Anomaly detection using streaming analytics & AI
Masud Hasan
Solutions Architect, Google Cloud
Cody Irwin
Solutions Manager, Google Cloud
An organization’s ability to quickly detect and respond to anomalies is critical to success in a digitally transforming culture. Google Cloud customers can strengthen this ability by using rich artificial intelligence and machine learning (AI/ML) capabilities in conjunction with an enterprise-class streaming analytics platform. We refer to this combination of fast data and advanced analytics as real-time AI. There are many applications for real-time AI across businesses, including anomaly detection, video analysis, and forecasting.
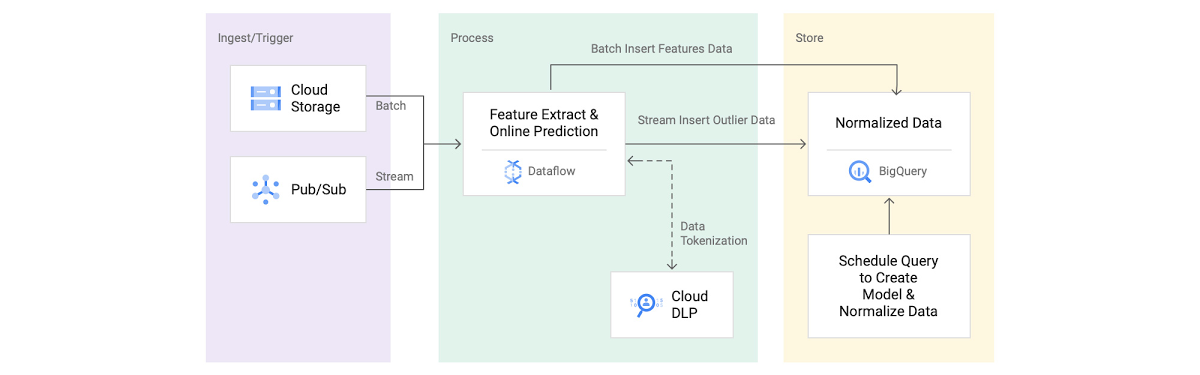
In this post, we walk through a real-time AI pattern for detecting anomalies in log files. By analyzing and extracting features from network logs, we helped a telecommunications (telco) customer build a streaming analytics pipeline to detect anomalies. We also discuss how you can adapt this pattern to meet your organization’s real-time needs.
How anomaly detection can help your business
Anomaly detection allows companies to identify, or even predict, abnormal patterns in unbounded data streams. Whether you are a large retailer identifying positive buying behaviors, a financial services provider detecting fraud, or a telco company identifying and mitigating potential threats, behavioral patterns that provide useful insights exist in your data.
Enabling real-time anomaly detection for a security use case
For telco customers, protecting their wireless networks from security threats is critical. By 2022, mobile data traffic is expected to reach 77.5 exabytes per month worldwide at a compound annual growth rate of 46%. This explosion of data increases the risk of attacks from unknown sources and is driving telco customers to look for new ways to detect threats, such as using machine learning techniques.
A signature-based pattern has been the primary technique used by many customers. In a signature based pattern, network traffic is investigated by comparing against repositories of signatures extracted from malicious objects. Although this technique works well for known threats, it is difficult to detect new attacks because no pattern or signature is available. In this blog, we walk through building a machine learning-based network anomaly detection solution by highlighting the following key components:
Generating synthetic data to simulate production volume using Dataflow and Pub/Sub.
Extracting features and real time prediction using Dataflow.
Training and normalizing data using BigQuery ML’s built-in k-means clustering model.
De-identifying sensitive data using Dataflow and Cloud DLP.
Generating synthetic NetFlow log using Dataflow and Pub/Sub
Let's start with synthetic data generation, which maps to the Ingest/Trigger section in figure 1. For illustrative purposes, we simulated NetFlow log by using an open source data generator pipeline.
