Cloud Data Fusion-Datenherkunft
Mit Cloud Data Fusion-Datenherkunft können Sie Folgendes tun:
Ursache für fehlerhafte Datenereignisse ermitteln
Führen Sie eine Wirkungsanalyse durch, bevor Sie Daten ändern.
Wir empfehlen, die Integration der Asset-Abstammung in Dataplex Universal Catalog zu verwenden. Weitere Informationen finden Sie unter Lineage in Dataplex Universal Catalog ansehen.
Sie können die Herkunft auch auf Dataset- und Feld-Ebene im Cloud Data Fusion Studio mit der Option Metadaten ansehen. Dort wird die Herkunft für einen ausgewählten Zeitraum angezeigt.
Die Herkunft auf Dataset-Ebene zeigt die Beziehung zwischen Datasets und Pipelines.
Die Zeilenebene auf Feldebene zeigt die Vorgänge, die für eine Reihe von Feldern im Quell-Dataset ausgeführt wurden, um einen anderen Satz von Feldern im Ziel-Dataset zu erzeugen.
Wenn Sie ab Cloud Data Fusion 6.9.2.4 die Datenherkunft in Cloud Data Fusion nicht erfassen, empfehlen wir, die Ausgabe der Datenherkunft auf Feldebene in Ihrer Instanz mit der Methode patch zu deaktivieren:
curl -X PATCH -H 'Content-Type: application/json' -H "Authorization: Bearer
$(gcloud auth print-access-token)"
'https://datafusion.googleapis.com/v1beta1/projects/PROJECT_ID/locations/REGION/instances/INSTANCE_ID?updateMask=options'
-d '{ "options": { "metadata.messaging.field.lineage.emission.enabled": "false" } }'
Ersetzen Sie Folgendes:
PROJECT_ID: die Google Cloud Projekt-IDREGION: Der Standort des Google Cloud ProjektsINSTANCE_ID: Die Cloud Data Fusion-Instanz-ID.
Anleitungsszenario
In dieser Anleitung arbeiten Sie mit zwei Pipelines:
Die
Shipment Data Cleansing-Pipeline liest Rohdaten für die Sendung aus einem kleinen Beispiel-Dataset und wendet Transformationen an, um die Daten zu bereinigen.Die Pipeline
Delayed Shipments USAliest dann die bereinigten Lieferungsdaten, analysiert sie und findet Lieferungen innerhalb der USA, die um mehr als einen Schwellenwert verzögert wurden.
Diese Anleitungspipelines zeigen ein typisches Szenario, in dem Rohdaten bereinigt und dann zur nachgelagerten Verarbeitung gesendet werden. Dieser Datentrail von den Rohdaten über die bereinigten Lieferungsdaten bis hin zur Ausgabe Analysierter Daten kann mit der Herkunftsfunktion von Cloud Data Fusion untersucht werden.
Ziele
- Herkunft von Daten durch Ausführen von Beispielpipelines nachvollziehen
- Herkunft auf Dataset- und Feldebene erkunden
- Informationen zur Übergabe von Handshakeinformationen aus der vorgelagerten Pipeline an die nachgelagerte Pipeline
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Cloud Data Fusion
- Cloud Storage
- BigQuery
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, Dataproc, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Erstellen Sie eine Cloud Data Fusion-Instanz.
- Klicken Sie auf die folgenden Links, um diese kleinen Beispiel-Datasets auf Ihren lokalen Computer herunterzuladen:
Cloud Data Fusion-UI öffnen
Bei Verwendung von Cloud Data Fusion verwenden Sie sowohl die Google Cloud Console als auch die separate Cloud Data Fusion-UI. In der Google Cloud Console können Sie ein Google Cloud Console-Projekt sowie Cloud Data Fusion-Instanzen erstellen und löschen. In der Cloud Data Fusion-Benutzeroberfläche können Sie die verschiedenen Seiten wie Lineage verwenden, um auf Cloud Data Fusion-Features zuzugreifen.
Öffnen Sie in der Google Cloud Console die Seite Instanzen.
Klicken Sie in der Spalte Aktionen für die Instanz auf den Link Instanz aufrufen. Die Benutzeroberfläche von Cloud Data Fusion wird in einem neuen Browsertab geöffnet.
Klicken Sie im Bereich Integrieren auf Studio, um die Cloud Data Fusion-Seite Studio zu öffnen.
