Auf dieser Seite wird beschrieben, wie Sie mit dem GKE Inference Quickstart die Bereitstellung von KI-/ML-Inferenzarbeitslasten in Google Kubernetes Engine (GKE) vereinfachen können. Inference Quickstart ist ein Dienstprogramm, mit dem Sie Ihre geschäftlichen Anforderungen für die Inferenz angeben und optimierte Kubernetes-Konfigurationen basierend auf Best Practices und den Benchmarks von Google für Modelle, Modellserver, Beschleuniger (GPUs, TPUs), Skalierung und Speicher erhalten können. So können Sie den zeitaufwendigen Prozess des manuellen Anpassens und Testens von Konfigurationen vermeiden.
Diese Seite richtet sich an Entwickler von maschinellem Lernen (ML), Plattformadministratoren und ‑operatoren sowie an Daten- und KI-Spezialisten, die erfahren möchten, wie sie GKE für KI-/ML-Inferenz effizient verwalten und optimieren können. Weitere Informationen zu gängigen Rollen und Beispielaufgaben, auf die wir in Google Cloud Inhalten verweisen, finden Sie unter Häufig verwendete GKE-Nutzerrollen und ‑Aufgaben.
Weitere Informationen zu Konzepten und Begriffen für die Bereitstellung von Modellen sowie dazu, wie GKE Gen AI-Funktionen die Leistung der Bereitstellung von Modellen verbessern und unterstützen können, finden Sie unter Modellinferenz in GKE.
Machen Sie sich vor dem Lesen dieser Seite mit Kubernetes, GKE und Model Serving vertraut.
Kurzanleitung für die Inferenz verwenden
Mit dem Inference Quickstart können Sie die Leistung und Kosteneffizienz Ihrer Inferenz-Arbeitslasten analysieren und datengestützte Entscheidungen zur Ressourcenzuweisung und zu Strategien für die Modellbereitstellung treffen.
Dies sind die allgemeinen Schritte zur Verwendung von Inference Quickstart:
Leistung und Kosten analysieren: Mit dem Befehl
gcloud container ai profiles listkönnen Sie verfügbare Konfigurationen aufrufen und nach Ihren Leistungs- und Kostenanforderungen filtern. Verwenden Sie den Befehlgcloud container ai profiles benchmarks list, um sich die vollständigen Benchmarking-Daten für eine bestimmte Konfiguration anzusehen. Mit diesem Befehl können Sie die kostengünstigste Hardware für Ihre spezifischen Leistungsanforderungen ermitteln.Manifeste bereitstellen: Nach der Analyse können Sie ein optimiertes Kubernetes-Manifest generieren und bereitstellen. Optional können Sie Optimierungen für Speicher und Autoscaling aktivieren. Sie können die Bereitstellung über die Google Cloud Console oder mit dem
kubectl apply-Befehl vornehmen. Vor der Bereitstellung müssen Sie prüfen, ob in Ihrem Google Cloud -Projekt ein ausreichendes Beschleunigerkontingent für die ausgewählten GPUs oder TPUs vorhanden ist.(Optional) Eigene Benchmarks ausführen: Die bereitgestellten Konfigurationen und Leistungsdaten basieren auf Benchmarks, die das ShareGPT-Dataset verwenden. Die Leistung für Ihre Arbeitslasten kann von dieser Baseline abweichen. Mit dem experimentellen Tool für Inferenz-Benchmarks können Sie die Leistung Ihres Modells unter verschiedenen Bedingungen messen.
Vorteile
Mit der Inference Quickstart können Sie Zeit und Ressourcen sparen, da optimierte Konfigurationen bereitgestellt werden. Diese Optimierungen verbessern die Leistung und senken die Infrastrukturkosten auf folgende Weise:
- Sie erhalten detaillierte, maßgeschneiderte Best Practices für die Konfiguration von Beschleuniger (GPU und TPU), Modellserver und Skalierung. GKE aktualisiert die Kurzanleitung für die Inferenz regelmäßig mit den neuesten Korrekturen, Bildern und Leistungsbenchmarks.
- Sie können die Anforderungen an Latenz und Durchsatz für Ihre Arbeitslast über dieGoogle Cloud -Konsolen-UI oder eine Befehlszeilenschnittstelle angeben und erhalten detaillierte, maßgeschneiderte Best Practices als Kubernetes-Bereitstellungsmanifeste.
Funktionsweise
Die Kurzanleitung für die Inferenz enthält maßgeschneiderte Best Practices, die auf den umfassenden internen Benchmarks von Google zur Leistung einzelner Replikate für Kombinationen aus Modell, Modellserver und Beschleunigertopologie basieren. In diesen Benchmarks wird die Latenz im Vergleich zum Durchsatz dargestellt, einschließlich der Messwerte für die Warteschlangengröße und den KV-Cache, die Leistungskurven für jede Kombination abbilden.
So werden maßgeschneiderte Best Practices generiert
Wir messen die Latenz in normalisierter Zeit pro Ausgabetoken (Normalized Time per Output Token, NTPOT) und Zeit bis zum ersten Token (Time to First Token, TTFT) in Millisekunden und den Durchsatz in Ausgabetokens pro Sekunde, indem wir Beschleuniger sättigen. Weitere Informationen zu diesen Leistungsmesswerten finden Sie unter Modellinferenz in GKE.
