
Managed Service for Apache Spark (formerly Dataproc)
The new way to Spark: Easier, smarter, faster
Run Apache Spark workloads with zero-ops serverless Spark or managed clusters. Accelerate development with agentic AI workflows and boost performance with Lightning Engine.
New customers get $300 in free credits to try Managed Service for Apache Spark and other Google Cloud products.
Apache Spark is a trademark of the Apache Software Foundation.

Features
Industry-leading performance with Lightning Engine
Accelerate large-scale ETL and SQL workloads up to 4.9x faster than open source Apache Spark with zero code changes. Lightning Engine utilizes a native C++ vectorized execution engine, intelligent caching, and optimized columnar shuffling. Combine this with intelligent Spark autotuning to eliminate the manual tuning tax, optimizing memory and preventing OOM errors automatically.
*The queries are derived from the TPC-DS standard and TPC-H standard
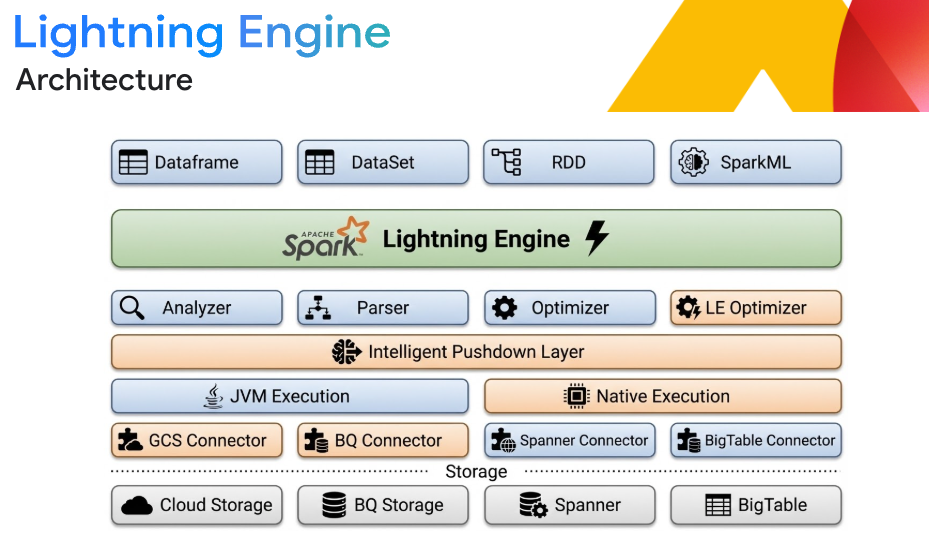
Flexible lakehouse interoperability
Build an open lakehouse architecture that guarantees engine independence. Process data in open formats like Apache Iceberg directly from Google Cloud Storage. Integrate seamlessly with BigQuery and Knowledge Catalog (formerly Dataplex) for unified analytics and governance, ensuring true multi-engine interoperability without translation layers.
