このページでは、SAP Landscape Transformation(SLT)を使用して、SAP アプリケーションから Google Cloud へのデータのリアルタイム レプリケーションを有効にする方法について説明します。コンテンツは、Cloud Data Fusion Hub で利用可能な SAP SLT Replication プラグインと SAP SLT No RFC Replication プラグインに適用されます。SAP ソースシステム、SLT、Cloud Storage、Cloud Data Fusion で次のことを行う構成を示します。
- SAP SLT を使用して、SAP メタデータとテーブルデータを Google Cloud に push する。 Google Cloud
- Cloud Storage バケットからデータを読み取る Cloud Data Fusion レプリケーション ジョブを作成する。
SAP SLT Replication によって、SAP ソースから BigQuery に継続的かつリアルタイムにデータを複製できます。SAP システムからのデータ移行を、コーディングすることなく構成して実行できます。
Cloud Data Fusion の SLT レプリケーション プロセスは次のとおりです。
- データはSAP Source System から生成されます。
- SLT はデータを追跡して読み取り、Cloud Storage にプッシュします。
- Cloud Data Fusion は、ストレージ バケットからデータを取得し、BigQuery に書き込みます。
Google Cloudでホストされている SAP システムなど、サポートされている SAP システムからデータを転送できます。
詳細については、 Google Cloudでの SAP の概要とサポートの詳細をご覧ください。
始める前に
このプラグインを使用するには、次の分野でのドメインに関する知識が必要です。
- Cloud Data Fusion でのパイプラインのビルド。
- IAM によるアクセス管理
- SAP Cloud とオンプレミスのエンタープライズ リソース プランニング(ERP)システムの構成
構成を実行する管理者とユーザー
このページのタスクは、Google Cloud または SAP システムで次のロールを持つユーザーが行います。
| ユーザーの種類 | 説明 |
|---|---|
| Google Cloud 管理者 | このロールを割り当てられたユーザーは、Google Cloud アカウントの管理者です。 |
| Cloud Data Fusion ユーザー | このロールを割り当てられているユーザーは、データ パイプラインを設計して実行することを承認されています。少なくとも、Cloud Data Fusion 閲覧者(roles/datafusion.viewer)のロールが付与されます。ロールベースのアクセス制御を使用している場合は、追加のロールが必要になることがあります。 |
| SAP 管理者 | このロールを割り当てられたユーザーは、SAP システムの管理者です。SAP サービスサイトからソフトウェアをダウンロードするためのアクセス権を付与されています。これは IAM のロールではありません。 |
| SAP ユーザー | このロールを割り当てられているユーザーは、SAP システムに接続することを承認されています。 これは IAM のロールではありません。 |
サポートされているレプリケーション オペレーション
SAP SLT レプリケーション プラグインは、次のオペレーションをサポートしています。
データ モデリング: このプラグインでは、すべてのデータ モデリング オペレーション(レコード insert、delete、update)がサポートされています。
データ定義: SAP Note 2055599(表示には SAP サポート ログインが必要)で説明しているように、どのソースシステム テーブル構造の変更が、自動的に SLT によって複製されるかに関する制限があります。一部のデータ定義オペレーションはプラグインでサポートされていません(手動で伝播する必要があります)。
- サポート対象:
- 非キーフィールドを追加する(SE11 で変更を加えた後、SE14 を使用してテーブルを有効にする)
- サポート対象外:
- キーフィールドを追加/削除
- 非キーフィールドを削除する
- データ型を変更
SAP の要件
SAP システムでは、次の項目が必要です。
- ソース SAP システム(組み込み)に、または専用の SLT ハブシステムとして、SLT サーバー バージョン 2011 SP17 以降がインストールされている。
- ソース SAP システムは、DMIS 2011 SP17 以降(例: DMIS 2018、DMIS 2020)をサポートする SAP ECC または SAP S/4HANA です。
- SAP ユーザー インターフェース アドオンは、SAP NetWeaver バージョンと互換性がある必要があります。
サポート パッケージが
/UI2/CL_JSONクラスPL 12以降をサポートしている。それ以外の場合は、/UI2/CL_JSONクラスcorrections用の最新の SAP Note を、ユーザー インターフェース アドオン バージョン(PL12用の SAP Note 2798102 など)に従って実装します。次のセキュリティが適用されている。
Cloud Data Fusion の要件
- Cloud Data Fusion インスタンス、バージョン 6.4.0 以降の任意のエディションが必要です。
- Cloud Data Fusion インスタンスに割り当てられたサービス アカウントに必要なロールが付与されます(サービス アカウントのユーザーの権限の付与をご覧ください)。
- プライベート Cloud Data Fusion インスタンスの場合、VPC ピアリングが必要です。
Google Cloud の要件
- プロジェクトで Cloud Storage API を有効にします。 Google Cloud
- Cloud Data Fusion ユーザーに、Cloud Storage バケットにフォルダを作成する権限を付与する必要があります(Cloud Storage の IAM ロールをご覧ください)。
- 省略可: 組織で必要に応じて保持ポリシーを設定します。
Storage バケットを作成する
SLT レプリケーション ジョブを作成する前に、Cloud Storage バケットを作成します。 このジョブは、データをバケットに転送し、ステージング バケットを 5 分ごとに更新します。ジョブを実行すると、Cloud Data Fusion はストレージ バケット内のデータを読み取り、BigQuery に書き込みます。
