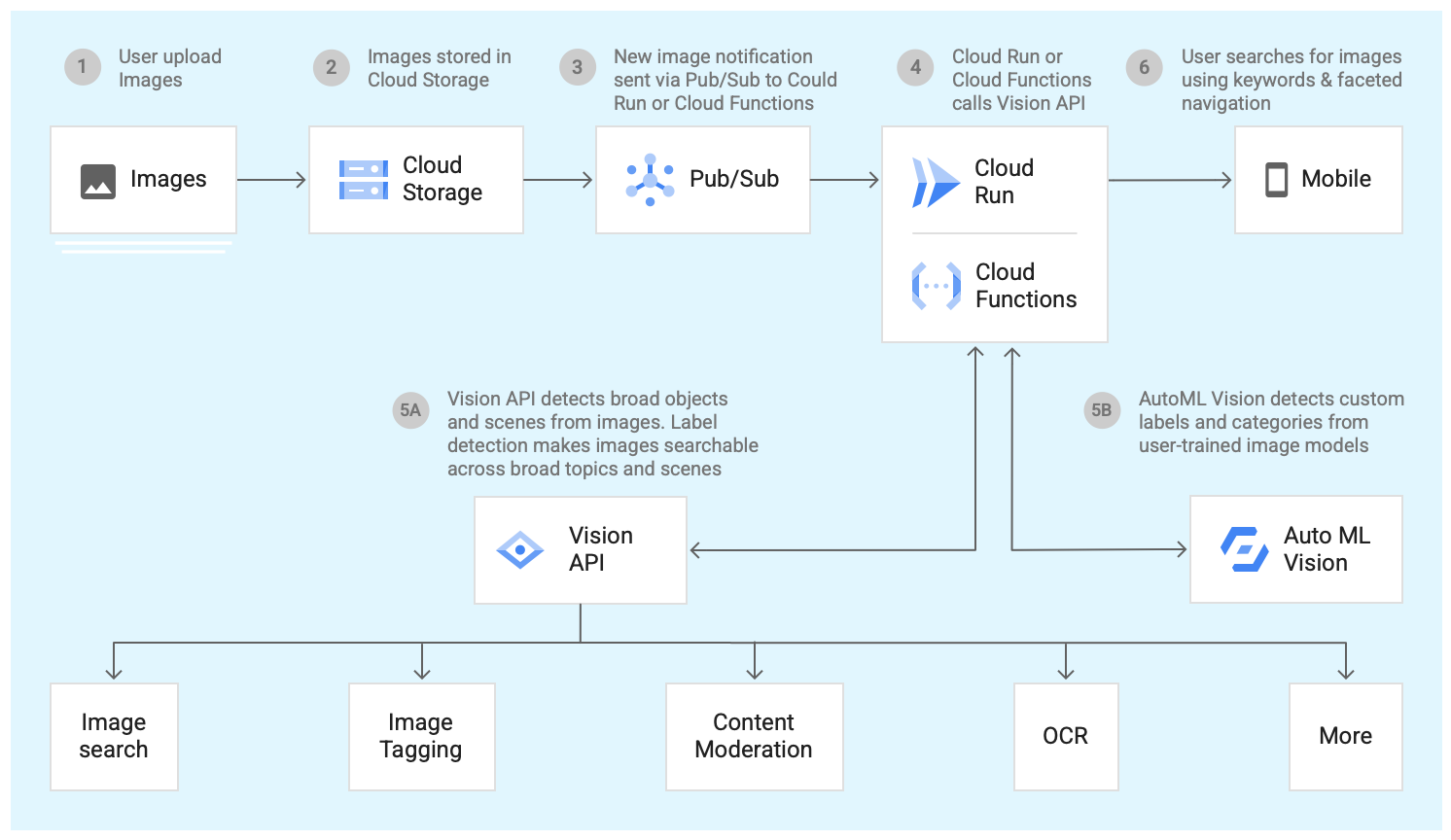
How-tos
Use Cloud Vision API and AutoML to tag and process images
Image tagging is also referred to as image labeling.
