Dataflow
リアルタイムのデータ インテリジェンス
リアルタイム データの可能性を最大限に引き出します。Dataflow は、リアルタイムの意思決定とカスタマー エクスペリエンスを加速するのに役立つ、使いやすくてスケーラブルなフルマネージド ストリーミング プラットフォームです。
新規のお客様には、Dataflow で使用できる無料クレジット $300 分を差し上げます。

機能
ストリーミング AI と ML を使用して、生成 AI モデルをリアルタイムで強化
リアルタイム データにより、AI / ML モデルに最新情報を提供し、予測精度を高めます。Dataflow ML は、完全な ML パイプラインのデプロイと管理を簡素化します。パーソナライズされた推奨事項、不正行為の検出、脅威の防止などに、すぐに使用できるパターンが用意されています。Gemini Enterprise Agent Platform、Gemini モデル、Gemma モデルを使用してストリーミング AIを構築し、リモート推論を実行し、MLTransform を使用してデータ処理を合理化します。Dataflow GPU と Right Fitting 機能を使用して、MLOps と ML ジョブの効率を高めます。
エンタープライズ規模での高度なストリーミングのユースケースを実現
Dataflow は、オープンソースの Apache Beam SDK を使用してエンタープライズ規模での高度なストリーミングのユースケースを実現するフルマネージド サービスです。状態と時間、変換、I/O コネクタなどの豊富な機能を備えています。Dataflow はジョブあたり 4,000 ワーカーまでスケーリングでき、ペタバイト規模のデータを定期的に処理します。自動スケーリングにより、バッチ パイプラインとストリーミング パイプラインの両方で最適なリソース使用率を実現できます。

生成 AI 向けのマルチモーダル データ処理をデプロイする
Dataflow では、画像、テキスト、音声などのマルチモーダル データを並行して取り込み、変換できます。各モダリティに特化した特徴抽出を適用し、それらの特徴を統合表現に融合します。これにより、データフィードが生成 AI モデルに融合され、多様な入力から新しいコンテンツを作成できるようになります。Google 社内チームは Dataflow と FlumeJava を利用して、利用可能な大規模な入力データプールに対して、レイテンシ要件なしでモデル予測を整理して計算します。
テンプレートとノートブックで価値創出までの時間を短縮