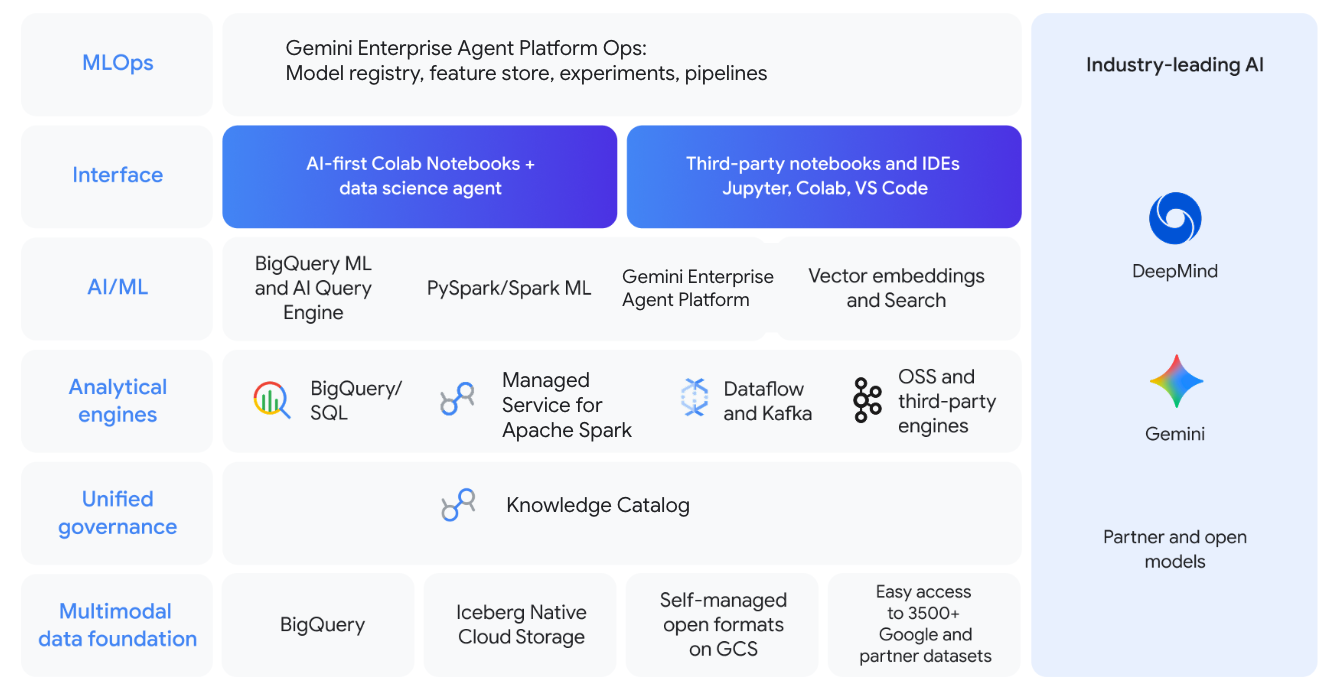
Unified AI powered developer experience
Clear your backlog with data agents that take action, not just answer questions. Accelerate your workflow using Gemini baked into the VSCode agentic extension for accelerated productivity of Spark workloads from development to production, or use the IDE of your choice. Leverate the Data Engineering and Data Science Agents to automate data wrangling, build pipelines from natural language, and generate PySpark code. Automatically troubleshoot broken Spark jobs with Gemini Cloud Assist. Combine SQL and Spark in a single, unified AI-first notebook.
Enterprise AI/ML ready
Build and operationalize your entire machine learning lifecycle. Accelerate model training and inference with GPU support, powered by NVIDIA RAPIDS, and pre-configured ML Runtimes for PyTorch and XGBoost. Integrate with the Google Cloud AI ecosystem to orchestrate end-to-end MLOps and manage assets with Gemini Enterprise Agent Platform Model Registry integration.
Secure, scalable, and seamless migrations
Integrate seamlessly with your security posture using IAM, VPC Service Controls, and Kerberos. Easily migrate cloud and legacy Spark workloads using Managed Service for Apache Spark templates and tooling. Lift-and-shift workloads with support for Spark 2.x up to Spark 4.0 without immediate code refactoring.
Multi-tenant efficiency and FinOps controls
Maximize resource utilization and reduce idle costs. Deploy multi-tenant Spark clusters that allow up to 800 users to share compute resources while maintaining strict data and environment isolation. Control your bill with scale-to-zero capabilities, per-second billing, and Spot VM support for flexible workloads.
Open and flexible ecosystem
Avoid vendor lock-in. While optimized for Apache Spark, our managed clusters support 30+ open source tools like Apache Hadoop, Flink, and Trino. Integrate seamlessly with orchestrators like Managed Service for Apache Airflow and extend with Kubernetes and Docker for maximum flexibility.