Das folgende Beispiel für ein Latenzprofil veranschaulicht den Wendepunkt, an dem der Durchsatz stagniert (grün), den Bereich nach dem Wendepunkt, in dem sich die Latenz verschlechtert (rot), und die ideale Zone (blau) für einen optimalen Durchsatz bei der angestrebten Latenz. Der Inference Quickstart enthält Leistungsdaten und Konfigurationen für diese ideale Zone.
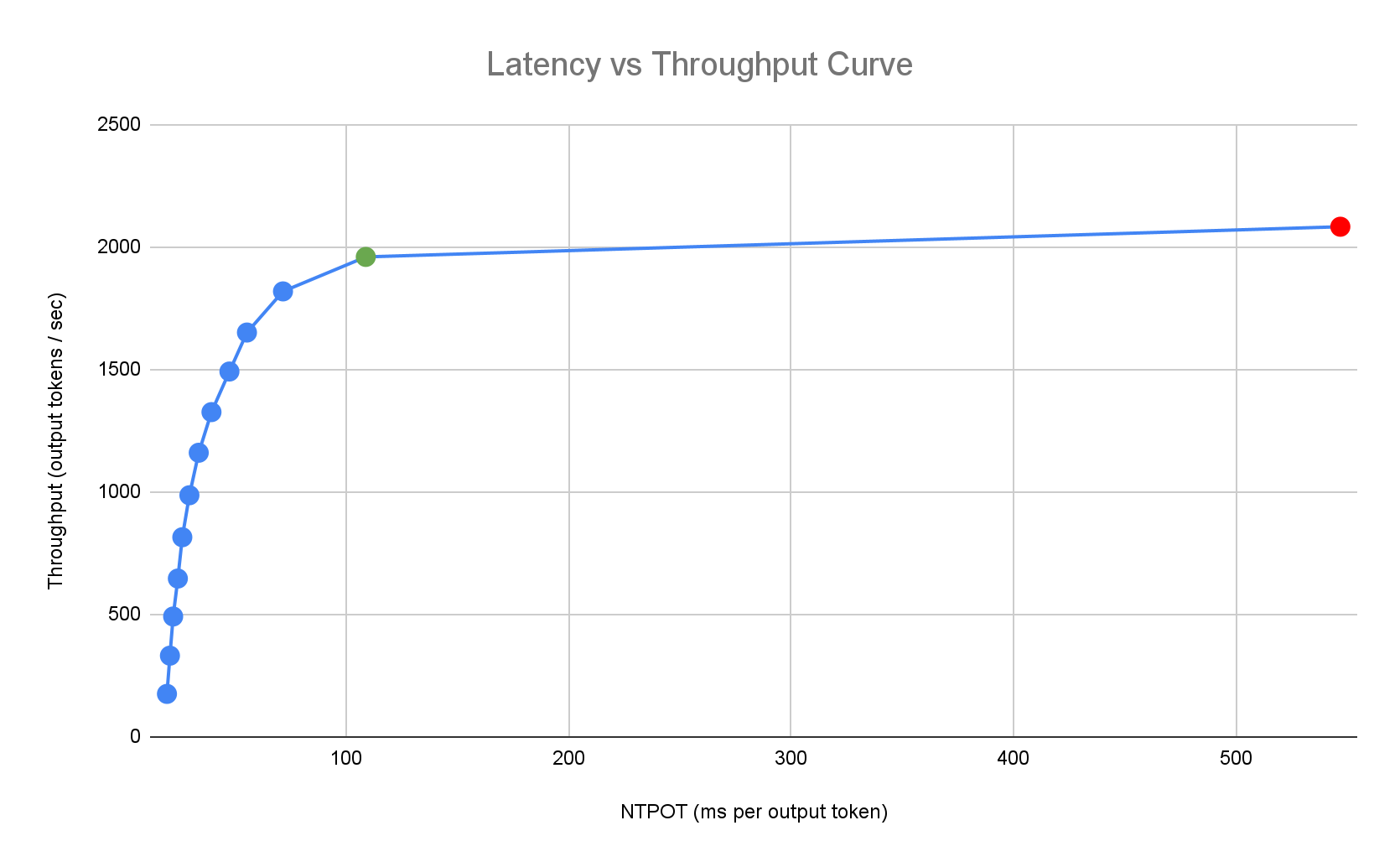
Anhand der Latenzanforderungen einer Inferenzanwendung ermittelt Inference Quickstart geeignete Kombinationen und den optimalen Betriebspunkt auf der Latenz-Durchsatz-Kurve. Dieser Punkt legt den HPA-Schwellenwert (Horizontal Pod Autoscaler) mit einem Puffer fest, um die Latenz beim Hochskalieren zu berücksichtigen. Der Gesamtschwellenwert gibt auch die anfängliche Anzahl der erforderlichen Replikate an. Der HPA passt diese Anzahl jedoch dynamisch an die Arbeitslast an.