Pipelines bereitstellen und ausführen
Importieren Sie die Rohlieferungsdaten. Klicken Sie auf der Seite Studio auf Importieren oder auf + > Pipeline > Importieren und wählen Sie dann die Shipment Data Cleansing-Pipeline aus, die Sie unter Vorbereitung heruntergeladen haben, und importieren Sie sie.
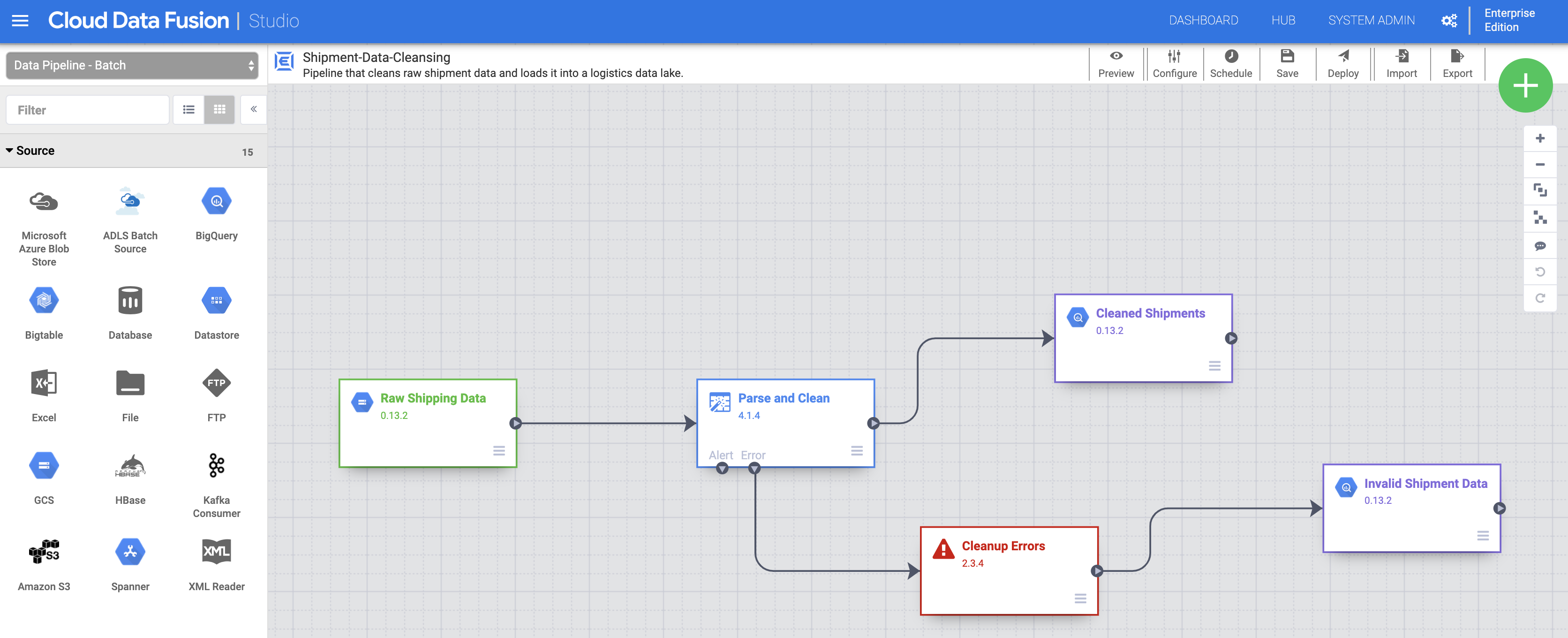
Stellen Sie die Pipeline bereit. Klicken Sie oben rechts auf der Seite Studio auf „Bereitstellen“. Nach der Bereitstellung wird die Seite Pipeline geöffnet.
Pipeline ausführen. Klicken Sie oben in der Mitte der Seite Pipeline auf „Ausführen“.
Importieren und stellen Sie die Daten und die Pipeline „Delayed Shipments“ ein. Wenn der Status der Bereinigung der Versanddaten Erfolgreich lautet, führen Sie die oben genannten Schritte für die Daten aus, die Sie unter Vorbereitung heruntergeladen haben. Kehren Sie zur Seite Studio zurück, um die Daten zu importieren, und stellen Sie dann diese zweite Pipeline über die Seite Pipeline bereit. Fahren Sie nach Abschluss der zweiten Pipeline mit den verbleibenden Schritten fort.