Deployment options
| Deployment options | Choose between the fine-grained control of managed clusters or the zero-ops simplicity of a serverless experience for the best option for your workload. | ||
|---|---|---|---|
| Deployment Mode: | What it is: | Ideal for: | Pay For: |
Serverless | Spark jobs as a service. Managed Spark, managed infrastructure. | New pipelines, interactive analysis, and spiky workloads where a zero-ops, pay-per-job model is preferred. | Job run time |
Clusters | Spark clusters as a service. Managed Spark, your infrastructure. | Migrating legacy Spark or OSS workloads, running persistent clusters, or requiring deep open-source customization. | Cluster uptime |
Deployment options
Choose between the fine-grained control of managed clusters or the zero-ops simplicity of a serverless experience for the best option for your workload.
Serverless
Spark jobs as a service.
Managed Spark, managed infrastructure.
New pipelines, interactive analysis, and spiky workloads where a zero-ops, pay-per-job model is preferred.
Job run time
Clusters
Spark clusters as a service.
Managed Spark, your infrastructure.
Migrating legacy Spark or OSS workloads, running persistent clusters, or requiring deep open-source customization.
Cluster uptime
How It Works
Data engineering at scale
Automated ETL pipelines
Automated ETL pipelines
Build robust, event-driven Spark ETL pipelines that automatically scale on demand. Leverage serverless execution for spiky workloads or managed clusters for persistent jobs. Use workflow templates to automate your most critical, production-level data processing jobs from end to end.
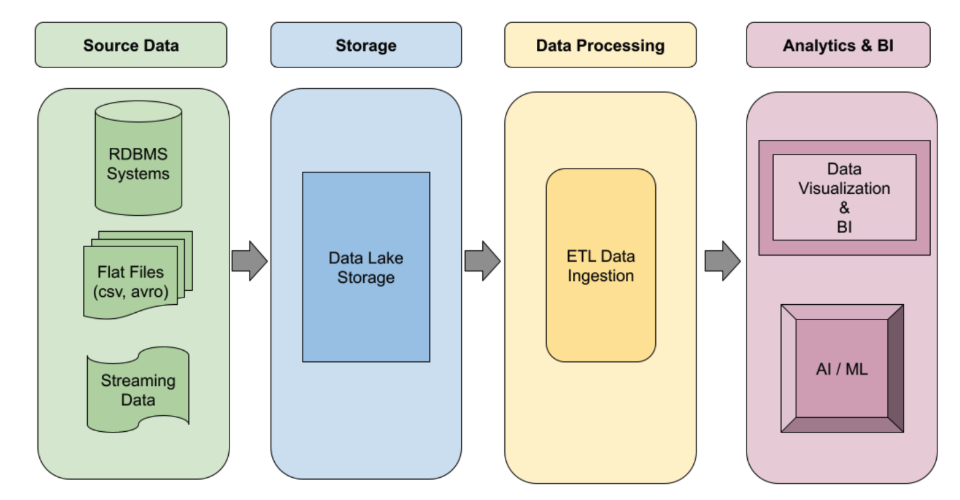


Tutorials, quickstarts, & labs
Automated ETL pipelines
Automated ETL pipelines
Build robust, event-driven Spark ETL pipelines that automatically scale on demand. Leverage serverless execution for spiky workloads or managed clusters for persistent jobs. Use workflow templates to automate your most critical, production-level data processing jobs from end to end.
Data science and machine learning
Interactive data science
Interactive data science
Empower data scientists to explore data and iterate on Spark ML models. Unify SQL and Spark using Gemini with the VSCode agentic extension or your IDE of choice, moving seamlessly from data exploration to model building with PySpark using serverless execution. Attach GPUs with a single command.


Tutorials, quickstarts, & labs
Interactive data science
Interactive data science
Empower data scientists to explore data and iterate on Spark ML models. Unify SQL and Spark using Gemini with the VSCode agentic extension or your IDE of choice, moving seamlessly from data exploration to model building with PySpark using serverless execution. Attach GPUs with a single command.
Lakehouse modernization
Open data lakehouse
Open data lakehouse
Use Managed Service for Apache Spark as the processing engine for your modern data lakehouse. Process data in open formats like Apache Iceberg directly from your data lake, eliminating data silos. Integrate with BigQuery and Lakehouse for Apache Iceberg for a unified, multi-engine analytics platform.
