Generative AI training and extraction lets you:
- Use zero-shot and few-shot technology to get a high performing model with little to no training data using the foundation model.
- Use fine-tuning to further boost accuracy as you provide more and more training data.
Generative AI training methods
The training method you choose depends on the amount of documents you have available and the amount of effort available to put into training your model. There are three ways to train a generative AI model:
| Training method | Zero-shot | Few-shot | Fine-tuning |
|---|---|---|---|
| Accuracy | Medium | Medium-high | High |
| Effort | Low | Low | Medium |
| Recommended number of training documents | 0 | 5 to 10 | 10 to 50+ |
Custom extractor model versions
The following models are available for custom extractor. To change model versions, see Manage processor versions.
Versions 1.4, 1.5 and 1.5 Pro support confidence scores.
| Model version | Description | Release channel | ML processing in US/EU | Fine-tuning in US/EU | Release date |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-02-05 |
GA model powered by the Gemini 2.0 Flash LLM. Also includes advanced OCR features such as checkbox detection. | Stable | Yes | US, EU | February 5, 2025 |
pretrained-foundation-model-v1.5-2025-05-05 |
Production-ready candidate powered by Gemini 2.5 Flash LLM. Recommended for those who want to experiment with newer models. | Stable | Yes | US, EU (Preview) | May 5, 2025 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
Production-ready model powered by the Gemini 2.5 Pro LLM. Supports a quota of up to 30 pages per minute for online process requests. This model has improved quality compared to v1.5, and may have a higher latency. | Stable | Yes | No | June 20, 2025 |
pretrained-foundation-model-v1.5.1-2025-08-07 |
Public preview model powered by the Gemini 2.5 Flash LLM. This model has the same features as v1.5, and has improved adaptive few-shot learning. | Release candidate | Yes | No | August 8, 2025 |
To change the processor version in your project, review Managing processor versions.
To make a Quota Increase Request (QIR) for the default processor quota, follow the steps in Manage your quota.
Initial setup
If not done so already, enable billing and the Document AI APIs.
Build and evaluate a generative AI model
Create a processor and define fields you want to extract following best practices, which is important because it impacts extraction quality.
- Go to Workbench > Custom extractor > Create processor > Assign a name.

- Go to Get started > Create new field.

Import documents
- Import documents with auto-labeling and assign documents to the training and test set.
- For zero-shot, only the schema is required. To evaluate the accuracy of the model, only a testing set is needed.
- For few-shot, we recommend five training documents.
- The number of needed testing documents depend on the use case. Generally, more testing documents is better.
- Confirm or edit the labels in the document.
Train model:
- Select the Build, then Create new version.
- Enter a name and select Create.

Evaluation:
- Go to Evaluate & test, select the version you just trained, then select View full evaluation.

- You now see metrics such as f1, precision, and recall for the entire document and each field.
- Decide if performance meets your production goals. If it does not then reevaluate training and testing sets.
Set a new version as default:
- Navigate to Manage versions.
- Select to expand the options, and then select Set as default.

Your model is now deployed. Documents sent to this processor use your custom version. You can evaluate the model's performance to check if it requires further training.
Evaluation reference
The evaluation engine can do both exact match or fuzzy matching. For an exact match, the extracted value must exactly match the ground truth or is counted as a miss.
Fuzzy matching extractions that had slight differences such as capitalization differences still count as a match. This can be changed at the Evaluation screen.

