本页面介绍了如何使用 GKE 推理快速入门来简化在 Google Kubernetes Engine (GKE) 上部署 AI/机器学习推理工作负载的过程。推理快速入门是一种实用程序,可让您指定推理业务需求,并根据最佳实践和 Google 在模型、模型服务器、加速器(GPU、TPU)和扩缩方面的基准,获得优化的 Kubernetes 配置。这有助于您避免手动调整和测试配置的耗时过程。
本页面适用于机器学习 (ML) 工程师、平台管理员和运维人员,以及希望了解如何高效管理和优化 GKE 以进行 AI/ML 推理的数据和 AI 专家。如需详细了解我们在 Google Cloud 内容中提及的常见角色和示例任务,请参阅常见的 GKE Enterprise 用户角色和任务。
如需详细了解模型服务概念和术语,以及 GKE 生成式 AI 功能如何提升和支持模型部署性能,请参阅 GKE 上的模型推理简介。
在阅读本页面内容之前,请确保您熟悉 Kubernetes、GKE 和模型服务。
使用推理快速入门
使用推理快速入门的简要步骤如下。点击链接可查看详细说明。
- 查看量身定制的最佳实践:在 Google Cloud 控制台中使用 GKE AI/ML 页面,或在终端中使用 Google Cloud CLI,首先提供输入内容,例如您偏好的开放模型(例如 Llama、Gemma 或 Mistral)。
- 您可以指定应用的延迟时间目标,指明应用对延迟时间是否敏感(例如聊天机器人)或对吞吐量是否敏感(例如批量分析)。
- 根据您的需求,推理快速入门会提供加速器选择、性能指标和 Kubernetes 清单,让您能够完全掌控部署或进一步修改。生成的清单会引用公共模型服务器映像,因此您无需自行创建这些映像。
- 部署清单:使用 Google Cloud 控制台或
kubectl apply命令部署建议的清单。在部署之前,您需要确保您的 Google Cloud 项目中有足够的加速器配额,以便用于所选的 GPU 或 TPU。 - 监控性能:使用 Cloud Monitoring 监控 GKE 提供的工作负载性能指标。您可以查看模型服务器信息中心,并根据需要微调部署。
优势
推理快速入门可提供优化配置,帮助您节省时间和资源。这些优化措施可通过以下方式提高性能并降低基础架构费用:
- 您会收到有关设置加速器(GPU 和 TPU)、模型服务器和扩缩配置的详细量身定制的最佳实践。GKE 会定期更新该工具,以提供最新的修复、映像和性能基准。
- 您可以使用Google Cloud 控制台界面或命令行界面指定工作负载的延迟时间和吞吐量要求,并获取详细的量身定制的最佳实践(以 Kubernetes 部署清单的形式呈现)。
使用场景
推理快速入门适用于以下场景:
- 探索最佳 GKE 推理架构:如果您要从其他环境(例如本地环境或其他云提供商)迁移,并且希望了解 GKE 上最新的推荐推理架构,以满足您特定的性能需求,请参阅此部分。
- 加快 AI/机器学习推理部署速度:如果您是经验丰富的 Kubernetes 用户,并且希望快速开始部署 AI 推理工作负载,推理快速入门可帮助您发现并实现 GKE 上的最佳实践部署,其中包含基于最佳实践的详细 YAML 配置。
- 探索 TPU 以提升性能:如果您已在 GKE 上使用 GPU 来利用 Kubernetes,则可以使用推理快速入门来探索使用 TPU 的优势,从而可能获得更好的性能。
工作原理
推理快速入门基于 Google 对模型、模型服务器和加速器拓扑组合的单副本性能进行的详尽的内部基准测试结果,提供量身定制的最佳实践。这些基准会绘制延迟时间与吞吐量的对比图,包括队列大小和 KV 缓存指标,从而绘制出每种组合的性能曲线。
个性化最佳实践的生成方式
我们通过饱和加速器来测量延迟时间(以每个输出 token 的标准化时间 [NTPOT] 毫秒为单位)和吞吐量(以每秒输出 token 数为单位)。如需详细了解这些性能指标,请参阅 GKE 上的模型推理简介。