SLT が Google Cloudにインストールされている場合
SLT サーバーには、作成したバケット内の Cloud Storage オブジェクトを作成、変更する権限が必要です。
少なくとも、サービス アカウントに次のロールを付与します。
- サービス アカウント トークン作成者(
roles/iam.serviceAccountTokenCreator) - Service Usage ユーザー(
roles/serviceusage.serviceUsageConsumer) - Storage オブジェクト管理者(
roles/storage.objectAdmin)
SLT が Google Cloudにインストールされていない場合
SAP VM とGoogle Cloud の間に Cloud VPN または Cloud Interconnect をインストールして、内部メタデータ エンドポイントへの接続を許可します(オンプレミス ホスト用の限定公開の Google アクセスの構成をご覧ください)。
内部メタデータをマッピングできない場合:
SLT が実行されているインフラストラクチャのオペレーティング システムに基づいて Google Cloud CLI をインストールします。
Cloud Storage が有効になっているプロジェクトでサービス アカウントを作成します。 Google Cloud
SLT オペレーティング システムで、サービス アカウントを使用して Google Cloud へのアクセスを承認します。
サービス アカウントの API キーを作成し、Cloud Storage 関連のスコープを承認します。
CLI を使用して、先ほどインストールした gcloud CLI に API キーをインポートします。
アクセス トークンを出力する gcloud CLI コマンドを有効にするには、SLT システムのトランザクション SM69 ツールで SAP オペレーティング システム コマンドを構成します。
アクセス トークンを出力する
SAP 管理者は、 Google Cloudからアクセス トークンを取得するオペレーティング システム コマンド SM69 を構成します。
アクセス トークンを出力するスクリプトを作成し、このスクリプトを SAP LT Replication Server ホストからユーザー <sid>adm として呼び出すように SAP オペレーティング システム コマンドを構成します。
Linux
OS コマンドを作成するには:
SAP LT Replication Server ホストで、
<sid>admがアクセスできるディレクトリに、次の行を含む bash スクリプトを作成します。PATH_TO_GCLOUD_CLI/bin/gcloud auth print-access-token SERVICE_ACCOUNT_NAMESAP ユーザー インターフェースを使用して、外部 OS コマンドを作成します。
- トランザクション
SM69を入力します。 - [作成] をクリックします。
- [外部コマンド] パネルの [コマンド] セクションで、コマンドの名前を入力します(例:
ZGOOGLE_CDF_TOKEN)。 [定義] セクションで次の操作を行います。
- [オペレーティング システム コマンド] フィールドに、スクリプト ファイルの拡張子として「
sh」と入力します。 [オペレーティング システム コマンドのパラメータ] フィールドに、次のように入力します。
/PATH_TO_SCRIPT/FILE_NAME.sh
- [オペレーティング システム コマンド] フィールドに、スクリプト ファイルの拡張子として「
[保存] をクリックします。
スクリプトをテストするには、[実行] をクリックします。
もう一度 [Execute] をクリックします。
Google Cloud トークンが返され、SAP ユーザー インターフェース パネルの下部に表示されます。
- トランザクション
Windows
SAP ユーザー インターフェースを使用して、外部オペレーティング システムのコマンドを作成します。
- トランザクション
SM69を入力します。 - [作成] をクリックします。
- [外部コマンド] パネルの [コマンド] セクションで、コマンドの名前を入力します(例:
ZGOOGLE_CDF_TOKEN)。 [定義] セクションで次の操作を行います。
- [オペレーティング システム コマンド] フィールドに、「
cmd /c」と入力します。 [オペレーティング システム コマンドのパラメータ] フィールドに、次のように入力します。
gcloud auth print-access-token SERVICE_ACCOUNT_NAME
- [オペレーティング システム コマンド] フィールドに、「
[保存] をクリックします。
スクリプトをテストするには、[実行] をクリックします。
もう一度 [Execute] をクリックします。
Google Cloud トークンが返され、SAP ユーザー インターフェース パネルの下部に表示されます。
SLT の要件
SLT コネクタは、次の設定が必要です。
- このコネクタは、SAP ECC NW 7.02、DMIS 2011 SP17 以降をサポートしています。
- SLT と Cloud Storage システムの間の RFC 接続またはデータベース接続を構成します。
- SSL 証明書を設定します。
- Google Trust Services リポジトリから、次の CA 証明書をダウンロードします。
- GTS Root R1
- GTS CA 1C3
- SAP ユーザー インターフェースで、
STRUSTトランザクションを使用して、ルート証明書と下位証明書の両方をSSL Client (Standard) PSEフォルダにインポートします。
- Google Trust Services リポジトリから、次の CA 証明書をダウンロードします。
- Internet Communication Manager(ICM)を HTTPS 用に設定する必要があります。SAP SLT システムで HTTP ポートと HTTPS ポートが維持され、有効になっていることを確認してください。これは、トランザクション コード
SMICM > Servicesで確認できます。 - SAP SLT システムがホストされている VM の API へのアクセスを有効にします。 Google Cloud これにより、公共のインターネットを経由してルーティングせずに、Google Cloud サービス間のプライベート通信が可能になります。
