Trino (anciennement Presto) est un moteur de requêtes SQL distribué conçu pour interroger de grands ensembles de données répartis entre une ou plusieurs sources de données hétérogènes. Trino peut interroger Hive, MySQL, Kafka et d'autres sources de données via des connecteurs. Ce tutoriel vous explique comment :
- Installer le service Trino sur un cluster Dataproc
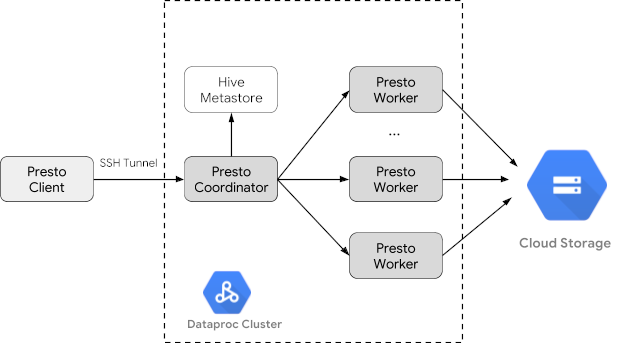
- Interrogez les données publiques d'un client Trino installé sur votre ordinateur local qui communique avec un service Trino sur votre cluster
- Exécuter des requêtes à partir d'une application Java qui communique avec le service Trino sur votre cluster via le pilote Java JDBC Trino
Objectifs
- Extrayez les données de BigQuery.
- Chargez les données dans Cloud Storage sous forme de fichiers CSV.
- Transformez les données :
- Exposer les données sous forme de table externe Hive pour que Trino puisse les interroger
- Convertissez les données du format CSV au format Parquet pour accélérer les requêtes.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
Si vous ne l'avez pas déjà fait, créez un projet Google Cloud et un bucket Cloud Storage pour stocker les données utilisées dans ce tutoriel. 1. Configurer votre projet- Connectez-vous à votre compte Google Cloud. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activer les API Dataproc, Compute Engine, Cloud Storage, and BigQuery.
- Installez Google Cloud CLI.
-
Pour initialiser gcloudCLI, exécutez la commande suivante :
gcloud init
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activer les API Dataproc, Compute Engine, Cloud Storage, and BigQuery.
- Installez Google Cloud CLI.
-
Pour initialiser gcloudCLI, exécutez la commande suivante :
gcloud init
- Dans la console Google Cloud, accédez à la page Buckets Cloud Storage.
- Cliquez sur Créer un bucket.
- Sur la page Créer un bucket, saisissez les informations concernant votre bucket. Pour passer à l'étape suivante, cliquez sur Continuer.
- Pour nommer votre bucket, saisissez un nom qui répond aux exigences de dénomination des buckets.
-
Pour Choisir l'emplacement de stockage des données, procédez comme suit :
- Sélectionnez une option de type d'emplacement.
- Sélectionnez une option Location (Emplacement).
- Pour Choisir une classe de stockage par défaut pour vos données, sélectionnez une classe de stockage.
- Pour le champ Choisir comment contrôler l'accès aux objets, sélectionnez une option de Contrôle des accès.
- Sous Paramètres avancés (facultatif), choisissez une méthode de chiffrement, une règle de conservation ou des libellés de bucket.
- Cliquez sur Create (Créer).
Créer un cluster Dataproc
Créez un cluster Dataproc à l'aide de l'option optional-components (disponible sur les images 2.1 et versions ultérieures) pour installer le composant facultatif Trino sur le cluster et de l'option enable-component-gateway pour activer la passerelle des composants et accéder à l'interface utilisateur Web de Trino depuis la console Google Cloud.
