Dataflow
Inteligencia de datos en tiempo real
Maximiza el potencial de tus datos en tiempo real. Dataflow es una plataforma de streaming totalmente gestionada que es fácil de usar y escalable para ayudar a agilizar la toma de decisiones y las experiencias de los clientes en tiempo real.
Los nuevos clientes reciben 300 USD en crédito gratis para utilizarlo en Dataflow.
Aspectos destacados de Dataflow
Aprovecha los datos en tiempo real para potenciar los casos prácticos de IA generativa y aprendizaje automático
Ofrece experiencias completas y personalizadas a tus clientes
Proceso de extracción, transformación y carga (ETL) en tiempo real e integración de datos en BigQuery

Características
Usa la IA y el aprendizaje automático en streaming para potenciar los modelos de IA generativa en tiempo real
Los datos en tiempo real permiten que los modelos de IA y aprendizaje automático cuenten con la información más reciente, lo que mejora la precisión de las predicciones. Dataflow ML simplifica el despliegue y la gestión de flujos de procesamiento de aprendizaje automático completos. Ofrecemos patrones listos para usarse con recomendaciones personalizadas, detección de fraudes, prevención de amenazas y mucho más. Crea IA en streaming con Vertex AI, los modelos de Gemini y los modelos de Gemma, ejecuta inferencias remotas y optimiza el tratamiento de datos con MLTransform. Mejora la eficiencia de las tareas de MLOps y de aprendizaje automático con la GPU de Dataflow y funciones ajustadas adecuadamente.
Habilita casos prácticos avanzados de streaming a escala empresarial
Dataflow es un servicio totalmente gestionado que utiliza el SDK de código abierto de Apache Beam para habilitar casos prácticos de streaming avanzados a escala empresarial. Ofrece múltiples funciones para estado y tiempo, transformaciones y conectores de E/S. Dataflow se puede escalar hasta 4000 trabajadores por tarea y procesa petabytes de datos de forma rutinaria. Incorpora un autoescalado que permite utilizar los recursos de forma óptima tanto en los flujos de procesamiento por lotes como en los de streaming.

Desplegar el tratamiento de datos multimodal en la IA generativa
Dataflow permite ingerir y transformar en paralelo datos multimodales, como imágenes, texto y audio. Aplica una extracción de funciones especializada para cada modalidad y, a continuación, fusiona estas funciones en una representación unificada. Esto fusionó los feeds de datos con modelos de IA generativa, lo que les permitió crear contenido nuevo a partir de diversos datos. Los equipos internos de Google utilizan Dataflow y FlumeJava para organizar y calcular predicciones de modelos para un gran grupo de datos de entrada disponibles sin requisitos de latencia.
Agiliza el tiempo de amortización con plantillas y cuadernos
Dataflow incluye herramientas para que puedas empezar a usarlo fácilmente. Las plantillas de Dataflow son modelos prediseñados para el procesamiento en streaming y por lotes, y están optimizadas para integrar los datos de CDC y BigQuery de manera eficiente. Crea flujos de procesamiento de forma iterativa con los frameworks más recientes de ciencia de datos desde cero gracias a los cuadernos de Vertex AI y despliégalos con el ejecutor de Dataflow.El creador de tareas de Dataflow es una interfaz de usuario visual para crear y ejecutar flujos de procesamiento de Dataflow en la consola de Google Cloud sin tener que escribir código.
Ahorra tiempo con herramientas inteligentes de diagnóstico y monitorización
Dataflow ofrece herramientas integrales de diagnóstico y monitorización. La detección de rezagados identifica automáticamente los cuellos de botella en el rendimiento, mientras que el muestreo de datos permite observar los datos en cada paso del flujo de procesamiento. Dataflow Insights te ofrece recomendaciones para mejorar las tareas. La interfaz de usuario de Dataflow ofrece completas herramientas de monitorización, como gráficos de tareas, detalles de ejecución, métricas, paneles de control de autoescalado y almacenamiento de registros. Dataflow también cuenta con una interfaz de usuario de supervisión de los costes de las tareas para que puedas estimar fácilmente los costes.