Dataflow には、簡単に使い始めることができるツールが揃っています。Dataflow テンプレート ストリーム処理とバッチ処理用に事前に設計されたブループリントであり、効率的な CDC と BigQuery データ統合のために最適化されています。Gemini Enterprise Agent Platform Notebooks を使用して、最新のデータ サイエンス フレームワークでゼロからパイプラインを反復的に構築し、Dataflow ランナーを使用してデプロイします。Dataflow ジョブビルダーは、コードを記述せずに Google Cloud コンソールで Dataflow パイプラインを構築して実行するためのビジュアル UI です。
スマートな診断ツールとモニタリング ツールで時間を節約
Dataflow には包括的な診断ツールとモニタリング ツールが用意されています。ストラグラー検出によりパフォーマンスのボトルネックが自動的に特定され、データ サンプリングにより各パイプライン ステップでデータを観察できます。Dataflow の分析情報は、ジョブの改善に関する推奨事項を提供します。Dataflow UI には、ジョブグラフ、実行の詳細、指標、自動スケーリング ダッシュボード、ロギングなどの豊富なモニタリング ツールが用意されています。Dataflow には、費用を簡単に見積もることができるジョブ費用モニタリング UI も用意されています。
組み込みのガバナンスとセキュリティ
Dataflow では、Confidential VM のサポートによる使用中のデータの暗号化、顧客管理の暗号鍵(CMEK)、VPC Service Controls の統合、パブリック IP の無効化など、さまざまな方法でデータを保護できます。Dataflow 監査ロギングを使用すると、組織は Dataflow の使用状況を可視化し、「誰がいつどこで何をしたか」を調べられるようになり、ガバナンスが向上します。

リアルタイム分析
リアルタイムの分析と運用パイプラインのためにストリーミング データを取り込む
リアルタイムの分析と運用パイプラインのためにストリーミング データを取り込む
ストリーミング データソース(Pub/Sub、Kafka、CDC イベント、ユーザー クリックストリーム、ログ、センサーデータ)を BigQuery、Google Cloud Storage データレイク、Spanner、Bigtable、SQL ストア、Splunk、Datadog などに統合して、データ ストリーミングの取り組みを開始します。最適化された Dataflow テンプレートにより、数回のクリックでノーコードでパイプラインを設定できます。