Datasets erkennen
Sie müssen ein Dataset erst entdecken, bevor Sie sich mit der Herkunft vertraut machen. Wählen Sie im linken Navigationsbereich der Cloud Data Fusion-UI die Option Metadaten aus, um die Seite Metadaten der Metadatenseite zu öffnen. Da im Dataset „Shipping Data Cleaning Dataset“ der bereinigte Dataset Cleaned-Ships als Referenz-Dataset angegeben wurde, geben Sie shipment in das Suchfeld ein. Die Suchergebnisse enthalten dieses Dataset.
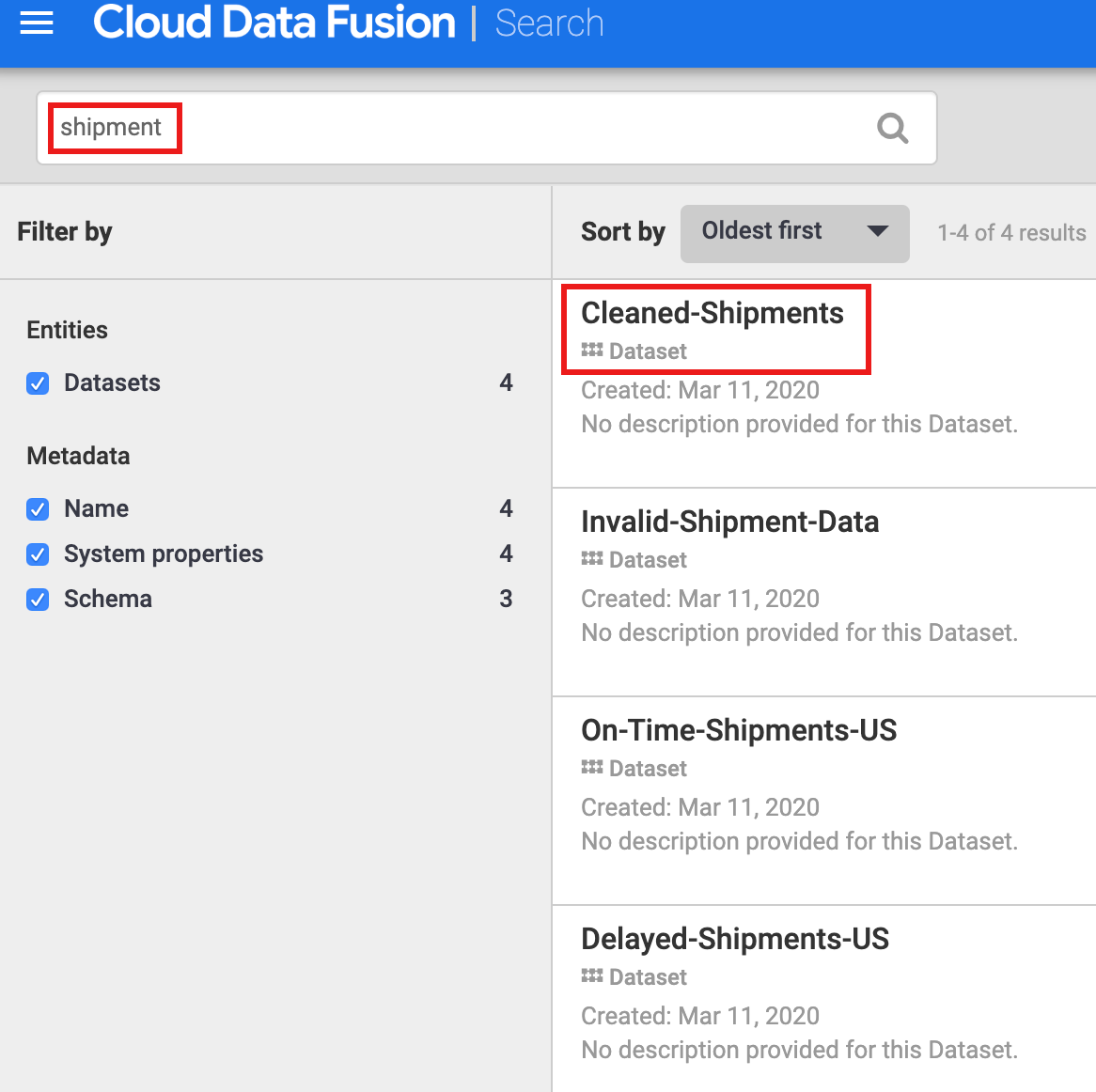
Datasets mithilfe von Tags erkennen
Eine Metadatensuche sucht Datasets, die von Cloud Data Fusion-Pipelines verbraucht, verarbeitet oder generiert wurden. Pipelines werden auf einem strukturierten Framework ausgeführt, das technische und Betriebsmetadaten generiert und erfasst. Die technischen Metadaten umfassen Dataset-Name, Typ, Schema, Felder, Erstellungszeit und Verarbeitungsinformationen. Diese technischen Informationen werden von den Metadaten- und Zeilenumbruchfunktionen von Cloud Data Fusion verwendet.
