Halaman ini menjelaskan metrik dan dasbor yang tersedia untuk memantau latensi startup workload Google Kubernetes Engine (GKE) dan node cluster yang mendasarinya. Anda dapat menggunakan metrik untuk melacak, memecahkan masalah, dan mengurangi latensi startup.
Halaman ini ditujukan untuk admin dan operator Platform yang perlu memantau dan mengoptimalkan latensi startup workload mereka. Untuk mempelajari lebih lanjut peran umum yang kami rujuk dalam konten, lihat Peran dan tugas pengguna GKE umum. Google Cloud
Ringkasan
Latensi startup sangat memengaruhi cara aplikasi Anda merespons lonjakan traffic, seberapa cepat replikanya pulih dari gangguan, dan seberapa efisien biaya pengoperasian cluster dan workload Anda. Memantau latensi startup workload dapat membantu Anda mendeteksi penurunan kualitas latensi dan melacak dampak update workload dan infrastruktur terhadap latensi startup.
Mengoptimalkan latensi startup beban kerja memberikan manfaat berikut:
- Menurunkan latensi respons layanan Anda kepada pengguna selama lonjakan traffic.
- Mengurangi kapasitas penayangan berlebih yang diperlukan untuk menyerap lonjakan permintaan saat replika baru dibuat.
- Mengurangi waktu tidak ada aktivitas resource yang sudah di-deploy dan menunggu resource yang tersisa untuk dimulai selama komputasi batch.
Sebelum memulai
Sebelum memulai, pastikan Anda telah melakukan tugas berikut:
- Aktifkan Google Kubernetes Engine API. Aktifkan Google Kubernetes Engine API
- Jika ingin menggunakan Google Cloud CLI untuk tugas ini,
instal lalu
lakukan inisialisasi
gcloud CLI. Jika sebelumnya Anda telah menginstal gcloud CLI, dapatkan versi terbaru dengan menjalankan perintah
gcloud components update. Versi gcloud CLI yang lebih lama mungkin tidak mendukung menjalankan perintah dalam dokumen ini.
Aktifkan Cloud Logging dan Cloud Monitoring API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Persyaratan
Untuk melihat metrik dan dasbor latensi startup workload, cluster GKE Anda harus memenuhi persyaratan berikut:
- Anda harus memiliki GKE versi 1.31.1-gke.1678000 atau yang lebih baru.
- Anda harus mengonfigurasi pengumpulan metrik sistem.
- Anda harus mengonfigurasi pengumpulan log sistem.
- Aktifkan kube state metrics dengan
komponen
PODdi cluster Anda untuk melihat metrik Pod dan container.
Peran dan izin yang diperlukan
Untuk mendapatkan izin yang diperlukan guna mengaktifkan pembuatan log serta mengakses dan memproses log, minta administrator untuk memberi Anda peran IAM berikut:
-
Melihat cluster, node, dan beban kerja GKE:
Kubernetes Engine Viewer (
roles/container.viewer) di project Anda -
Akses metrik latensi startup dan lihat dasbor:
Monitoring Viewer (
roles/monitoring.viewer) di project Anda -
Akses log dengan informasi latensi, seperti peristiwa pengambilan image Kubelet, dan lihat di Logs Explorer dan Log Analytics:
Logs Viewer (
roles/logging.viewer) di project Anda
Untuk mengetahui informasi selengkapnya tentang cara memberikan peran, baca artikel Mengelola akses ke project, folder, dan organisasi.
Anda mungkin juga bisa mendapatkan izin yang diperlukan melalui peran khusus atau peran bawaan lainnya.
Metrik latensi startup
Metrik latensi startup disertakan dalam metrik sistem GKE dan diekspor ke Cloud Monitoring di project yang sama dengan cluster GKE.