Gobernanza y seguridad integradas
Dataflow te ayuda a proteger tus datos de varias formas: mediante cifrado de datos en uso, que admite máquinas virtuales confidenciales. Claves de cifrado gestionadas por el cliente (CMEK). Integración de Controles de Servicio de VPC; desactivación de las IP públicas. Los registros de auditoría de Dataflow permiten a tu organización ver el uso de Dataflow y pueden responder a las preguntas "¿Quién hizo qué, dónde y cuándo?". para mejorar la gobernanza.
Cómo funciona
Dataflow es una plataforma totalmente gestionada para el tratamiento de datos por lotes y de streaming. Esta solución permite usar flujos de procesamiento de extracción, transformación y carga (ETL) escalables, analíticas de streaming en tiempo real, aprendizaje automático en tiempo real y transformaciones de datos complejas mediante el modelo unificado de Apache Beam. Y todo ello en la infraestructura de Google Cloud sin servidor.
Dataflow es una plataforma totalmente gestionada para el tratamiento de datos por lotes y de streaming. Esta solución permite usar flujos de procesamiento de extracción, transformación y carga (ETL) escalables, analíticas de streaming en tiempo real, aprendizaje automático en tiempo real y transformaciones de datos complejas mediante el modelo unificado de Apache Beam. Y todo ello en la infraestructura de Google Cloud sin servidor.

Analítica en tiempo real
Incorporar datos de streaming para analíticas en tiempo real y flujos de procesamiento operativos
Incorporar datos de streaming para analíticas en tiempo real y flujos de procesamiento operativos
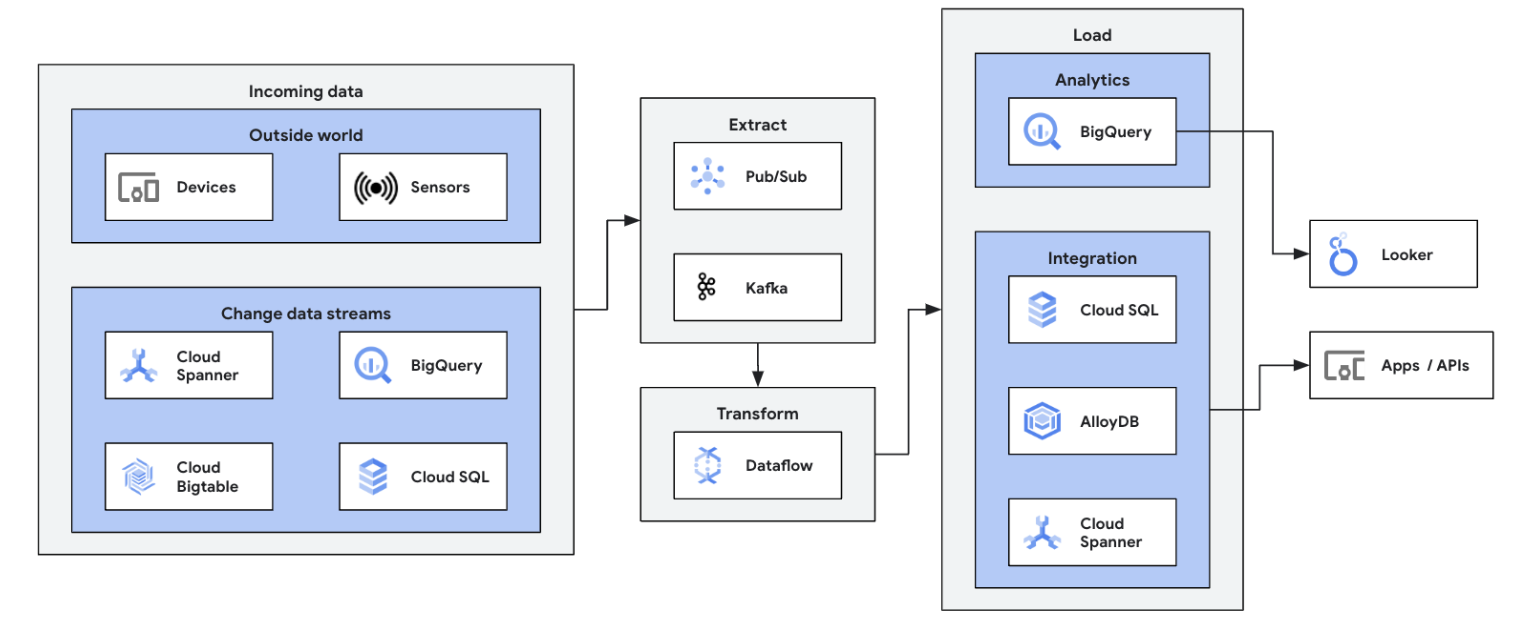
Inicia tu recorrido de flujo de datos integrando tus fuentes de datos de streaming (Pub/Sub, Kafka, eventos de CDC, flujo de clics de usuarios, registros y datos de sensores) en BigQuery, lagos de datos de Google Cloud Storage, Spanner, Bigtable, almacenes SQL, Splunk y Datadog, entre otros. Consulta las plantillas optimizadas de Dataflow para configurar tus flujos de procesamiento con solo unos clics y sin código. Añade una lógica personalizada a tus tareas de plantilla con el compilador de funciones definidas por el usuario integrado o crea flujos de procesamiento de extracción, transformación y carga (ETL) personalizados desde cero con toda la potencia de las transformaciones de Beam y el ecosistema de conectores de E/S. Dataflow también se usa habitualmente para invertir los datos procesados por extracción, transformación y carga (ETL) de BigQuery en almacenes de procesamiento de transacciones online (OLTP), para hacer búsquedas y servir anuncios a los usuarios finales rápidamente. Se trata de un patrón común para que Dataflow escriba datos de streaming en varias ubicaciones de almacenamiento.