Cloud Data Fusion unterstützt auch die Annotation von Datasets mit Geschäftsmetadaten wie Tags und Schlüsselwert-Attribute, die als Suchkriterien verwendet werden können. So fügen Sie beispielsweise eine Geschäfts-Tag-Annotation zum Raw Shipping Data-Dataset hinzu und suchen nach einer solchen Annotation:
Klicken Sie auf der Schaltfläche Immobilien auf den Knoten Rohversanddaten Pipeline, um die SeiteCloud Storage-Attribute zu öffnen.
Klicken Sie auf Metadaten ansehen, um die Seite Suche zu öffnen.
Klicken Sie unter Geschäfts-Tags auf „+“, fügen Sie einen Tag-Namen ein (alphanumerische Zeichen und Unterstriche sind zulässig) und drücken Sie die Eingabetaste.

Erkunde die Herkunft
Herkunft auf Dataset-Ebene
Klicken Sie auf der Seite „Suche“ auf den Namen des Datasets „Cleaned-Shipments“ (aus Datasets erkennen) und dann auf den Tab „Herkunft“. Die Herkunftsdiagramm zeigt, dass dieses Dataset von der Pipeline "Shipments-Data-Cleansing" generiert wurde, die das Dataset "Raw_Shipping_Data" verwendet hat.
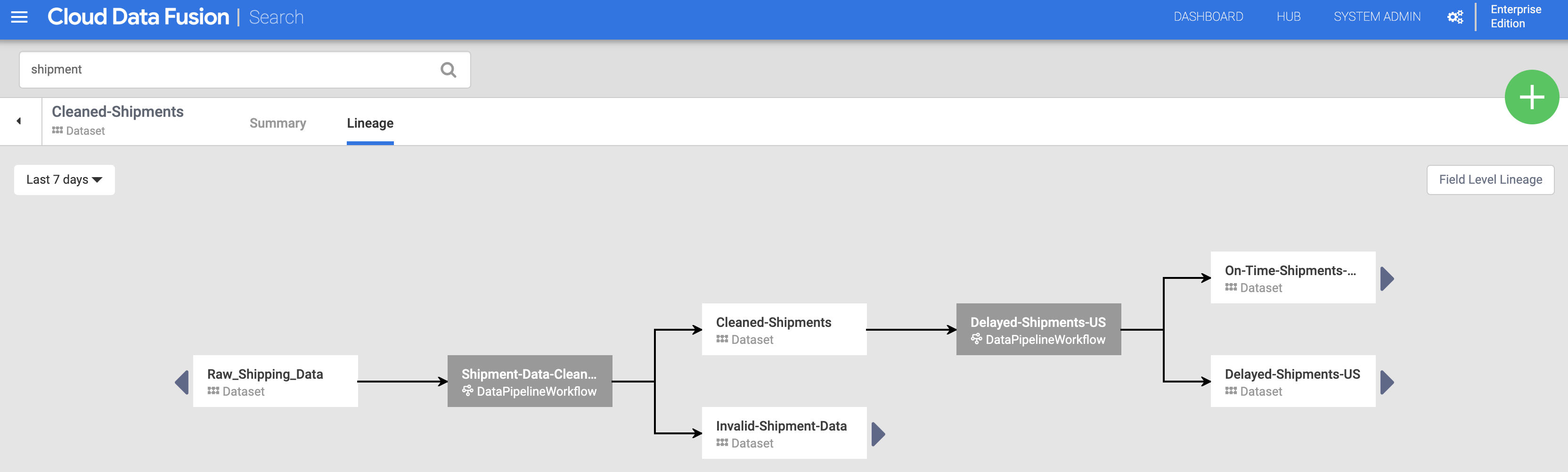
Mit dem Linkspfeil und dem Rechtspfeil können Sie durch die vorherigen oder nachfolgenden Dataset-Herkünfte zurück und vor navigieren. In diesem Beispiel zeigt die Diagramm die vollständige Herkunft für das Dataset "Cleaned-Shipments".