Nama metrik Cloud Monitoring dalam tabel ini harus diawali dengan
kubernetes.io/. Awalan tersebut telah dihilangkan dari
entri dalam tabel.
| Jenis metrik (Tingkat hierarki resource) Nama tampilan |
|
|---|---|
|
Jenis, Tipe, Unit
Resource yang dimonitor |
Deskripsi Label |
pod/latencies/pod_first_ready
(project)
Latensi siap pertama pod |
|
GAUGE, Double, s
k8s_pod |
Latensi startup end-to-end Pod (dari Pod Created hingga Ready), termasuk penarikan image. Dibuat sampelnya setiap 60 detik. |
node/latencies/startup
(project)
Latensi startup node |
|
GAUGE, INT64, s
k8s_node |
Total latensi startup node, dari CreationTimestamp instance GCE hingga Kubernetes node ready untuk pertama kalinya. Dibuat sampelnya setiap 60 detik.accelerator_family: klasifikasi node berdasarkan akselerator hardware: gpu, tpu, cpu.
kube_control_plane_available: apakah permintaan pembuatan node diterima saat KCP (kube control plane) tersedia.
|
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(project)
Latensi penskalaan per rekomendasi HPA |
|
GAUGE, DOUBLE, s
k8s_scale |
Latensi rekomendasi penskalaan Horizontal Pod Autoscaler (HPA) (waktu antara metrik dibuat dan rekomendasi penskalaan yang sesuai diterapkan ke apiserver) untuk target HPA. Dibuat sampelnya setiap 60 detik. Setelah sampelnya dibuat, data tidak akan terlihat selama maksimal 20 detik.metric_type: jenis sumber metrik. Nilainya harus salah satu dari "ContainerResource", "External", "Object", "Pods", atau "Resource".
|
Melihat dasbor Latensi Startup untuk beban kerja
Dasbor Latensi Startup untuk workload hanya tersedia untuk Deployment. Untuk melihat metrik latensi startup untuk Deployment, lakukan langkah-langkah berikut di konsol Google Cloud :
Buka halaman Workloads.
Untuk membuka tampilan Detail deployment, klik nama workload yang ingin Anda periksa.
Klik tab Observability.
Pilih Latensi Startup dari menu di sebelah kiri.
Melihat distribusi latensi startup Pod
Latensi startup Pod mengacu pada total latensi startup, termasuk penarikan image, yang mengukur waktu dari status Created Pod hingga status Ready. Anda dapat menilai latensi startup Pod menggunakan
dua diagram berikut:
Diagram Distribusi Latensi Startup Pod: diagram ini menampilkan persentil latensi startup Pod (persentil kelima puluh, persentil kesembilan puluh lima, dan persentil kesembilan puluh sembilan) yang dihitung berdasarkan pengamatan peristiwa startup Pod selama interval waktu 3 jam tetap, misalnya, 00.00-03.00 dan 03.00-06.00. Anda dapat menggunakan diagram ini untuk tujuan berikut:
- Pahami latensi startup Pod dasar Anda.
- Mengidentifikasi perubahan latensi startup Pod dari waktu ke waktu.
- Korelasikan perubahan latensi startup Pod dengan peristiwa terbaru, seperti peristiwa Deployment Workload atau Cluster Autoscaler. Anda dapat memilih peristiwa dalam daftar Anotasi di bagian atas dasbor.