統合された UDF ビルダーを使用してテンプレート ジョブにカスタム ロジックを追加するか、Beam 変換と I/O コネクタのエコシステムの機能をフル活用して、カスタム ETL パイプラインをゼロから作成します。Dataflow は、ETL で処理されたデータを BigQuery から OLTP ストアに戻して、高速ルックアップとエンドユーザーへのサービスを提供するためにもよく使用されます。ストリーミング データを複数のストレージ ロケーションに書き込むのは、Dataflow の一般的なパターンです。

最初の Dataflow ジョブを起動し、Dataflow の基礎に関する自習型コースを受講してください。
チュートリアル、クイックスタート、ラボ
リアルタイムの分析と運用パイプラインのためにストリーミング データを取り込む
リアルタイムの分析と運用パイプラインのためにストリーミング データを取り込む
ストリーミング データソース(Pub/Sub、Kafka、CDC イベント、ユーザー クリックストリーム、ログ、センサーデータ)を BigQuery、Google Cloud Storage データレイク、Spanner、Bigtable、SQL ストア、Splunk、Datadog などに統合して、データ ストリーミングの取り組みを開始します。最適化された Dataflow テンプレートにより、数回のクリックでノーコードでパイプラインを設定できます。統合された UDF ビルダーを使用してテンプレート ジョブにカスタム ロジックを追加するか、Beam 変換と I/O コネクタのエコシステムの機能をフル活用して、カスタム ETL パイプラインをゼロから作成します。Dataflow は、ETL で処理されたデータを BigQuery から OLTP ストアに戻して、高速ルックアップとエンドユーザーへのサービスを提供するためにもよく使用されます。ストリーミング データを複数のストレージ ロケーションに書き込むのは、Dataflow の一般的なパターンです。
最初の Dataflow ジョブを起動し、Dataflow の基礎に関する自習型コースを受講してください。
リアルタイム ETL とデータ統合
リアルタイム データでデータ プラットフォームをモダナイズ
リアルタイム データでデータ プラットフォームをモダナイズ
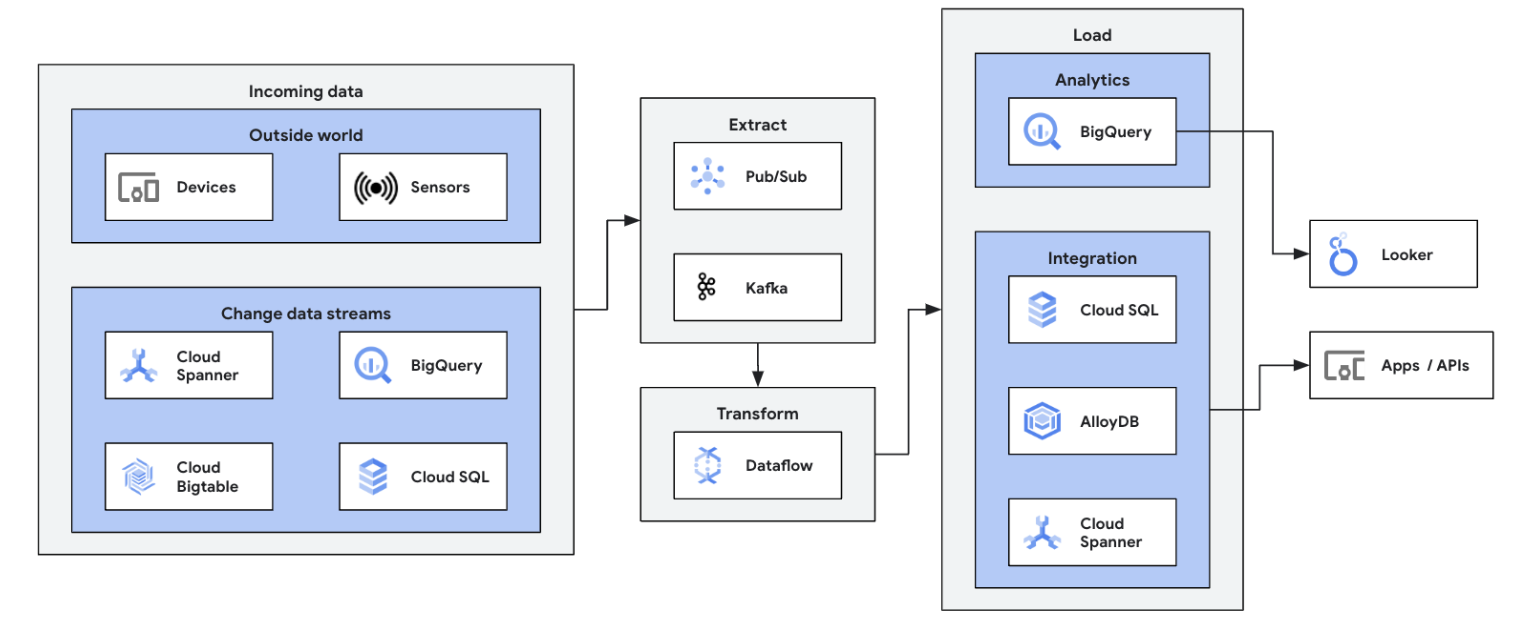