Berechnung der Kosten
Zur Berechnung der Kosten verwendet Inference Quickstart ein konfigurierbares Kostenverhältnis zwischen Ausgabe und Eingabe. Wenn dieses Verhältnis beispielsweise auf 4 festgelegt ist, wird davon ausgegangen, dass jedes Ausgabetoken viermal so viel kostet wie ein Eingabetoken. Die folgenden Gleichungen werden verwendet, um die Messwerte für die Kosten pro Token zu berechnen:
\[ \$/\text{output token} = \frac{\text{GPU \$/s}}{(\frac{1}{\text{output-to-input-cost-ratio}} \cdot \text{input tokens/s} + \text{output tokens/s})} \]
Dabei gilt:
\[ \$/\text{input token} = \frac{\text{\$/output token}}{\text{output-to-input-cost-ratio}} \]
Benchmarking
Die bereitgestellten Konfigurationen und Leistungsdaten basieren auf Benchmarks, bei denen mit dem ShareGPT-Dataset Traffic mit der folgenden Ein- und Ausgabeverteilung gesendet wird.
| Eingabetokens | Ausgabetokens | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Min. | Medianwert | Durchschnitt | P90 | P99 | Max. | Min. | Medianwert | Durchschnitt | P90 | P99 | Max. |
| 4 | 108 | 226 | 635 | 887 | 1.024 | 1 | 132 | 195 | 488 | 778 | 1.024 |
Hinweise
Führen Sie die folgenden Aufgaben aus, bevor Sie beginnen:
- Aktivieren Sie die Google Kubernetes Engine API. Google Kubernetes Engine API aktivieren
- Wenn Sie die Google Cloud CLI für diesen Task verwenden möchten, müssen Sie die gcloud CLI installieren und dann initialisieren. Wenn Sie die gcloud CLI bereits installiert haben, rufen Sie die neueste Version mit
gcloud components updateab.
Wählen Sie in der Google Cloud Console auf der Seite für die Projektauswahl ein Projekt von Google Cloud aus oder erstellen Sie eines.
Die Abrechnung für Ihr Google Cloud Projekt muss aktiviert sein.
Prüfen Sie, ob Ihr Projekt über genügend Beschleunigerkapazität verfügt:
- Wenn Sie GPUs verwenden: Prüfen Sie die Seite „Kontingente“.
- Wenn Sie TPUs verwenden, lesen Sie den Abschnitt Kontingent für TPUs und andere GKE-Ressourcen sicherstellen.
Vorbereitung für die Verwendung der GKE AI/ML-Benutzeroberfläche
Wenn Sie die Google Cloud -Konsole verwenden, müssen Sie auch einen Autopilot-Cluster erstellen, falls noch keiner in Ihrem Projekt vorhanden ist. Folgen Sie der Anleitung unter Autopilot-Cluster erstellen.
Vorbereiten der Verwendung der Befehlszeile
Wenn Sie die gcloud CLI zum Ausführen der Kurzanleitung für die Inferenz verwenden, müssen Sie auch die folgenden zusätzlichen Befehle ausführen:
Aktivieren Sie die
gkerecommender.googleapis.comAPI:gcloud services enable gkerecommender.googleapis.comLegen Sie das Abrechnungskontingentprojekt fest, das Sie für API-Aufrufe verwenden:
gcloud config set billing/quota_project PROJECT_IDPrüfen Sie, ob Ihre gcloud CLI-Version mindestens 536.0.1 ist. Falls nicht, führen Sie Folgendes aus:
gcloud components update
Beschränkungen
Beachten Sie die folgenden Einschränkungen, bevor Sie mit der Kurzanleitung für die Inferenz beginnen:
- Bei der Bereitstellung von Modellen über dieGoogle Cloud -Konsole werden nur Autopilot-Cluster unterstützt.
- Die Inference Quickstart-Anleitung enthält keine Profile für alle Modelle, die von einem bestimmten Modellserver unterstützt werden.
- Wenn Sie die Umgebungsvariable
HF_HOMEnicht festlegen, wenn Sie ein generiertes Manifest für ein großes Modell (90 GiB oder mehr) von Hugging Face verwenden, müssen Sie entweder einen Cluster mit Bootlaufwerken verwenden, die größer als die Standardlaufwerke sind, oder das Manifest ändern, umHF_HOMEauf/dev/shm/hf_cachefestzulegen. Dadurch wird RAM für den Cache anstelle des Bootlaufwerks des Knotens verwendet. Weitere Informationen finden Sie im Abschnitt Fehlerbehebung. - Modelle aus Cloud Storage laden wird nur für die Bereitstellung in Clustern mit dem Cloud Storage FUSE CSI-Treiber und aktivierter Workload Identity-Föderation für GKE unterstützt. Beide sind standardmäßig in Autopilot-Clustern aktiviert. Weitere Informationen finden Sie unter CSI-Treiber für Cloud Storage FUSE für GKE einrichten.
Optimierte Konfigurationen für die Modellinferenz analysieren und ansehen
In diesem Abschnitt wird beschrieben, wie Sie Konfigurationsempfehlungen mit der Google Cloud CLI untersuchen und analysieren.