- ネットワークが、SAP インフラストラクチャと Cloud Storage 間の必要なデータ転送量と速度をサポートできることを確認します。インストールが正常に完了するためには、Cloud VPN または Cloud Interconnect(またはその両方)をおすすめします。 ストリーミング API のスループットは、Cloud Storage プロジェクトに付与されたクライアントの割り当てによって異なります。
SLT レプリケーション サーバーを構成する
SAP ユーザーは次の手順を実行します。
次の手順では、SLT サーバーをソースシステムと Cloud Storage のバケットに接続し、ソースシステム、複製するデータテーブル、ターゲット ストレージ バケットを指定します。
Google ABAP SDK を構成する
データ レプリケーション用に SLT を構成するには(Cloud Data Fusion インスタンスごとに 1 回)、次の手順に沿って操作します。
SLT コネクタを構成するために、SAP-User が構成画面(SAP トランザクション
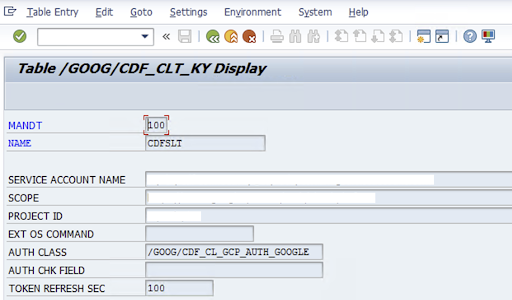
/GOOG/CDF_SETTINGS)に、Cloud Storage へのデータ転送のためのサービス アカウント キーに関する次の情報を入力します。 Google Cloud トランザクション SE16 を使用してテーブル /GOOG/CDF_CLT_KY で次のプロパティを構成し、このキーをメモします。- NAME: サービス アカウントキーの名前(例:
CDFSLT) - SERVICE ACCOUNT NAME: IAM サービス アカウント名
- SCOPE: サービス アカウントのスコープ。
- PROJECT ID: Google Cloud プロジェクトの ID
- 省略可: EXT OS コマンド: SLT が Google Cloudにインストールされていない場合にのみ、このフィールドを使用します。
AUTH クラス: OS コマンドがテーブル
/GOOG/CDF_CLT_KYで設定されている場合は、固定値(/GOOG/CDF_CL_GCP_AUTH)を使用します。TOKEN REFRESH SEC: 承認トークンの更新期間
- NAME: サービス アカウントキーの名前(例:
レプリケーション構成を作成する
トランザクション コード LTRC でレプリケーション構成を作成します。
- LTRC 構成に進む前に、SLT とソース SAP システム間の RFC 接続を確立してください。
- 1 つの SLT 構成に対して、レプリケーション用に複数の SAP テーブルが割り当てられている場合があります。
トランザクション コード
LTRCに移動し、[新しい構成] をクリックします。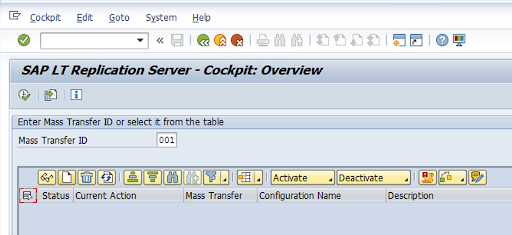
[構成名] と [説明] に入力し、[次へ] をクリックします。
SAP ソースシステムの RFC 接続を指定し、[次へ] をクリックします。
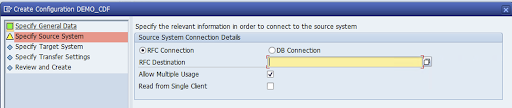
[ターゲットシステム接続の詳細] で [その他] を選択します。
[Scenario for RFC Communication] フィールドを開き、[SLT SDK] を選択して [次へ] をクリックします。
[転送設定の指定] ウィンドウに移動し、アプリケーション名(
ZGOOGLE_CDF)を入力します。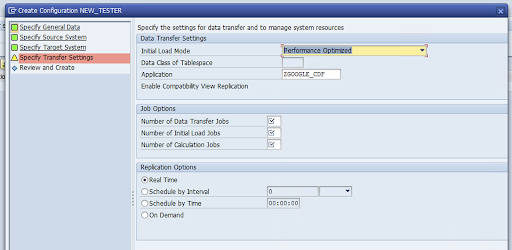
[Data Transfer ジョブの数]、[初期読み込みジョブの数]、[計算ジョブの数] を入力します。パフォーマンスの詳細については、SAP LT Replication Server パフォーマンス最適化ガイドをご覧ください。
[リアルタイム] > [次へ] をクリックします。
構成を確認して、[保存] をクリックします。以降の手順で [一括転送 ID] をメモします。
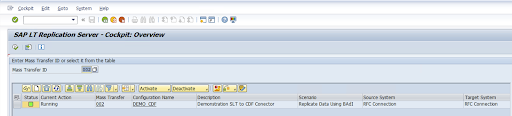
一括転送 ID と SAP テーブルの詳細を維持するには、SAP トランザクション
/GOOG/CDF_SETTINGSを実行します。[実行] をクリックするか、
F8を押します。行を追加アイコンをクリックして、新しいエントリを作成します。
[一括転送 ID]、[一括転送キー]、[GCP キー名]、[ターゲット GCS バケット] を入力します。[有効] チェックボックスをオンにして、変更を保存します。
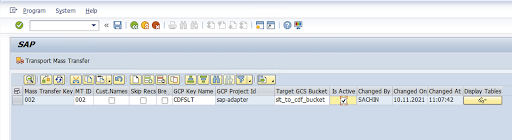
[構成名] 列で構成を選択し、[データ プロビジョニング] をクリックします。
省略可: テーブル名とフィールド名をカスタマイズします。
[カスタム名] をクリックして保存します。
[表示] をクリックします。
[行を追加] ボタンまたは [作成] ボタンをクリックして、新しいエントリを作成します。
BigQuery で使用する SAP テーブル名と外部テーブル名を入力し、変更を保存します。
[表示フィールド] 列の [表示] ボタンをクリックして、テーブル フィールドのマッピングを維持します。
提案されたマッピングが記載されたページが開きます。省略可: [一時フィールド名] と [フィールドの説明] を編集し、マッピングを保存します。
LTRC トランザクションに移動します。
[構成名] 列で値を選択し、[データ プロビジョニング] をクリックします。
[データベースのテーブル名] フィールドにテーブル名を入力し、レプリケーションのシナリオを選択します。
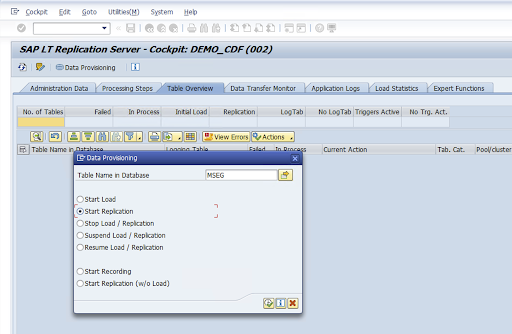
[実行] をクリックします。これにより、SLT SDK の実装がトリガーされ、Cloud Storage のターゲット バケットへのデータ転送が開始されます。
SAP トランスポート ファイルをインストールする
Cloud Data Fusion でレプリケーション ジョブを設計して実行するために、SAP コンポーネントが SAP トランスポート ファイルとして、zip ファイルにアーカイブされて配信されます。これは Cloud Data Fusion Hub でプラグインをデプロイするときにダウンロードできます。
SAP トランスポートをインストールするには、次の手順に沿って操作します。
ステップ 1: トランスポート リクエスト ファイルをアップロードする
- SAP インスタンスのオペレーティング システムにログインします。
- SAP トランザクション コード
AL11を使用して、DIR_TRANSフォルダのパスを取得します。通常、パスは/usr/sap/trans/です。 - cofile を
DIR_TRANS/cofilesフォルダにコピーします。 - データファイルを