以下示例延迟时间配置文件展示了吞吐量达到平稳状态的拐点(绿色)、拐点之后延迟时间恶化的点(红色),以及在延迟时间目标值下实现最佳吞吐量的理想区域(蓝色)。推理快速入门提供了此理想区域的性能数据和配置。
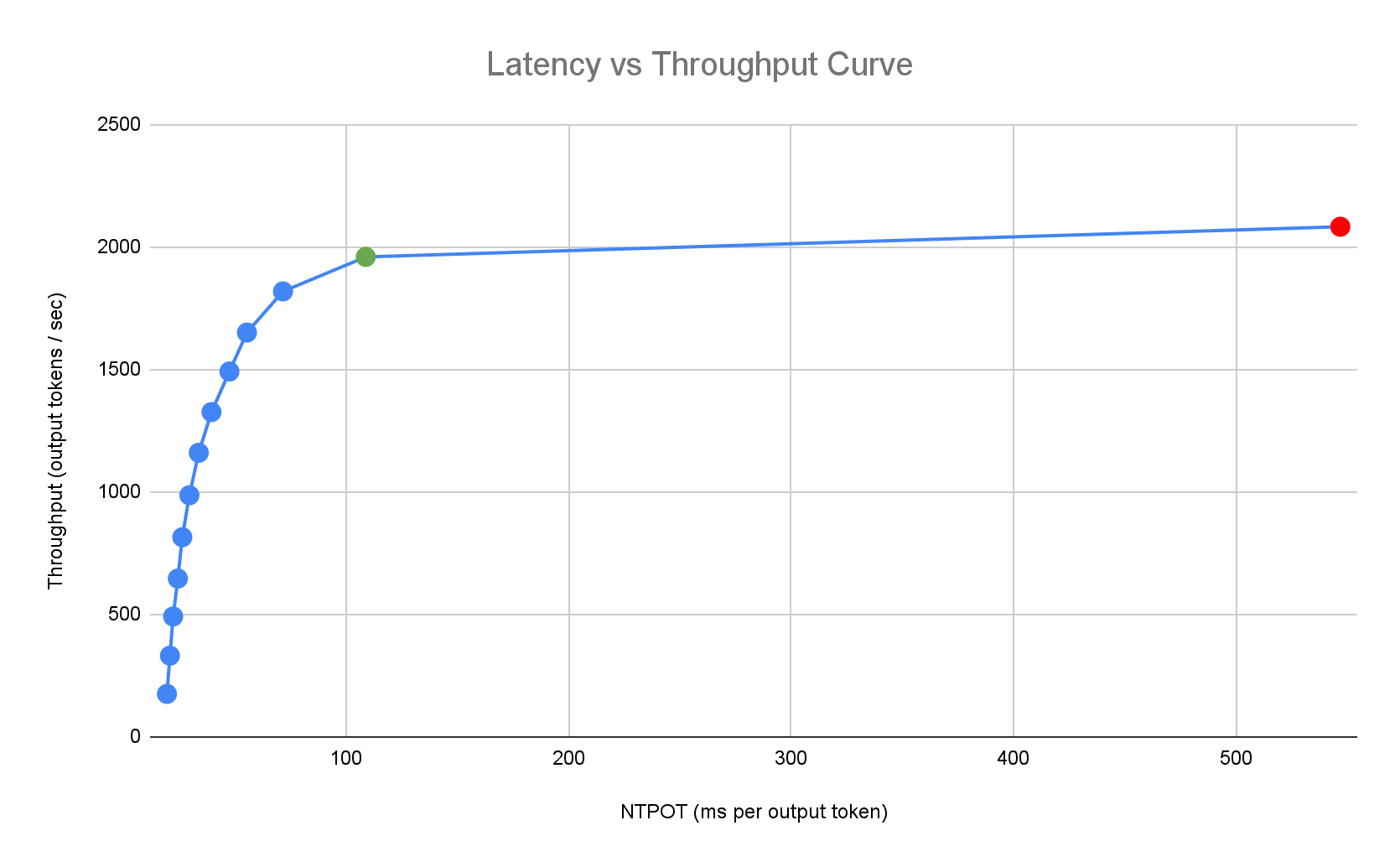
Inference Quickstart 会根据推理应用的延迟时间要求,确定合适的组合,并在延迟时间-吞吐量曲线上确定最佳运行点。此点设置了 Pod 横向自动扩缩器 (HPA) 阈值,并留出缓冲空间来应对扩缩延迟。总体阈值还会告知所需的初始副本数,不过 HPA 会根据工作负载动态调整此数量。
基准比较
所提供的配置和性能数据基于使用 ShareGPT 数据集发送流量的基准,具有以下输入和输出分布。
| 输入 token | 输出 token | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 最小值 | 中位数 | 平均值 | P90 | P99 | 最大值 | 最小值 | 中位数 | 平均值 | P90 | P99 | 最大值 |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
准备工作
在开始之前,请确保您已执行以下任务:
- 启用 Google Kubernetes Engine API。 启用 Google Kubernetes Engine API
- 如果您要使用 Google Cloud CLI 执行此任务,请安装并初始化 gcloud CLI。 如果您之前安装了 gcloud CLI,请运行
gcloud components update以获取最新版本。
在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目。
确保您的项目有足够的加速器容量:
- 如果您使用 GPU:请查看配额页面。
- 如果您使用 TPU,请参阅确保 TPU 和其他 GKE 资源的配额。
如果您还没有 Hugging Face 访问令牌和相应的 Kubernetes Secret,请生成一个。如需创建包含 Hugging Face 令牌的 Kubernetes Secret,请运行以下命令:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACE替换以下值:
- HUGGING_FACE_TOKEN:您之前生成的 Hugging Face 令牌。
- NAMESPACE:您要在其中部署模型服务器的 Kubernetes 命名空间。
某些模型可能还会要求您接受并签署其许可协议。
准备使用 GKE AI/机器学习界面
如果您使用 Google Cloud 控制台,还需要创建 Autopilot 集群(如果您的项目中尚未创建)。按照创建 Autopilot 集群中的说明操作。
准备使用命令行界面
如果您使用 gcloud CLI 运行推理快速入门,还需要运行以下其他命令:
启用
gkerecommender.googleapis.comAPI:gcloud services enable gkerecommender.googleapis.com设置您用于 API 调用的结算配额项目:
gcloud config set billing/quota_project PROJECT_ID检查您的 gcloud CLI 版本是否至少为 526.0.0。请注意,不支持 530.0.0 和 531.0.0。如果需要更新,请运行以下命令:
gcloud components update
限制
在开始使用推理快速入门之前,请注意以下限制:
- Google Cloud 控制台模型部署仅支持部署到 Autopilot 集群。
- 推理快速入门不提供给定模型服务器支持的所有模型的配置文件。
查看模型推理的优化配置
本部分介绍如何使用 Google Cloud 控制台或命令行生成和查看配置建议。
控制台
- 点击部署模型。
选择要查看的模型。推理快速入门支持的模型会显示已优化标签。