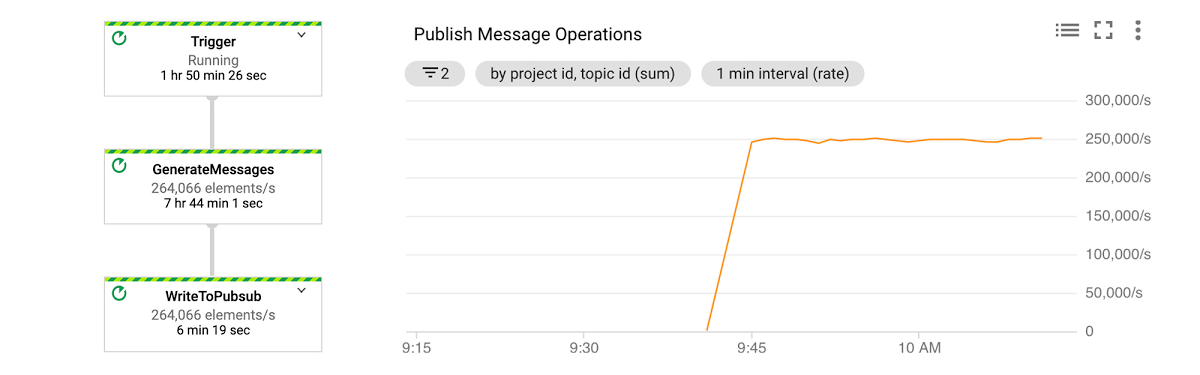
In figure 2, you can see that this pipeline of simulated data is publishing data at 250k elements/sec.
Extracting features and tokenizing sensitive data using Dataflow and Cloud DLP
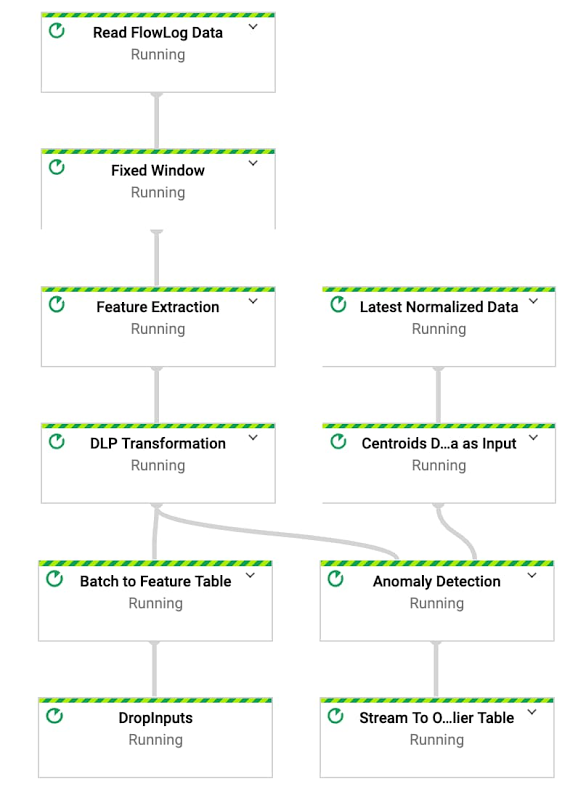
We have open sourced an anomaly detection pipeline that aggregates and ingests 150 GB of data in a 10-minute window. First, we find the subnet of the destination IP, dstSubnet. After that, to extract some basic features, we aggregate data by both destination subnets and subscriber ID. Using Apache Beam transforms, this pipeline first converts JSON messages to a Row type and then aggregates data using the schema. As you can see from the Feature Extraction Using Beam Schema Inferring snippet, you can extract sample features by using built-in Apache Beam Java SDK aggregation transforms, such as Min, Max and ApproximateUnique functions.