DIR_TRANS/dataフォルダにコピーします。 - データと cofile の ユーザーとグループを
<sid>admとsapsysに設定します。
ステップ 2: トランスポート リクエスト ファイルをインポートする
SAP 管理者は、SAP 転送管理システムまたはオペレーティング システムを使用して、トランスポート リクエスト ファイルをインポートできます。
SAP トランスポート管理システム
- SAP 管理者として SAP システムにログインします。
- トランザクション STMS を入力します。
- [概要] > [インポート] をクリックします
- [キュー] 列で、現在の SID をダブルクリックします。
- [その他] > [その他のリクエスト] > [追加] をクリックします。
- トランスポート リクエスト ID を選択し、[続行] をクリックします。
- インポート キューでトランスポート リクエストを選択し、[リクエスト] > [インポート] をクリックします。
- クライアント番号を入力します。
[Options] タブで、[Overwrite Originals] と [Ignore Invalid Component Version] を選択します(選択可能な場合)。
(省略可)トランスポートを後で再インポートするには、[後でのインポートのためにトランスポート リクエストをキューに残す]と [トランスポート リクエストを再度インポートする] をクリックします。これは、SAP システムのアップグレードとバックアップの復元を行う際に有用です。
[続行] をクリックします。
SE80やPFCGなどのトランザクションを使用して、関数モジュールと承認ロールが正常にインポートされていることを確認します。
オペレーティング システム
- SAP 管理者として SAP システムにログインします。
リクエストをインポート バッファに追加します。
tp addtobuffer TRANSPORT_REQUEST_ID SID例:
tp addtobuffer IB1K903958 DD1トランスポート リクエストをインポートします。
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238NNNは、クライアント番号に置き換えます(例:tp import IB1K903958 DD1 client=800 U1238)。SE80やPFCGなどの適切なトランザクションを使用して、関数モジュールと承認ロールが正常にインポートされていることを確認します。
必要な SAP 承認
Cloud Data Fusion でデータ パイプラインを実行するには、SAP ユーザーが必要です。SAP ユーザーは、コミュニケーション タイプまたはダイアログ タイプのいずれかである必要があります。SAP ダイアログ リソースの使用を回避するには、Communications タイプをおすすめします。SAP トランザクション コード SU01 を使用して、SAP 管理者はユーザーを作成できます。
SAP 承認は SAP 用のコネクタ(SAP 標準と新しいコネクタ承認オブジェクトの組み合わせ)の維持と構成に必要です。組織のセキュリティ ポリシーに基づいて承認オブジェクトを維持します。以下のリストに、コネクタに必要な重要な承認をいくつか紹介します。
承認オブジェクト: 承認オブジェクト
ZGOOGCDFMTは、トランスポート リクエスト ロールの一部として提供されます。ロールの作成: トランザクション コード
PFCGを使用して役割を作成します。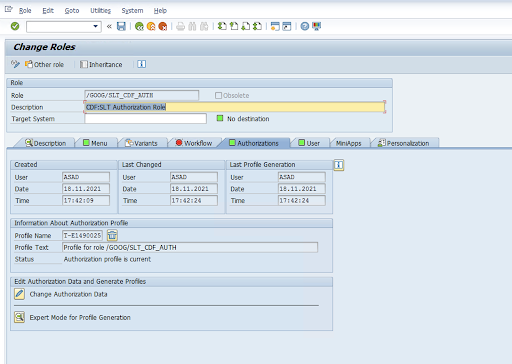
標準の SAP 承認オブジェクトの場合、組織は独自のセキュリティ メカニズムを使用して権限を管理します。
カスタム承認オブジェクトの場合は、承認オブジェクト
ZGOOGCDFMTの承認フィールドに値を指定します。詳細なアクセス制御のため、
ZGOOGCDFMTは承認グループベースの承認を行います。承認グループに対する完全、部分的なアクセス権を保有する、またはまったくアクセス権を付与されていないユーザーには、ロールに割り当てられた承認グループに基づいてアクセス権が付与されます。/GOOG/SLT_CDF_AUTH: すべての承認グループへのアクセス権つきのロール。特定の承認グループに固有のアクセスを制限するには、設定内の承認グループの FICDF を維持します。
ソースの RFC 宛先を作成する
構成を開始する前に、ソースと宛先の間で RFC 接続が確立されていることを確認してください。
トランザクション コード
SM59に移動する[作成] > [接続タイプ 3(ABAP 接続)] をクリックします。
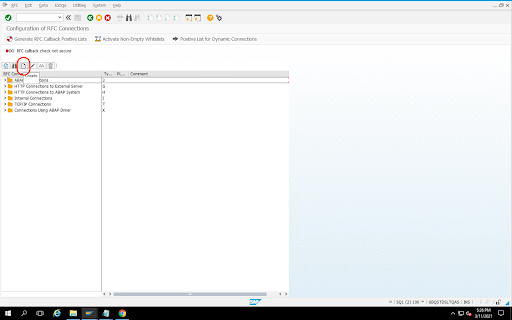
[テクニカル設定] ウィンドウで、RFC 宛先の詳細を入力します。
[ログオンとセキュリティ] タブをクリックして、RFC 認証情報(RFC ユーザーとパスワード)を維持します。
[保存] をクリックします。
[接続テスト] をクリックします。テストに成功したら、次に進めます。
RFC 認可テストが成功したことを確認します。
[ユーティリティ] > [テスト] > [承認テスト] をクリックします。
プラグインを構成する
プラグインを構成するには、Hub からデプロイし、レプリケーション ジョブを作成し、次の手順でソースとターゲットを構成します。
Cloud Data Fusion にプラグインをデプロイする
Cloud Data Fusion ユーザーが次の手順を行います。
Cloud Data Fusion レプリケーション ジョブを実行する前に、SAP SLT レプリケーション プラグインをデプロイします。
インスタンスに移動します。
Google Cloud コンソールで、Cloud Data Fusion の [インスタンス] ページに移動します。
新規または既存のインスタンスでレプリケーションを有効にします。
- 新規インスタンスの場合は、[インスタンスを作成] をクリックし、インスタンス名を入力し、[アクセラレータを追加] をクリックし、[レプリケーション] チェックボックスをオンにして、[保存] をクリックします。
- 既存のインスタンスの場合は、既存のインスタンスでのレプリケーションの有効化をご覧ください。
[インスタンスを表示] をクリックして、Cloud Data Fusion ウェブ インターフェースでインスタンスを開きます。
[Hub] をクリックします。
[SAP] タブにアクセスし、[SAP SLT] をクリックして [SAP SLT Replication Plugin] または [SAP SLT No RFC Replication Plugin] をクリックします。
[デプロイ] をクリックします。