Verwenden Sie den Befehl gcloud container ai profiles, um optimierte Profile (Kombinationen aus Modell, Modellserver, Modellserverversion und Beschleunigern) zu untersuchen und zu analysieren:
Modelle
Wenn Sie ein Modell auswählen möchten, verwenden Sie die Option models.
gcloud container ai profiles models list
Profile
Mit dem Befehl list können Sie generierte Profile aufrufen und nach Ihren Leistungs- und Kostenanforderungen filtern. Beispiel:
gcloud container ai profiles list \
--model=openai/gpt-oss-20b \
--pricing-model=on-demand \
--target-ttft-milliseconds=300
Die Ausgabe enthält unterstützte Profile mit Leistungsmesswerten wie Durchsatz, Latenz und Kosten pro Million Tokens am Wendepunkt. Dieser sieht etwa so aus:
Instance Type Accelerator Cost/M Input Tokens Cost/M Output Tokens Output Tokens/s NTPOT(ms) TTFT(ms) Model Server Model Server Version Model
a3-highgpu-1g nvidia-h100-80gb 0.009 0.035 13335 67 297 vllm gptoss openai/gpt-oss-20b
Die Werte stellen die Leistung dar, die an dem Punkt beobachtet wurde, an dem der Durchsatz nicht mehr zunimmt und die Latenz für ein bestimmtes Profil mit diesem Beschleunigertyp drastisch ansteigt (d. h. der Wendepunkt oder Sättigungspunkt). Weitere Informationen zu diesen Leistungsmesswerten finden Sie unter Modellinferenz in GKE.
Eine vollständige Liste der Flags, die Sie festlegen können, finden Sie in der Dokumentation zum Befehl list.
Alle Preisinformationen sind nur in US-Dollar verfügbar und standardmäßig auf die Region us-east5 festgelegt, mit Ausnahme von Konfigurationen, die A3-Maschinen verwenden. Diese sind standardmäßig auf die Region us-central1 festgelegt.
Benchmarks
Wenn Sie alle Benchmarking-Daten für ein bestimmtes Profil abrufen möchten, verwenden Sie den Befehl benchmarks list.
Beispiel:
gcloud container ai profiles benchmarks list \
--model=deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \
--model-server=vllm \
--pricing-model=on-demand
Die Ausgabe enthält eine Liste mit Leistungsmesswerten aus Benchmarks, die bei verschiedenen Anfrageraten ausgeführt wurden.
Der Befehl gibt die Ausgabe im CSV-Format aus. Wenn Sie die Ausgabe als Datei speichern möchten, verwenden Sie die Ausgabeweiterleitung. Beispiel: gcloud container ai profiles benchmarks list > profiles.csv.
Eine vollständige Liste der Flags, die Sie festlegen können, finden Sie in der Dokumentation zum Befehl benchmarks list.
Nachdem Sie ein Modell, einen Modellserver, eine Modellserverversion und einen Beschleuniger ausgewählt haben, können Sie ein Bereitstellungsmanifest erstellen.
Empfohlene Konfigurationen bereitstellen
In diesem Abschnitt wird beschrieben, wie Sie Konfigurationsempfehlungen mit der Google Cloud -Konsole oder der Befehlszeile generieren und bereitstellen.
Konsole
- Rufen Sie in der Google Cloud Console die Seite „GKE AI/ML“ auf.
- Klicken Sie auf Modelle bereitstellen.
Wählen Sie ein Modell aus, das Sie bereitstellen möchten. Modelle, die von der Kurzanleitung für die Inferenz unterstützt werden, sind mit dem Tag Optimized gekennzeichnet.
- Wenn Sie ein Fundierungsmodell ausgewählt haben, wird eine Modellseite geöffnet. Klicken Sie auf Bereitstellen. Sie können die Konfiguration vor der eigentlichen Bereitstellung noch ändern.
- Sie werden aufgefordert, einen Autopilot-Cluster zu erstellen, wenn noch keiner in Ihrem Projekt vorhanden ist. Folgen Sie der Anleitung unter Autopilot-Cluster erstellen. Kehren Sie nach dem Erstellen des Clusters zur GKE AI/ML-Seite in der Google Cloud Konsole zurück, um ein Modell auszuwählen.
Auf der Seite zur Modellbereitstellung werden Ihr ausgewähltes Modell sowie der empfohlene Modellserver und Beschleuniger vorab ausgefüllt. Sie können auch Einstellungen wie die maximale Latenz und die Modellquelle konfigurieren.
Optional: Wenn Sie das Manifest mit der empfohlenen Konfiguration aufrufen möchten, klicken Sie auf YAML aufrufen.
Klicken Sie auf Bereitstellen, um das Manifest mit der empfohlenen Konfiguration bereitzustellen. Es kann einige Minuten dauern, bis der Bereitstellungsvorgang abgeschlossen ist.
Rufen Sie die Seite Kubernetes Engine > Arbeitslasten auf, um sich Ihr Deployment anzusehen.
gcloud
Vorbereiten des Ladens von Modellen aus Ihrer Modellregistrierung: Im Inference-Schnellstart wird das Laden von Modellen aus Hugging Face oder Cloud Storage unterstützt.
Hugging Face
Falls noch nicht geschehen, generieren Sie ein Hugging Face-Zugriffstoken und ein entsprechendes Kubernetes-Secret.
