クライアント ライブラリを使用して Dataproc クラスタを作成する
下に記載のサンプルコードは、Cloud クライアント ライブラリを使用して Dataproc クラスタを作成し、そのクラスタでジョブを実行した後、そのクラスタを削除する方法を示しています。
以下を使用してこうしたタスクを実行することもできます。
- API Explorer を使用したクイックスタートの API REST リクエスト
- Google Cloud コンソールを使用して Dataproc クラスタを作成するの Google Cloud コンソール
- Google Cloud CLI を使用して Dataproc クラスタを作成するの Google Cloud CLI
準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Dataproc API を有効にします。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Dataproc API を有効にします。
コードの実行
チュートリアルを試す: [Cloud Shell で開く] をクリックして、Python Cloud クライアント ライブラリのチュートリアルを実行します。このチュートリアルでは、クラスタを作成し、PySpark ジョブを実行した後、クラスタを削除します。
Go
- クライアント ライブラリをインストールします。詳しくは、開発環境の設定をご覧ください。
- 認証の設定
- サンプル GitHub コードのクローンを作成して実行します。
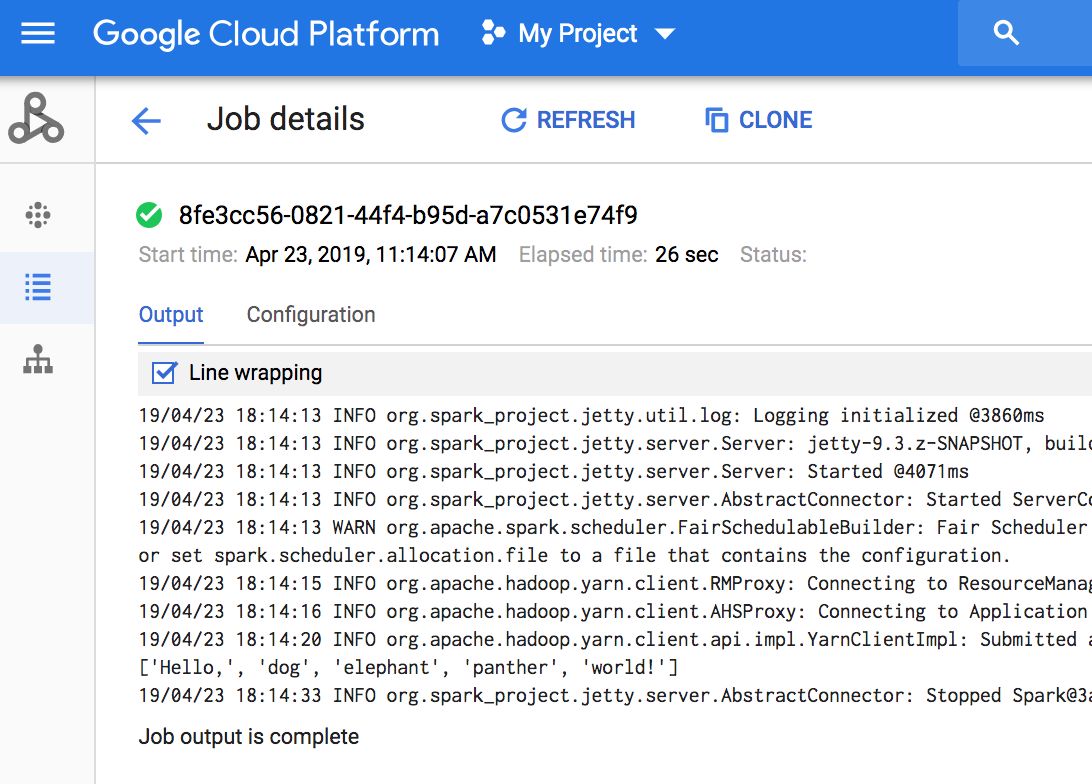
- 出力を確認します。このコードでは、Cloud Storage のデフォルトの Dataproc ステージング バケットにジョブドライバのログが出力されます。プロジェクトの Dataproc の [ジョブ] セクションで、Google Cloud コンソールからジョブドライバ出力を表示できます。ジョブの詳細ページで [ジョブ ID] をクリックすると、ジョブの出力が表示されます。
Java
- クライアント ライブラリをインストールします。詳細については、Java 開発環境の設定をご覧ください。
- 認証の設定
- サンプル GitHub コードのクローンを作成して実行します。
- 出力を確認します。このコードでは、Cloud Storage のデフォルトの Dataproc ステージング バケットにジョブドライバのログが出力されます。プロジェクトの Dataproc の [ジョブ] セクションで、Google Cloud コンソールからジョブドライバ出力を表示できます。ジョブの詳細ページで [ジョブ ID] をクリックすると、ジョブの出力が表示されます。
Node.js
- クライアント ライブラリをインストールします。詳細については、Node.js 開発環境の設定をご覧ください。
- 認証の設定
- サンプル GitHub コードのクローンを作成して実行します。
- 出力を確認します。このコードでは、Cloud Storage のデフォルトの Dataproc ステージング バケットにジョブドライバのログが出力されます。プロジェクトの Dataproc の [ジョブ] セクションで、Google Cloud コンソールからジョブドライバ出力を表示できます。ジョブの詳細ページで [ジョブ ID] をクリックすると、ジョブの出力が表示されます。
Python
- クライアント ライブラリをインストールします。詳細については、Python 開発環境の設定をご覧ください。
- 認証の設定
- サンプル GitHub コードのクローンを作成して実行します。
- 出力を確認します。このコードでは、Cloud Storage のデフォルトの Dataproc ステージング バケットにジョブドライバのログが出力されます。プロジェクトの Dataproc の [ジョブ] セクションで、Google Cloud コンソールからジョブドライバ出力を表示できます。ジョブの詳細ページで [ジョブ ID] をクリックすると、ジョブの出力が表示されます。
次のステップ
- Dataproc Cloud クライアント ライブラリの追加リソースをご覧ください。