レプリケーション ジョブを作成する
SAP SLT レプリケーション プラグインは、Cloud Storage API ステージング バケットを使用して SAP テーブルのコンテンツを読み取ります。
データ転送のレプリケーション ジョブを作成するには、次の手順に沿って操作します。
開いている Cloud Data Fusion インスタンスで、[ホーム] > [レプリケーション] > [レプリケーション ジョブの作成] をクリックします。[レプリケーション] オプションがない場合は、インスタンスのレプリケーションを有効にします。
レプリケーション ジョブの一意の [名前] と [説明] を入力します。
[次へ] をクリックします。
ソースを構成します。
次のフィールドに値を入力して、ソースを構成します。
- プロジェクト ID: Google Cloud プロジェクトの ID(このフィールドは事前入力されています)
Data Replication GCS Path: レプリケーション用のデータを含む Cloud Storage パス。SAP SLT ジョブで構成されているパスと同じである必要があります。内部的には、指定されたパスは
Mass Transfer IDとSource Table Nameに連結されます。形式:
gs://<base-path>/<mass-transfer-id>/<source-table-name>例:
gs://slt_bucket/012/MARAGUID: SLT GUID(SAP SLT 一括転送 ID に割り当てられた一意の識別子)。
一括転送 ID: SLT 一括転送 ID(SAP SLT の構成に割り当てられた一意の ID)。
SAP JCo ライブラリ GCS パス: ユーザーがアップロードした SAP JCo ライブラリ ファイルを含むストレージパス。SAP JCo ライブラリは、SAP サポート ポータルからダウンロードできます。 (プラグイン バージョン 0.10.0 では削除済み。)
SLT サーバー ホスト: SLT サーバー ホスト名または IP アドレス。(プラグイン バージョン 0.10.0 では削除済み。)
SAP システム番号: システム管理者によって提供されるインストール システム番号(
00など)。(プラグイン バージョン 0.10.0 では削除済み。)SAP クライアント: 使用する SAP クライアント(
100など)。(プラグイン バージョン 0.10.0 では削除済み)。SAP の言語: SAP ログオン言語(例:
EN)。(プラグイン バージョン 0.10.0 では削除済み。)SAP ログオンのユーザー名: SAP ユーザー名。 (プラグイン バージョン 0.10.0 では削除済み。)
- 推奨: SAP ログオンのユーザー名が定期的に変更される場合は、マクロを使用します。
SAP ログオン パスワード(M): ユーザー認証用の SAP ユーザー パスワード。
- 推奨: パスワードなどの機密性の高い値には、安全なマクロを使用してください。(プラグイン バージョン 0.10.0 では削除済み。)
CDF ジョブが停止したときに SLT レプリケーションを一時停止する: Cloud Data Fusion レプリケーション ジョブが停止するときに、SLT レプリケーション ジョブ(関連するテーブル用)の停止を試行します。Cloud Data Fusion のジョブが予期せず停止すると、失敗する可能性があります。
既存のデータを複製: ソーステーブルから既存のデータを複製するかどうかを示します。デフォルトでは、ジョブはソーステーブルから既存のデータを複製します。
falseに設定すると、ソーステーブルの既存のデータは無視され、ジョブの開始後に発生した変更のみが複製されます。サービス アカウントキー: Cloud Storage を操作する際に使用するキー。サービス アカウントには、Cloud Storage への書き込み権限が必要です。 Google Cloud VM で実行する場合は、VM に接続されているサービス アカウントを使用するように
auto-detectに設定する必要があります。
[次へ] をクリックします。
ターゲットを構成する
BigQuery にデータを書き込むには、BigQuery とステージング バケットの両方への書き込みアクセス権が必要です。変更イベントは、まず SLT から Cloud Storage にバッチで書き込まれます。その後、これらは BigQuery のステージング テーブルに読み込まれます。ステージング テーブルの変更は、BigQuery の結合クエリを使用して最終的なターゲット テーブルに統合されます。
最終的なターゲット テーブルには、ソーステーブルのすべての元の列と、1 つの追加の _sequence_num 列が含まれます。シーケンス番号を使用することで、レプリケーターに障害が発生したシナリオでデータの重複や欠落を回避できます。
次のフィールドに値を入力して、ソースを構成します。
- プロジェクト ID: BigQuery データセットのプロジェクト。Dataproc クラスタで実行する場合は、空白のままにしておくと、クラスタのプロジェクトが使用されます。
- 認証情報: 認証情報をご覧ください。
- サービス アカウント キー: Cloud Storage と BigQuery を操作する際に使用するサービス アカウント キーの内容。Dataproc クラスタで実行する場合は、空白のままにします。これにより、クラスタのサービス アカウントが使用されます。
- データセット名: BigQuery で作成するデータセットの名前。省略可。デフォルトでは、データセット名はソース データベース名と同じです。有効な名前は、文字、数字、アンダースコアのみを含む必要があり、最長で 1,024 文字まで可能です。無効な文字は、最終的なデータセット名でアンダースコアに置き換えられ、長さの上限を超える文字は切り捨てられます。
- 暗号鍵名: このターゲットによって作成されたリソースを保護するために使用される顧客管理の暗号鍵(CMEK)。暗号鍵名は
projects/<project-id>/locations/<key-location>/keyRings/<key-ring-name>/cryptoKeys/<key-name>の形式にする必要があります。 - ロケーション: BigQuery データセットと Cloud Storage ステージング バケットが作成されるロケーション。たとえば、リージョン バケットの場合は