Herkunft der Felder
Die Herkunft der Felder in Cloud Data Fusion zeigt die Beziehung zwischen den Feldern eines Datasets und den Transformationen, die für eine Gruppe von Feldern durchgeführt wurden, um eine andere Gruppe von Feldern zu erzeugen. Wie die Zeilenvorschub auf Dataset-Ebene ist die Herkunft der Felder zeitgebunden und die Ergebnisse ändern sich mit der Zeit.
Fahren Sie mit dem Schritt Herkunft auf Dataset-Ebene fort und klicken Sie im oberen rechten Bereich des Cleaned Shipments-Herkunftsdiagramms für die Dataset-Ebene auf die Schaltfläche "Herkunft auf Feldebene", um das Herkunftsdiagramm auf Feldebene anzuzeigen.
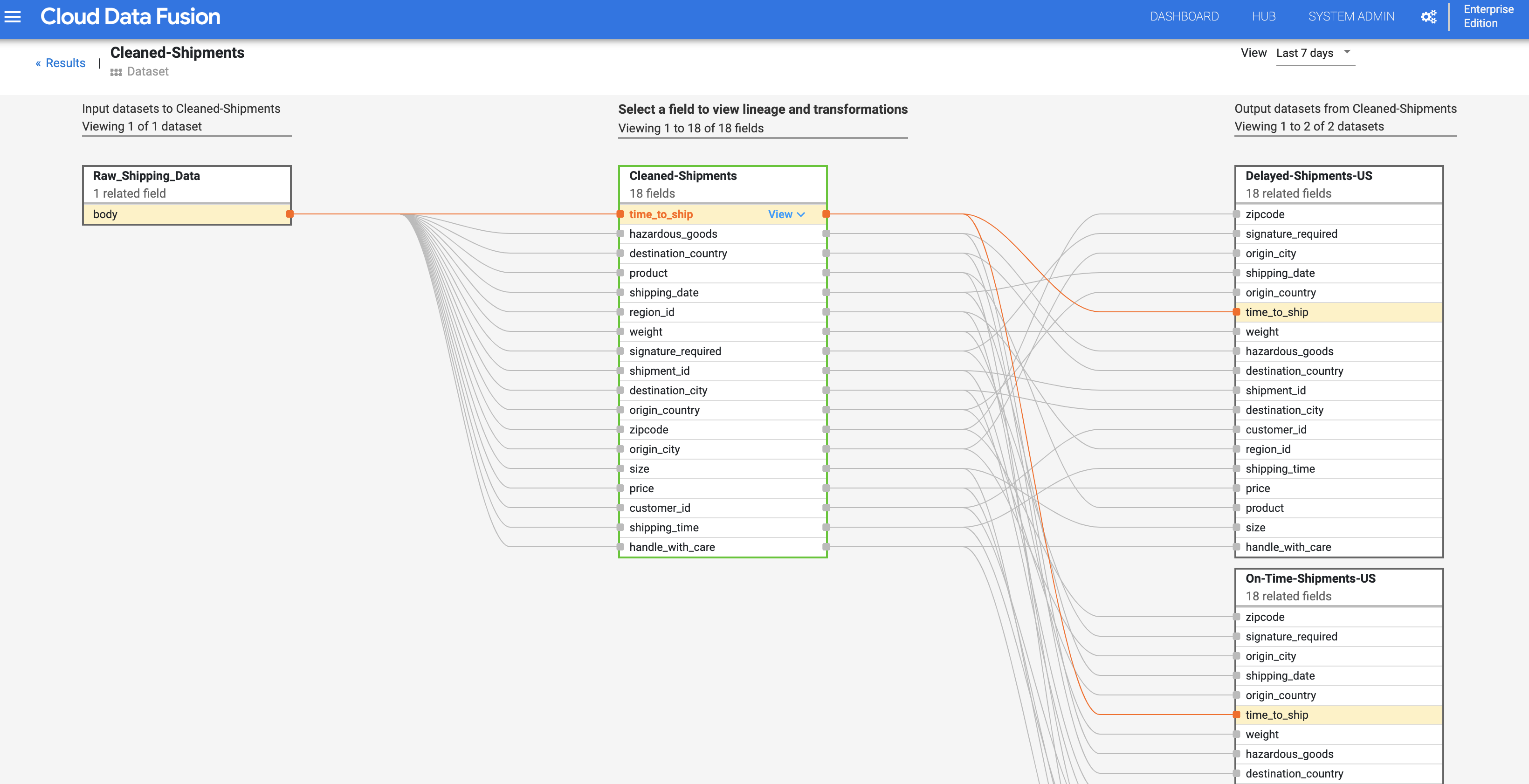
Das Liniendiagramm auf Feldebene zeigt die Verbindungen zwischen Feldern. Sie können ein Feld auswählen, um die Herkunft anzuzeigen. Wählen Sie Anzeigen > Feld anpinnen aus, um nur die Herkunft dieses Felds anzuzeigen.