Inicia tu primera tarea de Dataflow y completa nuestro curso autoguiado sobre conceptos básicos de Dataflow.
Tutoriales, guías de inicio rápido y experimentos
Incorporar datos de streaming para analíticas en tiempo real y flujos de procesamiento operativos
Incorporar datos de streaming para analíticas en tiempo real y flujos de procesamiento operativos
Inicia tu recorrido de flujo de datos integrando tus fuentes de datos de streaming (Pub/Sub, Kafka, eventos de CDC, flujo de clics de usuarios, registros y datos de sensores) en BigQuery, lagos de datos de Google Cloud Storage, Spanner, Bigtable, almacenes SQL, Splunk y Datadog, entre otros. Consulta las plantillas optimizadas de Dataflow para configurar tus flujos de procesamiento con solo unos clics y sin código. Añade una lógica personalizada a tus tareas de plantilla con el compilador de funciones definidas por el usuario integrado o crea flujos de procesamiento de extracción, transformación y carga (ETL) personalizados desde cero con toda la potencia de las transformaciones de Beam y el ecosistema de conectores de E/S. Dataflow también se usa habitualmente para invertir los datos procesados por extracción, transformación y carga (ETL) de BigQuery en almacenes de procesamiento de transacciones online (OLTP), para hacer búsquedas y servir anuncios a los usuarios finales rápidamente. Se trata de un patrón común para que Dataflow escriba datos de streaming en varias ubicaciones de almacenamiento.
Inicia tu primera tarea de Dataflow y completa nuestro curso autoguiado sobre conceptos básicos de Dataflow.
Proceso de extracción, transformación y carga (ETL) en tiempo real e integración de datos
Moderniza tu plataforma de datos con datos en tiempo real
Moderniza tu plataforma de datos con datos en tiempo real
Proceso de integración y proceso de extracción, transformación y carga (ETL) en tiempo real y escritura de datos de forma inmediata, lo que permite agilizar el análisis y la toma de decisiones. La arquitectura sin servidor y las funciones de streaming de Dataflow lo hacen perfecto para crear flujos de procesamiento de extracción, transformación y carga (ETL) en tiempo real. La capacidad de autoescalado de Dataflow asegura la eficiencia y la escalabilidad, mientras que la compatibilidad con varias fuentes de datos y destinos simplifica la integración.