us-east1、マルチリージョン バケットの場合はusです(ロケーションをご覧ください)。既存のバケットが指定されている場合、この値は無視されます。それは、ステージング バケットと BigQuery データセットがそのバケットと同じロケーションに作成されるためです。 ステージング バケット: 変更イベントがステージング テーブルに読み込まれる前に書き込まれるバケット。変更は、レプリケータ名と名前空間を含むディレクトリに書き込まれます。同じインスタンス内の複数のレプリケータ間で同じバケットを使用しても安全です。複数のインスタンス間でレプリカによって共有されている場合は、名前空間と名前が一意であることを確認してください。それ以外の場合は、動作が未定義になります。バケットは、BigQuery データセットと同じ場所に存在する必要があります。指定しない場合、
df-rbq-<namespace-name>-<job-name>-<deployment-timestamp>という名前の各ジョブに新しいバケットが作成されます。読み込み間隔(秒): BigQuery にデータのバッチを読み込む前に待機する秒数。
ステージング テーブルのプレフィックス: まずステージング テーブルに変更が書き込まれた後、最終テーブルにマージされます。ステージング テーブル名は、ターゲット テーブル名の前にこのプレフィックスを付けることで生成されます。
手動ドロップ処理を要求: ドロップ テーブルまたはデータベース イベントが発生したときに、テーブルとデータセットを削除するために手動での管理アクションを要求するかどうか。true に設定すると、レプリケータはテーブルまたはデータセットを削除しません。その代わりに、テーブルまたはデータセットが存在しなくなるまで失敗し、再試行します。データセットまたはテーブルが存在しない場合は、手動で操作する必要はありません。イベントは通常どおりスキップされます。
ソフト削除を有効にする: true に設定すると、ターゲットで削除イベントを受信したときにレコードの
_is_deleted列がtrueに設定されます。そうでない場合、レコードは BigQuery テーブルから削除されます。この構成は、順不同のイベントを生成するソースでは機能せず、レコードは常に BigQuery テーブルからソフト削除されます。
[次へ] をクリックします。
認証情報
プラグインを Dataproc クラスタで実行する場合、サービス アカウントキーを自動検出するように設定します。認証情報はクラスタ環境から自動的に読み取られます。
プラグインを Dataproc クラスタで実行しない場合は、サービス アカウント キーのパスを指定する必要があります。サービス アカウント キーは、コンソールの IAM ページで確認できます。 Google Cloud アカウントキーに BigQuery へのアクセス権があることを確認します。サービス アカウントキー ファイルは、クラスタ内のすべてのノードで使用可能で、ジョブを実行するすべてのユーザーが読み取り可能である必要があります。
制限事項
- テーブルには、複製する主キーが必要です。
- テーブルの名前変更オペレーションはサポートされていません。
- テーブルの変更は部分的にサポートされています。
- 既存の null 値を指定できない列は、null 値を指定できる列に変更できます。
- null 値を指定できる新しい列は、既存のテーブルに追加できます。
- テーブル スキーマに対するその他の変更は失敗します。
- 主キーの変更は失敗しませんが、既存のデータは新しい主キーで一意になるように書き換えられません。
テーブルと変換を選択する
[テーブルと変換を選択する] ステップでは、SLT システムでレプリケーション用に選択されたテーブルのリストが表示されます。
- 複製するテーブルを選択します。
- 省略可: 挿入、更新、削除などの追加のスキーマ オペレーションを選択します。
- スキーマを表示するには、テーブルの [複製する列] をクリックします。
省略可: スキーマ内の列の名前を変更する手順は次のとおりです。
- スキーマを表示した状態で、[変換] > [名前を変更] をクリックします。
- [名前を変更] 欄に新しい名前を入力し、[適用] をクリックします。
- 新しい名前を保存するには、[更新]、[保存] の順にクリックします。
[次へ] をクリックします。
省略可: 詳細プロパティを構成する
1 時間に複製するデータの量がわかっている場合は、適切なオプションを選択できます。
評価を確認する
[評価を確認する] ステップでは、スキーマの問題、欠損している機能、レプリケーション中に発生する接続の問題をスキャンします。
[評価を確認する] ページで [マッピングの表示] をクリックします。
問題が発生した場合は、処理を進める前に問題を解決する必要があります。
省略可: テーブルと変換を選択するときに列の名前を変更した場合は、この手順で新しい名前が正しいことを確認します。
[次へ] をクリックします。
レプリケーション ジョブの概要とデプロイ
[レプリケーション ジョブの詳細の確認] ページで、設定を確認し、[レプリケーション ジョブのデプロイ] をクリックします。
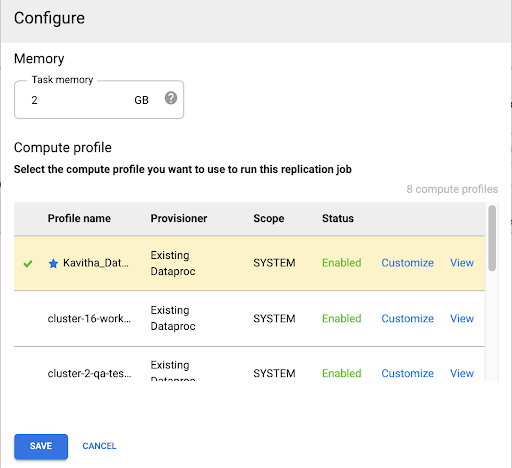
Compute Engine プロファイルを選択する
レプリケーション ジョブをデプロイしたら、Cloud Data Fusion ウェブ インターフェースの任意のページで [構成] をクリックします。
このレプリケーション ジョブの実行に使用する Compute Engine プロファイルを選択します。
[保存] をクリックします。
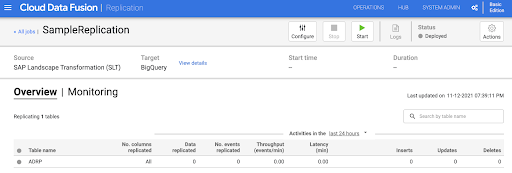
レプリケーション ジョブを開始する
- レプリケーション ジョブを実行するには、[開始] をクリックします。
省略可: パフォーマンスを最適化する
デフォルトでは、プラグインは最適なパフォーマンスが得られるように設定されています。追加の最適化については、ランタイム引数をご覧ください。
SLT と Cloud Data Fusion の通信のパフォーマンスは、次の要因によって異なります。
- ソースシステムの SLT と一元管理された専用の SLT システム(推奨オプション)
- SLT システムでのバックグラウンド ジョブ処理
- ソース SAP システムのダイアログ処理プロセス
- [LTRC アドミニストレーション] タブで各一括転送 ID に割り当てられるバックグラウンド ジョブ プロセスの数
- LTRS 設定
- SLT システムのハードウェア(CPU とメモリ)
- 使用するデータベース(例: HANA、Sybase、DB2)
- インターネット帯域幅(インターネット上の SAP システムとGoogle Cloud 間の接続)
- システムの既存の使用率(負荷)
- テーブル内の列数。列が増えると、レプリケーションが遅くなり、レイテンシが増加する可能性があります。
初期読み込みでは、LTRS 設定の次の読み取りタイプがおすすめです。