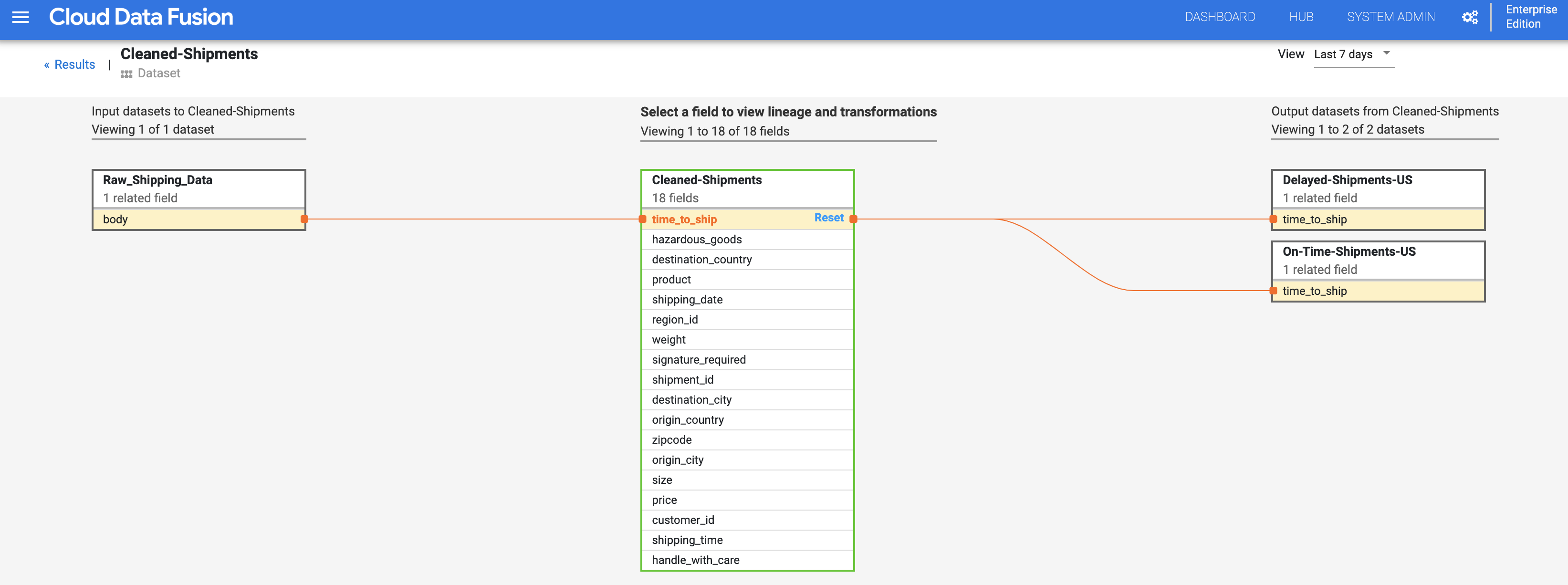
Wählen Sie Ansicht > Wirkung anzeigen aus, um eine Wirkungsanalyse durchzuführen.
