Questa pagina descrive come utilizzare GKE Inference Quickstart per semplificare il deployment dei workload di inferenza AI/ML su Google Kubernetes Engine (GKE). Avvio rapido dell'inferenza è un'utilità che ti consente di specificare i requisiti aziendali di inferenza e ottenere configurazioni Kubernetes ottimizzate in base alle best practice e ai benchmark di Google per modelli, server di modelli, acceleratori (GPU, TPU), scalabilità e spazio di archiviazione. In questo modo eviti la procedura dispendiosa in termini di tempo di aggiustamento e test manuali delle configurazioni.
Questa pagina è rivolta a machine learning engineer, amministratori e operatori della piattaforma e specialisti di dati e AI che vogliono capire come gestire e ottimizzare in modo efficiente GKE per l'inferenza AI/ML. Per scoprire di più sui ruoli comuni e sulle attività di esempio a cui facciamo riferimento nei contenuti di Google Cloud , consulta Ruoli e attività comuni degli utenti GKE.
Per saperne di più sui concetti e sulla terminologia relativi al servizio di modelli e su come le funzionalità di GKE Gen AI possono migliorare e supportare le prestazioni del servizio di modelli, consulta Informazioni sull'inferenza dei modelli su GKE.
Prima di leggere questa pagina, assicurati di conoscere Kubernetes, GKE e il model serving.
Utilizzo di Inference Quickstart
Avvio rapido dell'inferenza ti consente di analizzare le prestazioni e l'efficienza dei costi dei tuoi carichi di lavoro di inferenza e di prendere decisioni basate sui dati in merito all'allocazione delle risorse e alle strategie di deployment dei modelli.
I passaggi generali per utilizzare Avvio rapido dell'inferenza sono i seguenti:
Analizza prestazioni e costi: esplora le configurazioni disponibili e filtrale in base ai tuoi requisiti di prestazioni e costi utilizzando il comando
gcloud container ai profiles list. Per visualizzare il set completo di dati di benchmarking per una configurazione specifica, utilizza il comandogcloud container ai profiles benchmarks list. Questo comando ti consente di identificare l'hardware più conveniente per i tuoi requisiti di prestazioni specifici.Esegui il deployment dei manifest: dopo l'analisi, puoi generare un manifest Kubernetes ottimizzato ed eseguirne il deployment. Se vuoi, puoi attivare le ottimizzazioni per l'archiviazione e la scalabilità automatica. Puoi eseguire il deployment dalla console Google Cloud o utilizzando il comando
kubectl apply. Prima del deployment, devi assicurarti di avere una quota di acceleratori sufficiente per le GPU o le TPU selezionate nel tuo progetto Google Cloud .(Facoltativo) Esegui i tuoi benchmark: le configurazioni e i dati sul rendimento forniti si basano su benchmark che utilizzano il set di dati ShareGPT. Il rendimento dei tuoi workload potrebbe variare rispetto a questa baseline. Per misurare le prestazioni del modello in varie condizioni, puoi utilizzare lo strumento di benchmark dell'inferenza sperimentale.
Vantaggi
Avvio rapido dell'inferenza ti aiuta a risparmiare tempo e risorse fornendo configurazioni ottimizzate. Queste ottimizzazioni migliorano le prestazioni e riducono i costi dell'infrastruttura nei seguenti modi:
- Ricevi best practice personalizzate e dettagliate per impostare l'acceleratore (GPU e TPU), il server del modello e le configurazioni di scalabilità. GKE aggiorna regolarmente Inference Quickstart con le correzioni, le immagini e i benchmark delle prestazioni più recenti.
- Puoi specificare i requisiti di latenza e velocità effettiva del tuo carico di lavoro utilizzando l'interfaccia utente della consoleGoogle Cloud o un'interfaccia a riga di comando e ottenere best practice dettagliate e personalizzate come manifest di deployment Kubernetes.
Come funziona
Guida rapida all'inferenza fornisce best practice personalizzate in base ai benchmark interni esaustivi di Google sulle prestazioni di una singola replica per combinazioni di modello, server di modelli e topologia dell'acceleratore. Questi grafici dei benchmark mostrano la latenza rispetto al throughput, incluse le metriche relative alle dimensioni della coda e alla cache KV, che mappano le curve di rendimento per ogni combinazione.