| SLT システム | ソースシステム | テーブルタイプ | 推奨される読み取りタイプ [初期読み込み] |
|---|---|---|---|
| SLT 3.0 スタンドアロン [DMIS 2018_1_752 SP 2] |
S/4 HANA 1909 | 透過(小 / 中) 透過(大) クラスタ テーブル |
1 範囲の計算 1 範囲の計算 4 送信者キュー |
| SLT 組み込み [S4CORE 104 HANA 1909] |
なし | 透過(小 / 中) 透過(大) クラスタ テーブル |
1 範囲の計算 1 範囲の計算 4 送信者キュー |
| SLT 2.0 スタンドアロン [DMIS 2011_1_731 SP 17] |
ECC NW 7.02 | 透過(小 / 中) 透過(大) クラスタ テーブル |
5 個の送信者キュー 5 個の送信者キュー 4 個の送信者キュー |
| SLT 埋め込み [DMIS 2011_1_700 SP 17] |
なし | 透過(小 / 中) 透過(大) クラスタ テーブル |
5 個の送信者キュー 5 個の送信者キュー 4 個の送信者キュー |
- レプリケーションでは、範囲なしを使用してパフォーマンスを向上させます。
- 範囲は、高レイテンシのロギング テーブルにバックログが生成される場合にのみ使用してください。
- 1 個の範囲計算の使用: SLT 2.0 システムと HANA 以外のシステムでは、初期読み込みの読み取りタイプはおすすめしません。
- 1 個の範囲計算の使用: 初期ロードの読み取りタイプにより、BigQuery でレコードが重複することがあります。
- スタンドアロンの SLT システムを使用すると、パフォーマンスが常に向上します。
- ソースシステムのリソース使用率がすでに高い場合については、スタンドアロンの SLT システムを常におすすめします。
ランタイム引数
snapshot.thread.count:SNAPSHOT/INITIALデータの読み込みを並行して実行するスレッドの数を渡します。デフォルトでは、レプリケーション ジョブが実行される Dataproc クラスタで使用可能な vCPU の数を使用します。推奨: このパラメータは、並列スレッドの数を正確に制御する必要がある場合(クラスタでの使用量を低減する場合など)にのみ設定します。
poll.file.count: ウェブ インターフェースの [データ レプリケーション GCS パス] フィールドに指定された Cloud Storage パスから、ポーリングするファイルの数を渡します。デフォルトでは、この値は 1 ポーリングにつき500ですが、クラスタ構成に基づいて増減できます。推奨事項: このパラメータは、レプリケーションの遅延に関する厳格な要件がある場合にのみ設定します。値を小さくすると、遅延が短縮される場合があります。これを使用してスループットを改善できます(応答しない場合は、デフォルトよりも高い値を使用します)。
bad.files.base.path: レプリケーション中に検出されたエラーまたは不良なデータファイルがすべてコピーされるベースの Cloud Storage パスを渡します。これは、データ監査の要件が厳格である場合や、失敗した転送を記録するために特定の場所を使用しなければならない場合に有効です。デフォルトでは、問題のあるファイルはすべて、ウェブ インターフェースの [データ レプリケーション Cloud Storage パス] フィールドで指定された Cloud Storage パスにコピーされます。
障害のあるデータファイルの最終的なパスパターン:
gs://BASE_FILE_PATH/MASS_TRANSFER_ID/SOURCE_TABLE_NAME/bad_files/REPLICATION_JOB_NAME/REPLICATION_JOB_ID/BAD_FILE_NAME
例:
gs://slt_to_cdf_bucket/001/MARA/bad_files/MaraRepl/05f97349-7398-11ec-9443-8 ac0640fc83c/20220205_1901205168830_DATA_INIT.xml
悪いファイルの基準は、破損しているまたは無効な XML ファイル、PK 値の欠落、またはフィールド データ型の不一致の問題です。
サポートの詳細
サポートされている SAP のプロダクトとバージョン
- SAP_BASIS 702 リリース、SP レベル 0016 以降。
- SAP_ABA 702 リリース、SP レベル 0016 以降。
- DMIS 2011_1_700 リリース、SP レベル 0017 以降。
サポートされている SLT バージョン
SLT バージョン 2 と 3 がサポートされています。
サポートされている SAP デプロイモデル
スタンドアロン システムとして、またはソースシステムに組み込まれた SLT。
SLT の使用を開始する前に実装する必要がある SAP Note
PL12 以降に対する /UI2/CL_JSON クラスの修正がサポート パッケージに含まれていない場合は、/UI2/CL_JSON クラス訂正用の最新の SAP Note(PL12 用の SAP Note 2798102 など)を実装します。
推奨: セントラル システムまたはソース システムの条件に基づいて、レポート CNV_NOTE_ANALYZER_SLT で推奨される SAP Notes を実装します。詳細については、SAP Note 3016862 をご覧ください(SAP へのログインが必要です)。
SAP がすでに設定されている場合、追加の Note を実装する必要はありません。特定のエラーまたは問題については、SLT リリースのcentral SAP Note をご覧ください。
データ量またはレコードの幅の上限
抽出されるデータの量とレコードの幅に対して定義された上限はありません。
SAP SLT レプリケーション プラグインの想定スループット
パフォーマンスを最適化するのガイドラインに従って構成された環境では、プラグインは初期読み込みで 1 時間あたり約 13 GB、レプリケーション(CDC)で 1 時間あたり約 3 GB を抽出できます。実際のパフォーマンスは、Cloud Data Fusion と SAP システムの負荷またはネットワーク トラフィックによって異なる場合があります。
SAP デルタ抽出(変更データ)のサポート
SAP デルタ抽出がサポートされています。
必須: Cloud Data Fusion インスタンスのテナント ピアリング
Cloud Data Fusion インスタンスを内部 IP アドレスで作成する場合は、テナント ピアリングが必要です。テナント ピアリングの詳細については、限定公開インスタンスの作成をご覧ください。
