Form Parser extracts key-value pairs (KVPs), tables, selection marks (like checkboxes), generic fields, and text to augment and automate document processing.
Form Parser can be considered over the other parsers when the use case involves:
- Dealing with structured forms: It excels at extracting KVPs from
well-defined forms that look like conventional forms with labeled blanks to fill
in, such as
name: __. Form Parser's pre-trained model offers high accuracy for common fields like names, dates, and addresses. - Flexible table extraction is needed: Form Parser extracts from simple (no cells that span rows or columns) tables that look like tables. No training is needed (nor possible). For trained table extraction, the custom extractor can be used with a parent field containing column (cell) child fields.
- Need efficiency: Avoid building and maintaining extraction parsers, especially for high-volume and varied forms of extraction tasks.
Data-extraction features
Form Parser features encompass:
KVP: These are sets of two items within a document—a label or key and its corresponding data (a value). You can directly use KVPs (if the keys are consistent) or build custom logic to resolve varied keys into consistent structured information.
Generic entities: Parse 11 different fields from documents out of the box. These include:
emailphoneurldate_timeaddresspersonorganizationquantitypriceidpage_number
Text and layout: Use our latest OCR engine to extract text and layout information. This includes embedded text from digital PDFs (v2.1 only) or text from images.
Tables: Detect and extract tables from images and PDFs.
Checkboxes: A high-quality selection mark detector, which extracts checkboxes from images and PDF output as KVP, using the text nearest the checkbox, with a
valueTypeindicating whether it is filled or unfilled.
Languages and regions
- Form Parser 2.0 supports over 200 languages. Learn more.
- We provide feature support in eight regions. Learn more.
Model versions
The following processor versions are compatible with this feature. For more information, see Managing processor versions.
Limitations
Prior JPEG compressions for TIFF are unsupported. Type of JPEG encapsulation defined by the TIFF version 6.0 specification.
The checkbox model doesn't support parsing radio buttons. Some detected checkboxes might not have corresponding keys.
The model doesn't reliably parse a KVP with an unfilled value, such as a blank form.
The KVP parsing on documents in certain languages may have lower quality than Latin languages.
Process documents with Form Parser
This quickstart introduces you to the Form Parser feature in Document AI. In this quickstart, you use the Google Cloud console to set up your Google Cloud project and authorization, create a Form Parser, and then make a request for Document AI to process a PDF form.
Learn how to:
Enable Document AI in a Google Cloud project.
Create a Form Parser processor, which can identify and extract text, key-value pairs, tables, and generic entities from many types of documents.
Use the processor to annotate a sample document.
To follow step-by-step guidance for this task directly in the Google Cloud console, click Guide me:
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Create a Form Parser processor
Use the Google Cloud console to create a Form Parser processor. See creating and managing processors for more information.
In the Google Cloud console navigation menu, click Document AI and select Processor Gallery.
In the Processor Gallery,
search for Form Parser and select Create.
In the side window, enter a Processor name, such as
quickstart-form-processor.Select the region closest to you.
Click the Create button.
You're taken to the Processor Details page of your new form parser processor.
Test processor
After creating your processor, you can send annotation requests to it.
-
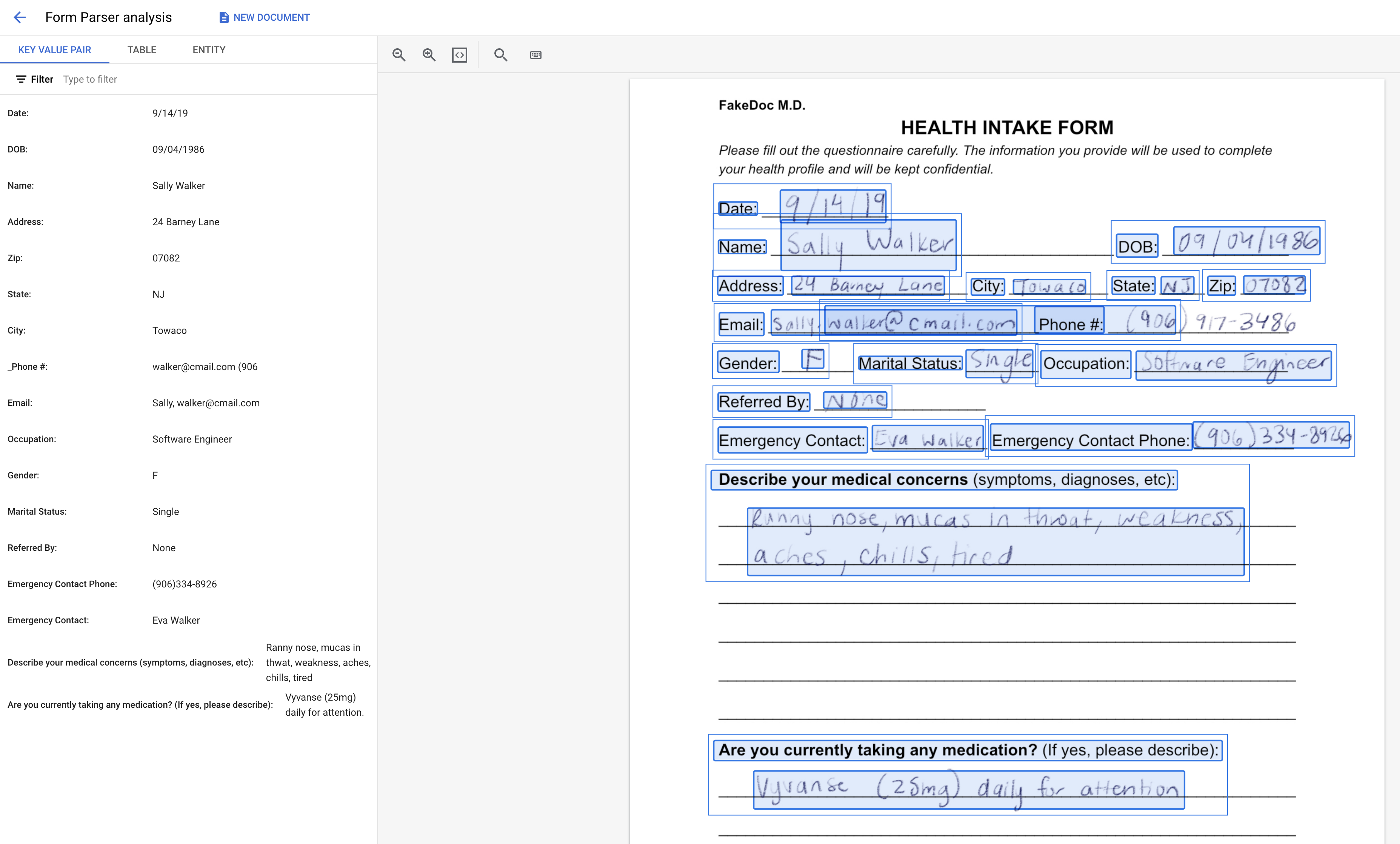
It's a PDF file containing a sample handwritten medical intake form. This document is stored in a publicly accessible Cloud Storage bucket.
Click the
Upload Test Document button and select the document you just downloaded.You should now be on the Form Parser analysis page. You can view the OCR detected text, key-value pairs, tables, and generic entities extracted from the document.
Clean up
To avoid unnecessary Google Cloud charges, use the Google Cloud console to delete your processor and project if you don't need them.
What's next
- Review the Processors list.