リアルタイムの ETL と統合プロセス、即時のデータの書き込みにより、迅速な分析と意思決定を可能にします。Dataflow のサーバーレス アーキテクチャとストリーミング機能は、リアルタイム ETL パイプラインの構築に最適です。Dataflow の自動スケーリング機能により効率性とスケーラビリティが確保されると同時に、さまざまなデータソースと宛先がサポートされているため、統合が容易になります。
こちらの Google Cloud Skills Boost コースで、Dataflow でのバッチ処理の基礎知識を習得しましょう。
チュートリアル、クイックスタート、ラボ
リアルタイム データでデータ プラットフォームをモダナイズ
リアルタイム データでデータ プラットフォームをモダナイズ
リアルタイムの ETL と統合プロセス、即時のデータの書き込みにより、迅速な分析と意思決定を可能にします。Dataflow のサーバーレス アーキテクチャとストリーミング機能は、リアルタイム ETL パイプラインの構築に最適です。Dataflow の自動スケーリング機能により効率性とスケーラビリティが確保されると同時に、さまざまなデータソースと宛先がサポートされているため、統合が容易になります。
こちらの Google Cloud Skills Boost コースで、Dataflow でのバッチ処理の基礎知識を習得しましょう。
リアルタイム ML と生成 AI
ストリーミング ML / AI でリアルタイムに対応
ストリーミング ML / AI でリアルタイムに対応
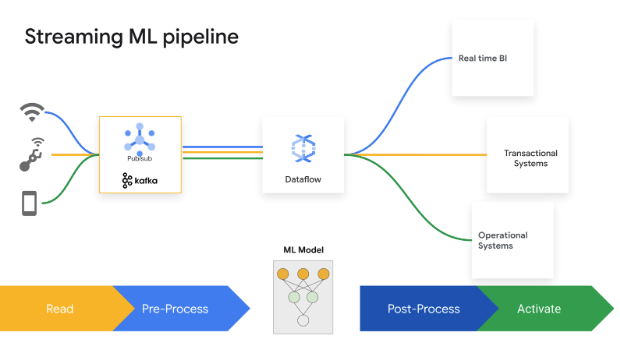
瞬時の判断はビジネスにおける価値を高めます。Dataflow のストリーミング AI と ML により、お客様は低レイテンシの予測と推論、リアルタイム パーソナライズ、脅威検出、不正行為防止など、リアルタイム インテリジェンスが重要となるさまざまなユースケースを実装できます。MLTransform を使用してデータを前処理する。これにより、複雑なコードの記述や基盤となるライブラリの管理からデータの変換に集中できます。RunInference を使用して生成 AI モデルに対して予測を行う。
チュートリアル、クイックスタート、ラボ
ストリーミング ML / AI でリアルタイムに対応
ストリーミング ML / AI でリアルタイムに対応
瞬時の判断はビジネスにおける価値を高めます。Dataflow のストリーミング AI と ML により、お客様は低レイテンシの予測と推論、リアルタイム パーソナライズ、脅威検出、不正行為防止など、リアルタイム インテリジェンスが重要となるさまざまなユースケースを実装できます。MLTransform を使用してデータを前処理する。これにより、複雑なコードの記述や基盤となるライブラリの管理からデータの変換に集中できます。RunInference を使用して生成 AI モデルに対して予測を行う。
