Dataproc 集群是在 Compute Engine 实例上构建的。机器类型定义了实例可用的虚拟化硬件资源。Compute Engine 提供了预定义机器类型和自定义机器类型。Dataproc 集群可以对主实例节点和/或工作器节点使用预定义类型和自定义类型。
Dataproc 集群支持以下 Compute Engine 预定义机器类型(机器类型可用性因区域而异):
- 通用机器类型,包括 N1、N2、N2D 和 E2 机器类型(Dataproc 还支持 N1、N2、N2D 和 E2 自定义机器类型)。
限制:
- 2.0 及更高版本的映像不支持 n1-standard-1 机器类型(对于 2.0 及以上版本的映像,不建议使用 n1-standard-1 机器类型;请改用具有更高内存的机器类型。
- 不支持共享核心机器类型,其中包括以下不受支持的机器类型:
- E2:e2-micro、e2-small 和 e2-medium 共享核心机器类型,以及
- N1:f1-micro 和 g1-small 共享核心机器类型。
- 计算优化机器类型,包括 C2 和 C2D 机器类型。
- 内存优化机器类型,包括 M1 和 M2 机器类型。
- ARM 机器类型,包括 T2A 机器类型。
自定义机器类型
Dataproc 支持 N1 系列 自定义机器类型。
自定义机器类型非常适合以下工作负载:
- 不适合使用预定义机器类型的工作负载。
- 需要更高的处理能力或更大的内存、但又不需要更高级别的机器类型所提供的全面升级的工作负载。
例如,如果您工作负载需要的处理能力比 n1-standard-4 实例提供的多,但下一步 n1-standard-8 实例将提供过多容量。借助自定义机器类型,您可以创建将主实例节点和/或工作器节点置于中间范围的 Dataproc 集群(具有 6 个虚拟 CPU 和 25 GB 内存)。
指定自定义机器类型
自定义机器类型使用特殊的 machine type 规范,并且受限制的约束。例如,具有 6 个虚拟 CPU 和 22.5 GB 内存的自定义虚拟机的自定义机器类型规格为 custom-6-23040。
机器类型规范中的数字与机器中的虚拟 CPU (vCPU) 数量 (6) 和内存量 (23040) 对应。内存量是以 GB 为单位的内存量乘以 1024 来计算(请参阅以 GB 或 MB 表示内存)。在以下示例中,22.5 (GB) 乘以 1024:22.5 * 1024 = 23040。
上述语法可用于为您的集群指定自定义机器类型。您可以在创建集群时为主节点或/或工作器节点设置机器类型。如果同时设置两者,则主实例节点可以使用与工作器节点不同的自定义机器类型。任何辅助工作器使用的机器类型设置以主要工作器的设置为准,不能单独进行设置(请参阅辅助工作器 - 抢占式虚拟机和非抢占式虚拟机)。
自定义机器类型价格
自定义机器类型价格基于自定义机器类型中使用的资源。Dataproc 价格会添加到计算资源的费用中,并基于集群中使用的虚拟 CPU (vCPU) 总数。
使用指定机器类型创建 Dataproc 集群
控制台
在 Google Cloud 控制台中,从 Dataproc 创建集群页面的配置节点面板中,为集群的主节点和工作器节点选择机器系列、系列和类型。
gcloud 命令
运行带有以下标志的 gcloud dataproc clusters create 命令,以创建具有主实例和/或工作器机器类型的 Dataproc 集群:
--master-machine-type machine-type标志让您可设置集群中主虚拟机实例(如果创建 HA 集群,则为主实例)所用的预定义或自定义机器类型--worker-machine-type custom-machine-type标志让您可设置集群中工作器虚拟机实例所用的预定义或自定义机器类型
示例:
gcloud dataproc clusters create test-cluster / --master-machine-type custom-6-23040 / --worker-machine-type custom-6-23040 / other argsDataproc 集群启动后,集群详细信息将显示在终端窗口中。终端窗口中显示的集群属性的部分示例列表如下:
... properties: distcp:mapreduce.map.java.opts: -Xmx1638m distcp:mapreduce.map.memory.mb: '2048' distcp:mapreduce.reduce.java.opts: -Xmx4915m distcp:mapreduce.reduce.memory.mb: '6144' mapred:mapreduce.map.cpu.vcores: '1' mapred:mapreduce.map.java.opts: -Xmx1638m ...