Aprende los conceptos básicos con el procesamiento por lotes de Dataflow en este curso del Acelerador de conocimientos de Google Cloud.
Tutoriales, guías de inicio rápido y experimentos
Moderniza tu plataforma de datos con datos en tiempo real
Moderniza tu plataforma de datos con datos en tiempo real
Proceso de integración y proceso de extracción, transformación y carga (ETL) en tiempo real y escritura de datos de forma inmediata, lo que permite agilizar el análisis y la toma de decisiones. La arquitectura sin servidor y las funciones de streaming de Dataflow lo hacen perfecto para crear flujos de procesamiento de extracción, transformación y carga (ETL) en tiempo real. La capacidad de autoescalado de Dataflow asegura la eficiencia y la escalabilidad, mientras que la compatibilidad con varias fuentes de datos y destinos simplifica la integración.
Aprende los conceptos básicos con el procesamiento por lotes de Dataflow en este curso del Acelerador de conocimientos de Google Cloud.
Aprendizaje automático e IA generativa en tiempo real
Actúa en tiempo real con la IA y aprendizaje automático en streaming
Actúa en tiempo real con la IA y aprendizaje automático en streaming
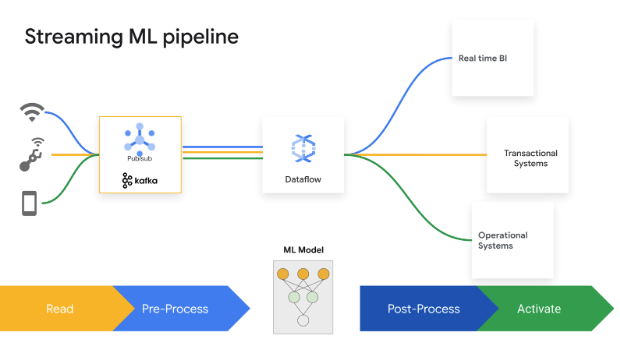
Tomar decisiones en cuestión de segundos genera valor empresarial. Gracias a la IA y el aprendizaje automático en streaming de Dataflow, los clientes pueden implementar predicciones e inferencias de baja latencia, personalización en tiempo real, detección de amenazas, prevención de fraudes y muchos más casos prácticos en los que la inteligencia en tiempo real importa. Preprocesa los datos con MLTransform, lo que te permitirá centrarte en transformar los datos sin tener que escribir código complejo ni gestionar bibliotecas subyacentes. Haz predicciones para tu modelo de IA generativa con RunInference.
Tutoriales, guías de inicio rápido y experimentos
Actúa en tiempo real con la IA y aprendizaje automático en streaming
Actúa en tiempo real con la IA y aprendizaje automático en streaming
Tomar decisiones en cuestión de segundos genera valor empresarial. Gracias a la IA y el aprendizaje automático en streaming de Dataflow, los clientes pueden implementar predicciones e inferencias de baja latencia, personalización en tiempo real, detección de amenazas, prevención de fraudes y muchos más casos prácticos en los que la inteligencia en tiempo real importa. Preprocesa los datos con MLTransform, lo que te permitirá centrarte en transformar los datos sin tener que escribir código complejo ni gestionar bibliotecas subyacentes. Haz predicciones para tu modelo de IA generativa con RunInference.