Come vengono generate le best practice personalizzate
Misuriamo la latenza in tempo normalizzato per token di output (NTPOT) e tempo al primo token (TTFT) in millisecondi e la velocità effettiva in token di output al secondo, saturando gli acceleratori. Per scoprire di più su queste metriche sul rendimento, consulta Informazioni sull'inferenza del modello su GKE.
Il seguente profilo di latenza di esempio illustra il punto di flesso in cui il throughput raggiunge un plateau (verde), il punto post-inflesso in cui la latenza peggiora (rosso) e la zona ideale (blu) per un throughput ottimale in corrispondenza del target di latenza. Guida rapida all'inferenza fornisce dati sulle prestazioni e configurazioni per questa zona ideale.
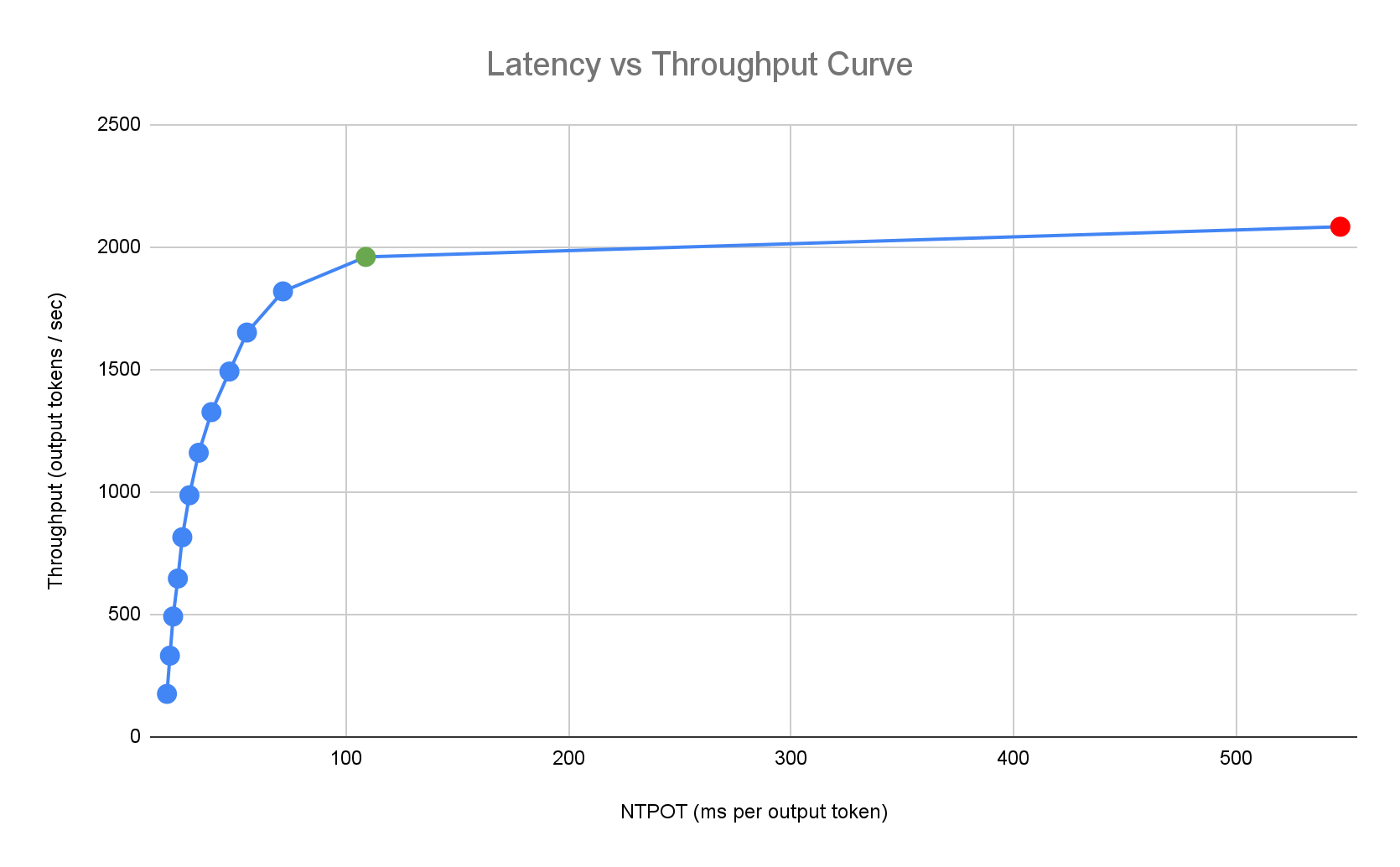
In base ai requisiti di latenza di un'applicazione di inferenza, Inference Quickstart identifica le combinazioni adatte e determina il punto operativo ottimale sulla curva latenza-velocità effettiva. Questo punto imposta la soglia di Horizontal Pod Autoscaler (HPA), con un buffer per tenere conto della latenza di scalabilità verticale. La soglia complessiva indica anche il numero iniziale di repliche necessarie, anche se HPA regola dinamicamente questo numero in base al workload.