マーケティング インテリジェンス
リアルタイムの分析情報でマーケティングを変革
リアルタイムの分析情報でマーケティングを変革
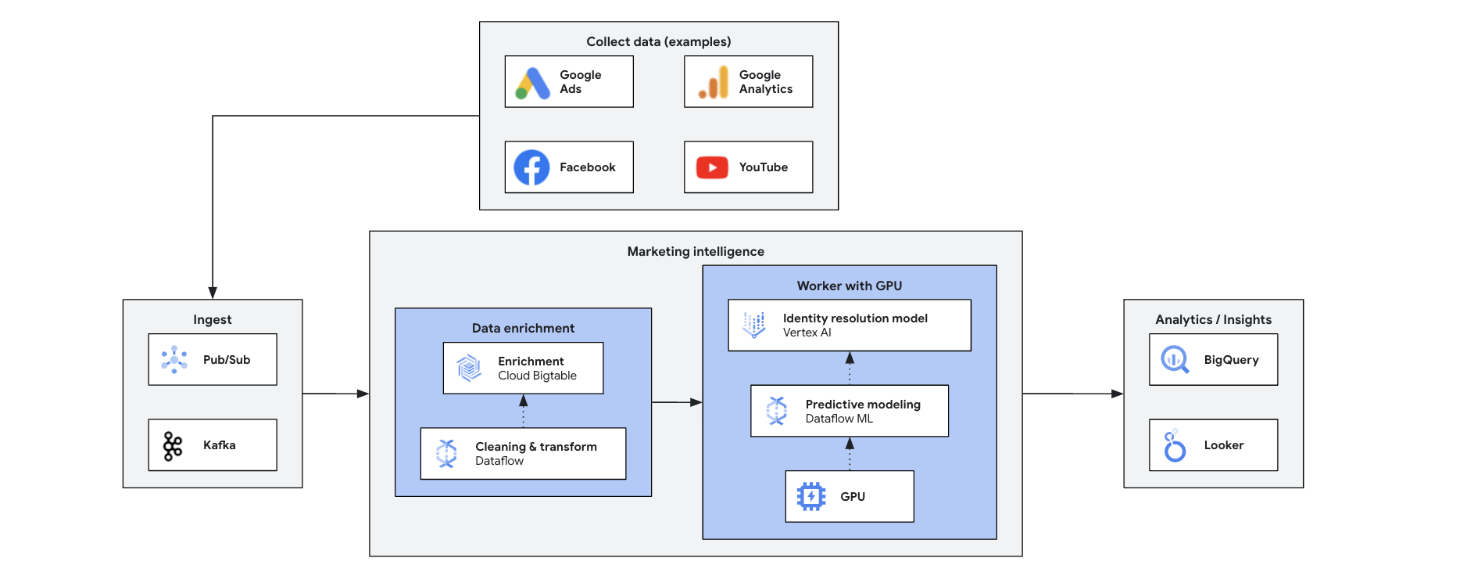
リアルタイムのマーケティング インテリジェンスで、現在の市場、顧客、競合他社のデータを分析し、情報に基づいた迅速な意思決定を行います。これにより、トレンド、行動、競合アクションに対するアジャイルな対応を可能にし、マーケティングを変革します。次のような利点があります。
- 一人ひとりに合わせたサービスによるリアルタイムのオムニチャネル マーケティング
- パーソナライズされたインタラクションによる顧客管理の改善
- アジャイルなマーケティング ミックスの最適化
- 動的ユーザー セグメンテーション
- 競争力を維持するための競合に関する情報
- ソーシャル メディアでのプロアクティブな危機管理
チュートリアル、クイックスタート、ラボ
リアルタイムの分析情報でマーケティングを変革
リアルタイムの分析情報でマーケティングを変革
リアルタイムのマーケティング インテリジェンスで、現在の市場、顧客、競合他社のデータを分析し、情報に基づいた迅速な意思決定を行います。これにより、トレンド、行動、競合アクションに対するアジャイルな対応を可能にし、マーケティングを変革します。次のような利点があります。
- 一人ひとりに合わせたサービスによるリアルタイムのオムニチャネル マーケティング
- パーソナライズされたインタラクションによる顧客管理の改善
- アジャイルなマーケティング ミックスの最適化
- 動的ユーザー セグメンテーション
- 競争力を維持するための競合に関する情報
- ソーシャル メディアでのプロアクティブな危機管理
クリックストリームの分析
ウェブとアプリのエクスペリエンスを最適化してパーソナライズする
ウェブとアプリのエクスペリエンスを最適化してパーソナライズする
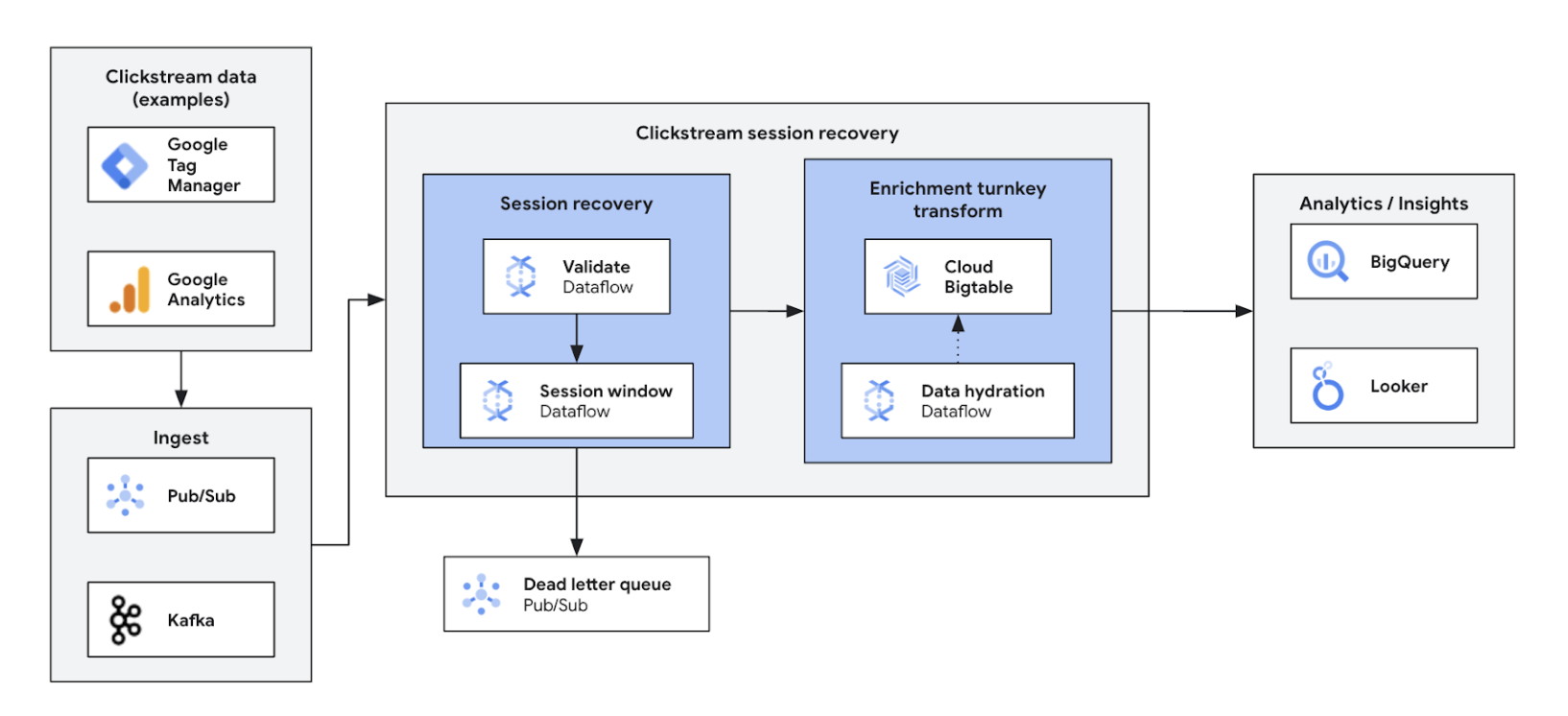
リアルタイムのクリックストリーム分析を使用すると、企業はウェブサイトやアプリでのユーザー インタラクションを瞬時に分析できます。これにより、リアルタイムのパーソナライズ、A/B テスト、ファネルの最適化が可能になり、エンゲージメントの向上、プロダクト開発の迅速化、離脱の削減、サービスに関するサポートの強化につながります。最終的には、優れたユーザー エクスペリエンスを実現し、動的な価格設定とパーソナライズされたレコメンデーションを通じてビジネスの成長を促進します。