Führen Sie den folgenden Befehl aus, um ein Kubernetes-Secret zu erstellen, das das Hugging Face-Token enthält:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=HUGGING_FACE_TOKEN \ --namespace=NAMESPACEErsetzen Sie die folgenden Werte:
- HUGGING_FACE_TOKEN: Das Hugging Face-Token, das Sie zuvor erstellt haben.
- NAMESPACE: der Kubernetes-Namespace, in dem Sie Ihren Modellserver bereitstellen möchten.
Bei einigen Modellen müssen Sie möglicherweise auch die Lizenzvereinbarung für die Einwilligung akzeptieren und unterzeichnen.
Cloud Storage
Mit einer optimierten Cloud Storage FUSE-Einrichtung können Sie unterstützte Modelle aus Cloud Storage laden. Dazu müssen Sie das Modell zuerst von Hugging Face in Ihren Cloud Storage-Bucket laden.
Sie können diesen Kubernetes-Job bereitstellen, um das Modell zu übertragen. Ändern Sie dazu
MODEL_IDin das vom Inference Quickstart unterstützte Modell.Manifeste generieren: Sie haben folgende Möglichkeiten zum Generieren von Manifesten:
- Basiskonfiguration: Generiert die Standardmanifeste für Kubernetes-Deployment, -Dienst und -PodMonitoring zum Bereitstellen eines Inferenzservers mit einem Replikat.
- (Optional) Speicheroptimierte Konfiguration: Generiert ein Manifest mit einer optimierten Cloud Storage FUSE-Einrichtung zum Laden von Modellen aus einem Cloud Storage-Bucket. Sie aktivieren diese Konfiguration mit dem Flag
--model-bucket-uri. Eine optimierte Cloud Storage FUSE-Einrichtung kann die Startzeit von LLM-Pods um mehr als das Siebenfache verkürzen. (Optional) Für Autoscaling optimierte Konfiguration: Generiert ein Manifest mit einem Horizontal Pod Autoscaler (HPA), um die Anzahl der Modellserver-Replikate automatisch an den Traffic anzupassen. Sie aktivieren diese Konfiguration, indem Sie ein Latenzziel mit Flags wie
--target-ntpot-millisecondsangeben.
Basiskonfiguration
Verwenden Sie im Terminal die Option
manifests, um Deployment-, Service- und PodMonitoring-Manifeste zu generieren:gcloud container ai profiles manifests createVerwenden Sie die erforderlichen Parameter
--model,--model-serverund--accelerator-type, um das Manifest anzupassen.Optional können Sie die folgenden Parameter festlegen:
--target-ntpot-milliseconds: Legen Sie diesen Parameter fest, um den HPA-Schwellenwert anzugeben. Mit diesem Parameter können Sie einen Skalierungsschwellenwert definieren, um die P50-Latenz für die normalisierte Zeit pro Ausgabetoken (Normalized Time Per Output Token, NTPOT), die am 50. Perzentil gemessen wird, unter dem angegebenen Wert zu halten. Wählen Sie einen Wert aus, der über der Mindestlatenz Ihres Accelerators liegt. Die HPA ist für maximalen Durchsatz konfiguriert, wenn Sie einen NTPOT-Wert über der maximalen Latenz Ihres Beschleunigers angeben. Beispiel:gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --model-server-version=v0.7.2 \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=200--target-ttft-milliseconds: Filtert Profile heraus, die das TTFT-Latenzziel überschreiten.--output-path: Wenn angegeben, wird die Ausgabe im angegebenen Pfad gespeichert, anstatt im Terminal ausgegeben. So können Sie die Ausgabe vor der Bereitstellung bearbeiten. Sie können diese Option beispielsweise mit--output=manifestverwenden, wenn Sie Ihr Manifest in einer YAML-Datei speichern möchten. Beispiel:gcloud container ai profiles manifests create \ --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B \ --model-server vllm \ --accelerator-type=nvidia-tesla-a100 \ --output=manifest \ --output-path /tmp/manifests.yaml
Eine vollständige Liste der Flags, die Sie festlegen können, finden Sie in der Dokumentation zum Befehl
manifests create.Speicheroptimiert
Sie können die Startzeit von Pods verbessern, indem Sie Modelle aus Cloud Storage mit einer optimierten Cloud Storage FUSE-Konfiguration laden. Das Laden aus Cloud Storage erfordert die GKE-Versionen 1.29.6-gke.1254000, 1.30.2-gke.1394000 oder höher.