Calcolo dei costi
Per calcolare il costo, Inference Quickstart utilizza un rapporto costo output/input configurabile. Ad esempio, se questo rapporto è impostato su 4, si presume che ogni token di output costi quattro volte di più di un token di input. Le seguenti equazioni vengono utilizzate per calcolare le metriche costo per token:
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
dove
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
Benchmarking
Le configurazioni e i dati sul rendimento forniti si basano su benchmark che utilizzano il set di dati ShareGPT per inviare traffico con la seguente distribuzione di input e output.
| Token di input | Token di output | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Mediana | Media | P90 | P99 | Max | Min | Mediana | Media | P90 | P99 | Max |
| 4 | 108 | 226 | 635 | 887 | 1024 | 1 | 132 | 195 | 488 | 778 | 1024 |
Prima di iniziare
Prima di iniziare, assicurati di aver eseguito le seguenti operazioni:
- Attiva l'API Google Kubernetes Engine. Attiva l'API Google Kubernetes Engine
- Se vuoi utilizzare Google Cloud CLI per questa attività,
installala e poi
inizializza
gcloud CLI. Se hai già installato gcloud CLI, scarica l'ultima
versione eseguendo
gcloud components update.
Nella console Google Cloud , nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud .
Verifica che la fatturazione sia attivata per il tuo progetto Google Cloud .
Assicurati di disporre di una capacità dell'acceleratore sufficiente per il tuo progetto:
- Se utilizzi GPU: controlla la pagina Quote.
- Se utilizzi le TPU, consulta Assicurati di avere la quota per le TPU e altre risorse GKE.
Prepararsi a utilizzare l'interfaccia utente AI/ML di GKE
Se utilizzi la console Google Cloud , devi anche creare un cluster Autopilot, se non ne è già stato creato uno nel tuo progetto. Segui le istruzioni riportate in Creare un cluster Autopilot.
Prepararsi a utilizzare l'interfaccia a riga di comando
Se utilizzi gcloud CLI per eseguire Avvio rapido dell'inferenza, devi eseguire anche questi comandi aggiuntivi:
Attiva l'API
gkerecommender.googleapis.com:gcloud services enable gkerecommender.googleapis.comImposta il progetto di quota di fatturazione che utilizzi per le chiamate API:
gcloud config set billing/quota_project PROJECT_IDVerifica che la versione di gcloud CLI sia almeno la 536.0.1. In caso contrario, esegui questo comando:
gcloud components update
Limitazioni
Prima di iniziare a utilizzare Inference Quickstart, tieni presente le seguenti limitazioni:
- Il deployment del modello della consoleGoogle Cloud supporta il deployment solo nei cluster Autopilot.
- Guida rapida all'inferenza non fornisce profili per tutti i modelli supportati da un determinato server di modelli.