Inteligencia de marketing
Transforma tu estrategia de marketing con estadísticas en tiempo real
Transforma tu estrategia de marketing con estadísticas en tiempo real
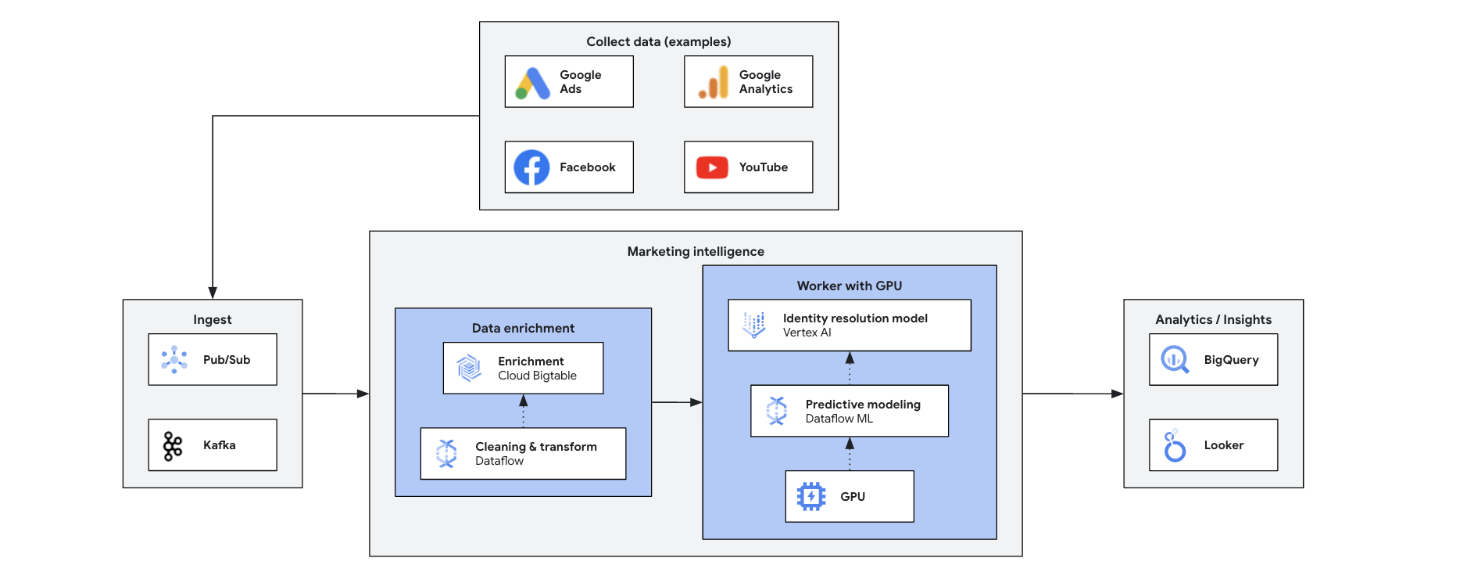
La inteligencia de marketing en tiempo real analiza los datos actuales del mercado, de los clientes y de la competencia para tomar decisiones rápidas y fundamentadas. Permite responder con rapidez a las tendencias, los comportamientos y las acciones de la competencia, lo que transforma el marketing. Entre sus ventajas se incluyen:
- Marketing omnicanal en tiempo real con ofertas personalizadas
- Mejor gestión de las relaciones con los clientes mediante interacciones personalizadas
- Optimización del marketing mix de forma ágil
- Segmentación de usuarios dinámica
- Inteligencia competitiva para ir un paso por delante
- Gestión proactiva de crisis en las redes sociales
Tutoriales, guías de inicio rápido y experimentos
Transforma tu estrategia de marketing con estadísticas en tiempo real
Transforma tu estrategia de marketing con estadísticas en tiempo real
La inteligencia de marketing en tiempo real analiza los datos actuales del mercado, de los clientes y de la competencia para tomar decisiones rápidas y fundamentadas. Permite responder con rapidez a las tendencias, los comportamientos y las acciones de la competencia, lo que transforma el marketing. Entre sus ventajas se incluyen:
- Marketing omnicanal en tiempo real con ofertas personalizadas
- Mejor gestión de las relaciones con los clientes mediante interacciones personalizadas
- Optimización del marketing mix de forma ágil
- Segmentación de usuarios dinámica
- Inteligencia competitiva para ir un paso por delante
- Gestión proactiva de crisis en las redes sociales
Analíticas de flujos de clics
Optimizar y personalizar las experiencias en la Web y en aplicaciones
Optimizar y personalizar las experiencias en la Web y en aplicaciones
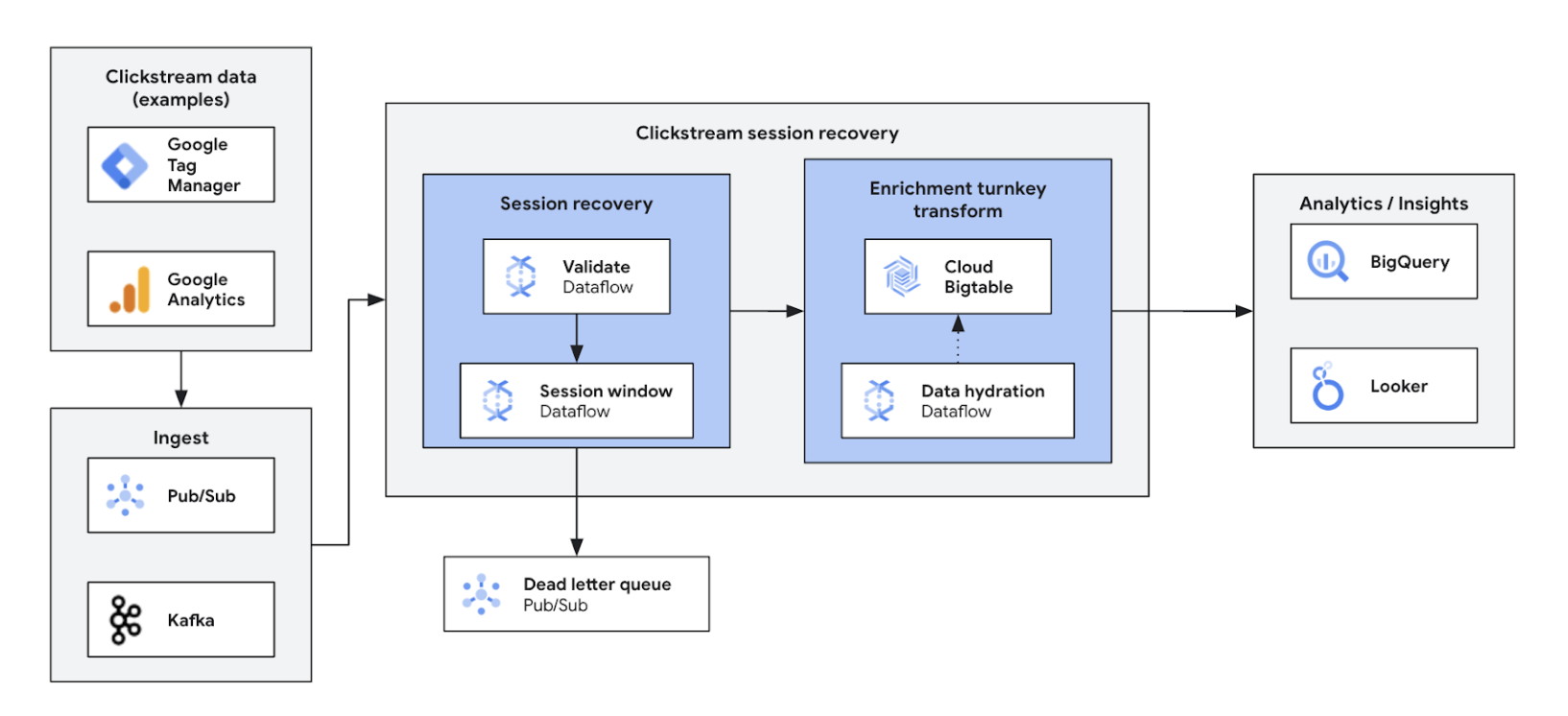
Las analíticas de flujos de clics en tiempo real permiten a las empresas analizar al instante las interacciones de los usuarios en los sitios web y las aplicaciones. De este modo, disfrutará de funciones de personalización en tiempo real, pruebas A/B y optimización del embudo de conversión, lo que se traduce en un aumento de la interacción, un desarrollo de productos más rápido, una reducción de la tasa de abandono y una asistencia mejorada con el producto. En última instancia, permite ofrecer una experiencia de usuario superior e impulsa el crecimiento del negocio gracias a un sistema de precios dinámico y recomendaciones personalizadas.