Fine-tuning
With fine-tuning, you use hundreds or thousands of documents for your training.
Create a processor and define fields you want to extract following best practices, which is important because it impacts extraction quality.
Import documents with auto-labeling, and assign documents to the training and test set.
Confirm or edit the labels in the document.
Train model.
- Select the Build tab, and select Create New Version in the Fine-tuning box.
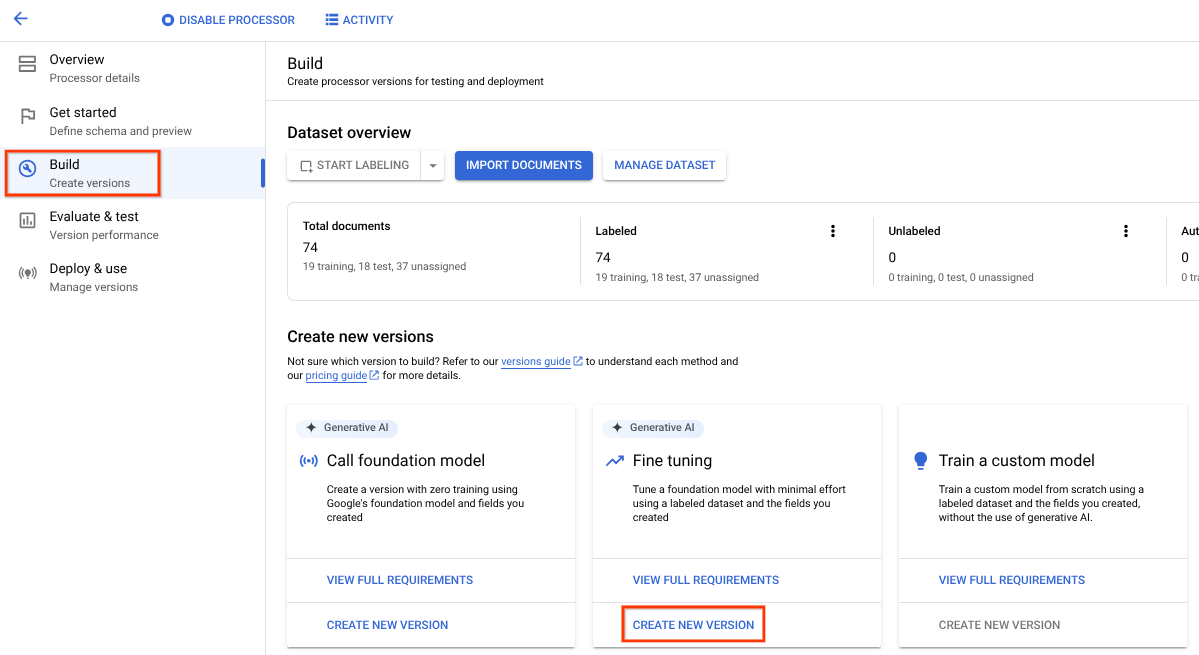
Try out the default training parameters or values provided. If the results are unsatisfactory, experiment with these advanced options:
Training steps (between 100 and 400): Controls how often the weights are optimized on a batch of data during the tuning.
- Too low indicates a risk that the training ends before convergence (under-fitting).
- Too high means the model might see the same batch of data multiple times during the training, which can lead to overfitting.
- Fewer steps leads to faster training time. Higher counts can help for documents with little template variation (and lower ones for those with more variation).
Learning rate multiplier (between 0.1 and 10): Controls how quickly the model parameters are optimized on the training data. It roughly corresponds to the size of each training step.
- Low rates mean small changes in the model weights at each training step. If too low, the model might not converge to a stable solution.
- High rates indicate large changes, and too high can mean the model steps over the optimal solution and converges instead to a suboptimal solution.
- Training time is not affected by the choice of learning rate.
Give a name, select the required base processor version, and select Create.

Evaluation: Go to Evaluate & test, then select the version you just trained and select View full evaluation.
- You now see metrics such as f1, precision, and recall for the entire document and each field.
- Decide if performance meets your production goals. If not, then further training documents might be required.
Set a new version as the default:
- Navigate to Manage versions.
- Select to expand the options, and select Set as default.
Your model is now deployed and documents sent to this processor now use your custom version. You want to evaluate the model's performance to check if it requires further training.
Auto-labeling with the foundation model
The foundation model can accurately extract fields for a variety of document types, but you can also provide additional training data to improve the accuracy of the model for specific document structures.
Document AI uses the label names you define and previous annotations to make it quicker and easier to label documents at scale with auto-labeling.
- When you've created a custom processor, go to the Get Started tab.
- Select Create New Field.
Give the label a descriptive, distinct name. Choose Extract for values directly from the document or Derive for values inferred by the system. This improves the foundation model's accuracy and performance.

For extraction accuracy and performance add a description (such as added context, insights, and prior knowledge for each entity) for the kinds of entities it should pick up.

Navigate to the Build tab, then select Import Documents.

Select the path of the documents and which set the documents should be imported into. Check the auto-labeling option and select the foundation model.
In the Build tab, select Manage Dataset.
When you see your imported documents, select one of them.