The subscriberId values in our dataset might contain PII, such as IMSI numbers. In order to avoid storing PII as plain text to BigQuery, we used Cloud DLP to de-identify IMSI numbers. We picked deterministic encryption where data can be de-identified (or tokenized) and re-identified (or de-tokenized) using the same CryptoKey. To minimize the frequency of calls to the Cloud DLP service and to fit within the limitations of DLP message size(0.5 MB), we built a microbatch approach by using Apache Beam’s state and timer API. This sample code shows how the request is buffered and emitted based on a batch size and an event time trigger. To meet concurrent requests for our data volume, we increased the default Cloud DLP API quota limit to 40,000 API calls per minute.
Train and normalize data using BigQuery ML
We then train and normalize data in BigQuery, as seen as the Store component in figure 1. To handle large volumes of daily data (20 TB), we used ingestion-time partitioned tables and clustering by the subscriberID and dstSubnet field. Storing data in a partitioned table allows us to quickly select training data using filters for days (e.g. 10 days) and a group of subscribers (e.g. users from organization X).
We used the k-means clustering algorithm in BigQuery ML to train a model and create clusters. Since BigQuery ML enables training models by using standard SQL, to automate overall model creation and training processes, we used stored procedures and scheduled queries. We were able to create a k-means clustering model in less than 15 minutes for a terabyte-scale dataset. After experimenting with multiple cluster sizes, our model evaluation suggested that we used four. Next, we normalized the data by finding a normalized distance for each cluster.
Realtime outlier detection using Dataflow
The final step in our journey is to detect outliers, which is step 4 in the reference architecture in figure 1. To detect outliers in real-time, we extended the same pipeline used for feature extraction. First, we feed the normalized data to the pipeline as a side input. Now that we have normalized our data available from the pipeline, we find the nearest centroid by calculating the distance between the centroid and input vector. Lastly, to find outliers, we calculate how far the input vector is from the nearest centroid. If the distance is three standard deviations above the mean, as indicated in this diagram, we output those data points as outliers in a BigQuery table.
To test if our model can successfully detect an anomaly, we manually published an outlier message. For the subscriber ID ‘000000000000000’, we used a higher number of transmission, 150000 bytes, and receiving, 40000 bytes, than the usual volumes.
We then query the outlier table in BigQuery and we can see that subscriber ID is stored in a de-identified format, as expected, because of the chosen Cloud DLP transformation. To retrieve our original data in a secure Pub/Sub subscription, we use this data re-identification pipeline. As shown in figure, our original outlier subscriber ID (00000000000000000) is successfully re-identified.
Insights applied
The insights identified in an advanced, real-time pipeline are only as good as the improvement they enable within an organization. To make these insights actionable, you can enable dashboards for data storytelling, alerts for exception-based management, and actions for process streamlining or automatic mitigation. For anomaly detection, the anomalies identified can be immediately available in Looker as dashboard visualizations or used to trigger an alert or action when an anomalous condition is met. In the case of anomaly detection, you can use an action to create a ticket in a ticketing system for additional investigation and tracking.
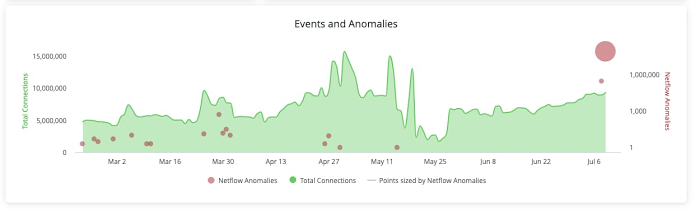
Summary
Real-time AI solutions have the biggest impact when approached with the end-goal in mind (How will this help us meet our business goals?) and the flexibility to adapt as needs change (How do we quickly evolve as our goals, learnings, and environment change?). Whether you are a security team looking to better identify the unknown or a retailer hoping to better spot positive buying trends, Google Cloud has the tools required to turn that business need into a solution.
In this blog, we showed you how you can build a secure, real-time anomaly detection solution using Dataflow, BigQuery ML and Cloud DLP. Although finding anomalies using well-defined probability distribution may not be completely accurate to solve adversarial use cases, it’s important to perform further analysis to confidently identify any security risks. If you’d like to give it a try, you can refer to this github repo for a reference implementation.