- Définissez les variables d'environnement :
- PROJECT : ID du projet
- BUCKET_NAME: : nom du bucket Cloud Storage créé à la section Avant de commencer
- REGION : région dans laquelle le cluster utilisé dans ce tutoriel sera créé (par exemple, "us-west1")
- WORKERS : trois à cinq nœuds de calcul sont recommandés pour ce tutoriel
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- Exécutez la Google Cloud CLI sur votre ordinateur local pour créer le cluster.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
Préparer les données
Exportez l'ensemble de données bigquery-public-data chicago_taxi_trips vers Cloud Storage sous forme de fichiers CSV, puis créez une table externe Hive pour référencer les données.
- Sur votre ordinateur local, exécutez la commande suivante pour importer les données relatives aux taxis issues de BigQuery sous forme de fichiers CSV sans en-têtes dans le bucket Cloud Storage créé à la section Avant de commencer.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Créez des tables externes Hive sauvegardées sous forme de fichiers CSV et Parquet dans le bucket Cloud Storage.
- Créez la table externe Hive
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Vérifiez que la table externe Hive a été créée.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - Créez une autre table externe Hive
chicago_taxi_trips_parquetavec les mêmes colonnes, mais avec des données stockées au format Parquet pour améliorer les performances des requêtes.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Chargez les données issues de la table CSV Hive dans la table Parquet Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - Vérifiez que les données ont été chargées correctement.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Créez la table externe Hive
Exécuter des requêtes
Vous pouvez exécuter des requêtes localement à partir de la CLI Trino ou d'une application.
Requêtes de la CLI Trino
Cette section explique comment interroger l'ensemble de données Parquet Hive sur les taxis à l'aide de la CLI Trino.
- Exécutez la commande suivante sur votre ordinateur local pour vous connecter en SSH au nœud maître de votre cluster. Le terminal local cessera de répondre pendant l'exécution de la commande.
gcloud compute ssh trino-cluster-m
- Dans la fenêtre de terminal SSH du nœud maître de votre cluster, exécutez la CLI Trino, qui se connecte au serveur Trino exécuté sur le nœud maître.
trino --catalog hive --schema default
- Lorsque l'invite
trino:defaults'affiche, vérifiez que Trino peut trouver les tables Hive.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- Exécutez les requêtes à partir de l'invite
trino:default, et comparez les performances d'interrogation des données Parquet par rapport aux données CSV.- Requête de données Parquet
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - Requête de données CSV
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Requête de données Parquet
Requêtes depuis une application Java
Pour exécuter des requêtes à partir d'une application Java via le pilote Java JDBC Trino :
1. Téléchargez le pilote Java JDBC Trino.
1. Ajoutez une dépendance trino-jdbc dans le fichier Maven pom.xml.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>Exemple de code Java
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
Journalisation et surveillance
Journalisation
Les journaux Trino se trouvent dans /var/log/trino/ sur les nœuds maîtres et de calcul du cluster.
UI Web
Consultez la section Afficher les URL de la passerelle des composants et y accéder pour ouvrir l'interface utilisateur Web de Trino s'exécutant sur le nœud maître du cluster dans votre navigateur local.
Surveillance
Trino expose les informations d'exécution du cluster via des tables d'exécution.
Dans une invite de session Trino (à partir de trino:default), exécutez la requête suivante pour afficher les données de la table d'exécution:
select * FROM system.runtime.nodes;
Effectuer un nettoyage
Une fois le tutoriel terminé, vous pouvez procéder au nettoyage des ressources que vous avez créées afin qu'elles ne soient plus comptabilisées dans votre quota et qu'elles ne vous soient plus facturées. Dans les sections suivantes, nous allons voir comment supprimer ou désactiver ces ressources.
Supprimer le projet
Le moyen le plus simple d'empêcher la facturation est de supprimer le projet que vous avez créé pour ce tutoriel.
Pour supprimer le projet :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Supprimer le cluster
- Pour supprimer le cluster :
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
Supprimer le bucket
- Pour supprimer le bucket Cloud Storage que vous avez créé à la section Avant de commencer, y compris les fichiers de données qui y sont stockés:
gsutil -m rm -r gs://${BUCKET_NAME}