- Se non imposti la variabile di ambiente
HF_HOMEquando utilizzi un manifest generato per un modello di grandi dimensioni (90 GiB o più) di Hugging Face, devi utilizzare un cluster con dischi di avvio più grandi di quelli predefiniti o modificare il manifest per impostareHF_HOMEsu/dev/shm/hf_cache. In questo modo, la RAM verrà utilizzata per la cache anziché il disco di avvio del nodo. Per maggiori informazioni, consulta la sezione Risoluzione dei problemi. - Il caricamento di modelli da Cloud Storage supporta solo il deployment nei cluster con il driver CSI di Cloud Storage FUSE e Workload Identity Federation for GKE abilitati, entrambi abilitati per impostazione predefinita nei cluster Autopilot. Per maggiori dettagli, vedi Configurare il driver CSI di Cloud Storage FUSE per GKE.
Analizza e visualizza le configurazioni ottimizzate per l'inferenza del modello
Questa sezione descrive come esplorare e analizzare i consigli di configurazione utilizzando Google Cloud CLI.
Utilizza il comando gcloud container ai profiles
per esplorare e analizzare i profili ottimizzati (combinazioni di modello, server di modelli,
versione del server di modelli e acceleratori):
Modelli
Per esplorare e selezionare un modello, utilizza l'opzione models.
gcloud container ai profiles models list
Profili
Utilizza il comando list
per esplorare i profili generati e filtrarli in base ai tuoi
requisiti di rendimento e costo. Ad esempio:
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
L'output mostra i profili supportati con metriche sul rendimento come throughput, latenza e costo per milione di token nel punto di flesso. Avrà un aspetto simile al seguente:
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
I valori rappresentano le prestazioni osservate nel punto in cui la velocità effettiva smette di aumentare e la latenza inizia ad aumentare drasticamente (ovvero il punto di flesso o di saturazione) per un determinato profilo con questo tipo di acceleratore. Per scoprire di più su queste metriche sul rendimento, consulta Informazioni sull'inferenza del modello su GKE.
Per l'elenco completo dei flag che puoi impostare, consulta la documentazione del comando
list.
Tutte le informazioni sui prezzi sono disponibili solo in valuta USD e per impostazione predefinita nella regione us-east5, ad eccezione delle configurazioni che utilizzano macchine A3, che per impostazione predefinita si trovano nella regione us-central1.
Benchmark
Per ottenere tutti i dati di benchmarking per un profilo specifico, utilizza il comando
benchmarks list.
Ad esempio:
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm \
--pricing-model=on-demand
L'output contiene un elenco di metriche sul rendimento dei benchmark eseguiti a diverse frequenze di richieste.
Il comando mostra l'output in formato CSV. Per archiviare l'output come
file, utilizza il reindirizzamento dell'output. Ad esempio
gcloud container ai profiles benchmarks list > profiles.csv.
Per l'elenco completo dei flag che puoi impostare, consulta la documentazione del comando
benchmarks list.
Dopo aver scelto un modello, un server modello, una versione del server modello e un acceleratore, puoi procedere alla creazione di un manifest di deployment.
Esegui il deployment delle configurazioni consigliate
Questa sezione descrive come generare e implementare i consigli di configurazione utilizzando la console Google Cloud o la riga di comando.
Console
- Nella console Google Cloud , vai alla pagina GKE AI/ML.
- Fai clic su Esegui il deployment dei modelli.
Seleziona un modello di cui vuoi eseguire il deployment. I modelli supportati dalla guida di avvio rapido per l'inferenza vengono visualizzati con il tag Ottimizzato.
- Se hai selezionato un modello di base, si apre una pagina del modello. Fai clic su Esegui il deployment. Puoi comunque modificare la configurazione prima del deployment effettivo.
- Ti viene chiesto di creare un cluster Autopilot, se non ne esiste uno nel tuo progetto. Segui le istruzioni riportate in Creare un cluster Autopilot. Dopo aver creato il cluster, torna alla pagina GKE AI/ML nella console Google Cloud per selezionare un modello.
La pagina di deployment del modello viene precompilata con il modello selezionato e con il server modello e l'acceleratore consigliati. Puoi anche configurare impostazioni come la latenza massima e l'origine del modello.
(Facoltativo) Per visualizzare il manifest con la configurazione consigliata, fai clic su Visualizza YAML.
Per eseguire il deployment del manifest con la configurazione consigliata, fai clic su Esegui il deployment. Il completamento dell'operazione di deployment potrebbe richiedere alcuni minuti.