- 如果您选择了基础模型,系统会打开模型页面。点击部署。 您仍然可以在实际部署之前修改配置。
- 如果您的项目中没有 Autopilot 集群,系统会提示您创建一个。按照创建 Autopilot 集群中的说明操作。创建集群后,返回到 Google Cloud 控制台中的 GKE AI/ML 页面,选择一个模型。
模型部署页面会预先填充您选择的模型以及推荐的模型服务器和加速器。您还可以配置最大延迟时间等设置。
如需查看包含推荐配置的清单,请点击查看 YAML。
gcloud
使用 gcloud alpha container ai profiles 命令探索和查看模型、模型服务器、模型服务器版本和加速器的优化组合:
模型
如需探索和选择模型,请使用 models 选项。
gcloud alpha container ai profiles models list
模型服务器
如需探索您感兴趣的模型的推荐模型服务器,请使用 model-servers 选项。例如:
gcloud alpha container ai profiles model-servers list \
--model=meta-llama/Meta-Llama-3-8B
输出类似于以下内容:
Supported model servers:
- vllm
服务器版本
(可选)如需探索您感兴趣的模型服务器支持的版本,请使用 model-server-versions 选项。如果您跳过此步骤,推理快速入门将默认使用最新版本。例如:
gcloud alpha container ai profiles model-server-versions list \
--model=meta-llama/Meta-Llama-3-8B \
--model-server=vllm
输出类似于以下内容:
Supported model server versions:
- e92694b6fe264a85371317295bca6643508034ef
- v0.7.2
加速器
如需探索您感兴趣的模型和模型服务器组合的推荐加速器,请使用 accelerators 选项。例如:
gcloud alpha container ai profiles accelerators list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server-version=v0.7.2
输出类似于以下内容:
Supported accelerators:
accelerator | model | model server | model server version | accelerator count | output tokens per second | ntpot ms
---------------------|-----------------------------------------|--------------|------------------------------------------|-------------------|--------------------------|---------
nvidia-tesla-a100 | deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | vllm | v0.7.2 | 1 | 3357 | 72
nvidia-h100-80gb | deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | vllm | v0.7.2 | 1 | 6934 | 30
For more details on each accelerator, use --format=yaml
输出会返回加速器类型列表以及以下指标:
- 吞吐量(以每秒输出的 token 数为单位)
- 每个输出 token 的标准化时间 (NTPOT),以毫秒为单位