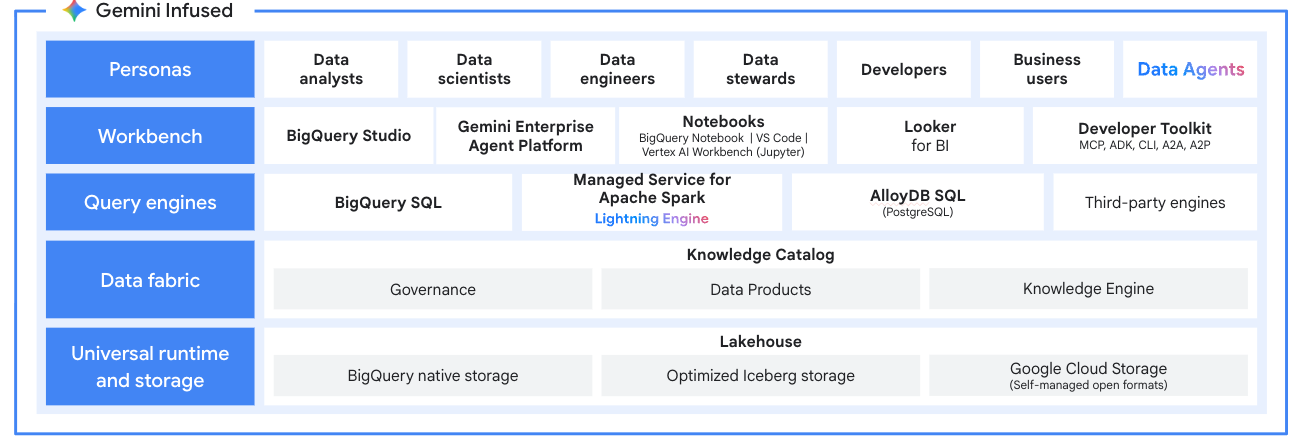

Tutorials, quickstarts, & labs
Open data lakehouse
Open data lakehouse
Use Managed Service for Apache Spark as the processing engine for your modern data lakehouse. Process data in open formats like Apache Iceberg directly from your data lake, eliminating data silos. Integrate with BigQuery and Lakehouse for Apache Iceberg for a unified, multi-engine analytics platform.
Pricing
| How Managed Service for Apache Spark pricing works | Pricing depends on your chosen deployment model. Serverless bills per job execution, while clusters bill for underlying compute and uptime. | |
|---|---|---|
| Deployment mode: | What you pay for: | What you pay: |
Serverless | Pay only for what you use. Billed per-second for compute, GPUs, and shuffle storage. Scale-to-zero ensures you never pay for idle capacity. | Starting at $0.06 per DCU hour |
Premium tier and accelerators: Access Lightning Engine for up to 4.9x faster performance or attach NVIDIA GPUs for AI/ML workloads. | Starting at $0.089 per DCU hour Serverless premium tier | |
Clusters | Pay for cluster uptime. Billed for underlying Compute Engine resources plus a flat management fee. Leverage Spot VMs and zero-scale to optimize costs. | Starting at $0.01 per vCPU hour Management fee |
Lightning Engine add-on: Bring breakthrough performance to your clusters. Experience up to 4.9x faster execution than open source Spark. | Starting at $0.0025 per vCPU hour | |
Learn more about Managed Service for Apache Spark pricing. View all pricing details.
How Managed Service for Apache Spark pricing works
Pricing depends on your chosen deployment model. Serverless bills per job execution, while clusters bill for underlying compute and uptime.
Serverless
Pay only for what you use. Billed per-second for compute, GPUs, and shuffle storage. Scale-to-zero ensures you never pay for idle capacity.
Starting at
$0.06 per DCU hour
Premium tier and accelerators:
Access Lightning Engine for up to 4.9x faster performance or attach NVIDIA GPUs for AI/ML workloads.
Starting at
$0.089 per DCU hour
Serverless premium tier
Clusters
Pay for cluster uptime. Billed for underlying Compute Engine resources plus a flat management fee. Leverage Spot VMs and zero-scale to optimize costs.