Per visualizzare il deployment, vai alla pagina Kubernetes Engine > Workload.
gcloud
Preparati a caricare i modelli dal tuo registro dei modelli: la guida rapida all'inferenza supporta il caricamento di modelli da Hugging Face o Cloud Storage.
Hugging Face
Se non ne hai già uno, genera un token di accesso Hugging Face e un secret Kubernetes corrispondente.
Per creare un secret di Kubernetes che contenga il token Hugging Face, esegui il seguente comando:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACESostituisci i seguenti valori:
- HUGGING_FACE_TOKEN: il token Hugging Face creato in precedenza.
- NAMESPACE: lo spazio dei nomi Kubernetes in cui vuoi eseguire il deployment del server del modello.
Alcuni modelli potrebbero anche richiedere di accettare e firmare il contratto di licenza per il consenso.
Cloud Storage
Puoi caricare i modelli supportati da Cloud Storage con una configurazione Cloud Storage FUSE ottimizzata. Per farlo, devi prima caricare il modello da Hugging Face nel bucket Cloud Storage.
Puoi eseguire il deployment di questo job Kubernetes per trasferire il modello, modificando
MODEL_IDnel modello supportato della guida rapida all'inferenza.Genera manifest: per generare i manifest sono disponibili le seguenti opzioni:
- Configurazione di base: genera i manifest standard di Kubernetes Deployment, Service e PodMonitoring per il deployment di un server di inferenza a replica singola.
- (Facoltativo) Configurazione ottimizzata per l'archiviazione: genera un manifest con una configurazione Cloud Storage FUSE ottimizzata per caricare i modelli da un bucket Cloud Storage. Per abilitare questa configurazione, utilizza il flag
--model-bucket-uri. Una configurazione ottimizzata di Cloud Storage FUSE può migliorare il tempo di avvio del pod LLM di oltre 7 volte. (Facoltativo) Configurazione ottimizzata per la scalabilità automatica: genera un manifest con un Horizontal Pod Autoscaler (HPA) per regolare automaticamente il numero di repliche del server di modelli in base al traffico. Puoi attivare questa configurazione specificando un target di latenza con flag come
--target-ntpot-milliseconds.
Configurazione di base
Nel terminale, utilizza l'opzione
manifestsper generare i manifest di deployment, servizio e PodMonitoring:gcloud container ai profiles manifests createUtilizza i parametri obbligatori
--model,--model-servere--accelerator-typeper personalizzare il manifest.(Facoltativo) Puoi impostare questi parametri:
--target-ntpot-milliseconds: imposta questo parametro per specificare la soglia HPA. Questo parametro consente di definire una soglia di scalabilità per mantenere la latenza NTPOT (Normalized Time Per Output Token) P50, misurata al 50° percentile, al di sotto del valore specificato. Scegli un valore superiore alla latenza minima dell'acceleratore. L'HPA è configurato per la massima velocità effettiva se specifichi un valore NTPOT superiore alla latenza massima dell'acceleratore. Ad esempio:gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds: filtra i profili che superano il target di latenza TTFT.--output-path: se specificato, l'output viene salvato nel percorso fornito anziché stampato nel terminale, in modo da poterlo modificare prima di eseguirne il deployment. Ad esempio, puoi utilizzarlo con l'opzione--output=manifestse vuoi salvare il manifest in un file YAML. Ad esempio:gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml
Per l'elenco completo dei flag che puoi impostare, consulta la documentazione del comando
manifests create.Ottimizzato per l'archiviazione
Puoi migliorare il tempo di avvio del pod caricando i modelli da Cloud Storage utilizzando una configurazione ottimizzata di Cloud Storage FUSE. Il caricamento da Cloud Storage richiede GKE 1.29.6-gke.1254000, 1.30.2-gke.1394000 o versioni successive
A questo scopo, procedi nel seguente modo:
- Carica il modello dal repository Hugging Face nel bucket Cloud Storage.