チュートリアル、クイックスタート、ラボ
ウェブとアプリのエクスペリエンスを最適化してパーソナライズする
ウェブとアプリのエクスペリエンスを最適化してパーソナライズする
リアルタイムのクリックストリーム分析を使用すると、企業はウェブサイトやアプリでのユーザー インタラクションを瞬時に分析できます。これにより、リアルタイムのパーソナライズ、A/B テスト、ファネルの最適化が可能になり、エンゲージメントの向上、プロダクト開発の迅速化、離脱の削減、サービスに関するサポートの強化につながります。最終的には、優れたユーザー エクスペリエンスを実現し、動的な価格設定とパーソナライズされたレコメンデーションを通じてビジネスの成長を促進します。
リアルタイムのログ レプリケーションと分析
一元化されたログ管理と分析
一元化されたログ管理と分析
Dataflow を使用して Splunk などのサードパーティ プラットフォームに Google Cloud のログをレプリケートし、準リアルタイムのログ処理と分析を行うことができます。このソリューションは、ログ管理、コンプライアンス、監査、分析機能を一元化しながら、費用を削減し、パフォーマンスを向上させます。
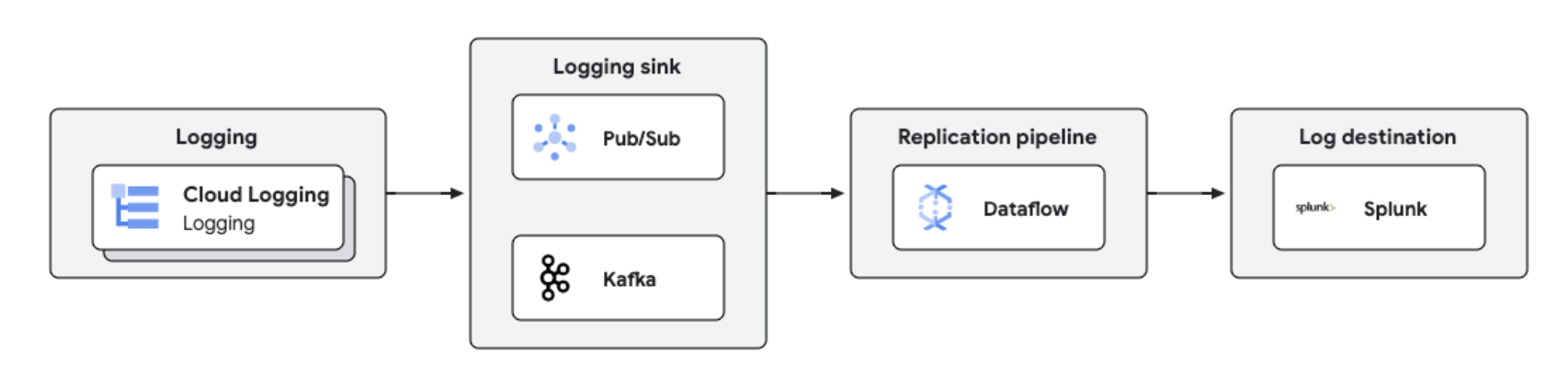
チュートリアル、クイックスタート、ラボ
一元化されたログ管理と分析
一元化されたログ管理と分析
Dataflow を使用して Splunk などのサードパーティ プラットフォームに Google Cloud のログをレプリケートし、準リアルタイムのログ処理と分析を行うことができます。このソリューションは、ログ管理、コンプライアンス、監査、分析機能を一元化しながら、費用を削減し、パフォーマンスを向上させます。
料金
| Dataflow の料金の仕組み | Dataflow の課金とリソースモデルについて学習する。 | |
|---|---|---|
| サービスと用途 | 説明 | 料金 |
Dataflow のコンピューティング リソース | Dataflow のコンピューティング リソースに対する課金には、以下が含まれます。 | 詳しくは、料金ページをご覧ください |
その他の Dataflow リソース | 詳しくは、料金ページをご覧ください | |
Dataflow の確約利用割引(CUD) | Dataflow CUD では、コミットメント期間に応じた 2 つのレベルの割引が用意されています。
| Dataflow CUD の詳細 |