トラブルシューティング
レプリケーション ジョブが再起動し続ける
レプリケーション ジョブが自動的に再起動し続ける場合は、レプリケーション ジョブ クラスタのメモリを増やして、レプリケーション ジョブを再実行します。
BigQuery シンクでの重複
SAP SLT レプリケーション プラグインの詳細設定で並列ジョブの数を定義すると、テーブルが大きい場合はエラーが発生し、BigQuery シンクの列が重複するようになります。
この問題を回避するには、データを読み込むときに並列ジョブを削除します。
エラーのシナリオ
次の表に、いくつかの一般的なエラー メッセージを示します(引用符内のテキストは、実行時に実際の値に置き換えられます)。
| メッセージ ID | メッセージ | 推奨される対処方法 |
|---|---|---|
CDF_SAP_SLT_01402 |
Service account type is not defined for
SERVICE_ACCT_NAME_FROM_UI. |
指定した Cloud Storage のパスが正しいことを確認します。 |
CDF_SAP_SLT_01403 |
Service account key provided is not valid due to error:
ROOT_CAUSE. Please provide a valid service account key for
service account type : SERVICE_ACCT_NAME_FROM_UI. |
メッセージに表示された根本原因を確認し、適切な措置を講じます。 |
CDF_SAP_SLT_01404 |
Mass Transfer ID could not be found. Please ensure that it exists
in given GCS Bucket. |
指定された一括転送 ID の形式が正しいことを確認します。 |
CDF_SAP_SLT_01502 |
The specified data replication GCS path 'slt_to_cdf_bucket_1' or
Mass Transfer ID '05C' could not be found. Please ensure that it exists in
GCS. |
指定した Cloud Storage のパスが正しいことを確認します。 |
CDF_SAP_SLT_01400 |
Metadata file not found. The META_INIT.json file is not present or
file is present with invalid format. |
メッセージに表示された根本原因を確認し、適切な措置を講じます。 |
CDF_SAP_SLT_03408 |
Failed to start the event reader. |
メッセージに表示された根本原因を確認し、適切な措置を講じます。 |
CDF_SAP_SLT_03409 |
Error while processing TABLE_NAME file for source table
gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/TABLE_NAME
/FILE_NAME. Root cause: ROOT_CAUSE. |
メッセージに表示された根本原因を確認し、適切な措置を講じます。 |
CDF_SAP_SLT_03410 |
Failed to replicate data for source table TABLE_NAME
from file: gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/
TABLE_NAME/FILE_NAME. Root cause:
ROOT_CAUSE. |
メッセージに表示された根本原因を確認し、適切な措置を講じます。 |
CDF_SAP_SLT_03411 |
Failed data replication for source table TABLE_NAME.
Root cause: ROOT_CAUSE. |
メッセージに表示された根本原因を確認し、適切な措置を講じます。 |
CDF_SAP_SLT_03412 |
Failed to create target table for source table
TABLE_NAME. Root cause: ROOT_CAUSE. |
メッセージに表示された根本原因を確認し、適切な措置を講じます。 |
データ型マッピング
次の表では、SAP アプリケーションと Cloud Data Fusion で使用されるデータ型のマッピングを示します。
| SAP のデータ型 | ABAP のタイプ | 説明(SAP) | Cloud Data Fusion のデータ型 |
|---|---|---|---|
| 数値 | |||
| INT1 | b | 1-byte integer | int |
| INT2 | s | 2-byte integer | int |
| INT4 | i | 4-byte integer | int |
| INT8 | 8 | 8-byte integer | long |
| 12 月 | p | BCD 形式でパックされた番号(DEC) | decimal |
| DF16_DEC DF16_RAW |
a | 10 進浮動小数点数 8 バイト IEEE 754r | decimal |
| DF34_DEC DF34_RAW |
e | 10 進浮動小数点数 16 バイト IEEE 754r | decimal |
| FLTP | f | バイナリ形式の浮動小数点数 | double |
| 文字 | |||
| CHAR LCHR |
c | 文字列 | string |
| SSTRING GEOM_EWKB |
文字列 | 文字列 | string |
| STRING GEOM_EWKB |
文字列 | 文字列 CLOB | bytes |
| NUMC ACCP |
n | 数値テキスト | string |
| Byte | |||
| RAW LRAW |
x | バイナリデータ | bytes |
| RAWSTRING | xstring | バイト文字列 BLOB | bytes |
| 日時 | |||
| DATS | d | 日付 | date |
| 時刻 | t | 時間 | time |
| TIMESTAMP | utcl | ( Utclong ) TimeStamp |
timestamp |
次のステップ
- Cloud Data Fusion について学ぶ。
- Google Cloud上の SAP の詳細を確認する。