The predictions from the model are now shown highlighted in purple.
- Review each label predicted by the model, and verify it's correct.
If there are missing fields, add those as well.

When the document has been reviewed, select Mark as Labeled. The document is now ready to be used by the model.
Make sure the document is in either the testing or training set.
Three-level nesting
Custom Extractor now provides three levels of nesting. This feature provides better extraction for complex tables.
You can determine the model type using the following API calls:
The response of these is a ProcessorVersion, which contains the modelType field in v1beta3 preview.
Procedure and example
We are using this sample:

Select Get Started, and then create a field:
- Create the top level.
- In this sample, the
officer_appointmentsis used. - Select This is a parent label.
- Select Occurrence:
Optional multiple.



Select Add child field. The second level label can now be created:
- For this level label, create
officer. - Select This is a parent label.
- Select Occurrence:
Optional multiple.


- For this level label, create
Select Add child field from second level
officer. Create child labels for the third level of nesting.
When your schema is set, you can get predictions from documents with three levels of nesting using auto-labeling.


Label cross-page nested entities
The pretrained-foundation-model-v1.5-2025-05-05 processor supports three-level nesting across
pages.
Label an entity normally across a page. Note: The labeled entity will only be visible on the page where it's labeled, with the navigation bar changing page to page. By pinning the parent entity, this navigation bar persists.
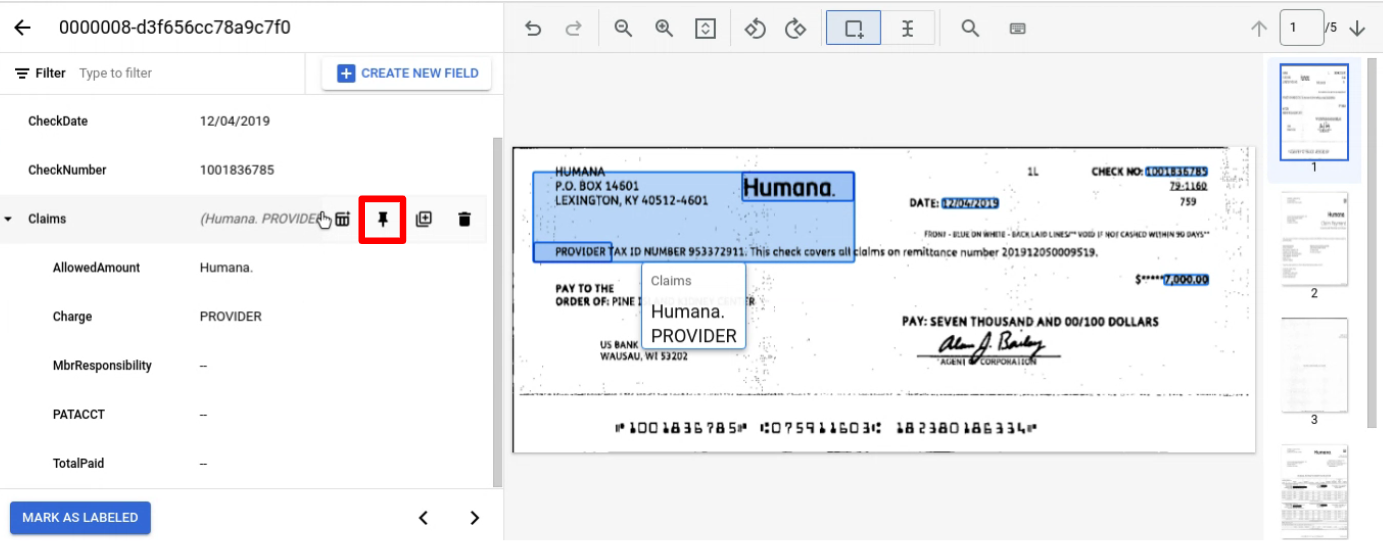
Pin the parent entity with children you want to label across pages.
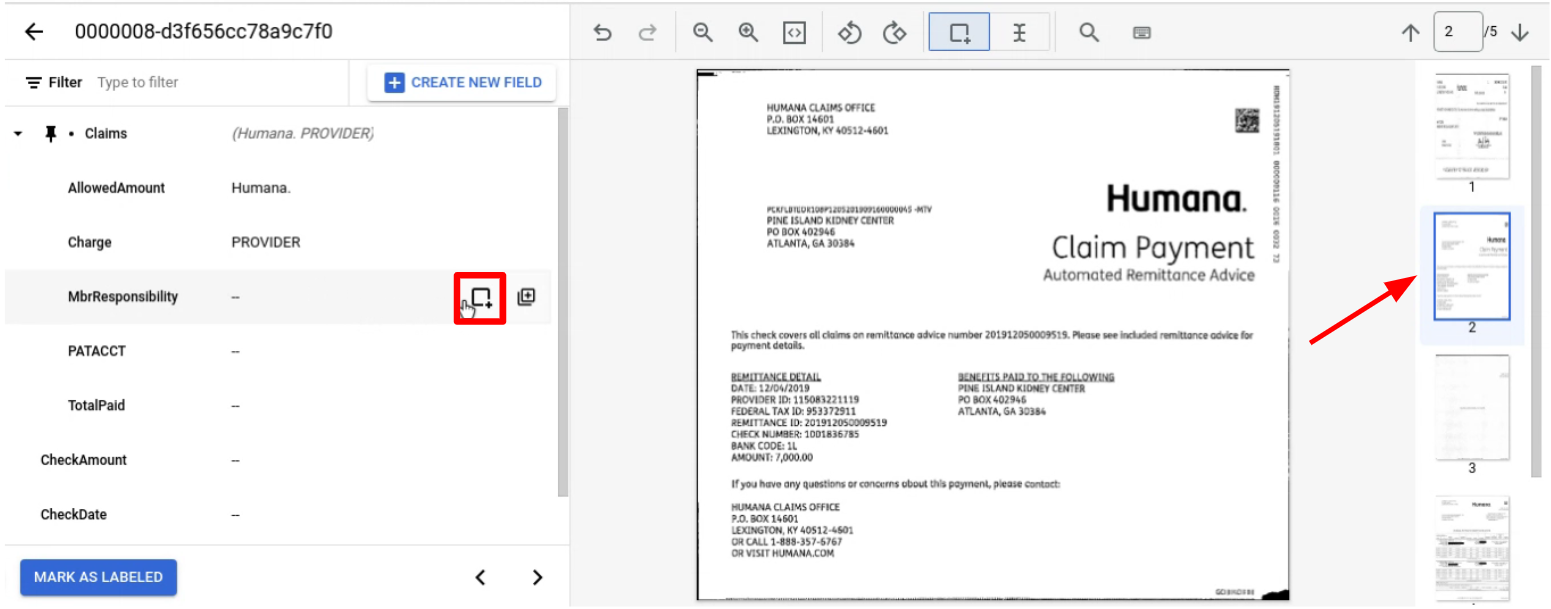
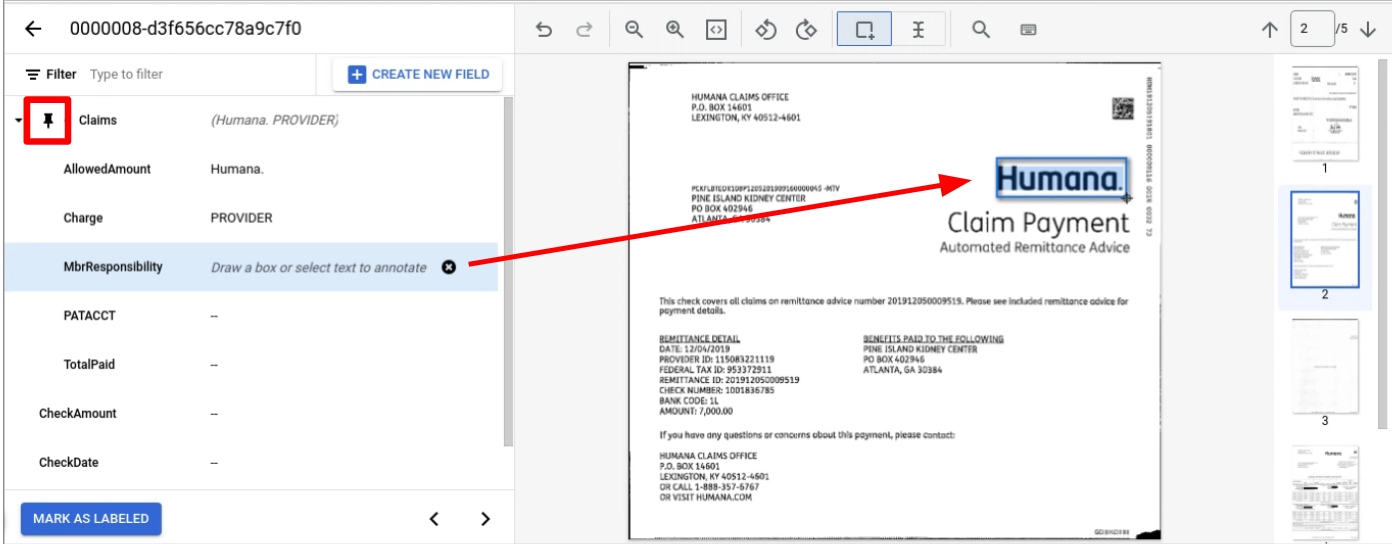
Navigate to the page with the child entity or entities to label.
Dataset configuration
A document dataset is required to train, up-train, or evaluate a processor version. Document AI processors learn from examples, just like humans. Dataset fuels processor stability in terms of performance.Train dataset
