Tutorial ini menunjukkan cara menayangkan model bahasa besar (LLM) menggunakan Unit Pemrosesan Tensor (TPU) di Google Kubernetes Engine (GKE) dengan framework penayangan vLLM. Dalam tutorial ini, Anda akan menayangkan Llama 3.1 70b, menggunakan TPU Trillium, dan menyiapkan penskalaan otomatis Pod horizontal menggunakan metrik server vLLM.
Dokumen ini adalah titik awal yang baik jika Anda memerlukan kontrol terperinci, skalabilitas, ketahanan, portabilitas, dan efektivitas biaya Kubernetes terkelola saat Anda men-deploy dan menayangkan beban kerja AI/ML.
Latar belakang
Dengan menggunakan TPU Trillium di GKE, Anda dapat menerapkan solusi inferensi yang tangguh dan siap produksi dengan semua manfaat Kubernetes terkelola, termasuk skalabilitas yang efisien dan ketersediaan yang lebih tinggi. Bagian ini menjelaskan teknologi utama yang digunakan dalam panduan ini.
TPU Trillium
TPU adalah sirkuit terintegrasi khusus aplikasi (ASIC) yang dikembangkan khusus oleh Google. TPU digunakan untuk mempercepat model machine learning dan AI yang dibangun menggunakan framework seperti TensorFlow, PyTorch, dan JAX. Tutorial ini menggunakan TPU Trillium, yang merupakan TPU generasi keenam Google.
Sebelum menggunakan TPU di GKE, sebaiknya selesaikan jalur pembelajaran berikut:
- Pelajari arsitektur sistem TPU Trillium.
- Pelajari TPU di GKE.
vLLM
vLLM adalah framework open source yang sangat dioptimalkan untuk menyajikan LLM. vLLM dapat meningkatkan throughput penyajian di TPU, dengan fitur seperti berikut:
- Implementasi transformer yang dioptimalkan dengan PagedAttention.
- Batch berkelanjutan untuk meningkatkan throughput penayangan secara keseluruhan.
- Paralelisme tensor dan penayangan terdistribusi di beberapa TPU.
Untuk mempelajari lebih lanjut, lihat dokumentasi vLLM.
Cloud Storage FUSE
Cloud Storage FUSE menyediakan akses dari cluster GKE Anda ke Cloud Storage untuk bobot model yang berada di bucket penyimpanan objek. Dalam tutorial ini, bucket Cloud Storage yang dibuat awalnya akan kosong. Saat vLLM dimulai, GKE akan mendownload model dari Hugging Face dan meng-cache bobot ke bucket Cloud Storage. Saat Pod dimulai ulang, atau penskalaan deployment, pemuatan model berikutnya akan mendownload data yang di-cache dari bucket Cloud Storage, dengan memanfaatkan download paralel untuk performa yang optimal.
Untuk mempelajari lebih lanjut, lihat dokumentasi driver CSI Cloud Storage FUSE.
Membuat cluster GKE
Anda dapat menayangkan LLM di TPU dalam cluster GKE Autopilot atau Standard. Sebaiknya gunakan cluster Autopilot untuk pengalaman Kubernetes yang terkelola sepenuhnya. Untuk memilih mode operasi GKE yang paling sesuai untuk workload Anda, lihat Memilih mode operasi GKE.
Autopilot
Buat cluster GKE Autopilot:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
Standar
Buat cluster GKE Standar:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriverBuat node pool slice TPU:
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE membuat resource berikut untuk LLM:
- Cluster Standar GKE yang menggunakan Workload Identity Federation untuk GKE dan telah mengaktifkan driver CSI Cloud Storage FUSE.
- TPU Trillium node pool dengan jenis mesin
ct6e-standard-8t. Node pool ini memiliki satu node, delapan chip TPU, dan penskalaan otomatis diaktifkan.
Mengonfigurasi kubectl untuk berkomunikasi dengan cluster Anda
Untuk mengonfigurasi kubectl agar dapat berkomunikasi dengan cluster Anda, jalankan perintah berikut:
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
Buat Secret Kubernetes untuk kredensial Hugging Face
Membuat namespace. Anda dapat melewati langkah ini jika menggunakan namespace
default:kubectl create namespace ${NAMESPACE}Buat Secret Kubernetes yang berisi token Hugging Face, jalankan perintah berikut:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
Membuat bucket Cloud Storage
Jalankan perintah berikut di Cloud Shell:
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
Tindakan ini akan membuat bucket Cloud Storage untuk menyimpan file model yang Anda download dari Hugging Face.
Menyiapkan Akun Layanan Kubernetes untuk mengakses bucket
Buat Akun Layanan Kubernetes:
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Berikan akses baca-tulis ke Akun Layanan Kubernetes untuk mengakses bucket Cloud Storage:
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"Atau, Anda dapat memberikan akses baca-tulis ke semua bucket Cloud Storage dalam project:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE membuat resource berikut untuk LLM:
- Bucket Cloud Storage untuk menyimpan model yang didownload dan cache kompilasi. Driver CSI Cloud Storage FUSE membaca konten bucket.