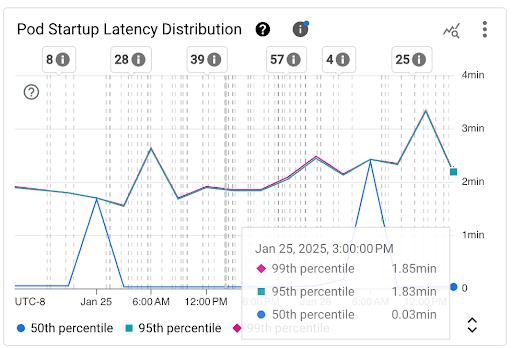
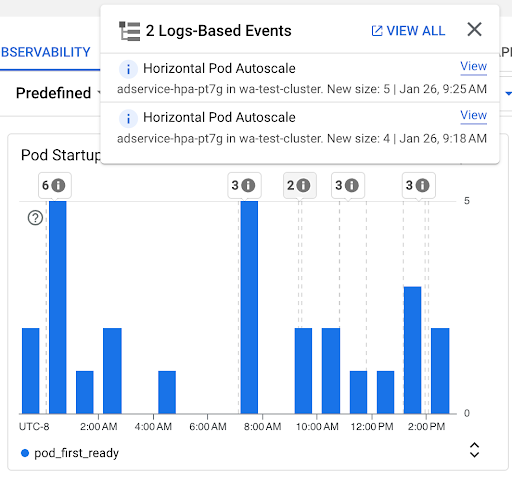
Diagram Jumlah Startup Pod: diagram ini menampilkan jumlah Pod yang dimulai selama interval waktu yang dipilih. Anda dapat menggunakan diagram ini untuk tujuan berikut:
- Memahami ukuran sampel Pod yang digunakan untuk menghitung persentil distribusi latensi startup Pod untuk interval waktu tertentu.
- Pahami penyebab Pod dimulai, seperti Deployment Workload atau peristiwa Horizontal Pod Autoscaler. Anda dapat memilih peristiwa dalam daftar Anotasi di bagian atas dasbor.
Melihat latensi startup setiap Pod
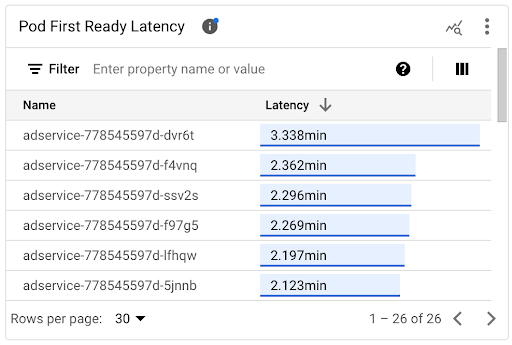
Anda dapat melihat latensi startup setiap Pod pada diagram linimasa Pod First Ready Latency dan daftar terkait.
- Gunakan diagram linimasa Latensi Siap Pod Pertama untuk mengorelasikan setiap mulai Pod dengan peristiwa terbaru, seperti peristiwa Horizontal Pod Autoscaler atau Cluster Autoscaler. Anda dapat memilih peristiwa ini dalam daftar Anotasi di bagian atas dasbor. Diagram ini membantu Anda menentukan potensi penyebab perubahan latensi startup dibandingkan dengan Pod lainnya.
- Gunakan daftar Latensi Pod Siap Pertama untuk mengidentifikasi setiap Pod yang memerlukan waktu paling lama atau paling singkat untuk dimulai. Anda dapat mengurutkan daftar berdasarkan kolom Latensi. Saat mengidentifikasi Pod yang memiliki latensi startup tertinggi, Anda dapat memecahkan masalah penurunan latensi dengan mengorelasikan peristiwa mulai Pod dengan peristiwa terbaru lainnya.
Anda dapat mengetahui kapan Pod dibuat dengan melihat nilai di kolom timestamp dalam peristiwa pembuatan Pod yang sesuai. Untuk melihat kolom
timestamp, jalankan kueri berikut di
Logs Explorer:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
Untuk mencantumkan semua peristiwa pembuatan Pod untuk beban kerja Anda, gunakan filter berikut
dalam kueri sebelumnya:
protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Saat membandingkan latensi setiap Pod, Anda dapat menguji dampak berbagai konfigurasi pada latensi startup Pod dan mengidentifikasi konfigurasi optimal berdasarkan persyaratan Anda.
Menentukan latensi penjadwalan Pod
Latensi penjadwalan Pod adalah jumlah waktu antara saat Pod dibuat dan saat Pod dijadwalkan di node. Latensi penjadwalan Pod berkontribusi pada waktu mulai ke akhir Pod, dan dihitung dengan mengurangi stempel waktu peristiwa penjadwalan Pod dan permintaan pembuatan Pod.