To improve the model and its accuracy, train a dataset on your documents. The model is made up of documents with ground-truth.- For fine-tuning, you need a minimum of 1 document to train a new model with version
for
pretrained-foundation-model-v1.2-2024-05-10andpretrained-foundation-model-v1.3-2024-08-31. - For a few-shot, five documents is recommended.
- For zero-shot, only a schema is required.
Test dataset
The test dataset is what the model uses to generate an F1 score (accuracy). It is made up of documents with ground-truth. To see how often the model is right, the ground truth is used to compare the model's predictions (extracted fields from the model) with the correct answers. The test dataset should have at least one document forpretrained-foundation-model-v1.2-2024-05-10 and
pretrained-foundation-model-v1.3-2024-08-31.
Custom extractor with property descriptions
With property descriptions, you can train a model by describing what the labeled fields are like. You can provide additional context and insights for each entity. This allows the model to train by matching fields that fit the description you provide and improve extraction accuracy. Property descriptions can be specified for both parent and child entities.
Good examples of property descriptions include location information and text patterns of the property values, which help disambiguate potential sources of confusion in the document. Clear and precise property descriptions guide the model with rules that promote more reliable and consistent extractions, regardless of the specific document structure or content variations.
Update document schema for a processor
For how to set the property descriptions, refer to Update document schema.
Send a processing request with property descriptions
If the document schema already has descriptions set, you can send a process request with the instructions at Send a processing request.
Fine-tune a processor with property descriptions
Before using any of the request data, make the following replacements:
- LOCATION: your processor's location, for example:
us- United Stateseu- European Union