- Volume dengan caching file diaktifkan dan fitur download paralel dari Cloud Storage FUSE.
Praktik terbaik: Gunakan cache file yang didukung oleh
tmpfsatauHyperdisk / Persistent Diskbergantung pada perkiraan ukuran konten model, misalnya, file bobot. Dalam tutorial ini, Anda akan menggunakan cache file Cloud Storage FUSE yang didukung oleh RAM.
Men-deploy server model vLLM
Untuk men-deploy server model vLLM, tutorial ini menggunakan Deployment Kubernetes. Deployment adalah objek Kubernetes API yang memungkinkan Anda menjalankan beberapa replika Pod yang didistribusikan di antara node dalam cluster.
Periksa manifes Deployment berikut yang disimpan sebagai
vllm-llama3-70b.yaml, yang menggunakan satu replika:Jika Anda menskalakan Deployment ke beberapa replika, penulisan serentak ke
VLLM_XLA_CACHE_PATHakan menyebabkan error:RuntimeError: filesystem error: cannot create directories. Untuk mencegah error ini, Anda memiliki dua opsi:Hapus lokasi cache XLA dengan menghapus blok berikut dari YAML Deployment. Artinya, semua replika akan mengompilasi ulang cache.
- name: VLLM_XLA_CACHE_PATH value: "/data"Menskalakan Deployment ke
1, dan menunggu replika pertama siap dan menulis ke cache XLA. Kemudian, lakukan penskalaan ke replika tambahan. Hal ini memungkinkan replika yang tersisa untuk membaca cache, tanpa mencoba menulisnya.
Terapkan manifes dengan menjalankan perintah berikut:
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}Lihat log dari server model yang sedang berjalan:
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}Output-nya akan terlihat seperti berikut:
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Menyajikan model
Untuk mendapatkan alamat IP eksternal layanan VLLM, jalankan perintah berikut:
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})Berinteraksi dengan model menggunakan
curl:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'Outputnya akan mirip dengan berikut ini:
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Menyiapkan autoscaler kustom
Di bagian ini, Anda akan menyiapkan penskalaan otomatis Pod horizontal menggunakan metrik Prometheus kustom. Anda menggunakan metrik Google Cloud Managed Service for Prometheus dari server vLLM.
Untuk mempelajari lebih lanjut, lihat Google Cloud Managed Service for Prometheus. Fitur ini harus diaktifkan secara default di cluster GKE.
Siapkan Adaptor Stackdriver Metrik Kustom di cluster Anda:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlTambahkan peran Monitoring Viewer ke akun layanan yang digunakan oleh Custom Metrics Stackdriver Adapter:
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSimpan manifes berikut sebagai
vllm_pod_monitor.yaml:Terapkan ke cluster:
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
Membuat beban pada endpoint vLLM
Buat beban ke server vLLM untuk menguji cara GKE melakukan penskalaan otomatis dengan metrik vLLM kustom.
Jalankan skrip bash (
load.sh) untuk mengirimkanNjumlah permintaan paralel ke endpoint vLLM:#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitGanti PARALLEL_PROCESSES dengan jumlah proses paralel yang ingin Anda jalankan.
Jalankan skrip bash:
chmod +x load.sh nohup ./load.sh &
Pastikan bahwa Google Cloud Managed Service for Prometheus menyerap metrik
Setelah Google Cloud Managed Service for Prometheus meng-scrape metrik dan Anda menambahkan beban ke endpoint vLLM, Anda dapat melihat metrik di Cloud Monitoring.
Di konsol Google Cloud , buka halaman Metrics explorer.
Klik < > PromQL.