Imposta il flag
--model-bucket-uridurante la generazione del manifest. Questa configurazione carica il modello da un bucket Cloud Storage utilizzando il driver CSI di Cloud Storage FUSE. L'URI deve puntare al percorso contenente il fileconfig.jsone i pesi del modello. Puoi specificare un percorso a una directory all'interno del bucket aggiungendolo all'URI del bucket.Ad esempio:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --accelerator-type=nvidia-l4 \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlSostituisci
BUCKET_NAMEcon il nome del tuo bucket Cloud Storage.Prima di applicare il manifest, devi eseguire il comando
gcloud storage buckets add-iam-policy-bindingche si trova nei commenti del manifest. Questo comando è necessario per concedere al account di servizio GKE l'autorizzazione ad accedere al bucket Cloud Storage utilizzando la federazione delle identità per i workload per GKE.Se intendi scalare il deployment a più di una replica, devi scegliere una delle seguenti opzioni per evitare errori di scrittura simultanea nel percorso della cache XLA (
VLLM_XLA_CACHE_PATH):- Opzione 1 (consigliata): innanzitutto, ridimensiona il deployment a 1 replica. Attendi che il pod sia pronto, in modo da poter scrivere nella cache XLA. Aumenta poi il numero di repliche che ti interessa. Le repliche successive leggeranno dalla cache compilata senza conflitti di scrittura.
- Opzione 2: rimuovi completamente la variabile di ambiente
VLLM_XLA_CACHE_PATHdal manifest. Questo approccio è più semplice, ma disattiva la memorizzazione nella cache per tutte le repliche.
Nei tipi di acceleratore TPU, questo percorso della cache viene utilizzato per archiviare la cache di compilazione XLA, che accelera la preparazione del modello per le implementazioni ripetute.
Per altri suggerimenti su come migliorare il rendimento, consulta Ottimizzare il driver CSI di Cloud Storage FUSE per il rendimento di GKE.
Ottimizzato per la scalabilità automatica
Puoi configurare Horizontal Pod Autoscaler (HPA) per regolare automaticamente il numero di repliche del server di modelli in base al carico. In questo modo, i server dei modelli possono gestire in modo efficiente carichi variabili aumentando o diminuendo le risorse in base alle necessità. La configurazione di HPA segue le best practice di scalabilità automatica per le guide relative a GPU e TPU.
Per includere le configurazioni HPA durante la generazione dei manifest, utilizza uno o entrambi i flag
--target-ntpot-millisecondse--target-ttft-milliseconds. Questi parametri definiscono una soglia di scalabilità per HPA per mantenere la latenza P50 per NTPOT o TTFT al di sotto del valore specificato. Se imposti solo uno di questi flag, per lo scaling verrà presa in considerazione solo quella metrica.Scegli un valore superiore alla latenza minima dell'acceleratore. L'HPA è configurato per la massima velocità effettiva se specifichi un valore superiore alla latenza massima dell'acceleratore.
Ad esempio:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250Crea un cluster: puoi pubblicare il modello su cluster GKE Autopilot o Standard. Ti consigliamo di utilizzare un cluster Autopilot per un'esperienza Kubernetes completamente gestita. Per scegliere la modalità operativa GKE più adatta ai tuoi workload, consulta Scegliere una modalità operativa GKE.
Se non hai un cluster esistente, segui questi passaggi:
Autopilot
Segui queste istruzioni per creare un cluster Autopilot. GKE gestisce il provisioning dei nodi con capacità GPU o TPU in base ai manifest di deployment, se disponi della quota necessaria nel progetto.
Standard
- Crea un cluster zonale o regionale.
Crea un pool di nodi con gli acceleratori appropriati. Segui questi passaggi in base al tipo di acceleratore scelto:
- GPU: per prima cosa, controlla la pagina Quote nella console Google Cloud per assicurarti di disporre di una capacità GPU sufficiente. Poi, segui le istruzioni riportate in Creare un pool di nodi GPU.
- TPU: per prima cosa, assicurati di avere TPU sufficienti seguendo le istruzioni riportate in Assicurati di avere la quota per le TPU e altre risorse GKE. Quindi, procedi alla creazione di un pool di nodi TPU.