Starting at
$0.01 per vCPU hour
Management fee
Lightning Engine add-on:
Bring breakthrough performance to your clusters. Experience up to 4.9x faster execution than open source Spark.
Starting at
$0.0025 per vCPU hour
Learn more about Managed Service for Apache Spark pricing. View all pricing details.
Business Case
Customer success stories

“We saw some of our quality checks go from 11 hours down to minutes.”
Michael Manos, Chief Technology Officer of Dun & Bradstreet
Migrating to Google Cloud has helped Dun & Bradstreet significantly increase the speed of data flows, reducing quality check processes from hours to minutes and cutting the time it takes to publish new data in half. This strong data foundation also enables Dun & Bradstreet to leverage the full power of Google Cloud’s ecosystem, including cutting-edge data and AI technologies.



The Managed Service for Apache Spark difference
Zero-ops productivity with flexible deployment options. Choose serverless execution or fully managed clusters to eliminate infrastructure overhead and the manual tuning tax.
Agentic AI development. Accelerate your workflow with Gemini baked into the VSCode agentic extension or with your IDE of choice along with Data Agents that automate PySpark coding, data wrangling, and job troubleshooting in a unified notebook.
Industry-leading performance. powered by Lightning Engine. Accelerate your most demanding ETL and data science workloads by up to 4.9x, significantly reducing your total cost of ownership










Additional resources:
FAQ
What happened to Dataproc and Serverless Spark?
To simplify your experience, we have unified Dataproc and Google Cloud Serverless for Apache Spark under a single product: Managed Service for Apache Spark. You get the exact same powerful capabilities, but now you simply choose your preferred deployment model—zero-ops serverless or fully managed clusters—from a single, unified interface. Compare both deployment modes in greater detail.
When should I choose serverless versus managed clusters?
Choose serverless when you want to focus purely on code with zero infrastructure management, ideal for new pipelines and ad-hoc analysis. Choose managed clusters when you need fine-grained control, are migrating legacy or cloud Spark or other OSS workloads, or require persistent clusters with diverse open-source tools.
What is Lightning Engine?
Lightning Engine is Google Cloud’s native, highly optimized execution engine. Built with C++ libraries, it optimizes every layer—from high-throughput storage connectors to intelligent caching. It delivers up to 4.9x better performance than standard Spark and 2x the price-performance over the leading high-speed Spark alternative, integrating seamlessly into your serverless or cluster deployments with zero code changes.
Do I need to install my own ML libraries like PyTorch?
No. If you are running AI/ML workloads, you can use our pre-configured ML Runtimes. These environments come with common libraries like PyTorch, XGBoost, and scikit-learn built-in, along with optimized NVIDIA GPU drivers, eliminating complex setup.
Is Managed Service for Apache Spark fully open-source compatible?
Yes. We provide a 100% open-source compatible Apache Spark environment. You can run your existing Spark code without modifications, ensuring complete workload portability and avoiding vendor lock-in.
How does Gemini AI help with Spark development?
Gemini AI can be brought directly into your IDE of choice to act as your AI co-pilot. It helps you write and debug PySpark code faster, while Gemini Cloud Assist provides automated root-cause analysis and troubleshooting recommendations for failed jobs.
Can I use this service to build an open data lakehouse?
Absolutely. Managed Service for Apache Spark is a core processing engine for Google Cloud's open lakehouse. It allows you to process data in open formats like Apache Iceberg directly from Cloud Storage, integrating seamlessly with BigQuery and Knowledge Catalog for Apache Iceberg.
How do the standard and premium pricing tiers work?
The standard and premium tiers currently only apply to serverless deployments. Standard is ideal for cost-effective, general-purpose batch processing and ETL. The premium tier is designed for your most demanding workloads, unlocking the 4.9x performance boost over open source Apache Spark with Lightning Engine and providing access to GPU-accelerated AI/ML capabilities.