Dataflow の料金の詳細すべての料金の詳細を見る。
Dataflow の料金の仕組み
Dataflow の課金とリソースモデルについて学習する。
Dataflow の確約利用割引(CUD)
Dataflow CUD では、コミットメント期間に応じた 2 つのレベルの割引が用意されています。
- 1 年間の CUD では、オンデマンド料金から 20% 割引となります。
- 3 年間の CUD では、オンデマンド料金から 40% 割引となります。
Dataflow CUD の詳細
Dataflow の料金の詳細すべての料金の詳細を見る。
ビジネスケース
業界をリードするお客様が Dataflow を選ぶ理由
ANZ Bank、Google Cloud SRE 担当プロダクト オーナー Namitha Vijaya Kumar 氏
「Dataflow は、バッチ処理とリアルタイム データ処理の両方に対応しており、エンタープライズのデータレイクにおいてデータを適宜、最新の状態に維持できます。その結果、分析/意思決定のためのダウンストリーム データの使用や、小売業のお客様へのリアルタイム通知の配信が促進されます。」
Dataflow のメリット
ストリーミング ML が簡単に
AI / ML にストリーミングを導入するターンキー機能: 推論のための RunInference、モデル トレーニングの前処理のための MLTransform、特徴量ストアの検索のための拡充、動的 GPU のサポートはすべて、限られた GPU リソースに無駄な費用をかけずにトイルを削減します。
堅牢なツールで最適なコスト パフォーマンスを実現
Dataflow は、パフォーマンスとリソース使用量を最大化する自動最適化により、費用対効果に優れたストリーミングを提供します。あらゆるワークロードに合わせて簡単にスケーリングでき、AI による自己回復機能を備えています。堅牢なツールが運用と理解に役立ちます。
オープン、移植可能、拡張可能
Dataflow はオープンソースの Apache Beam 向けに構築されており、バッチとストリーミングの統合をサポートするため、クラウド、オンプレミス、エッジデバイス間でワークロードを移植できます。
パートナーとインテグレーション




Dataflow パートナー
Google Cloud パートナーが Dataflow との統合機能を開発しており、さまざまな規模での強力なデータ処理タスクが迅速かつ容易に行えるようになっています。すべてのパートナーを参照し、今すぐストリーミングを始めましょう。


