(Facoltativo, ma consigliato) Attiva le funzionalità di osservabilità: nella sezione dei commenti del manifest generato, vengono forniti comandi aggiuntivi per attivare le funzionalità di osservabilità suggerite. L'attivazione di queste funzionalità fornisce maggiori informazioni per aiutarti a monitorare le prestazioni e lo stato dei carichi di lavoro e dell'infrastruttura sottostante.
Di seguito è riportato un esempio di comando per abilitare le funzionalità di osservabilità:
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALLPer saperne di più, consulta Monitorare i carichi di lavoro di inferenza.
(Solo HPA) Esegui il deployment di un adattatore delle metriche: un adattatore delle metriche, ad esempio l'adattatore delle metriche personalizzate Stackdriver, è necessario se le risorse HPA sono state generate nei manifest di deployment. L'adattatore delle metriche consente a HPA di accedere alle metriche del server del modello che utilizzano l'API per le metriche esterne di Kube. Per eseguire il deployment dell'adattatore, consulta la documentazione dell'adattatore su GitHub.
Esegui il deployment dei manifest: esegui il comando
kubectl applye inserisci il file YAML per i manifest. Ad esempio:kubectl apply -f ./manifests.yaml
Testare gli endpoint di deployment
Se hai eseguito il deployment del manifest, il servizio di cui è stato eseguito il deployment è esposto al seguente endpoint:
http://model-model_server-service:8000/
Il server del modello, ad esempio vLLM, in genere è in ascolto sulla porta 8000.
Per testare il deployment, devi configurare il port forwarding. Esegui questo comando in un terminale separato:
kubectl port-forward service/model-model_server-service 8000:8000
Per esempi di come creare e inviare una richiesta all'endpoint, consulta la documentazione di vLLM.
Controllo delle versioni del manifest
Guida rapida per l'inferenza fornisce i manifest più recenti con convalida sulle versioni recenti del cluster GKE. Il manifest restituito per un profilo potrebbe cambiare nel tempo, in modo da ricevere una configurazione ottimizzata al momento del deployment. Se hai bisogno di un manifest stabile, salvalo e memorizzalo separatamente.
Il manifest include commenti e un'annotazione recommender.ai.gke.io/version
nel seguente formato:
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
L'annotazione precedente ha i seguenti valori:
- DATE: la data in cui è stato generato il manifest.
- CLUSTER_VERSION: la versione del cluster GKE utilizzata per la convalida.
- NODE_VERSION: la versione del nodo GKE utilizzata per la convalida.
- GPU_DRIVER_VERSION: (solo GPU) la versione del driver GPU utilizzata per la convalida.
- MODEL_SERVER: il server di modelli utilizzato nel manifest.
- MODEL_SERVER_VERSION: la versione del server modello utilizzata nel manifest.
Monitorare i carichi di lavoro di inferenza
Per monitorare i workload di inferenza di cui è stato eseguito il deployment, vai a Esplora metriche nella console Google Cloud .
Abilitare il monitoraggio automatico
GKE include una funzionalità di monitoraggio automatico che fa parte delle funzionalità di osservabilità più ampie. Questa funzionalità esegue la scansione del cluster alla ricerca di workload che vengono eseguiti su server di modelli supportati ed esegue il deployment delle risorse PodMonitoring che consentono di visualizzare le metriche di questi workload in Cloud Monitoring. Per saperne di più sull'attivazione e la configurazione del monitoraggio automatico, consulta Configurare il monitoraggio automatico delle applicazioni per i workload.
Dopo aver abilitato la funzionalità, GKE installa dashboard predefinite per il monitoraggio delle applicazioni per i carichi di lavoro supportati.
Se esegui il deployment dalla pagina GKE AI/ML nella console Google Cloud , le risorse PodMonitoring e HPA vengono create automaticamente utilizzando la configurazione targetNtpot.
Risoluzione dei problemi
- Se imposti la latenza troppo bassa, la guida rapida all'inferenza potrebbe non generare un suggerimento. Per risolvere il problema, seleziona un target di latenza compreso tra la latenza minima e massima osservata per gli acceleratori selezionati.
- Guida rapida per l'inferenza esiste indipendentemente dai componenti GKE, quindi la versione del cluster non è direttamente pertinente per l'utilizzo del servizio. Tuttavia, ti consigliamo di utilizzare un cluster nuovo o aggiornato per evitare discrepanze nel rendimento.