Anda dapat menemukan stempel waktu peristiwa penjadwalan Pod individual dari kolom jsonPayload.eventTime di peristiwa penjadwalan Pod yang sesuai. Untuk melihat
kolom jsonPayload.eventTime, jalankan kueri berikut di
Logs Explorer:
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
Untuk mencantumkan semua peristiwa penjadwalan Pod untuk beban kerja Anda, gunakan filter berikut
dalam kueri sebelumnya:
resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Melihat latensi penarikan image
Latensi pull image container berkontribusi pada latensi startup Pod dalam skenario saat image belum tersedia di node atau image perlu diperbarui. Saat mengoptimalkan latensi penarikan image, Anda mengurangi latensi startup workload selama peristiwa penskalaan cluster.
Anda dapat melihat tabel Kubelet Image Pull Events untuk melihat kapan image container workload ditarik dan berapa lama prosesnya berlangsung.
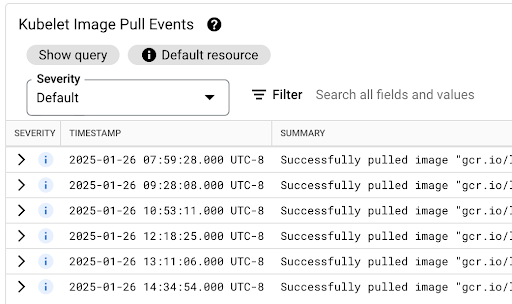
Latensi penarikan image tersedia di kolom jsonPayload.message, yang berisi pesan seperti berikut:
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
Melihat distribusi latensi rekomendasi penskalaan HPA
Latensi rekomendasi penskalaan Horizontal Pod Autoscaler (HPA) untuk target HPA adalah jumlah waktu antara saat metrik dibuat dan saat rekomendasi penskalaan yang sesuai diterapkan ke server API. Saat Anda mengoptimalkan latensi rekomendasi penskalaan HPA, Anda mengurangi latensi startup workload selama peristiwa penskalaan horizontal.
Penskalaan HPA dapat dilihat pada dua diagram berikut:
Diagram Distribusi Latensi Rekomendasi Penskalaan HPA: diagram ini menampilkan persentil latensi rekomendasi penskalaan HPA (persentil kelima puluh, persentil kesembilan puluh lima, dan persentil kesembilan puluh sembilan) yang dihitung berdasarkan pengamatan rekomendasi penskalaan HPA selama interval waktu 3 jam terakhir. Anda dapat menggunakan diagram ini untuk tujuan berikut:
- Pahami latensi rekomendasi penskalaan HPA dasar Anda.
- Mengidentifikasi perubahan latensi rekomendasi penskalaan HPA seiring waktu.
- Korelasikan perubahan latensi rekomendasi penskalaan HPA dengan peristiwa terbaru. Anda dapat memilih peristiwa dalam daftar Anotasi di bagian atas dasbor.
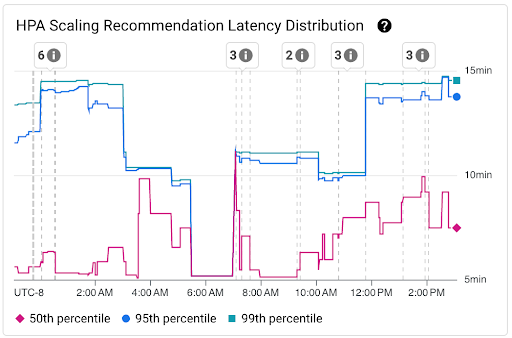
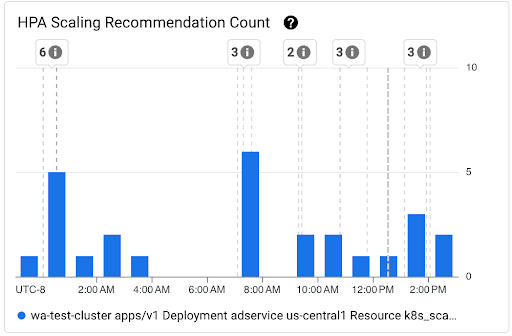
Diagram Jumlah Rekomendasi Penskalaan HPA: diagram ini menampilkan jumlah rekomendasi penskalaan HPA yang diamati selama interval waktu yang dipilih. Gunakan diagram untuk tugas berikut:
- Memahami ukuran sampel rekomendasi penskalaan HPA. Sampel digunakan untuk menghitung persentil dalam distribusi latensi untuk rekomendasi penskalaan HPA selama interval waktu tertentu.