Tutoriales, guías de inicio rápido y experimentos
Optimizar y personalizar las experiencias en la Web y en aplicaciones
Optimizar y personalizar las experiencias en la Web y en aplicaciones
Las analíticas de flujos de clics en tiempo real permiten a las empresas analizar al instante las interacciones de los usuarios en los sitios web y las aplicaciones. De este modo, disfrutará de funciones de personalización en tiempo real, pruebas A/B y optimización del embudo de conversión, lo que se traduce en un aumento de la interacción, un desarrollo de productos más rápido, una reducción de la tasa de abandono y una asistencia mejorada con el producto. En última instancia, permite ofrecer una experiencia de usuario superior e impulsa el crecimiento del negocio gracias a un sistema de precios dinámico y recomendaciones personalizadas.
Réplica de registros y analíticas en tiempo real
Gestión y analíticas centralizadas de registros
Gestión y analíticas centralizadas de registros
Los registros de Google Cloud se pueden replicar en plataformas de terceros como Splunk mediante Dataflow para procesar y analizar registros casi en tiempo real. Esta solución ofrece funciones centralizadas de gestión de registros, cumplimiento, auditoría y analíticas, a la vez que reduce los costes y mejora el rendimiento.
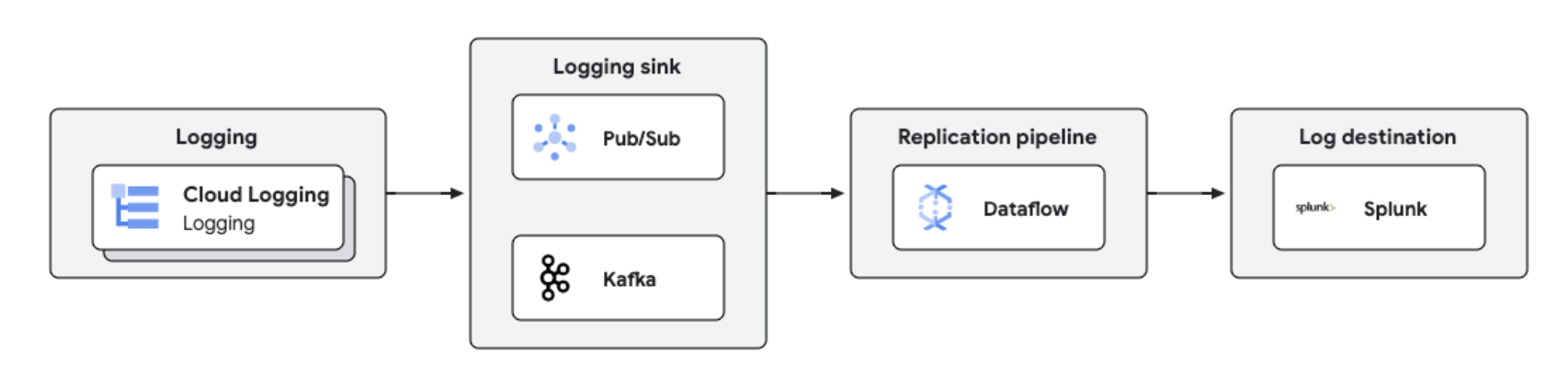
Tutoriales, guías de inicio rápido y experimentos
Gestión y analíticas centralizadas de registros
Gestión y analíticas centralizadas de registros
Los registros de Google Cloud se pueden replicar en plataformas de terceros como Splunk mediante Dataflow para procesar y analizar registros casi en tiempo real. Esta solución ofrece funciones centralizadas de gestión de registros, cumplimiento, auditoría y analíticas, a la vez que reduce los costes y mejora el rendimiento.