- Se ricevi un errore
PERMISSION_DENIEDper i comandigkerecommender.googleapis.comche indica che manca un progetto di quota, devi impostarlo manualmente. Eseguigcloud config set billing/quota_project PROJECT_IDper risolvere il problema.
Pod espulso a causa dello spazio di archiviazione temporanea insufficiente
Quando esegui il deployment di un modello di grandi dimensioni (90 GiB o più) da Hugging Face, il pod potrebbe essere rimosso con un messaggio di errore simile a questo:
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
Questo errore si verifica perché il modello viene memorizzato nella cache sul disco di avvio del nodo, una forma di storage temporaneo. Il disco di avvio viene utilizzato per l'archiviazione temporanea quando il manifest di deployment non imposta la variabile di ambiente HF_HOME su una directory nella RAM del nodo.
- Per impostazione predefinita, i nodi GKE hanno un disco di avvio di 100 GiB.
- GKE riserva il 10% del disco di avvio per l'overhead di sistema, lasciando 90 GiB per i tuoi carichi di lavoro.
- Se le dimensioni del modello sono pari o superiori a 90 GB e viene eseguito su un disco di avvio di dimensioni predefinite, kubelet rimuove il pod per liberare spazio di archiviazione temporaneo.
Per risolvere il problema, scegli una delle seguenti opzioni:
- Utilizza la RAM per la memorizzazione nella cache del modello: nel manifest di deployment, imposta la variabile di ambiente
HF_HOMEsu/dev/shm/hf_cache. In questo modo, la RAM del nodo viene utilizzata per memorizzare nella cache il modello anziché il disco di avvio. - Aumenta le dimensioni del disco di avvio:
- GKE Standard: aumenta le dimensioni del disco di avvio quando crei un cluster, crei un node pool o aggiorni un node pool.
- Autopilot: per richiedere un disco di avvio più grande, crea una classe di computing personalizzata e imposta il campo
bootDiskSizenella regolamachineType.
Il pod entra in un ciclo di arresti anomali durante il caricamento dei modelli da Cloud Storage
Dopo aver eseguito il deployment di un manifest generato con il flag --model-bucket-uri,
il deployment potrebbe bloccarsi e il pod entra nello stato CrashLoopBackOff.
Il controllo dei log del container inference-server potrebbe mostrare un errore fuorviante, ad esempio huggingface_hub.errors.HFValidationError. Ad esempio:
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
Questo errore si verifica in genere quando il percorso Cloud Storage fornito nel
flag --model-bucket-uri non è corretto. Il server di inferenza, ad esempio vLLM,
non riesce a trovare i file del modello richiesti (come config.json) nel percorso di montaggio.
Se non riesce a trovare i file locali, il server torna a presupporre che il percorso sia un ID repository di Hugging Face Hub. Poiché il percorso non è un ID repository valido, il server genera un errore di convalida ed entra in un ciclo di arresti anomali.
Per risolvere il problema, verifica che il percorso fornito al flag --model-bucket-uri
punti alla directory esatta nel bucket Cloud Storage che
contiene il file config.json del modello e tutti i pesi del modello associati.
Passaggi successivi
- Visita il portale di orchestrazione AI/ML su GKE per esplorare le nostre guide, i nostri tutorial e i nostri casi d'uso ufficiali per l'esecuzione di carichi di lavoro AI/ML su GKE.
- Per ulteriori informazioni sull'ottimizzazione della distribuzione del modello, consulta Best practice per l'ottimizzazione dell'inferenza di modelli linguistici di grandi dimensioni con le GPU. Vengono trattate le best practice per la gestione di LLM con GPU su GKE, come quantizzazione, parallelismo dei tensori e gestione della memoria.
- Per saperne di più sulle best practice per la scalabilità automatica, consulta queste guide:
- Per informazioni sulle best practice di archiviazione, consulta Ottimizzare il driver CSI di Cloud Storage FUSE per le prestazioni di GKE.
- Esplora esempi sperimentali per sfruttare GKE per accelerare le tue iniziative di AI/ML in GKE AI Labs.