- Korelasikan rekomendasi penskalaan HPA dengan peristiwa startup Pod baru dan dengan peristiwa Horizontal Pod Autoscaler. Anda dapat memilih peristiwa dalam daftar Anotasi di bagian atas dasbor.
Melihat masalah penjadwalan untuk Pod
Masalah penjadwalan pod dapat memengaruhi latensi startup end-to-end beban kerja Anda. Untuk mengurangi latensi startup end-to-end workload Anda, pecahkan masalah dan kurangi jumlah masalah ini.
Berikut adalah dua diagram yang tersedia untuk melacak masalah tersebut:
- Diagram Pod yang Tidak Dapat Dijadwalkan/Tertunda/Gagal menampilkan jumlah Pod yang tidak dapat dijadwalkan, tertunda, dan gagal dari waktu ke waktu.
- Diagram Backoff/Waiting/Readiness Failed Containers menampilkan jumlah penampung dalam status ini dari waktu ke waktu.
Melihat dasbor latensi startup untuk node
Untuk melihat metrik latensi startup untuk node, lakukan langkah-langkah berikut di konsolGoogle Cloud :
Buka halaman Cluster Kubernetes.
Untuk membuka tampilan Cluster details, klik nama cluster yang ingin Anda periksa.
Klik tab Observability.
Dari menu di sebelah kiri, pilih Latensi Startup.
Melihat distribusi latensi startup node
Latensi startup node mengacu pada total latensi startup, yang
mengukur waktu dari CreationTimestamp node hingga status
Kubernetes node ready. Latensi startup node dapat dilihat pada
dua diagram berikut:
Diagram Distribusi Latensi Startup Node: diagram ini menampilkan persentil latensi startup node (persentil kelima puluh, persentil kesembilan puluh lima, dan persentil kesembilan puluh sembilan) yang dihitung berdasarkan pengamatan peristiwa startup node selama interval waktu 3 jam tetap, misalnya, 00.00-03.00 dan 03.00-06.00. Anda dapat menggunakan diagram ini untuk tujuan berikut:
- Pahami latensi startup node dasar Anda.
- Mengidentifikasi perubahan latensi startup node dari waktu ke waktu.
- Korelasikan perubahan latensi startup node dengan peristiwa terbaru, seperti Update Cluster atau Update Node Pool. Anda dapat memilih peristiwa dalam daftar Anotasi di bagian atas dasbor.