Cloud Vision API can identify and label general objects, landmarks, locations, logos, activities, animal species, products, and more in an image. Once the images are tagged with the detected labels, image search, processing and management are automated and easier.
If you need targeted custom labels, use Cloud AutoML to train a custom ML model.
To use Google OCR technologies on premise, use OCR On-Prem, available in the Cloud Marketplace.
Additional resources
Pricing example
To run a basic image processing pipeline that detects labels as shown on the right, your monthly cost would be $27.36.
You can check the usage assumptions made to arrive at this number in the pricing calculator.
First 1,000 units per month is free.
Extract text from images
Extract text from images with Cloud Vision API
Through Cloud Vision API, you can detect and extract text and handwriting from any images in different languages. It also has multi-region support for which you can specify continent-level data storage and OCR processing.
You can choose to get immediate results for a small number of images (up to 16 per request), or batch process a larger number of images (up to 2000 per request) asynchronously for a result later.


Pricing example
To run a basic processing pipeline that extracts text from images as shown on the right, your monthly cost would be $27.36.
You can check the usage assumptions made to arrive at this number in the pricing calculator.
First 1,000 units per month is free.
How-tos
Extract text from images with Cloud Vision API
Through Cloud Vision API, you can detect and extract text and handwriting from any images in different languages. It also has multi-region support for which you can specify continent-level data storage and OCR processing.
You can choose to get immediate results for a small number of images (up to 16 per request), or batch process a larger number of images (up to 2000 per request) asynchronously for a result later.
Additional resources
Pricing example
To run a basic processing pipeline that extracts text from images as shown on the right, your monthly cost would be $27.36.
You can check the usage assumptions made to arrive at this number in the pricing calculator.
First 1,000 units per month is free.
Pricing
| How much does my use case cost? | Understand your monthly cost to solve for a use case, with products you need and key usage assumptions laid out. | ||
|---|---|---|---|
| Use case | Products used | Usage assumptions | Estimated monthly cost (USD) |
Image tagging, processing and search | Cloud Vision Cloud Storage Pub/Sub Cloud Run | 1. 15,000 Cloud Vision label detection API calls monthly 2. 100 GiB monthly storage 3. One 1.25 GiB CPU 4. Four GiB published daily through Pub/Sub | $27.36 |
Extract text and insights from documents | Document AI Cloud Storage BigQuery Cloud Functions | 1. 1,000 Document AI form parser API calls monthly 2. 100 GiB monthly storage 3. 1 TiB monthly queries 4. RAM: 512 MB, CPU: 800 MHz | $71.87 |
Extract text from images | Cloud Vision Cloud Storage Pub/Sub Cloud Run | 1. 15,000 Cloud Vision OCR API calls monthly 2. 100 GiB monthly storage 3. One 1.25 GiB CPU 4. Four GiB published daily through Pub/Sub | $27.36 |
See full unit pricing details for Document AI, Vision API and AutoML.
How much does my use case cost?
Understand your monthly cost to solve for a use case, with products you need and key usage assumptions laid out.
Image tagging, processing and search
Cloud Vision
Cloud Storage
Pub/Sub
Cloud Run
1. 15,000 Cloud Vision label detection API calls monthly
2. 100 GiB monthly storage
3. One 1.25 GiB CPU
4. Four GiB published daily through Pub/Sub
$27.36
Extract text and insights from documents
Document AI
Cloud Storage
BigQuery
Cloud Functions
1. 1,000 Document AI form parser API calls monthly
2. 100 GiB monthly storage
3. 1 TiB monthly queries
4. RAM: 512 MB, CPU: 800 MHz
$71.87
Extract text from images
Cloud Vision
Cloud Storage
Pub/Sub
Cloud Run
1. 15,000 Cloud Vision OCR API calls monthly
2. 100 GiB monthly storage
3. One 1.25 GiB CPU
4. Four GiB published daily through Pub/Sub
$27.36
See full unit pricing details for Document AI, Vision API and AutoML.


