REST API
如需创建使用自定义机器类型的集群,请在 masterConfig 和/或 cluster.create API 请求的 workerConfig
InstanceGroupConfig 中设置 machineTypeUri。
示例:
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "test-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
}
}
}
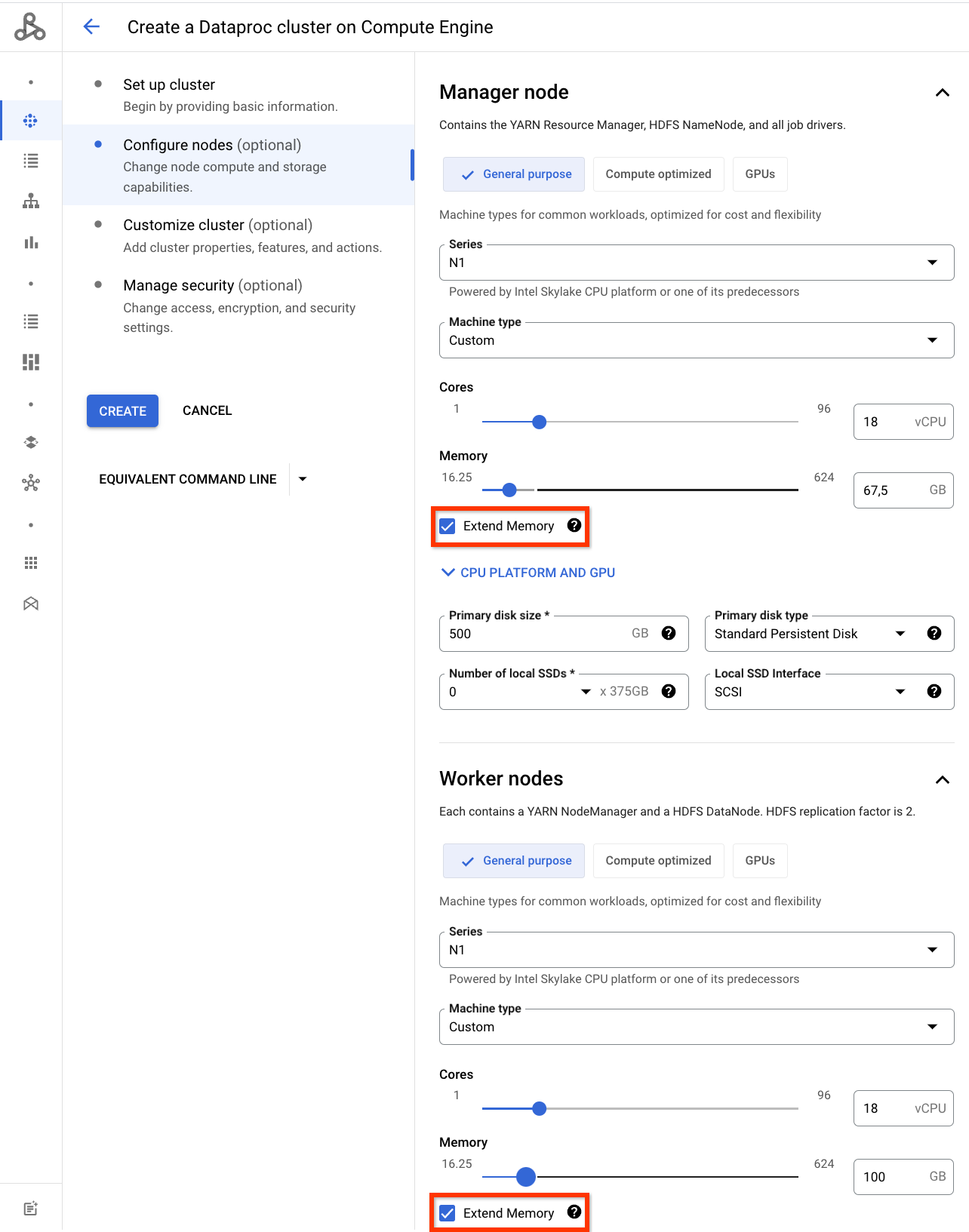
使用具有扩展内存的自定义机器类型创建 Dataproc 集群
Dataproc 支持满足以下条件的自定义机器类型:扩展内存超过每个 vCPU 6.5 GB 内存的限制(请参阅扩展内存价格)。
控制台
在 Google Cloud 控制台中 Dataproc 创建集群页面上的配置节点面板中,在主节点和/或工作器节点部分自定义机器类型内存时,请点击扩展内存。
gcloud 命令
要通过具有扩展内存的自定义 CPU 的 gcloud 命令行创建集群,请向 ‑‑master-machine-type 和/或 ‑‑worker-machine-type 标志添加 -ext 后缀。
示例
以下 gcloud 命令行示例可创建一个 Dataproc 集群,该集群的每个节点具有 1 个 CPU 和 50 GB 内存 (50 * 1024 = 51200):
gcloud dataproc clusters create test-cluster / --master-machine-type custom-1-51200-ext / --worker-machine-type custom-1-51200-ext / other args
API
以下示例
...
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "custom-1-51200-ext",
...
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "custom-1-51200-ext",
...
...
ARM 机器类型
Dataproc 支持创建集群,其中包含使用 ARM 机器类型(例如 T2A 机器类型)的节点。
要求和限制:
- Dataproc 映像必须与 ARM 芯片组兼容(目前,只有 Dataproc 2.1-ubuntu20-arm 映像与 ARM 芯片组兼容)。请注意,此映像不支持许多可选和初始化操作组件(请参阅 2.1.x 发布版本)。