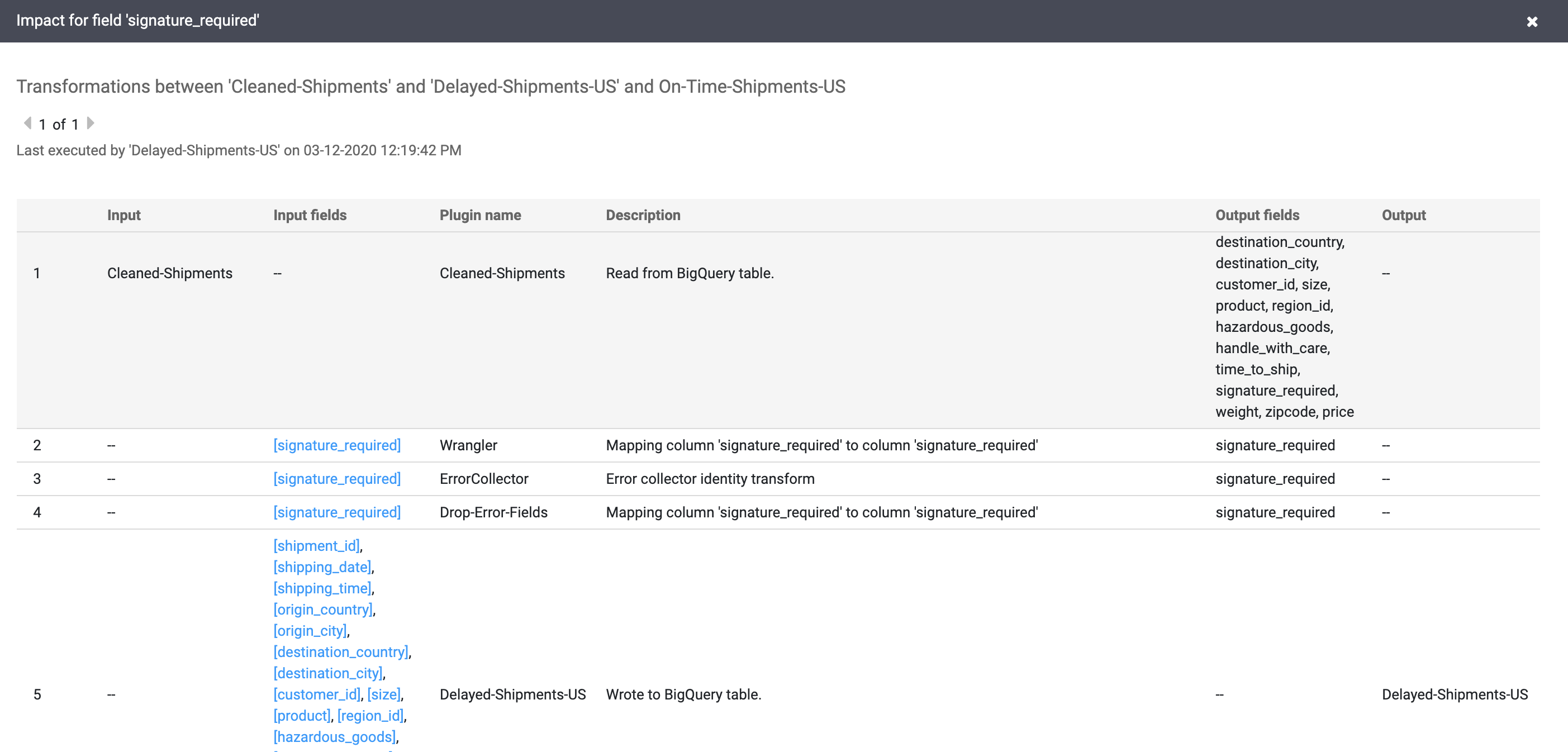
Die Ursachen- und Wirkungslinks zeigen die Transformationen auf beiden Seiten eines Felds in einem für Menschen lesbaren Verzeichnis. Diese Informationen können für die Berichterstellung und Governance wichtig sein.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Nachdem Sie diese Anleitung abgeschlossen haben, bereinigen Sie die inGoogle Cloud erstellten Ressourcen, damit sie keine kostenpflichtigen Kontingente verbrauchen. In den folgenden Abschnitten erfahren Sie, wie Sie diese Ressourcen löschen oder deaktivieren.
Anleitungs-Dataset löschen
In dieser Anleitung wird ein logistics_demo-Dataset mit mehreren Tabellen in Ihrem Projekt erstellt.
Sie können das Dataset über die BigQuery-Web-UI in der Google Cloud Console löschen.
Löschen Sie die Cloud Data Fusion-Instanz.
Folgen Sie der Anleitung zum Löschen Ihrer Cloud Data Fusion-Instanz.
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten durch Löschen des für die Anleitung erstellten Projekts.
So löschen Sie das Projekt:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Anleitungen lesen
- Weitere Anleitung durcharbeiten