Precios
| Cómo funcionan los precios de Dataflow | Descubre el modelo de facturación y de recursos de Dataflow. | |
|---|---|---|
| Servicios y uso | Descripción | Precios |
Recursos de computación de Dataflow | La facturación de Dataflow para los recursos de computación incluye lo siguiente: | Más información en nuestra página de precios detallada |
Otros recursos de Dataflow | Otros recursos de Dataflow en los que se facturan todas las tareas incluyen discos persistentes, GPUs y resúmenes. | Más información en nuestra página de precios detallada |
Descuentos por compromiso de uso (CUDs) de Dataflow | Los CUDs de Dataflow ofrecen dos niveles de descuentos, según el periodo de compromiso:
| |
Más información sobre los precios de Dataflow Ver toda la información sobre los precios.
Cómo funcionan los precios de Dataflow
Descubre el modelo de facturación y de recursos de Dataflow.
Recursos de computación de Dataflow
La facturación de Dataflow para los recursos de computación incluye lo siguiente:
Más información en nuestra página de precios detallada
Otros recursos de Dataflow
Otros recursos de Dataflow en los que se facturan todas las tareas incluyen discos persistentes, GPUs y resúmenes.
Más información en nuestra página de precios detallada
Descuentos por compromiso de uso (CUDs) de Dataflow
Los CUDs de Dataflow ofrecen dos niveles de descuentos, según el periodo de compromiso:
- Un CUD de 1 año te da un 20 % de descuento sobre la tarifa bajo demanda
- Un CUD de 3 años te da un 40 % de descuento sobre la tarifa bajo demanda
Más información sobre los precios de Dataflow Ver toda la información sobre los precios.
Caso de negocio
Descubre por qué los principales clientes eligen Dataflow
Namitha Vijaya Kumar, propietaria de producto de Google Cloud SRE de ANZ Bank
"Dataflow nos ayuda tanto a procesar por lotes como en tiempo real, lo que asegura que los datos se mantengan en el momento oportuno en los data lakes empresariales. Esto, a su vez, contribuye a que los datos se usen posteriormente para el análisis, la toma de decisiones y la entrega de notificaciones en tiempo real a nuestros clientes minoristas".
Contenido relacionado
Google ha recibido el reconocimiento por parte de los clientes como la elección del cliente en lo que respecta al procesamiento de streaming de eventos
Descargar el informe
Aprovechar el potencial del aprendizaje automático en el mundo de los datos de streaming con Spotify
Ver vídeo
Yahoo compara Dataflow y Apache Flink autogestionado en dos casos prácticos de streaming
Leer el blog
Ventajas de Dataflow
Streaming de aprendizaje automático sin complicaciones
Funciones básicas para trasladar el streaming a la inteligencia artificial y al aprendizaje automático: RunInference para la inferencia, MLTransform para el preprocesamiento del entrenamiento de modelos, el enriquecimiento de las búsquedas de Feature Store y la compatibilidad con GPUs dinámicas reducen la labor manual y sin desperdiciar gasto para los recursos de GPU limitados.
Precio y rendimiento óptimo con herramientas potentes
Dataflow ofrece streaming rentable con optimización automatizada para maximizar el rendimiento y el uso de recursos. Se escala sin esfuerzo para gestionar cualquier carga de trabajo y cuenta con funciones de autorreparación basadas en IA. Dispone de herramientas sólidas que facilitan las operaciones y la comprensión.
Abierto, portátil y extensible
Dataflow se ha diseñado para Apache Beam sobre código abierto con compatibilidad unificada por lotes y en streaming, de modo que permite la portabilidad de tus cargas de trabajo entre nubes, entornos on‐premise o a dispositivos perimetrales.
Partners e integración




Partners de Dataflow
Algunos Google Cloud Partners han desarrollado integraciones con Dataflow para ejecutar tareas potentes de tratamiento de datos de forma rápida y sencilla, independientemente de su tamaño. Consulta todos los partners para iniciar tu recorrido de streaming hoy mismo.