- 由于必须为集群指定一个映像,因此主节点、工作器节点和辅助工作器节点必须使用与所选 Dataproc ARM 映像兼容的 ARM 机器类型。
- 与 ARM 机器类型不兼容的 Dataproc 功能不可用(例如,T2A 机器类型不支持本地 SSD)。
创建具有 ARM 机器类型的 Dataproc 集群
控制台
目前,Google Cloud 控制台不支持创建 Dataproc ARM 机器类型集群。
gcloud
如需创建使用 ARM t2a-standard-4 机器类型的 Dataproc 集群,请在终端窗口或 Cloud Shell 中本地运行以下 gcloud 命令。
gcloud dataproc clusters create cluster-name \ --region=REGION \ --image-version=2.1-ubuntu20-arm \ --master-machine-type=t2a-standard-4 \ --worker-machine-type=t2a-standard-4
备注:
REGION:集群所在的区域。
ARM 映像从
2.1.18-ubuntu20-arm开始提供。如需了解可用于自定义集群的其他命令行标志,请参阅 gcloud dataproc clusters create 参考文档。
*-arm images仅支持已安装的组件和 2.1.x 发布版本页面上列出的以下可选组件(不支持该页面上列出的其余 2.1 可选组件和所有初始化操作):- Apache Hive WebHCat
- Docker
- Zookeeper(安装在高可用性集群中;非高可用性集群中的可选组件)
API
以下示例 Dataproc REST API clusters.create 请求会创建一个 ARM 机器类型集群。
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "sample-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "t2a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "t2a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"softwareConfig": {
"imageVersion": "2.1-ubuntu20-arm"
}
}
}
如需深入了解
- 请参阅使用自定义机器类型创建虚拟机实例。
- 请参阅创建和启动 Arm 虚拟机实例。