Gehen Sie hierzu folgendermaßen vor:
- Modell aus dem Hugging Face-Repository in Ihren Cloud Storage-Bucket laden
Legen Sie beim Generieren des Manifests das Flag
--model-bucket-urifest. Dadurch wird das Modell so konfiguriert, dass es mit dem Cloud Storage FUSE CSI-Treiber aus einem Cloud Storage-Bucket geladen wird. Der URI muss auf den Pfad verweisen, der dieconfig.json-Datei und die Gewichte des Modells enthält. Sie können einen Pfad zu einem Verzeichnis im Bucket angeben, indem Sie ihn an den Bucket-URI anhängen.Beispiel:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --model-server=vllm \ --accelerator-type=nvidia-l4 \ --model-bucket-uri=gs://BUCKET_NAME \ --output-path=manifests.yamlErsetzen Sie
BUCKET_NAMEdurch den Namen Ihres Cloud Storage-Buckets.Bevor Sie das Manifest anwenden, müssen Sie den Befehl
gcloud storage buckets add-iam-policy-bindingausführen, der in den Kommentaren des Manifests enthalten ist. Dieser Befehl ist erforderlich, um dem GKE-Dienstkonto die Berechtigung für den Zugriff auf den Cloud Storage-Bucket mit der Workload Identity-Föderation für GKE zu erteilen.Wenn Sie Ihr Deployment auf mehr als ein Replikat skalieren möchten, müssen Sie eine der folgenden Optionen auswählen, um gleichzeitige Schreibfehler im XLA-Cachepfad (
VLLM_XLA_CACHE_PATH) zu vermeiden:- Option 1 (empfohlen): Skalieren Sie zuerst die Bereitstellung auf 1 Replikat. Warten Sie, bis der Pod bereit ist, damit er in den XLA-Cache schreiben kann. Skalieren Sie dann auf die gewünschte Anzahl von Replikaten. Die nachfolgenden Replikate lesen aus dem gefüllten Cache, ohne dass es zu Schreibkonflikten kommt.
- Option 2: Entfernen Sie die Umgebungsvariable
VLLM_XLA_CACHE_PATHvollständig aus dem Manifest. Dieser Ansatz ist einfacher, deaktiviert aber das Caching für alle Replikate.
Bei TPU-Beschleunigertypen wird dieser Cachepfad verwendet, um den XLA-Kompilierungscache zu speichern. Dadurch wird die Modellvorbereitung für wiederholte Bereitstellungen beschleunigt.
Weitere Tipps zur Leistungssteigerung finden Sie unter CSI-Treiber für Cloud Storage FUSE für GKE-Leistung optimieren.
Für Autoscaling optimiert
Sie können das horizontale Pod-Autoscaling (Horizontal Pod Autoscaler, HPA) so konfigurieren, dass die Anzahl der Modellserver-Replikate automatisch an die Last angepasst wird. So können Ihre Modellserver unterschiedliche Lasten effizient bewältigen, indem sie je nach Bedarf skaliert werden. Die HPA-Konfiguration entspricht den Best Practices für das Autoscaling in den Anleitungen für GPUs und TPUs.
Wenn Sie HPA-Konfigurationen beim Generieren von Manifesten einbeziehen möchten, verwenden Sie eines oder beide der Flags
--target-ntpot-millisecondsund--target-ttft-milliseconds. Diese Parameter definieren einen Skalierungsschwellenwert für die HPA, damit die P50-Latenz für NTPOT oder TTFT unter dem angegebenen Wert bleibt. Wenn Sie nur eines dieser Flags festlegen, wird nur dieser Messwert für die Skalierung berücksichtigt.Wählen Sie einen Wert aus, der über der Mindestlatenz Ihres Accelerators liegt. Die HPA ist für maximalen Durchsatz konfiguriert, wenn Sie einen Wert über der maximalen Latenz Ihres Beschleunigers angeben.
Beispiel:
gcloud container ai profiles manifests create \ --model=google/gemma-2-27b-it \ --accelerator-type=nvidia-l4 \ --target-ntpot-milliseconds=250Cluster erstellen: Sie können Ihr Modell in GKE Autopilot- oder Standardclustern bereitstellen. Für eine vollständig verwaltete Kubernetes-Umgebung empfehlen wir die Verwendung eines Autopilot-Clusters. Informationen zum Auswählen des GKE-Betriebsmodus, der für Ihre Arbeitslasten am besten geeignet ist, finden Sie unter GKE-Betriebsmodus auswählen.
Wenn Sie keinen vorhandenen Cluster haben, gehen Sie so vor:
Autopilot
Folgen Sie dieser Anleitung, um einen Autopilot-Cluster zu erstellen. GKE stellt die Knoten mit GPU- oder TPU-Kapazität basierend auf den Bereitstellungsmanifesten bereit, sofern Sie das erforderliche Kontingent in Ihrem Projekt haben.
Standard
- Erstellen Sie einen zonalen oder regionalen Cluster.
Erstellen Sie einen Knotenpool mit den entsprechenden Beschleunigern. Führen Sie je nach ausgewähltem Beschleunigertyp die folgenden Schritte aus:
- GPUs: Prüfen Sie zuerst auf der Seite „Kontingente“ in der Google Cloud -Konsole, ob Sie genügend GPU-Kapazität haben. Folgen Sie dann der Anleitung unter GPU-Knotenpool erstellen.
- TPUs: Prüfen Sie zuerst, ob Sie genügend TPUs haben. Folgen Sie dazu der Anleitung unter Kontingent für TPUs und andere GKE-Ressourcen bereitstellen. Erstellen Sie dann einen TPU-Knotenpool.
(Optional, aber empfohlen) Observability-Funktionen aktivieren: Im Kommentarbereich des generierten Manifests finden Sie zusätzliche Befehle zum Aktivieren der vorgeschlagenen Observability-Funktionen. Wenn Sie diese Funktionen aktivieren, erhalten Sie mehr Statistiken, mit denen Sie die Leistung und den Status von Arbeitslasten und der zugrunde liegenden Infrastruktur überwachen können.