Masukkan kueri berikut untuk mengamati metrik traffic:
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
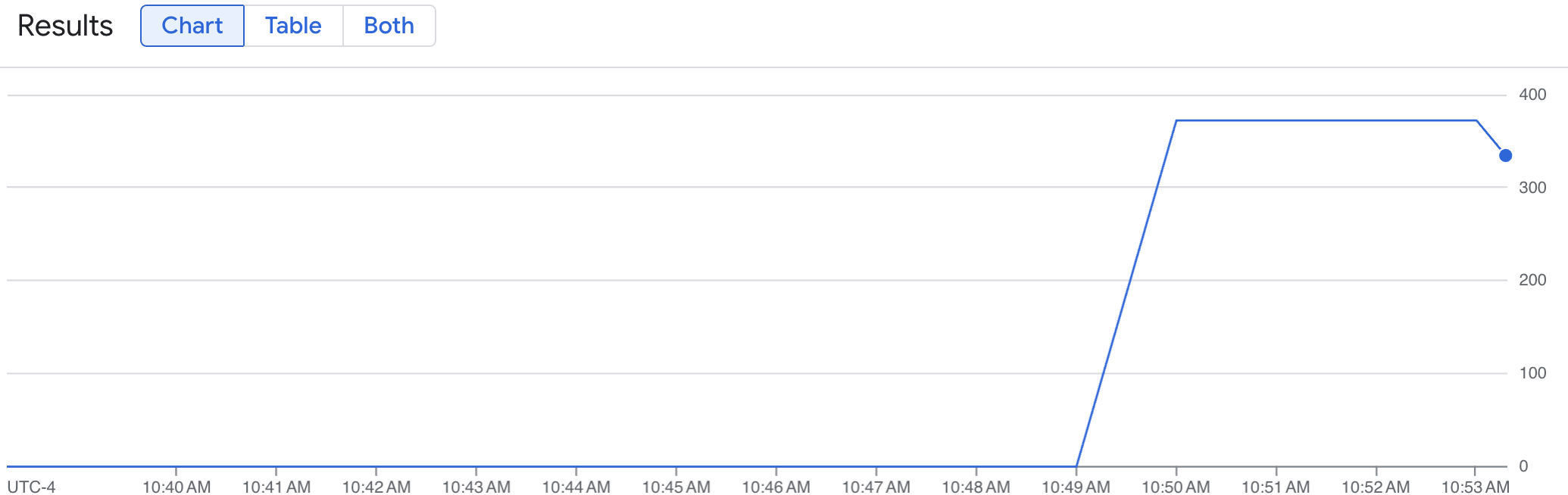
Grafik garis menampilkan metrik vLLM Anda (num_requests_waiting) yang diukur dari waktu ke waktu. Metrik vLLM diukur dari 0 (pra-pemuatan) hingga nilai (pasca-pemuatan). Grafik ini mengonfirmasi bahwa metrik vLLM Anda diserap ke Google Cloud Managed Service for Prometheus. Grafik contoh berikut menunjukkan nilai pra-muat awal 0, yang mencapai nilai pasca-muat maksimum mendekati 400 dalam waktu satu menit.
Men-deploy konfigurasi Horizontal Pod Autoscaler
Saat memutuskan metrik mana yang akan digunakan untuk penskalaan otomatis, sebaiknya gunakan metrik berikut untuk TPU vLLM:
num_requests_waiting: Metrik ini terkait dengan jumlah permintaan yang menunggu dalam antrean server model. Jumlah ini mulai bertambah secara signifikan saat cache kv penuh.gpu_cache_usage_perc: Metrik ini terkait dengan pemanfaatan cache kv, yang secara langsung berkorelasi dengan jumlah permintaan yang diproses untuk siklus inferensi tertentu di server model. Perhatikan bahwa metrik ini berfungsi sama di GPU dan TPU, meskipun terikat pada skema penamaan GPU.
Sebaiknya gunakan num_requests_waiting saat mengoptimalkan throughput dan biaya, serta saat target latensi dapat dicapai dengan throughput maksimum server model Anda.
Sebaiknya gunakan gpu_cache_usage_perc jika Anda memiliki workload yang sensitif terhadap latensi dan penskalaan berbasis antrean tidak cukup cepat untuk memenuhi persyaratan Anda.
Untuk penjelasan lebih lanjut, lihat Praktik terbaik untuk penskalaan otomatis workload inferensi model bahasa besar (LLM) dengan TPU.
Saat memilih averageValuetarget untuk konfigurasi HPA, Anda harus menentukannya secara eksperimental. Lihat postingan blog Hemat GPU: Penskalaan otomatis yang lebih cerdas untuk workload inferensi GKE Anda untuk mendapatkan ide tambahan tentang cara mengoptimalkan bagian ini. profile-generator yang digunakan dalam postingan blog ini juga berfungsi untuk vLLM TPU.
Dalam petunjuk berikut, Anda men-deploy konfigurasi HPA menggunakan metrik num_requests_waiting. Untuk tujuan demonstrasi, Anda menetapkan metrik ke nilai rendah sehingga konfigurasi HPA menskalakan replika vLLM Anda menjadi dua. Untuk men-deploy konfigurasi Horizontal Pod Autoscaler menggunakan num_requests_waiting, ikuti langkah-langkah berikut:
Simpan manifes berikut sebagai
vllm-hpa.yaml:Metrik vLLM di Google Cloud Managed Service for Prometheus mengikuti format
vllm:metric_name.Praktik terbaik: Gunakan
num_requests_waitinguntuk menskalakan throughput. Gunakangpu_cache_usage_percuntuk kasus penggunaan TPU yang sensitif terhadap latensi.Deploy konfigurasi Horizontal Pod Autoscaler:
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE menjadwalkan Pod lain untuk di-deploy, yang memicu autoscaler node pool untuk menambahkan node kedua sebelum men-deploy replika vLLM kedua.
Lihat progres penskalaan otomatis Pod:
kubectl get hpa --watch -n ${NAMESPACE}Outputnya mirip dengan hal berikut ini:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77sTunggu selama 10 menit dan ulangi langkah-langkah di bagian Verifikasi bahwa Google Cloud Managed Service for Prometheus menyerap metrik. Google Cloud Managed Service for Prometheus kini menyerap metrik dari kedua endpoint vLLM.