- PROJECT_ID: Your Google Cloud project ID.
- PROCESSOR_ID: the ID of your custom processor.
- DISPLAY_NAME: Display name for the processor.
- PRETRAINED_PROCESSOR_VERSION: the processor version identifier. Refer to Select a processor version for more information. For example:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS: Training steps for model fine-tuning.
- LEARN_RATE_MULTIPLIER: Learning rate multiplier for model finetuning.
- DOCUMENT_SCHEMA: Schema for the processor. Refer to DocumentSchema representation.
HTTP method and URL:
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Request JSON body:
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
To send your request, choose one of these options:
curl
Save the request body in a file named request.json,
and execute the following command:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Save the request body in a file named request.json,
and execute the following command:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Custom extractor with signature detection
(Public preview) Custom extractor supports
signature detection. This feature lets you detect the presence of
signatures in the documents. Signature detection is available only by using the
derived method type. You can specify a schema with the entity type signature
for such entities. The signature entities are derived using visual cues from
the document.
For examples and configuration instructions, click Custom extractor with derived field and signature detection.
Custom extractor with derived fields
The custom extractor supports derived fields. It lets you configure a field to be populated through intelligent inference or generation based on document context, rather than direct text extraction. You can employ this for use cases such as deducing the country from an address, summarizing a document, counting items in a table, or detecting if an ID is authentic, without requiring the value to be explicitly present in the text.
For examples and configuration instructions, click Custom extractor with derived field and signature detection.
What's next
Learn about Custom extractor with derived field and signature detection.