Hier sehen Sie ein Beispiel für einen Befehl zum Aktivieren von Observability-Funktionen:
gcloud container clusters update $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$LOCATION \ --enable-managed-prometheus \ --logging=SYSTEM,WORKLOAD \ --monitoring=SYSTEM,DEPLOYMENT,HPA,POD,DCGM \ --auto-monitoring-scope=ALLWeitere Informationen finden Sie unter Inferenzarbeitslasten überwachen.
(Nur HPA) Messwertadapter bereitstellen: Ein Messwertadapter, z. B. der Stackdriver-Adapter für benutzerdefinierte Messwerte, ist erforderlich, wenn HPA-Ressourcen in den Bereitstellungsmanifesten generiert wurden. Der Messwerteadapter ermöglicht dem HPA den Zugriff auf Modellservermesswerte, die die kube external metrics API verwenden. Informationen zum Bereitstellen des Adapters finden Sie in der Adapterdokumentation auf GitHub.
Manifeste bereitstellen: Führen Sie den Befehl
kubectl applyaus und übergeben Sie die YAML-Datei für Ihre Manifeste. Beispiel:kubectl apply -f ./manifests.yaml
Bereitstellungsendpunkte testen
Wenn Sie das Manifest bereitgestellt haben, wird der bereitgestellte Dienst über den folgenden Endpunkt verfügbar gemacht:
http://model-model_server-service:8000/
Der Modellserver, z. B. vLLM, überwacht in der Regel Port 8000.
Wenn Sie Ihre Bereitstellung testen möchten, müssen Sie die Portweiterleitung einrichten. Führen Sie den folgenden Befehl in einem separaten Terminal aus:
kubectl port-forward service/model-model_server-service 8000:8000
Beispiele für das Erstellen und Senden einer Anfrage an Ihren Endpunkt finden Sie in der vLLM-Dokumentation.
Manifestversionierung
Die Kurzanleitung für die Inferenz enthält die neuesten Manifeste, die für aktuelle GKE-Clusterversionen validiert wurden. Das für ein Profil zurückgegebene Manifest kann sich im Laufe der Zeit ändern, sodass Sie bei der Bereitstellung eine optimierte Konfiguration erhalten. Wenn Sie ein stabiles Manifest benötigen, speichern Sie es separat.
Das Manifest enthält Kommentare und eine recommender.ai.gke.io/version-Annotation im folgenden Format:
# Generated on DATE using:
# GKE cluster CLUSTER_VERSION
# GPU_DRIVER_VERSION GPU driver for node version NODE_VERSION
# Model server MODEL_SERVER MODEL_SERVER_VERSION
Die vorherige Anmerkung hat die folgenden Werte:
- DATE: Das Datum, an dem das Manifest generiert wurde.
- CLUSTER_VERSION: Die GKE-Clusterversion, die für die Validierung verwendet wird.
- NODE_VERSION: Die für die Validierung verwendete GKE-Knotenversion.
- GPU_DRIVER_VERSION: (nur GPU) Die GPU-Treiberversion, die für die Validierung verwendet wird.
- MODEL_SERVER: Der im Manifest verwendete Modellserver.
- MODEL_SERVER_VERSION: Die im Manifest verwendete Modellserverversion.
Inferenzarbeitslasten überwachen
Wenn Sie Ihre bereitgestellten Inferenzarbeitslasten überwachen möchten, rufen Sie den Metrics Explorer in der Google Cloud Console auf.
Automatisches Monitoring aktivieren
GKE bietet eine automatische Monitoring-Funktion, die Teil der umfassenderen Observability-Funktionen ist. Mit dieser Funktion wird der Cluster nach Arbeitslasten durchsucht, die auf unterstützten Modellservern ausgeführt werden, und die PodMonitoring-Ressourcen werden bereitgestellt, damit diese Arbeitslastmesswerte in Cloud Monitoring sichtbar sind. Weitere Informationen zum Aktivieren und Konfigurieren der automatischen Überwachung finden Sie unter Automatische Anwendungsüberwachung für Arbeitslasten konfigurieren.
Nachdem Sie die Funktion aktiviert haben, installiert GKE vorgefertigte Dashboards zum Monitoring von Anwendungen für unterstützte Arbeitslasten.
Wenn Sie die Bereitstellung über die Seite „GKE AI/ML“ in der Google Cloud Console vornehmen, werden PodMonitoring- und HPA-Ressourcen automatisch anhand der targetNtpot-Konfiguration für Sie erstellt.
Fehlerbehebung
- Wenn Sie die Latenz zu niedrig festlegen, wird im Inference Quickstart möglicherweise keine Empfehlung generiert. Um dieses Problem zu beheben, wählen Sie ein Latenzziel zwischen der minimalen und der maximalen Latenz aus, die für die ausgewählten Beschleuniger beobachtet wurde.
- Die Kurzanleitung für die Inferenz ist unabhängig von GKE-Komponenten. Ihre Clusterversion ist daher für die Verwendung des Dienstes nicht direkt relevant. Wir empfehlen jedoch, einen neuen oder aktuellen Cluster zu verwenden, um Leistungsabweichungen zu vermeiden.