这些值表示在吞吐量停止增加且延迟时间开始大幅增加(即拐点或饱和点)时,使用相应加速器类型的给定配置所观察到的性能。如需详细了解这些性能指标,请参阅关于在 GKE 上进行模型推理。
如需了解其他选项,请参阅 Google Cloud CLI 文档。
选择模型、模型服务器、模型服务器版本和加速器后,您可以继续创建部署清单。
部署建议的配置
本部分介绍如何使用 Google Cloud 控制台或命令行生成和部署配置建议。
控制台
- 点击部署模型。
选择要部署的模型。推理快速入门支持的模型会显示已优化标签。
- 如果您选择了基础模型,系统会打开模型页面。点击部署。 您仍然可以在实际部署之前修改配置。
- 如果您的项目中没有 Autopilot 集群,系统会提示您创建一个。按照创建 Autopilot 集群中的说明操作。创建集群后,返回到 Google Cloud 控制台中的 GKE AI/ML 页面,选择一个模型。
模型部署页面会预先填充您选择的模型以及推荐的模型服务器和加速器。您还可以配置最大延迟时间等设置。
(可选)如需查看包含推荐配置的清单,请点击查看 YAML。
如需部署采用推荐配置的清单,请点击部署。部署操作可能需要几分钟时间才能完成。
如需查看部署,请前往 Kubernetes Engine > 工作负载页面。
gcloud
生成清单:在终端中,使用
manifests选项生成 Deployment、Service 和 PodMonitoring 清单:gcloud alpha container ai profiles manifests create使用必需的
--model、--model-server和--accelerator-type参数自定义清单。您可以选择性地设置以下参数:
--target-ntpot-milliseconds:设置此参数以指定 HPA 阈值。此参数可让您定义一个扩缩阈值,以使在第 50 个四分位点测量的每个输出 token 的归一化时间 (NTPOT) P50 延迟时间保持在指定值以下。选择一个高于加速器最低延迟的值。如果您指定的 NTPOT 值高于加速器的最大延迟时间,则 HPA 会配置为实现最大吞吐量。例如:gcloud alpha container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--model-server-version:模型服务器版本。如果未指定,则默认为最新版本。--namespace:要在其中部署清单的命名空间。默认命名空间为“default”。--output:有效值包括manifest、comments和all。默认情况下,此参数设置为all。您可以选择仅输出用于部署工作负载的清单,也可以选择仅输出注释(如果您想查看有关如何启用功能的说明)。--output-path:如果指定,输出将保存到提供的路径,而不是打印到终端,以便您在部署之前编辑输出。例如,如果您想将清单保存在 YAML 文件中,可以将此选项与--output=manifest选项搭配使用。例如:gcloud alpha container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml
如需了解其他选项,请参阅 Google Cloud CLI 文档。
预配基础架构:按照这些预配步骤确保基础架构已正确设置,以便进行模型部署、监控和扩缩。
部署清单:运行
kubectl apply命令,并传入清单的 YAML 文件。例如:kubectl apply -f ./manifests.yaml
预配基础架构
请按照以下步骤操作,确保您的基础架构已正确设置,以便进行模型部署、监控和扩缩:
创建集群:您可以在 GKE Autopilot 或 Standard 集群上部署模型。我们建议您使用 Autopilot 集群获得全托管式 Kubernetes 体验。如需选择最适合您的工作负载的 GKE 操作模式,请参阅选择 GKE 操作模式。
如果您没有现有集群,请按以下步骤操作:
Autopilot
按照以下说明创建 Autopilot 集群。如果您在项目中拥有必要的配额,GKE 会根据部署清单处理具有 GPU 或 TPU 容量的节点的预配。
Standard
- 创建可用区级或区域级集群。
创建具有相应加速器的节点池。根据您选择的加速器类型,按照以下步骤操作:
- GPU:首先,请查看 Google Cloud 控制台中的“配额”页面,确保您有足够的 GPU 容量。然后,按照创建 GPU 节点池中的说明操作。
- TPU:首先,请按照确保 TPU 和其他 GKE 资源的配额中的说明,确保您有足够的 TPU。然后,继续创建 TPU 节点池。
(可选,但建议执行)启用可观测性功能:在生成的清单的注释部分中,提供了用于启用建议的可观测性功能的其他命令。启用这些功能可提供更多数据洞见,帮助您监控工作负载和底层基础架构的性能和状态。
以下是用于启用可观测性功能的命令示例:
gcloud beta container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALL如需了解详情,请参阅监控推理工作负载。
(仅限 HPA)部署指标适配器:如果部署清单中生成了 HPA 资源,则必须使用指标适配器,例如自定义指标 Stackdriver 适配器。借助指标适配器,HPA 可以访问使用 kube 外部指标 API 的模型服务器指标。如需部署适配器,请参阅 GitHub 上的适配器文档。
测试部署端点
如果您使用命令行部署了清单,则部署的服务会在以下端点公开:
http://model-model_server-service:port/
测试您的服务。 在另一个终端中,运行以下命令来设置端口转发:
kubectl port-forward service/model-model_server-service 8000:8000
如需查看有关如何构建请求并将其发送到端点的示例,请参阅 vLLM 文档。
监控推理工作负载
如需监控已部署的推理工作负载,请前往 Google Cloud 控制台中的Metrics Explorer。
启用自动监控
GKE 包含自动监控功能,该功能是更广泛的可观测性功能的一部分。此功能会扫描集群中在受支持的模型服务器上运行的工作负载,并部署 PodMonitoring 资源,使这些工作负载指标可在 Cloud Monitoring 中显示。如需详细了解如何启用和配置自动监控,请参阅为工作负载配置自动应用监控。
启用该功能后,GKE 会安装预建的信息中心,以监控受支持的工作负载的应用。
如果您通过 Google Cloud 控制台中的 GKE AI/机器学习页面进行部署,系统会使用 targetNtpot 配置自动为您创建 PodMonitoring 和 HPA 资源。
问题排查
- 如果您将延迟时间设置得过低,推理快速入门可能无法生成建议。如需解决此问题,请选择介于所选加速器的观测到的最短延迟时间和最长延迟时间之间的延迟时间目标。
- 推理快速入门独立于 GKE 组件,因此您的集群版本与使用该服务没有直接关系。不过,我们建议您使用全新的或最新的集群,以免出现任何性能差异。
- 如果您针对
gkerecommender.googleapis.com命令收到PERMISSION_DENIED错误,提示缺少配额项目,则需要手动设置。运行gcloud config set billing/quota_project PROJECT_ID即可解决此问题。
后续步骤
- 访问 GKE 上的 AI/机器学习编排门户,探索我们的官方指南、教程和应用场景,了解如何在 GKE 上运行 AI/机器学习工作负载。
- 如需详细了解模型服务优化,请参阅使用 GPU 优化大语言模型推理的最佳实践。本文介绍了使用 GKE 上的 GPU 进行 LLM 服务的最佳实践,例如量化、张量并行处理和内存管理。
- 如需详细了解自动扩缩的最佳实践,请参阅以下指南:
- 在 GKE AI 实验室中探索利用 GKE 加速 AI/机器学习计划的实验性示例。