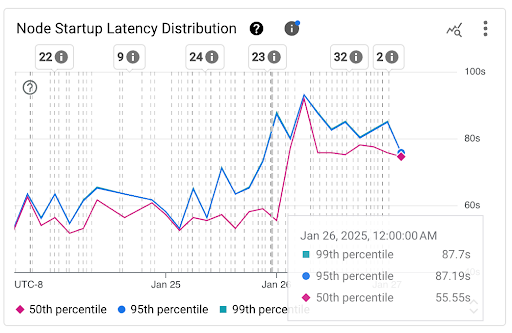
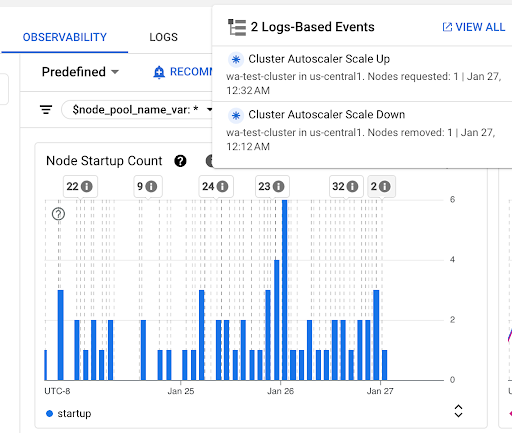
Diagram Jumlah Startup Node: diagram ini menampilkan jumlah node yang dimulai selama interval waktu yang dipilih. Anda dapat menggunakan diagram untuk tujuan berikut:
- Memahami ukuran sampel node, yang digunakan untuk menghitung persentil distribusi latensi startup node untuk interval waktu tertentu.
- Pahami penyebab dimulainya node seperti Update Node Pool atau peristiwa Cluster Autoscaler. Anda dapat memilih peristiwa dalam daftar Anotasi di bagian atas dasbor.
Melihat latensi startup setiap node
Saat membandingkan latensi setiap node, Anda dapat menguji dampak berbagai konfigurasi node terhadap latensi startup node dan mengidentifikasi konfigurasi optimal berdasarkan persyaratan Anda. Anda dapat melihat latensi startup setiap node pada diagram linimasa Latensi Startup Node dan daftar terkait.
Gunakan diagram linimasa Latensi Startup Node untuk mengorelasikan setiap mulai node dengan peristiwa terbaru, seperti Update Cluster atau Update Kumpulan Node. Anda dapat menentukan kemungkinan penyebab perubahan latensi startup dibandingkan dengan node lainnya. Anda dapat memilih peristiwa dalam daftar Anotasi di bagian atas dasbor.
Gunakan daftar Latensi Startup Node untuk mengidentifikasi setiap node yang membutuhkan waktu paling lama atau paling singkat untuk dimulai. Anda dapat mengurutkan daftar berdasarkan kolom Latensi. Saat mengidentifikasi node dengan latensi startup tertinggi, Anda dapat memecahkan masalah penurunan latensi dengan mengorelasikan peristiwa mulai node dengan peristiwa terbaru lainnya.
Anda dapat mengetahui kapan node individual dibuat dengan melihat nilai kolom
protoPayload.metadata.creationTimestamp dalam peristiwa
pembuatan node yang sesuai. Untuk melihat kolom protoPayload.metadata.creationTimestamp, jalankan kueri berikut di Logs Explorer:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
Melihat latensi startup di node pool
Jika node pool Anda memiliki konfigurasi yang berbeda, misalnya, untuk menjalankan workload yang berbeda, Anda mungkin perlu memantau latensi startup node secara terpisah menurut node pool. Saat membandingkan latensi startup node di seluruh node pool, Anda bisa mendapatkan insight tentang pengaruh konfigurasi node terhadap latensi startup node dan mengoptimalkan latensi.
Secara default, dasbor Latensi Startup Node menampilkan Distribusi Latensi Startup gabungan dan Latensi Startup Node individual di semua node pool dalam cluster. Untuk melihat latensi startup node untuk node pool tertentu, pilih nama node pool menggunakan filter $node_pool_name_var yang berada di bagian atas dasbor.
Langkah berikutnya
- Pelajari cara mengoptimalkan penskalaan otomatis Pod berdasarkan metrik.
- Pelajari lebih lanjut cara mengurangi latensi cold start di GKE.
- Pelajari cara mengurangi latensi pengambilan gambar dengan Streaming gambar.
- Pelajari ekonomi yang mengejutkan dari penyesuaian Penskalaan Otomatis Pod Horizontal.
- Pantau workload Anda dengan pemantauan aplikasi otomatis.