- Wenn Sie für
gkerecommender.googleapis.com-Befehle den FehlerPERMISSION_DENIEDerhalten, der besagt, dass ein Kontingentprojekt fehlt, müssen Sie es manuell festlegen. Führen Siegcloud config set billing/quota_project PROJECT_IDaus, um das Problem zu beheben.
Pod wurde aufgrund von zu wenig flüchtigem Speicher entfernt
Wenn Sie ein großes Modell (90 GiB oder mehr) von Hugging Face bereitstellen, wird Ihr Pod möglicherweise mit einer Fehlermeldung wie dieser entfernt:
Fails because inference server consumes too much ephemeral storage, and gets evicted low resources: Warning Evicted 3m24s kubelet The node was low on resource: ephemeral-storage. Threshold quantity: 10120387530, available: 303108Ki. Container inference-server was using 92343412Ki, request is 0, has larger consumption of ephemeral-storage..,
Dieser Fehler tritt auf, weil das Modell auf dem Bootlaufwerk des Knotens zwischengespeichert wird, einer Form von flüchtigem Speicher. Das Bootlaufwerk wird für sitzungsspezifischen Speicher verwendet, wenn im Bereitstellungsmanifest die Umgebungsvariable HF_HOME nicht auf ein Verzeichnis im RAM des Knotens festgelegt ist.
- Standardmäßig haben GKE-Knoten ein 100 GiB großes Bootlaufwerk.
- GKE reserviert 10% des Bootlaufwerks für den System-Overhead, sodass 90 GiB für Ihre Arbeitslasten verbleiben.
- Wenn die Modellgröße mindestens 90 GiB beträgt und das Modell auf einem Bootlaufwerk mit Standardgröße ausgeführt wird, entfernt kubelet den Pod, um temporären Speicherplatz freizugeben.
Wählen Sie eine der folgenden Optionen, um dieses Problem zu beheben:
- RAM für das Zwischenspeichern von Modellen verwenden: Legen Sie in Ihrem Bereitstellungsmanifest die Umgebungsvariable
HF_HOMEauf/dev/shm/hf_cachefest. Dabei wird der RAM des Knotens verwendet, um das Modell zu cachen, anstatt das Bootlaufwerk. - Größe des Bootlaufwerks erhöhen:
- GKE Standard: Erhöhen Sie die Größe des Bootlaufwerks, wenn Sie einen Cluster erstellen, einen Knotenpool erstellen oder einen Knotenpool aktualisieren.
- Autopilot: Wenn Sie ein größeres Bootlaufwerk anfordern möchten, erstellen Sie eine benutzerdefinierte Compute-Klasse und legen Sie das Feld
bootDiskSizein der RegelmachineTypefest.
Pod gerät beim Laden von Modellen aus Cloud Storage in eine Absturzschleife
Nachdem Sie ein mit dem Flag --model-bucket-uri generiertes Manifest bereitgestellt haben, kann das Deployment hängen bleiben und der Pod wechselt in den Status CrashLoopBackOff.
Wenn Sie die Logs für den Container inference-server prüfen, wird möglicherweise ein irreführender Fehler wie huggingface_hub.errors.HFValidationError angezeigt. Beispiel:
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '/data'.
Dieser Fehler tritt in der Regel auf, wenn der im --model-bucket-uri-Flag angegebene Cloud Storage-Pfad falsch ist. Der Inferenzserver, z. B. vLLM, kann die erforderlichen Modelldateien (z. B. config.json) nicht am bereitgestellten Pfad finden.
Wenn die lokalen Dateien nicht gefunden werden, geht der Server davon aus, dass der Pfad eine Repository-ID für den Hugging Face Hub ist. Da der Pfad keine gültige Repository-ID ist, schlägt der Server mit einem Validierungsfehler fehl und gerät in eine Absturzschleife.
Prüfen Sie zur Behebung dieses Problems, ob der Pfad, den Sie für das Flag --model-bucket-uri angegeben haben, auf das genaue Verzeichnis in Ihrem Cloud Storage-Bucket verweist, das die config.json-Datei des Modells und alle zugehörigen Modellgewichte enthält.
Nächste Schritte
- Im Portal zur KI-/ML-Orchestrierung in GKE finden Sie offizielle Anleitungen, Tutorials und Anwendungsfälle für die Ausführung von KI-/ML-Arbeitslasten in GKE.
- Weitere Informationen zur Optimierung der Bereitstellung von Modellen finden Sie unter Best Practices für die Optimierung der Inferenz großer Sprachmodelle mit GPUs. Darin werden Best Practices für die Bereitstellung von LLMs mit GPUs in GKE behandelt, z. B. Quantisierung, Tensorparallelismus und Arbeitsspeicherverwaltung.
- Weitere Informationen zu Best Practices für das Autoscaling finden Sie in den folgenden Anleitungen:
- Informationen zu Best Practices für den Speicher finden Sie unter CSI-Treiber für Cloud Storage FUSE für GKE-Leistung optimieren.
- In GKE AI Labs finden Sie experimentelle Beispiele dafür, wie Sie GKE nutzen können, um Ihre KI-/ML-Initiativen zu beschleunigen.